
É aquela terça-feira do mês – você sabe, aquela em que acontece a festa do bloco de blogueiros conhecida como T-SQL Tuesday. Este mês é apresentado por Russ Thomas (@SQLJudo), e o tópico é "Chamando todos os sintonizadores e cabeças de engrenagem". Vou tratar de um problema relacionado ao desempenho aqui, embora me desculpe por não estar totalmente de acordo com as diretrizes que Russ estabeleceu em seu convite (não vou usar dicas, sinalizadores de rastreamento ou guias de plano) .
No SQLBits na semana passada, fiz uma apresentação sobre gatilhos, e meu bom amigo e colega MVP Erland Sommarskog compareceu. A certa altura, sugeri que antes de criar um novo gatilho em uma tabela, você deve verificar se já existe algum gatilho e considerar combinar a lógica em vez de adicionar um gatilho adicional. Minhas razões foram principalmente para a manutenção do código, mas também para o desempenho. Erland perguntou se eu já havia testado para ver se havia alguma sobrecarga adicional em ter vários gatilhos disparados para a mesma ação, e eu tive que admitir que, não, eu não tinha feito nada extenso. Então eu vou fazer isso agora.
No AdventureWorks2014, criei um conjunto simples de tabelas que basicamente representam
sys.all_objects (~2.700 linhas) e sys.all_columns (~9.500 linhas). Eu queria medir o efeito na carga de trabalho de várias abordagens para atualizar ambas as tabelas – essencialmente, você tem usuários atualizando a tabela de colunas e usa um gatilho para atualizar uma coluna diferente na mesma tabela e algumas colunas na tabela de objetos. - T1:linha de base :Suponha que você possa controlar todo o acesso a dados por meio de um procedimento armazenado; neste caso, as atualizações em ambas as tabelas podem ser realizadas diretamente, sem a necessidade de triggers. (Isso não é prático no mundo real, porque você não pode proibir de forma confiável o acesso direto às tabelas.)
- T2:gatilho único contra outra tabela :Suponha que você possa controlar a instrução de atualização na tabela afetada e adicionar outras colunas, mas as atualizações na tabela secundária precisam ser implementadas com um gatilho. Atualizaremos todas as três colunas com uma instrução.
- T3:gatilho único em ambas as tabelas :nesse caso, temos um gatilho com duas instruções, uma que atualiza a outra coluna na tabela afetada e outra que atualiza todas as três colunas na tabela secundária.
- T4:gatilho único em ambas as tabelas :Como T3, mas desta vez, temos um gatilho com quatro instruções, uma que atualiza a outra coluna na tabela afetada e uma instrução para cada coluna atualizada na tabela secundária. Essa pode ser a maneira como isso é tratado se os requisitos forem adicionados ao longo do tempo e uma instrução separada for considerada mais segura em termos de teste de regressão.
- T5:dois acionadores :Um gatilho atualiza apenas a tabela afetada; o outro usa uma única instrução para atualizar as três colunas na tabela secundária. Isso pode ser feito se os outros acionadores não forem percebidos ou se for proibido modificá-los.
- T6:quatro acionadores :Um gatilho atualiza apenas a tabela afetada; os outros três atualizam cada coluna na tabela secundária. Novamente, isso pode ser feito se você não souber que os outros gatilhos existem ou se tiver medo de tocar nos outros gatilhos devido a problemas de regressão.
Aqui estão os dados de origem com os quais estamos lidando:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Agora, para cada um dos 6 testes, vamos executar nossas atualizações 1.000 vezes e medir o tempo
T1:linha de base
Este é o cenário em que temos a sorte de evitar gatilhos (novamente, não muito realistas). Nesse caso, mediremos as leituras e a duração desse lote. Eu coloquei
/*real*/ no texto da consulta para que eu possa facilmente extrair as estatísticas apenas para essas instruções, e não para quaisquer instruções de dentro dos gatilhos, pois, em última análise, as métricas se acumulam nas instruções que invocam os gatilhos. Observe também que as atualizações reais que estou fazendo não fazem muito sentido, então ignore que estou definindo o agrupamento para o nome do servidor/instância e o principal_id do objeto para o session_id da sessão atual . UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:gatilho único
Para isso, precisamos do seguinte gatilho simples, que atualiza apenas
dbo.src :CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Então nosso lote só precisa atualizar as duas colunas na tabela primária:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:gatilho único nas duas tabelas
Para este teste, nosso gatilho se parece com isso:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO E agora o lote que estamos testando precisa apenas atualizar a coluna original na tabela primária; o outro é tratado pelo gatilho:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:gatilho único nas duas tabelas
Isso é como T3, mas agora o gatilho tem quatro instruções:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO O lote de teste permanece inalterado:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:dois acionadores
Aqui temos um gatilho para atualizar a tabela primária e um gatilho para atualizar a tabela secundária:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO O lote de teste é novamente muito básico:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:quatro acionadores
Desta vez temos um gatilho para cada coluna afetada; um na tabela primária e três nas tabelas secundárias.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO E o lote de teste:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Medindo o impacto da carga de trabalho
Por fim, escrevi uma consulta simples em
sys.dm_exec_query_stats para medir as leituras e a duração de cada teste:SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Resultados
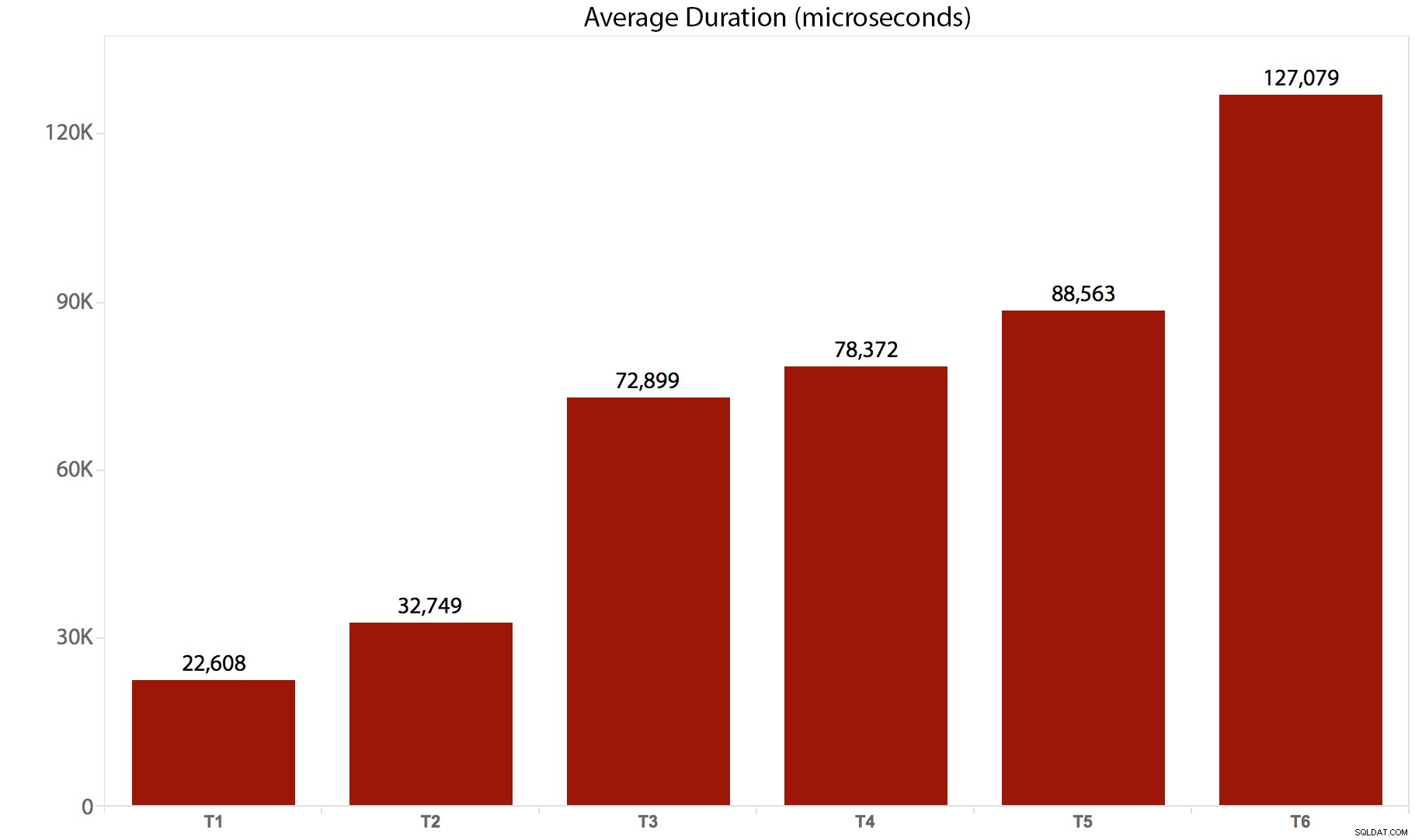
Fiz os testes 10 vezes, coletei os resultados e fiz a média de tudo. Aqui está como ele quebrou:
| Teste/Lote | Duração média (microssegundos) | Total de leituras (8 mil páginas) |
|---|---|---|
| T1 :UPDATE /*real*/ dbo.tr1 … | 22.608 | 205.134 |
| T2 :UPDATE /*real*/ dbo.tr2 … | 32.749 | 11.331.628 |
| T3 :UPDATE /*real*/ dbo.tr3 … | 72.899 | 22.838.308 |
| T4 :UPDATE /*real*/ dbo.tr4 … | 78.372 | 44.463.275 |
| T5 :UPDATE /*real*/ dbo.tr5 … | 88.563 | 41.514.778 |
| T6 :UPDATE /*real*/ dbo.tr6 … | 127.079 | 100.330.753 |
E aqui está uma representação gráfica da duração:
Conclusão
É claro que, nesse caso, há uma sobrecarga substancial para cada gatilho invocado – todos esses lotes afetaram o mesmo número de linhas, mas em alguns casos as mesmas linhas foram tocadas várias vezes. Provavelmente realizarei mais testes de acompanhamento para medir a diferença quando a mesma linha nunca é tocada mais de uma vez - um esquema mais complicado, talvez, onde 5 ou 10 outras tabelas precisam ser tocadas todas as vezes, e essas instruções diferentes podem ser em um único gatilho ou em vários. Meu palpite é que as diferenças de sobrecarga serão impulsionadas mais por coisas como simultaneidade e o número de linhas afetadas do que pela sobrecarga do próprio gatilho - mas veremos.
Quer experimentar a demonstração você mesmo? Baixe o roteiro aqui.



