Um dos casos de uso de índice filtrado mencionado nos Manuais Online diz respeito a uma coluna que contém principalmente
NULL valores. A ideia é criar um índice filtrado que exclua os NULLs , resultando em um índice não clusterizado menor que requer menos manutenção do que o índice não filtrado equivalente. Outro uso popular de índices filtrados é filtrar NULLs de um UNIQUE index, dando o comportamento que os usuários de outros mecanismos de banco de dados podem esperar de um padrão UNIQUE índice ou restrição:exclusividade sendo imposta apenas para o não-NULL valores. Infelizmente, o otimizador de consultas tem limitações no que diz respeito aos índices filtrados. Esta postagem analisa alguns exemplos menos conhecidos.
Tabelas de amostra
Usaremos duas tabelas (A e B) que têm a mesma estrutura:uma chave primária clusterizada substituta, uma chave primária
NULL coluna que é única (desconsiderando NULLs ) e uma coluna de preenchimento que representa as outras colunas que podem estar em uma tabela real. A coluna de interesse é principalmente-
NULL one, que eu declarei como SPARSE . A opção esparsa não é necessária, apenas a incluo porque não tenho muitas chances de usá-la. Em qualquer caso, SPARSE provavelmente faz sentido em muitos cenários em que se espera que os dados da coluna sejam principalmente NULL . Sinta-se à vontade para remover o atributo esparso dos exemplos, se desejar. CREATE TABLE dbo.TableA( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk integer IDENTITY PRIMARY KEY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x);
Cada tabela contém os números de 1 a 2.000 na coluna de dados com 40.000 linhas adicionais em que a coluna de dados é
NULL : -- Números 1 - 2.000INSERT dbo.TableA WITH (TABLOCKX) (data)SELECT TOP (2000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))FROM sys.columns AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER() OVER (ORDER BY (SELECT NULL)); -- NULLsINSERT TOP (40000) dbo.TableA WITH (TABLOCKX) (data)SELECT CONVERT(bigint, NULL)FROM sys.columns AS cCROSS JOIN sys.columns AS c2; -- Copiar para TableBINSERT dbo.TableB WITH (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
Ambas as tabelas recebem um
UNIQUE índice filtrado para os 2.000 não-NULL valores de dados: CRIAR ÍNDICE NÃO CLUSTERADO ÚNICO uqAON dbo.TableA (dados) WHERE data NOT NULL; CRIAR ÍNDICE NÃO CLUSTERADO ÚNICO uqBON dbo.TableB (data) WHERE data NOT NULL;
A saída de
DBCC SHOW_STATISTICS resume a situação: DBCC SHOW_STATISTICS (TabelaA, uqA) WITH STAT_HEADER;DBCC SHOW_STATISTICS (TabelaB, uqB) WITH STAT_HEADER;

Exemplo de consulta
A consulta abaixo executa uma junção simples das duas tabelas – imagine que as tabelas estão em algum tipo de relacionamento pai-filho e muitas das chaves estrangeiras são NULL. Algo nesse sentido de qualquer maneira.
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
Plano de execução padrão
Com o SQL Server em sua configuração padrão, o otimizador escolhe um plano de execução com uma junção de loops aninhados paralelos:
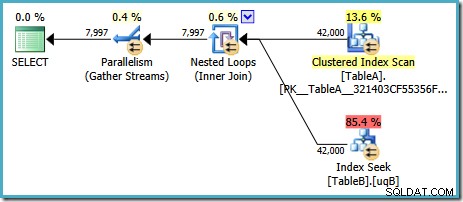
Este plano tem um custo estimado de 7,7768 magic Optimizer units™.
Há algumas coisas estranhas sobre este plano, no entanto. A Busca de Índice usa nosso índice filtrado na tabela B, mas a consulta é conduzida por uma Varredura de Índice Agrupado da tabela A. O predicado de junção é um teste de igualdade nas colunas de dados, que rejeitará
NULLs (independentemente do ANSI_NULLS contexto). Poderíamos esperar que o otimizador executasse algum raciocínio avançado com base nessa observação, mas não. Este plano lê todas as linhas da tabela A (incluindo os 40.000 NULLs ), realiza uma busca no índice filtrado na tabela B para cada um, contando com o fato de que NULL não corresponderá a NULL nessa busca. Isso é um tremendo desperdício de esforço. O estranho é que o otimizador deve ter percebido que a junção rejeita
NULLs para escolher o índice filtrado para a tabela B busca, mas não pensou em filtrar NULLs da tabela A primeiro – ou melhor ainda, simplesmente escanear o NULL - índice filtrado livre na tabela A. Você pode se perguntar se esta é uma decisão baseada em custo, talvez as estatísticas não sejam muito boas? Talvez devêssemos forçar o uso do índice filtrado com uma dica? Insinuar o índice filtrado na tabela A apenas resulta no mesmo plano com as funções invertidas – varrer a tabela B e buscar na tabela A. Forçar o índice filtrado para ambas as tabelas produz erro 8622 :o processador de consultas não pôde produzir um plano de consulta. Adicionando um predicado NOT NULL
Suspeitando que a causa tenha algo a ver com o
NULL implícito -rejeição do predicado de junção, adicionamos um NOT NULL explícito predicado para o ON cláusula (ou a cláusula WHERE cláusula se preferir, dá no mesmo aqui): SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL;
Adicionamos o
NOT NULL verifique na coluna da tabela A porque o plano original varreu o índice clusterizado dessa tabela em vez de usar nosso índice filtrado (a busca na tabela B foi boa – ela usou o índice filtrado). A nova consulta é semanticamente exatamente igual à anterior, mas o plano de execução é diferente: 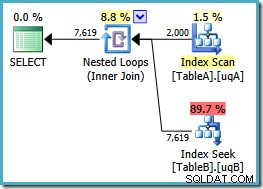
Agora temos a varredura esperada do índice filtrado na tabela A, produzindo 2.000 não
NULL linhas para direcionar as buscas de loop aninhado na tabela B. Ambas as tabelas estão usando nossos índices filtrados aparentemente de forma otimizada agora:o novo plano custa apenas 0,362835 unidades (abaixo de 7,7768). No entanto, podemos fazer melhor. Adicionando dois predicados NOT NULL
O redundante
NOT NULL predicado para a tabela A fez maravilhas; o que acontece se adicionarmos um para a tabela B também? SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL AND tb.data IS NOT NULL;
Esta consulta ainda é logicamente igual aos dois esforços anteriores, mas o plano de execução é diferente novamente:
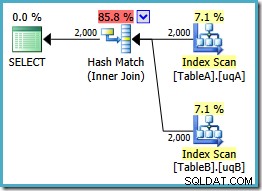
Este plano cria uma tabela de hash para as 2.000 linhas da tabela A e, em seguida, sonda as correspondências usando as 2.000 linhas da tabela B. O número estimado de linhas retornadas é muito melhor do que o plano anterior (você notou a estimativa de 7.619 lá?) e o custo de execução estimado caiu novamente, de 0,362835 para 0,0772056 .
Você pode tentar forçar uma junção de hash usando uma dica no original ou único-
NOT NULL consultas, mas você não terá o plano de baixo custo mostrado acima. O otimizador simplesmente não tem a capacidade de raciocinar completamente sobre o NULL -rejeição do comportamento da junção conforme ela se aplica aos nossos índices filtrados sem ambos os predicados redundantes. Você pode se surpreender com isso - mesmo que seja apenas a ideia de que um predicado redundante não foi suficiente (certamente se
ta.data é NOT NULL e ta.data = tb.data , segue que tb.data também é NOT NULL , certo?) Ainda não é perfeito
É um pouco surpreendente ver uma junção de hash lá. Se você está familiarizado com as principais diferenças entre os três operadores de junção física, provavelmente sabe que a junção de hash é um dos principais candidatos onde:
- A entrada pré-ordenada não está disponível
- A entrada de compilação de hash é menor que a entrada de sonda
- A entrada da sonda é muito grande
Nenhuma dessas coisas é verdade aqui. Nossa expectativa seria que o melhor plano para essa consulta e conjunto de dados fosse uma junção de mesclagem, explorando a entrada ordenada disponível de nossos dois índices filtrados. Podemos tentar sugerir uma junção de mesclagem, mantendo os dois extras
ON predicados de cláusula: SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data IS NOT NULL AND tb.data IS NOT NULLOPTION (MERGE JOIN);
A forma do plano é como esperávamos:
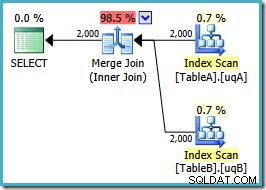
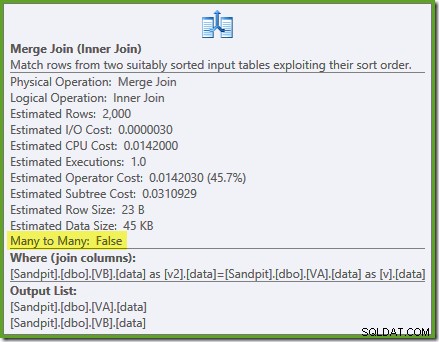
Uma varredura ordenada de ambos os índices filtrados, ótimas estimativas de cardinalidade, fantástica. Apenas um pequeno problema:este plano de execução é muito pior; o custo estimado saltou de 0,0772056 para 0,741527 . O motivo do salto no custo estimado é revelado verificando as propriedades do operador de junção de mesclagem:
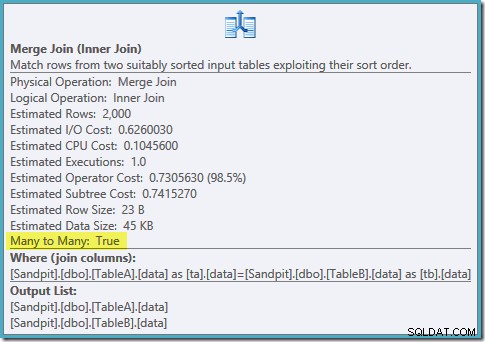
Esta é uma junção cara para muitos, onde o mecanismo de execução deve acompanhar as duplicatas da entrada externa em uma tabela de trabalho e retroceder conforme necessário. Duplicatas? Estamos digitalizando um índice exclusivo! Acontece que o otimizador não sabe que um índice exclusivo filtrado produz valores exclusivos (conecte item aqui). Na verdade, esta é uma junção um-para-um, mas o otimizador custa como se fosse muitos-para-muitos, explicando por que ele prefere o plano de junção de hash.
Uma estratégia alternativa
Parece que continuamos enfrentando limitações do otimizador ao usar índices filtrados aqui (apesar de ser um caso de uso destacado nos Manuais Online). O que acontece se tentarmos usar visualizações?
Usando visualizações
As duas visualizações a seguir apenas filtram as tabelas base para mostrar as linhas em que a coluna de dados éNOT NULL:
CREATE VIEW dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableAWHERE data IS NOT NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data IS NOT NULL;
Reescrever a consulta original para usar as visualizações é trivial:
SELECT v.data, v2.dataFROM dbo.VA AS vJOIN dbo.VB AS v2 ON v.data =v2.data;
Lembre-se de que esta consulta produziu originalmente um plano de loops aninhados paralelos com custo de 7,7768 unidades. Com as referências de visualização, obtemos este plano de execução:
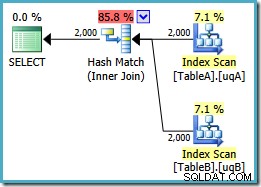
Este é exatamente o mesmo plano de junção de hash que tivemos que adicionar redundanteNOT NULLpredicados para obter com os índices filtrados (o custo é 0,0772056 unidades como antes). Isso é esperado, porque tudo o que fizemos essencialmente aqui é enviar o extraNOT NULLpredicados da consulta para uma visualização.
Indexando as visualizações
Também podemos tentar materializar as visualizações criando um índice clusterizado exclusivo na coluna pk:
CRIAR ÍNDICE AGRUPADO ÚNICO cuq EM dbo.VA (pk);CRIAR ÍNDICE AGRUPADO ÚNICO cuq EM dbo.VB (pk);
Agora podemos adicionar índices não clusterizados exclusivos na coluna de dados filtrados na exibição indexada:
CRIAR ÍNDICE NÃO CLUSTERADO EXCLUSIVO ix EM dbo.VA (dados); CRIAR ÍNDICE NÃO CLUSTRADO ÚNICO ix EM dbo.VB (dados);
Observe que a filtragem é realizada na exibição, esses índices não clusterizados não são filtrados.
O plano perfeito
Agora estamos prontos para executar nossa consulta na visualização, usando oNOEXPANDdica de tabela:
SELECT v.data, v2.dataFROM dbo.VA AS v WITH (NOEXPAND)JOIN dbo.VB AS v2 WITH (NOEXPAND) ON v.data =v2.data;
O plano de execução é:
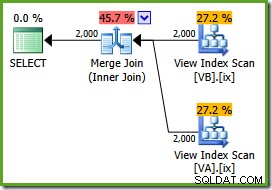
O otimizador pode ver o não filtrado índices de exibição não clusterizados são exclusivos, portanto, uma junção de mesclagem de muitos para muitos não é necessária. Este plano de execução final tem um custo estimado de 0,0310929 unidades – ainda menor que o plano de junção de hash (0,0772056 unidades). Isso valida nossa expectativa de que uma junção de mesclagem deve ter o menor custo estimado para essa consulta e conjunto de dados de amostra.
ONOEXPANDdicas são necessárias mesmo na Enterprise Edition para garantir que a garantia de exclusividade fornecida pelos índices de exibição seja usada pelo otimizador.
Resumo
Esta postagem destaca duas importantes limitações do otimizador com índices filtrados:
- Predicados de junção redundantes podem ser necessários para corresponder a índices filtrados
- Os índices exclusivos filtrados não fornecem informações de exclusividade ao otimizador
Em alguns casos, pode ser prático simplesmente adicionar os predicados redundantes a cada consulta. A alternativa é encapsular os predicados implícitos desejados em uma visão não indexada. O plano de correspondência de hash neste post foi muito melhor do que o plano padrão, mesmo que o otimizador possa encontrar o plano de junção de mesclagem um pouco melhor. Às vezes, você pode precisar indexar a visualização e usar
NOEXPAND dicas (necessárias de qualquer maneira para instâncias do Standard Edition). Ainda em outras circunstâncias, nenhuma dessas abordagens será adequada. Desculpe por isso :)