Neste artigo, discutiremos vários problemas que você pode enfrentar ao criar, configurar ou manter um site de grupo de disponibilidade Always on.
Antes de passar por este artigo, é recomendável ler o artigo anterior, Configurando e Configurando o Grupo de Disponibilidade Always on no SQL Server, para se familiarizar com o conceito de Grupo de Disponibilidade Always On e os assistentes de Novo Grupo de Disponibilidade mostrados neste artigo.
Recurso de grupo de disponibilidade sempre ativado não ativado
Suponha que, ao tentar criar um novo Grupo de Disponibilidade Always On, a partir do nó Always On High Availability, no Pesquisador de Objetos do SQL Server Management Studio, você enfrentou a mensagem de erro abaixo:
O recurso Always On Availability Groups deve ser habilitado para a instância do servidor 'SQL1' antes que você possa criar um grupo de disponibilidade nesta instância. Para habilitar esse recurso, abra o SQL Server Configuration Manager, selecione SQL Server Services, clique com o botão direito do mouse no nome do serviço SQL Server, selecione Propriedades e use a guia Always On Availability Groups da caixa de diálogo Server Properties. Habilitar Grupos de Disponibilidade AlwaysOn pode exigir que a instância do servidor seja hospedada por um nó do Windows Server Failover Cluster (WSFC). (Microsoft.SqlServer.Management.HadrTasks)

Fica claro na mensagem de erro que o recurso Grupos de Disponibilidade AlwaysOn deve ser habilitado em cada instância do SQL Server que participa do site do Grupo de Disponibilidade AlwaysOn, antes de criar esse site.
Você pode habilitar facilmente o recurso Always on Availability Group, abrindo o console do SQL Server Configuration Manager, navegue na guia SQL Server Services, clique com o botão direito do mouse no serviço SQL Server Database Engine e escolha a opção Properties.
Na janela de propriedades do SQL Server aberta, vá para a guia Always on High Availability e marque a caixa de seleção ao lado de Enable Always on Availability Group , levando em consideração que essa alteração requer a reinicialização do serviço SQL Server para entrar em vigor, conforme mostrado abaixo:

Problema de validação de pré-requisitos do banco de dados
Nas etapas anteriores do assistente Novo Grupo de Disponibilidade, você será solicitado a especificar os bancos de dados que participarão do Grupo de Disponibilidade Always On. Antes de adicionar o banco de dados, o banco de dados deve passar na verificação de validação de pré-requisitos. Caso contrário, o banco de dados não poderá ser selecionado nas listas de bancos de dados, conforme mostrado na mensagem de erro abaixo:
Para ser adicionado a um grupo de disponibilidade, esse banco de dados deve ser definido para o modelo de recuperação completo. Defina a propriedade de banco de dados do Modelo de Recuperação como Completo e execute um backup de banco de dados completo ou diferencial no banco de dados. Você precisará agendar backups de log no banco de dados.

A mensagem é clara. Onde o banco de dados deve ser configurado com um modelo de recuperação completa e um backup completo ou diferencial deve ser realizado nesse banco de dados.
Além disso, o assistente avisa para agendar um backup de log de transações para esse banco de dados após alterar o modelo de recuperação para Completo, para truncar o arquivo de log de transações automaticamente e evitar a execução desse arquivo de log de transações sem espaço livre.
Para corrigir esse problema, altere o modelo de recuperação do banco de dados de Simples para Completo, na guia Opções da janela de propriedades do banco de dados e faça um backup completo desse banco de dados, conforme mostrado abaixo:

Atualizando a janela Select Databases, o status do banco de dados será alterado para Meet Prerequisites, conforme mostrado abaixo:

Problema de permissão de local de rede compartilhada
Ao tentar configurar um site de Grupo de Disponibilidade Always on, a etapa de validação do assistente de Novo Grupo de Disponibilidade falhou com a mensagem de erro abaixo:
O servidor primário 'SQL1' não pode gravar em '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. (Microsoft.SqlServer.Management.HadrModel)
Falha no backup do servidor 'SQL1'. (Microsoft.SqlServer.SmoExtended)
Não é possível abrir o dispositivo de backup '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. Erro 5 do sistema operacional (acesso negado.).
BACKUP DATABASE está terminando de forma anormal. (Provedor de dados .Net SqlClient)
No método de sincronização inicial do banco de dados completo e do backup de log, uma pasta compartilhada é necessária para manter os arquivos de backup completo e de backup de log de transações temporariamente para restaurá-los em todas as réplicas secundárias. Se a réplica primária não conseguir gravar os arquivos de backup nela ou as réplicas secundárias não conseguirem ler os arquivos de backup dela, o processo de validação do Novo Grupo de Disponibilidade falhará conforme abaixo:

Para corrigir esse problema, precisamos conceder permissão de leitura e gravação à conta SQL Server Service das réplicas primária e secundária na pasta compartilhada mostrada na mensagem de erro e, em seguida, executar novamente o processo de validação para garantir que todas as verificações sejam bem-sucedidas , como mostrado abaixo:

Problema de cluster de failover do Windows
Suponha que você esteja verificando o status de um site do Always on Availability Group existente e veja que:
- A função principal é movida da instância SQL1 para SQL2.
- No SQL2, os bancos de dados estão no estado Sincronizado.
- No SQL1, os bancos de dados não são sincronizados.
- SQL1 está no estado Resolvendo.
Como você pode ver claramente no SSMS Object Explorer abaixo:

Verificando os logs de erro do SQL Server no nó problemático, podemos ver que a réplica do Grupo de Disponibilidade fica offline e o Grupo de Disponibilidade parou de funcionar devido a um problema no Cluster de Failover do Windows Server, conforme mostrado nos erros abaixo:
- Always On Availability Groups:O nó de cluster de failover do Windows Server local não está mais online . Esta é apenas uma mensagem informativa. Nenhuma ação do usuário é necessária.
- Always On:O gerenciador de réplicas de disponibilidade está ficando offline porque o nó local do Windows Server Failover Clustering (WSFC) perdeu o quorum. Esta é apenas uma mensagem informativa. Nenhuma ação do usuário é necessária.
- Always On:A réplica local do grupo de disponibilidade 'DemoGroup' está sendo interrompida. Esta é apenas uma mensagem informativa. Nenhuma ação do usuário é necessária.

A mesma coisa pode ser detectada no Visualizador de Eventos do Windows Server, que mostra gradualmente como a réplica muda seu estado para o estado Resolvendo, conforme abaixo:
- Always On:A réplica local do grupo de disponibilidade 'DemoGroup' está se preparando para a transição para a função de resolução . Esta é apenas uma mensagem informativa. Nenhuma ação do usuário é necessária.
- O grupo de disponibilidade 'DemoGroup' está sendo solicitado para interromper a renovação da concessão porque o grupo de disponibilidade está off-line . Esta é apenas uma mensagem informativa. Nenhuma ação do usuário é necessária.
- O estado da réplica de disponibilidade local no grupo de disponibilidade 'DemoGroup' mudou de 'PRIMARY_NORMAL' para 'RESOLVING_NORMAL'. O estado mudou porque o grupo de disponibilidade está ficando offline. A réplica está ficando offline porque o grupo de disponibilidade associado foi excluído, ou o usuário colocou o grupo de disponibilidade associado offline no console de gerenciamento do Windows Server Failover Clustering (WSFC) ou o grupo de disponibilidade está fazendo failover para outra instância do SQL Server. Para obter mais informações, consulte o log de erros do SQL Server ou o log de cluster. Se este for um grupo de disponibilidade do Windows Server Failover Clustering (WSFC), você também poderá ver o console de gerenciamento do WSFC.

Para verificar o status do site de cluster do Windows, usaremos o Gerenciador de cluster de failover para ver qual parte do cluster do Windows está falhando.
Mas o Failover Cluster Manager mostra que todo o cluster está inativo, conforme mostrado abaixo:

A primeira coisa a validar aqui do lado do Windows Failover Cluster é o Cluster Service, que pode ser verificado no console do Windows Services, conforme abaixo:

Fica claro no console de serviços que o serviço de cluster não está em execução. Para corrigir esse problema, inicie o serviço nesse console e atualize o console do Gerenciador de Cluster de Failover para garantir que o site de cluster do Windows esteja funcionando, conforme mostrado abaixo:

Verificando novamente o Grupo de Disponibilidade Always on, você verá que os bancos de dados estão sincronizados novamente e o site do Grupo de Disponibilidade Always on está em estado de integridade novamente, conforme mostrado abaixo:

O arquivo de log de transações está cheio no lado principal
Suponha que você receba a mensagem de erro abaixo ao tentar executar uma nova consulta em um dos bancos de dados do Always on Availability Group:

Verificando o que está bloqueando o arquivo de logs de transações e impede que ele seja truncado, você verá que o arquivo de log de transações deste banco de dados está com operação de backup de log pendente para ser truncado, conforme mostrado abaixo:

Fazendo um backup de log de transações para esse banco de dados, caso você esqueça de agendar um trabalho de backup de log de transações, da seguinte maneira:

E verifique novamente o que está bloqueando o log de transações desse banco de dados, está mostrando no meu cenário que está aguardando Availability_Replica. O que significa que os logs estão aguardando para serem gravados na réplica secundária, mas não podem enviar esses logs de transações para as réplicas secundárias devido a um problema no site do Always On Availability Group, conforme abaixo:

O melhor local para verificar e solucionar problemas do site Always on Availability Group é o Always on Dashboard, que pode ser aberto clicando com o botão direito do mouse no nome do grupo de disponibilidade e escolhendo a opção Show Dashboard.
No painel, você pode ver que a réplica secundária SQL2 não está sincronizada com a réplica primária, devido a um problema de conectividade, conforme mostrado abaixo:

Verificando a réplica secundária e certificando-se de que o SQL Server Service esteja funcionando no lado secundário, da seguinte maneira:

Em seguida, atualizando o painel do Grupo de Disponibilidade novamente, você verá que o site do Grupo de Disponibilidade Always on está íntegro novamente. Verificando se o arquivo de logs de transações está bloqueado por alguma operação, veremos que está pendente OLDEST_PAGE, indicando que a página mais antiga do banco de dados é mais antiga que o checkpoint LSN. Esse problema pode ser corrigido facilmente fazendo outro backup do log de transações e o arquivo de log de transações não será bloqueado por nada, conforme mostrado claramente abaixo:

Always on Availability Group Failover Misconfiguration
Assume that the Primary replica becomes offline due to an unplanned issue. As expected, the system will not be affected as an automatic failover operation will be performed and the secondary replica will act as the new Primary replica.
But in our case, this happy scenario is not valid, where the secondary replica changed to Resolving state and the system is down!

Checking the secondary replica’s error log and see why it is not acting as the new Primary as expected, you will see that it is failing due to a role synchronization issue, as shown below:
The availability group database "AdventureWorks2017" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.

This means that there is an issue with the synchronization mode that is used in this Availability Group. The synchronization mode used, can be checked from the Always on Availability Group properties page.
From the properties page below, it is clear that the Failover mode in this Availability Group is configured to be performed Manually only. In this case, you need to manually perform a failover operation before rebooting or shutting down the server:

This can be fixed easily by changing the Failover Mode to Automatic, where an automatic failover operation will be performed in case of any unplanned shutdown or reboot:

The same issue can be faced when the Windows Failover Cluster quorum is configured with Node Majority for an even number of replicas, where any failure for one of the servers will bring the Windows Failover Cluster site offline. For more information, check Windows Failover Cluster Quorum Modes in SQL Server Always On Availability Groups:

Failover with Data Loss
Assume that you are trying to perform a manual failover between the Primary and one of the Secondary replicas, but in the Select New Primary Replica window, you see a warning message that the failover operation may end up with data loss as the Primary and the selected Secondary replica are not synchronized, as shown below:

To identify the cause of that issue, we will browse the Always on Health events using the Always on Availability Group dashboard, which shows that the Primary replica is not able to open a connection to the Secondary replica, ash shown below:

After fixing the connectivity issue between the Primary and the Secondary, refresh the replicas list and you will see that the data loss issue is fixed, as shown below. For more information about troubleshooting the connectivity issues, check Troubleshoot connecting to the SQL Server Database Engine.

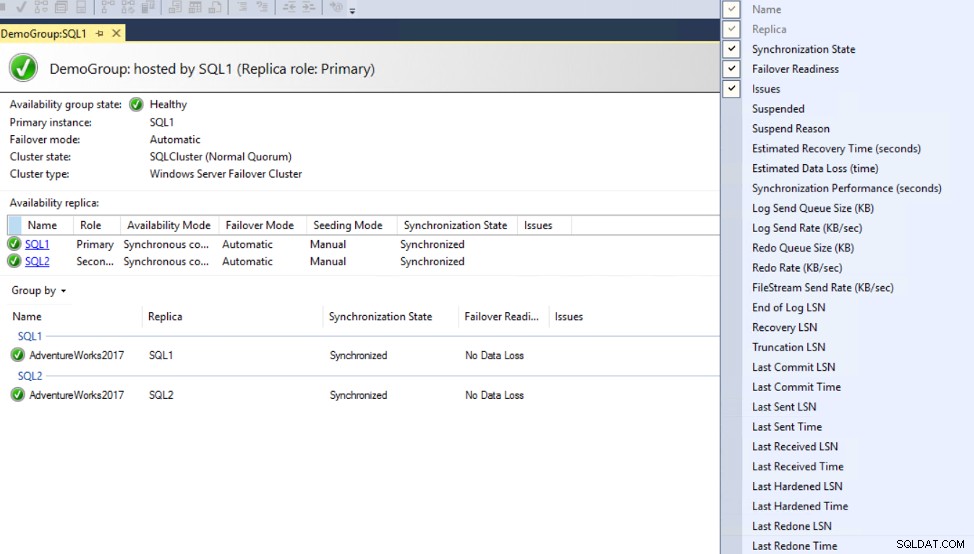
Monitoring Always on Availability Group Latency
The Availability Group dashboard can be modified to include additional columns that provide information about the synchronization latency between Primary and Secondary replicas, including the Commit LSN, Sent LSN and harden LSN values, without showing why there is a latency, as shown below:
For more information about measuring the latency, check the Measuring Availability Group synchronization lag.
Starting from SSMS 17.4, the Always on Availability Group dashboard enhanced to include two new options that are used for latency information calculation, analysis and reporting, which helps in identifying the bottlenecks in the transaction logs flow between the Primary and the Secondary replicas and narrow down the cause of that latency.
For more information about the new functionality and reports, check to Use the Always on Availability Group dashboard.
To trigger using this new option, click on Collect Latency Data option from the Always on Availability Group dashboard, that will create a new SQL Agent job on the Primary and Secondary replicas to collect the latency data, As shown below:

When the created job execution has completed on all the Availability Group replicas, you will be able to view the latency statistics from the latency reports by right-clicking on the Availability Group name and choose the Primary Replica Latency or Secondary Replica Latency report, based on the replica role in the Availability Group.
After providing information about the Availability Group replicas, the latency report will show a graphical view of the transaction log commit time on the Primary replica and the remote Hardening time for the secondary replicas, aggregated as average values. Also, the report provides statistical values for the transaction logs send, receive, commit, compress, decompress and other numerical values based on the replica role in the Availability Group.
For more information about the latency report, check New in SSMS - Always On Availability Group Latency Reports.
The below report is an example of the latency reports generated from the Secondary replica, showing normal logs transport operations:

Also, the Log Block Latency report shows the amount of time, in ms, that the transaction log on the Primary replica waits for Secondary replicas to commit that transaction. After enabling it from the Availability Group Dashboard, you can browse it from the SSMS similar to the previous latency reports. Take into consideration that, the large latency time indicates that the Primary replica is waiting a long time for the Secondary replicas to commit the sent transactions, as shown below: