Embora venham com muitas restrições e algumas advertências importantes de implementação, as exibições indexadas ainda são um recurso muito poderoso do SQL Server quando empregadas corretamente nas circunstâncias certas. Um uso comum é fornecer uma visão pré-agregada dos dados subjacentes, dando aos usuários a capacidade de consultar os resultados diretamente sem incorrer nos custos de processamento das associações, filtros e agregações subjacentes sempre que uma consulta é executada.
Embora os novos recursos da Enterprise Edition, como armazenamento colunar e processamento em modo de lote, tenham transformado as características de desempenho de muitas consultas grandes desse tipo, ainda não há maneira mais rápida de obter um resultado do que evitar completamente todo o processamento subjacente, por mais eficiente que seja esse processamento. poderia ter se tornado.
Antes que as exibições indexadas (e seus primos mais limitados, as colunas computadas) fossem adicionadas ao produto, os profissionais de banco de dados às vezes escreviam códigos complexos de vários gatilhos para apresentar os resultados de uma consulta importante em uma tabela real. Esse tipo de arranjo é notoriamente difícil de acertar em todas as circunstâncias, principalmente quando as alterações simultâneas nos dados subjacentes são frequentes.
O recurso de visualizações indexadas torna tudo isso muito mais fácil, onde é aplicado de forma sensata e correta. O mecanismo de banco de dados cuida de tudo o que é necessário para garantir que os dados lidos de uma exibição indexada correspondam sempre à consulta subjacente e aos dados da tabela.
Manutenção incremental
O SQL Server mantém os dados de exibição indexados sincronizados com a consulta subjacente atualizando automaticamente os índices de exibição adequadamente sempre que os dados são alterados nas tabelas base. O custo desta atividade de manutenção é suportado pelo processo de alteração dos dados base. As operações extras necessárias para manter os índices de exibição são adicionadas silenciosamente ao plano de execução para a operação de inserção, atualização, exclusão ou mesclagem original. Em segundo plano, o SQL Server também cuida de questões mais sutis relacionadas ao isolamento de transações, por exemplo, garantindo o tratamento correto para transações executadas em instantâneo ou isolamento de instantâneo confirmado de leitura.
Construir as operações extras do plano de execução necessárias para manter os índices de exibição corretamente não é uma questão trivial, pois qualquer pessoa que tenha tentado uma implementação de "tabela de resumo mantida por código de gatilho" saberá. A complexidade da tarefa é uma das razões pelas quais as visualizações indexadas têm tantas restrições. Limitar a área de superfície suportada a junções internas, projeções, seleções (filtros) e os agregados SUM e COUNT_BIG reduz consideravelmente a complexidade da implementação.
As visualizações indexadas são mantidas incrementalmente . Isso significa que o processador de consulta determina o efeito líquido das alterações da tabela base na exibição e aplica apenas as alterações necessárias para atualizar a exibição. Em casos simples, ele pode calcular os deltas necessários apenas a partir das alterações da tabela base e dos dados atualmente armazenados na visualização. Onde a definição de exibição contém junções, a parte de manutenção de exibição indexada do plano de execução também precisará acessar as tabelas unidas, mas isso geralmente pode ser executado de forma eficiente, considerando os índices de tabela base apropriados.
Para simplificar ainda mais a implementação, o SQL Server sempre usa a mesma forma de plano básico (como ponto de partida) para implementar operações de manutenção de exibição indexada. As facilidades normais fornecidas pelo otimizador de consulta são empregadas para simplificar e otimizar a forma de manutenção padrão conforme apropriado. Vamos agora recorrer a um exemplo para ajudar a reunir esses conceitos.
Exemplo 1 - Inserção de linha única
Suponha que temos a seguinte tabela simples e visualização indexada:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Depois que esse script é executado, os dados na tabela de amostra ficam assim:

E a visualização Indexada contém:

O exemplo mais simples de um plano de manutenção de exibição indexada para essa configuração ocorre quando adicionamos uma única linha à tabela base:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); O plano de execução para esta inserção é mostrado abaixo:
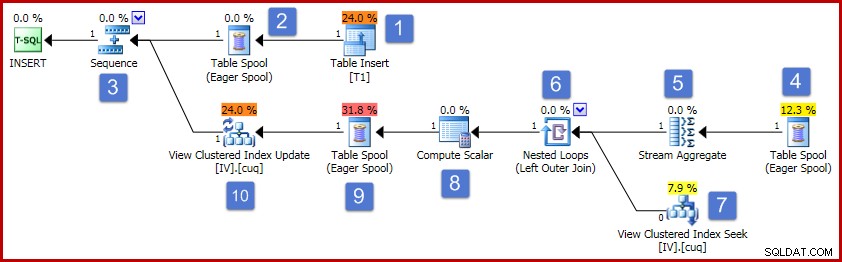
Seguindo os números do diagrama, o funcionamento deste plano de execução procede da seguinte forma:
- O operador Table Insert adiciona a nova linha à tabela base. Este é o único operador de plano associado à inserção da tabela base; todos os operadores restantes estão preocupados com a manutenção da visualização indexada.
- O Eager Table Spool salva os dados da linha inserida no armazenamento temporário.
- O operador Sequence garante que a ramificação superior do plano seja executada até a conclusão antes que a próxima ramificação da Sequência seja ativada. Neste caso especial (inserindo uma única linha), seria válido remover a Sequência (e os spools nas posições 2 e 4), conectando diretamente a entrada Stream Aggregate à saída do Table Insert. Essa possível otimização não é implementada, portanto, a sequência e os spools permanecem.
- Este Eager Table Spool está associado ao spool na posição 2 (ele tem uma propriedade de ID de nó primário que fornece esse link explicitamente). O spool reproduz linhas (uma linha no caso atual) do mesmo armazenamento temporário gravado pelo spool primário. Como mencionado acima, os spools e as posições 2 e 4 são desnecessários e são apresentados simplesmente porque existem no modelo genérico para manutenção da visualização indexada.
- O Stream Aggregate calcula a soma dos dados da coluna Value no conjunto inserido e conta o número de linhas presentes por grupo de chave de visualização. A saída são os dados incrementais necessários para manter a visualização sincronizada com os dados de base. Observe que o Stream Aggregate não tem um elemento Group By porque o otimizador de consulta sabe que apenas um único valor está sendo processado. No entanto, o otimizador não aplica lógica semelhante para substituir as agregações por projeções (a soma de um único valor é apenas o valor em si, e a contagem sempre será um para uma inserção de linha única). Calcular a soma e os agregados de contagem para uma única linha de dados não é uma operação cara, portanto, essa otimização perdida não é motivo de preocupação.
- A junção relaciona cada alteração incremental calculada a uma chave existente na visualização indexada. A junção é uma junção externa porque os dados recém-inseridos podem não corresponder a nenhum dado existente na visualização.
- Este operador localiza a linha a ser modificada na visualização.
- O Compute Scalar tem duas responsabilidades importantes. Primeiro, ele determina se cada alteração incremental afetará uma linha existente na exibição ou se uma nova linha terá que ser criada. Ele faz isso verificando se a junção externa produziu um nulo do lado da visão da junção. Nossa inserção de exemplo é para o grupo 3, que não existe atualmente na exibição, portanto, uma nova linha será criada. A segunda função do Compute Scalar é calcular novos valores para as colunas de exibição. Se uma nova linha deve ser adicionada à exibição, isso é simplesmente o resultado da soma incremental do Stream Aggregate. Se uma linha existente na visualização precisar ser atualizada, o novo valor será o valor existente na linha da visualização mais a soma incremental do Stream Aggregate.
- Este carretel de mesa ansioso é para proteção de Halloween. É necessário para correção quando uma operação de inserção afeta uma tabela que também é referenciada no lado de acesso a dados da consulta. Tecnicamente, não é necessário se a operação de manutenção de linha única resultar em uma atualização para uma linha de visualização existente, mas permanece no plano de qualquer maneira.
- O operador final no plano é rotulado como um operador de atualização, mas executará uma inserção ou uma atualização para cada linha recebida, dependendo do valor da coluna "código de ação" adicionada pelo Compute Scalar no nó 8 . De forma mais geral, esse operador de atualização é capaz de inserções, atualizações e exclusões.
Há um pouco de detalhes lá, então resumindo:
- Os dados dos grupos agregados são alterados pela chave clusterizada exclusiva da visualização. Ele calcula o efeito líquido das alterações da tabela base em cada coluna por chave.
- A junção externa conecta as alterações incrementais por chave às linhas existentes na visualização.
- A computação escalar calcula se uma nova linha deve ser adicionada à visualização ou uma linha existente atualizada. Ele calcula os valores finais da coluna para a operação de inserção ou atualização da exibição.
- O operador de atualização de visualização insere uma nova linha ou atualiza uma existente conforme indicado pelo código de ação.
Exemplo 2 – Inserção de várias linhas
Acredite ou não, o plano de execução de inserção de tabela base de linha única discutido acima estava sujeito a várias simplificações. Embora algumas possíveis otimizações adicionais tenham sido perdidas (como observado), o otimizador de consulta ainda conseguiu remover algumas operações do modelo geral de manutenção de exibição indexada e reduzir a complexidade de outras.
Várias dessas otimizações foram permitidas porque estávamos inserindo apenas uma única linha, mas outras foram ativadas porque o otimizador conseguiu ver os valores literais sendo adicionados à tabela base. Por exemplo, o otimizador pode ver que o valor do grupo inserido passaria o predicado na cláusula WHERE da visualização.
Se agora inserirmos duas linhas, com os valores "ocultos" nas variáveis locais, obtemos um plano um pouco mais complexo:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2); 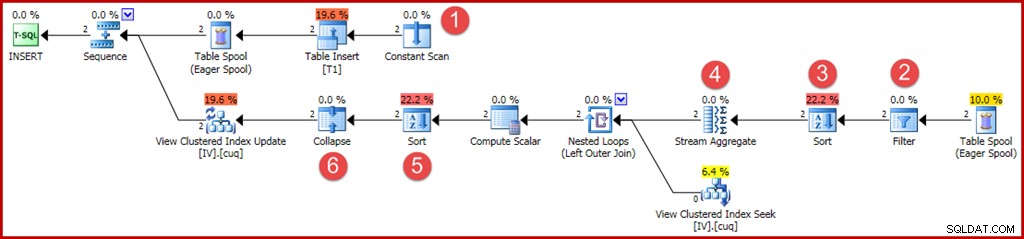
Os operadores novos ou alterados são anotados como antes:
- O Constant Scan fornece os valores a serem inseridos. Anteriormente, uma otimização para inserções de linha única permitia que esse operador fosse omitido.
- Um operador de filtro explícito agora é necessário para verificar se os grupos inseridos na tabela base correspondem à cláusula WHERE na exibição. Como acontece, ambas as novas linhas passarão no teste, mas o otimizador não pode ver os valores nas variáveis para saber isso com antecedência. Além disso, não seria seguro armazenar em cache um plano que ignorasse esse filtro porque uma reutilização futura do plano poderia ter valores diferentes nas variáveis.
- Uma classificação agora é necessária para garantir que as linhas cheguem ao Stream Aggregate na ordem do grupo. A classificação foi removida anteriormente porque é inútil classificar uma linha.
- O Stream Aggregate agora tem uma propriedade "group by", que corresponde à chave clusterizada exclusiva da visualização.
- Essa classificação é necessária para apresentar linhas em ordem de código de ação, chave de visualização, que é necessária para a operação correta do operador Recolher. Sort é um operador de bloqueio total, portanto, não há mais necessidade de um Eager Table Spool para proteção de Halloween.
- O novo operador Collapse combina uma inserção e uma exclusão adjacentes no mesmo valor de chave em uma única operação de atualização. Este operador não é realmente necessário neste caso, porque nenhum código de ação de exclusão pode ser gerado (somente inserções e atualizações). Isso parece ser um descuido, ou talvez algo deixado por motivos de segurança. As partes geradas automaticamente de um plano de consulta de atualização podem se tornar extremamente complexas, por isso é difícil saber com certeza.
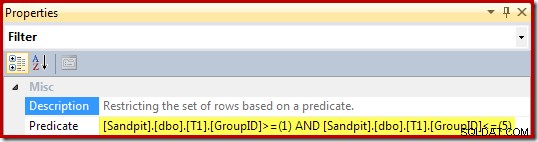
As propriedades do Filtro (derivadas da cláusula WHERE da visualização) são:
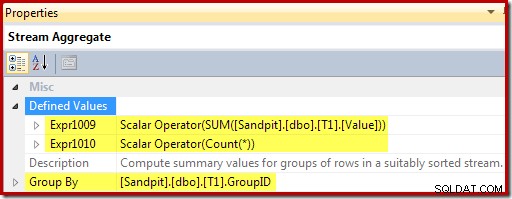
O Stream Aggregate agrupa pela chave de visualização e calcula as agregações de soma e contagem por grupo:
O Compute Scalar identifica a ação a ser executada por linha (inserir ou atualizar neste caso) e calcula o valor a ser inserido ou atualizado na visualização:
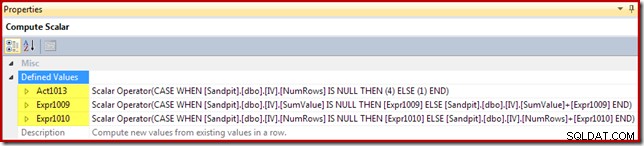
O código de ação recebe um rótulo de expressão de [Act1xxx]. Os valores válidos são 1 para uma atualização, 3 para uma exclusão e 4 para uma inserção. Essa expressão de ação resulta em uma inserção (código 4) se nenhuma linha correspondente for encontrada na exibição (ou seja, a junção externa retornou um nulo para a coluna NumRows). Se uma linha correspondente foi encontrada, o código de ação é 1 (atualização).
Observe que NumRows é o nome dado à coluna COUNT_BIG(*) necessária na exibição. Em um plano que poderia resultar em exclusões da exibição, o Compute Scalar detectaria quando esse valor se tornaria zero (sem linhas para o grupo atual) e geraria um código de ação de exclusão (3).
As expressões restantes mantêm as agregações de soma e contagem na exibição. Observe que os rótulos de expressão [Expr1009] e [Expr1010] não são novos; eles se referem aos rótulos criados pelo Stream Aggregate. A lógica é simples:se uma linha correspondente não for encontrada, o novo valor a ser inserido será apenas o valor calculado na agregação. Se uma linha correspondente na exibição for encontrada, o valor atualizado será o valor atual na linha mais o incremento calculado pela agregação.
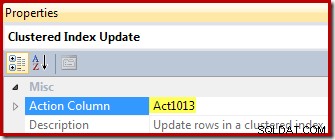
Por fim, o operador de atualização de exibição (mostrado como uma atualização de índice clusterizado no SSMS) mostra a referência da coluna de ação ([Act1013] definida pelo Compute Scalar):
Exemplo 3 – Atualização de várias linhas
Até agora, analisamos apenas as inserções na tabela base. Os planos de execução para uma exclusão são muito semelhantes, com apenas algumas pequenas diferenças nos cálculos detalhados. Este próximo exemplo, portanto, passa a examinar o plano de manutenção para uma atualização da tabela base:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Como antes, essa consulta usa variáveis para ocultar valores literais do otimizador, evitando que algumas simplificações sejam aplicadas. Também é preciso atualizar dois grupos separados, evitando otimizações que podem ser aplicadas quando o otimizador sabe que apenas um único grupo (uma única linha da visualização indexada) será afetado. O plano de execução anotado para a consulta de atualização está abaixo:
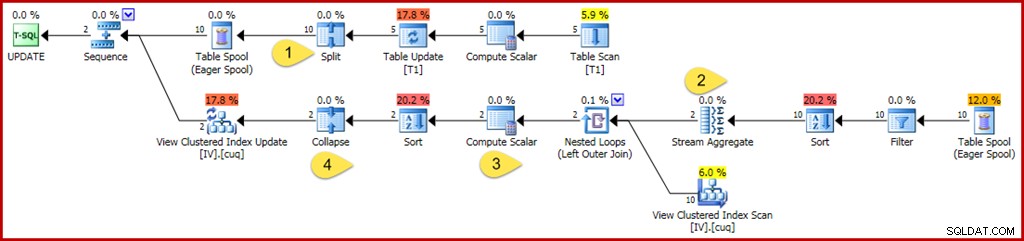
As alterações e pontos de interesse são:
- O novo operador Split transforma cada atualização de linha da tabela base em uma operação separada de exclusão e inserção. Cada linha de atualização é dividida em duas linhas separadas, dobrando o número de linhas após esse ponto no plano. Split faz parte do padrão split-sort-collapse necessário para proteger contra erros de violação de chave exclusiva transitórios incorretos.
- O Stream Aggregate é modificado para considerar as linhas de entrada que podem especificar uma exclusão ou uma inserção (devido à divisão e determinada por uma coluna de código de ação na linha). Uma linha de inserção contribui com o valor original em agregados de soma; o sinal é invertido para linhas de ação de exclusão. Da mesma forma, o agregado de contagem de linhas aqui conta as linhas de inserção como +1 e as linhas de exclusão como –1.
- A lógica Compute Scalar também é modificada para refletir que o efeito líquido das alterações por grupo pode exigir uma eventual ação de inserção, atualização ou exclusão na exibição materializada. Na verdade, não é possível que essa consulta de atualização específica resulte na inserção ou exclusão de uma linha nessa exibição, mas a lógica necessária para deduzir isso está além das habilidades de raciocínio atuais do otimizador. Uma consulta de atualização ou definição de exibição ligeiramente diferente pode resultar em uma combinação de ações de inserção, exclusão e atualização de exibição.
- O operador Collapse é destacado apenas por sua função no padrão split-sort-collapse mencionado acima. Observe que ele só recolhe exclusões e inserções na mesma chave; exclusões e inserções sem correspondência após o Collapse são perfeitamente possíveis (e bastante comuns).
Como antes, as principais propriedades do operador a serem observadas para entender o trabalho de manutenção da exibição indexada são Filter, Stream Aggregate, Outer Join e Compute Scalar.
Exemplo 4 – Atualização de várias linhas com junções
Para completar a visão geral dos planos de execução de manutenção de exibição indexada, precisaremos de uma nova exibição de exemplo que una várias tabelas e inclua uma projeção na lista de seleção:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Para garantir a exatidão, um dos requisitos de exibição indexada é que uma agregação de soma não possa operar em uma expressão que possa ser avaliada como nula. A definição de exibição acima usa ISNULL para atender a esse requisito. Um exemplo de consulta de atualização que produz um componente de plano de manutenção de índice bastante abrangente é mostrado abaixo, juntamente com o plano de execução que ele produz:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1; 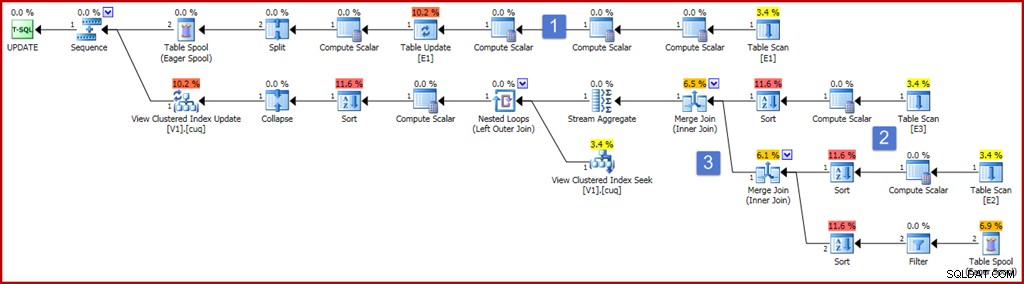
O plano parece bastante grande e complicado agora, mas a maioria dos elementos é exatamente como já vimos. As principais diferenças são:
- A ramificação superior do plano inclui vários operadores Compute Scalar extras. Eles podem ser organizados de forma mais compacta, mas essencialmente estão presentes para capturar os valores de pré-atualização das colunas não agrupadas. O Compute Scalar à esquerda da Table Update captura o valor pós-atualização da coluna "a", com a projeção ISNULL aplicada.
- Os novos Compute Scalars nesta área do plano calculam o valor produzido pela expressão ISNULL em cada tabela de origem. Em geral, as projeções nas tabelas unidas na exibição serão representadas por Compute Scalars aqui. As classificações nesta área do plano estão presentes apenas porque o otimizador escolheu uma estratégia de junção de mesclagem por motivos de custo (lembre-se, a mesclagem requer entrada classificada por chave de junção).
- Os dois operadores de junção são novos e simplesmente implementam as junções na definição da visualização. Essas junções sempre aparecem antes do Stream Aggregate que calcula o efeito incremental das alterações na exibição. Observe que uma alteração em uma tabela base pode fazer com que uma linha que costumava atender aos critérios de junção não seja mais unida e vice-versa. Todas essas complexidades em potencial são tratadas corretamente (dadas as restrições de exibição indexada) pelo Stream Aggregate, produzindo um resumo das alterações por chave de exibição após a execução das junções.
Considerações finais
Esse último plano representa praticamente o modelo completo para manter uma exibição indexada, embora a adição de índices não clusterizados à exibição também adicionaria operadores adicionais em spool da saída do operador de atualização de exibição. Além de uma divisão extra (e uma combinação de classificação e retração se o índice não clusterizado da exibição for exclusivo), não há nada de muito especial nessa possibilidade. Adicionar uma cláusula de saída à consulta da tabela base também pode produzir alguns operadores extras interessantes, mas, novamente, eles não são específicos da manutenção de exibição indexada em si.
Para resumir a estratégia geral completa:
- As alterações da tabela base são aplicadas normalmente; valores de pré-atualização podem ser capturados.
- Um operador de divisão pode ser usado para transformar atualizações em pares excluir/inserir.
- Um spool antecipado salva as informações de alteração da tabela base no armazenamento temporário.
- Todas as tabelas na visualização são acessadas, exceto a tabela base atualizada (que é lida do spool).
- As projeções na visualização são representadas por Compute Scalars.
- Os filtros na visualização são aplicados. Os filtros podem ser inseridos em varreduras ou buscas como resíduos.
- As junções especificadas na visualização são executadas.
- Um agregado calcula as alterações incrementais líquidas agrupadas por chave de visualização em cluster.
- O conjunto de alterações incrementais é unido externamente à visualização.
- Um Compute Scalar calcula um código de ação (inserir/atualizar/excluir na exibição) para cada alteração e calcula os valores reais a serem inseridos ou atualizados. A lógica computacional é baseada na saída da agregação e no resultado da junção externa à visão.
- As alterações são classificadas em ordem de chave de visualização e código de ação e recolhidas para atualizações conforme apropriado.
- Por fim, as alterações incrementais são aplicadas à própria visualização.
Como vimos, o conjunto normal de ferramentas disponíveis para o otimizador de consultas ainda é aplicado às partes do plano geradas automaticamente, o que significa que uma ou mais das etapas acima podem ser simplificadas, transformadas ou removidas completamente. No entanto, a forma básica e a operação do plano permanecem intactas.
Se você estiver acompanhando os exemplos de código, poderá usar o script a seguir para limpar:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;