Este post tem “strings anexadas:por um bom motivo. Vamos explorar profundamente o SQL VARCHAR, o tipo de dados que lida com strings.
Além disso, isso é “apenas para os seus olhos” porque, sem cordas, não haverá postagens de blog, páginas da web, instruções de jogos, receitas marcadas e muito mais para nossos olhos lerem e desfrutarem. Lidamos com um zilhão de cordas todos os dias. Então, como desenvolvedores, você e eu somos responsáveis por tornar esse tipo de dado eficiente para armazenar e acessar.
Com isso em mente, abordaremos o que é melhor para armazenamento e desempenho. Insira o que pode e não deve fazer para este tipo de dados.
Mas antes disso, VARCHAR é apenas um dos tipos de string no SQL. O que o torna diferente?
O que é VARCHAR no SQL? (Com exemplos)
VARCHAR é um tipo de dados de string ou caractere de tamanho variável. Você pode armazenar letras, números e símbolos com ele. A partir do SQL Server 2019, você pode usar todo o intervalo de caracteres Unicode ao usar um agrupamento com suporte a UTF-8.
Você pode declarar colunas ou variáveis VARCHAR usando VARCHAR[(n)], onde n representa o tamanho da string em bytes. O intervalo de valores para n é de 1 a 8000. São muitos dados de caracteres. Mas ainda mais, você pode declará-lo usando VARCHAR(MAX) se precisar de uma string gigantesca de até 2 GB. Isso é grande o suficiente para sua lista de segredos e coisas privadas em seu diário! No entanto, observe que você também pode declará-lo sem o tamanho e o padrão é 1 se você fizer isso.
Vamos ter um exemplo.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
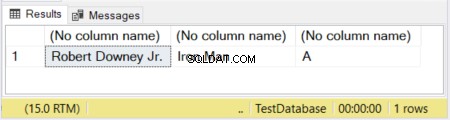
Na Figura 1, as 2 primeiras colunas têm seus tamanhos definidos. A terceira coluna fica sem tamanho. Assim, a palavra “Avengers” é truncada porque um VARCHAR sem tamanho declarado assume como padrão 1 caractere.
Agora, vamos tentar algo enorme. Mas observe que essa consulta levará um tempo para ser executada – 23 segundos no meu laptop.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
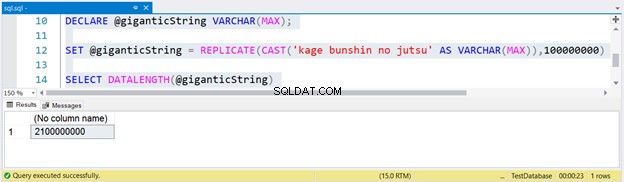
Para gerar uma sequência enorme, replicamos kage bunshin no jutsu 100 milhões de vezes. Observe o CAST em REPLICATE. Se você não converter a expressão de string para VARCHAR(MAX), o resultado será truncado para até 8.000 caracteres apenas.
Mas como o SQL VARCHAR se compara a outros tipos de dados de string?
Diferença entre CHAR e VARCHAR no SQL
Comparado com VARCHAR, CHAR é um tipo de dados de caractere de comprimento fixo. Não importa quão pequeno ou grande seja um valor que você coloque em uma variável CHAR, o tamanho final é o tamanho da variável. Confira as comparações abaixo.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
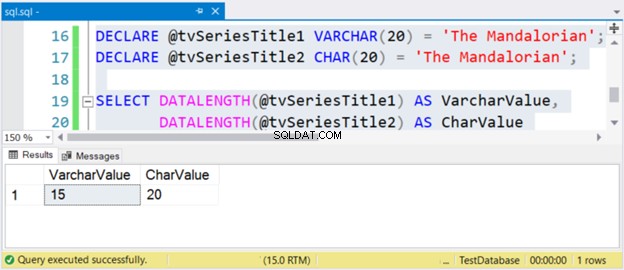
O tamanho da string “The Mandalorian” é de 15 caracteres. Portanto, o VarcharValue coluna reflete corretamente. No entanto, CharValue mantém o tamanho de 20 – é preenchido com 5 espaços à direita.
SQL VARCHAR vs NVARCHAR
Duas coisas básicas vêm à mente ao comparar esses tipos de dados.
Primeiro, é o tamanho em bytes. Cada caractere em NVARCHAR tem o dobro do tamanho de VARCHAR. NVARCHAR(n) é apenas de 1 a 4000.
Em seguida, os caracteres que ele pode armazenar. NVARCHAR pode armazenar caracteres multilíngues como coreano, japonês, árabe, etc. Se você planeja armazenar letras de K-Pop coreano em seu banco de dados, este tipo de dados é uma das suas opções.
Vamos ter um exemplo. Vamos usar o grupo K-pop 세븐틴 ou Seventeen em inglês.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
O código acima produzirá o valor da string, seu tamanho em bytes e o número de caracteres. Se forem caracteres não Unicode, o número de caracteres será igual ao tamanho em bytes. Mas este não é o caso. Confira a Figura 4 abaixo.
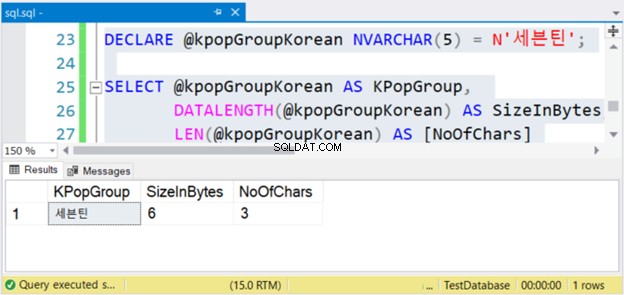
Ver? Se NVARCHAR tiver 3 caracteres, o tamanho em bytes é o dobro. Mas não com VARCHAR. O mesmo também é verdade se você usar caracteres em inglês.
Mas e o NCHAR? NCHAR é a contrapartida de CHAR para caracteres Unicode.
SQL Server VARCHAR com suporte a UTF-8
O suporte a VARCHAR com UTF-8 é possível em nível de servidor, nível de banco de dados ou nível de coluna de tabela alterando as informações de agrupamento. O agrupamento a ser usado deve oferecer suporte a UTF-8.
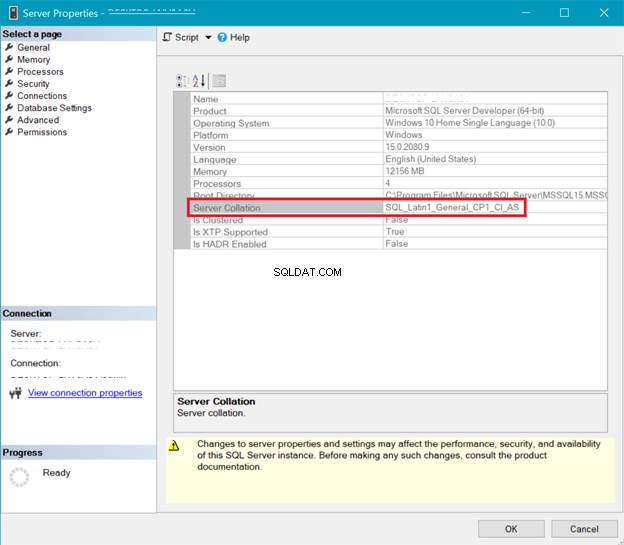
COLLATION DO SQL SERVER
A Figura 5 apresenta a janela no SQL Server Management Studio que mostra o agrupamento de servidores.
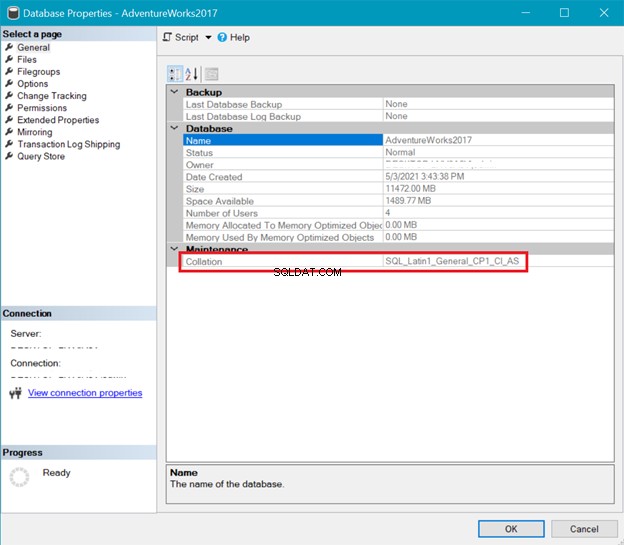
COLLATION DO BANCO DE DADOS
Enquanto isso, a Figura 6 mostra o agrupamento do AdventureWorks base de dados.
ARRUMAÇÃO DA COLUNA DA TABELA
O agrupamento de servidor e banco de dados acima mostra que não há suporte para UTF-8. A string de ordenação deve ter um _UTF8 para o suporte a UTF-8. Mas você ainda pode usar o suporte a UTF-8 no nível de coluna de uma tabela. Veja o exemplo.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
O código acima tem Latin1_General_100_BIN2_UTF8 agrupamento para o KoreanName coluna. Embora VARCHAR e não NVARCHAR, esta coluna aceitará caracteres do idioma coreano. Vamos inserir alguns registros e depois visualizá-los.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Estamos usando nomes do grupo Seventeen K-pop usando contrapartes coreanas e inglesas. Para caracteres coreanos, observe que você ainda deve prefixar o valor com N , assim como você faz com valores NVARCHAR.
Então, ao usar SELECT com ORDER BY, você também pode usar o agrupamento. Você pode observar isso no exemplo acima. Isso seguirá as regras de classificação para o agrupamento especificado.
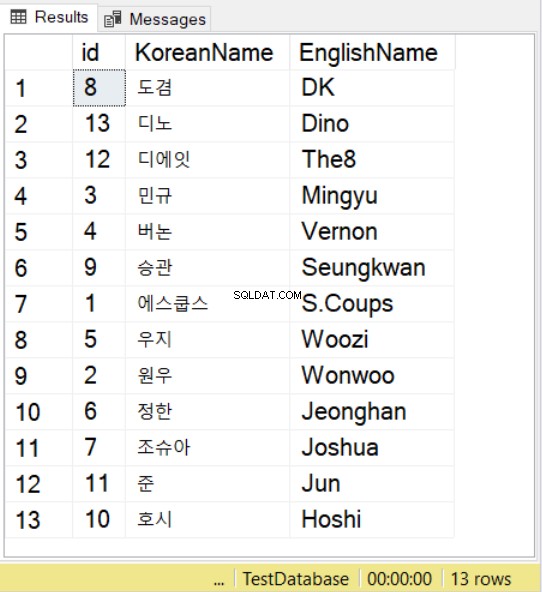
ARMAZENAMENTO DE VARCHAR COM SUPORTE UTF-8
Mas como é o armazenamento desses personagens? Se você espera 2 bytes por caractere, terá uma surpresa. Confira a Figura 8.
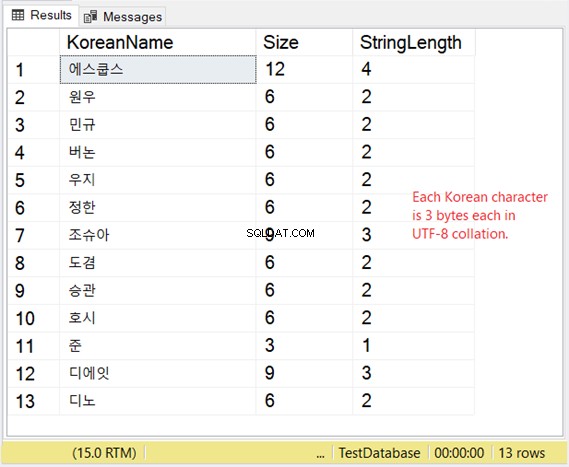
Portanto, se o armazenamento for muito importante para você, considere a tabela abaixo ao usar VARCHAR com suporte a UTF-8.
| Personagens | Tamanho em bytes |
| Ascii 0 – 127 | 1 |
| A escrita baseada em latim e grego, cirílico, copta, armênio, hebraico, árabe, siríaco, Tāna e N'Ko | 2 |
| Script do Leste Asiático, como chinês, coreano e japonês | 3 |
| Caracteres no intervalo 010000–10FFFF | 4 |
Nosso exemplo coreano é um script do leste asiático, então são 3 bytes por caractere.
Agora que terminamos de descrever e comparar VARCHAR com outros tipos de strings, vamos agora cobrir o que fazer e o que não fazer
O que fazer ao usar VARCHAR no SQL Server
1. Especifique o tamanho
O que poderia dar errado sem especificar o tamanho?
TRRUNCAMENTO DE STRING
Se você ficar preguiçoso ao especificar o tamanho, ocorrerá o truncamento da string. Você já viu um exemplo disso anteriormente.
IMPACTO DE ARMAZENAMENTO E DESEMPENHO
Outra consideração é armazenamento e desempenho. Você só precisa definir o tamanho certo para seus dados, não mais. Mas como você poderia saber? Para evitar truncamento no futuro, você pode apenas configurá-lo para o maior tamanho. Isso é VARCHAR(8000) ou mesmo VARCHAR(MAX). E 2 bytes serão armazenados como estão. Mesma coisa com 2GB. Isso importa?
Responder isso nos levará ao conceito de como o SQL Server armazena dados. Eu tenho outro artigo explicando isso em detalhes com exemplos e ilustrações.
Em suma, os dados são armazenados em páginas de 8 KB. Quando uma linha de dados excede esse tamanho, o SQL Server a move para outra unidade de alocação de página chamada ROW_OVERFLOW_DATA.
Suponha que você tenha dados VARCHAR de 2 bytes que possam caber na unidade de alocação de página original. Quando você armazena uma string maior que 8.000 bytes, os dados serão movidos para a página de estouro de linha. Em seguida, reduza-o novamente para um tamanho menor e ele será movido de volta para a página original. O movimento de vai-e-vem causa muita E/S e um gargalo de desempenho. Recuperar isso de 2 páginas em vez de 1 também precisa de E/S extra.
Outra razão é a indexação. VARCHAR(MAX) é um grande NÃO como chave de índice. Enquanto isso, VARCHAR(8000) excederá o tamanho máximo da chave de índice. Isso é 1700 bytes para índices não clusterizados e 900 bytes para índices clusterizados.
IMPACTO DA CONVERSÃO DE DADOS
No entanto, há outra consideração:conversão de dados. Experimente com um CAST sem o tamanho como o código abaixo.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Este código fará a conversão de uma data/hora com informações de fuso horário para VARCHAR.
Portanto, se ficarmos preguiçosos ao especificar o tamanho durante CAST ou CONVERT, o resultado será limitado a apenas 30 caracteres.
Que tal converter NVARCHAR para VARCHAR com suporte a UTF-8? Há uma explicação detalhada sobre isso mais tarde, então continue lendo.
2. Use VARCHAR se o tamanho da string variar consideravelmente
Nomes da AdventureWorks banco de dados variam em tamanho. Um dos nomes mais curtos é Min Su, enquanto o nome mais longo é Osarumwense Uwaifiokun Agbonile. Isso é entre 6 e 31 caracteres, incluindo os espaços. Vamos importar esses nomes em 2 tabelas e comparar entre VARCHAR e CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Qual dos 2 é melhor? Vamos verificar as leituras lógicas usando o código abaixo e inspecionando a saída de STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
Leituras lógicas:
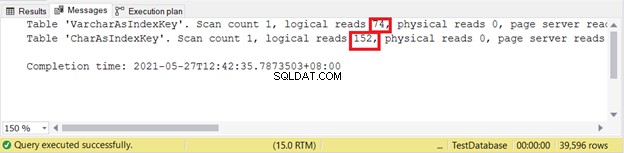
Quanto menos lógica lê, melhor. Aqui, a coluna CHAR usou mais que o dobro da contraparte VARCHAR. Assim, VARCHAR ganha neste exemplo.
3. Use VARCHAR como chave de índice em vez de CHAR quando os valores variam em tamanho
O que aconteceu quando usado como chaves de índice? O CHAR se sairá melhor que o VARCHAR? Vamos usar os mesmos dados da seção anterior e responder a esta pergunta.
Consultaremos alguns dados e verificaremos as leituras lógicas. Neste exemplo, o filtro usa a chave de índice.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Leituras lógicas:
Portanto, as chaves de índice VARCHAR são melhores do que as chaves de índice CHAR quando a chave tem tamanhos variados. Mas que tal INSERT e UPDATE que irão alterar as entradas do índice?
AO USAR INSERIR E ATUALIZAR
Vamos testar 2 casos e depois verificar as leituras lógicas como costumamos fazer.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Leituras lógicas:
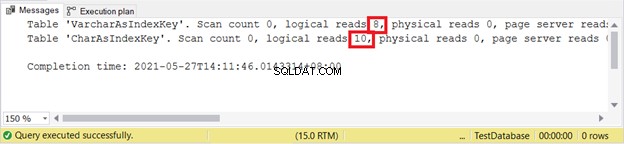
VARCHAR ainda é melhor ao inserir registros. Que tal ATUALIZAR?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Leituras lógicas:
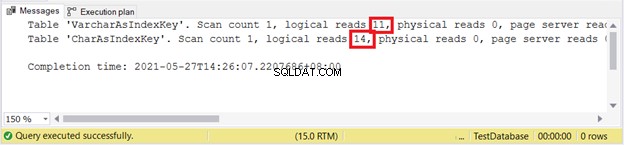
Parece que VARCHAR ganha novamente.
Eventualmente, ele vence nosso teste, embora possa ser pequeno. Você tem um caso de teste maior que prova o contrário?
4. Considere VARCHAR com suporte a UTF-8 para dados multilíngues (SQL Server 2019+)
Se houver uma mistura de caracteres Unicode e não Unicode em sua tabela, você pode considerar VARCHAR com suporte a UTF-8 sobre NVARCHAR. Se a maioria dos caracteres estiver dentro do intervalo de ASCII 0 a 127, pode oferecer economia de espaço em comparação com NVARCHAR.
Para ver o que quero dizer, vamos fazer uma comparação.
NVARCHAR PARA VARCHAR COM SUPORTE UTF-8
Você já migrou seus bancos de dados para o SQL Server 2019? Você está planejando migrar seus dados de string para o agrupamento UTF-8? Teremos um exemplo de um valor misto de caracteres japoneses e não japoneses para dar uma ideia.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Agora que os dados estão definidos, vamos inspecionar o tamanho em bytes dos 2 valores:

Surpresa! Com NVARCHAR, o tamanho é de 30 bytes. Isso é 15 vezes mais do que 2 caracteres. Mas quando convertido para VARCHAR com suporte a UTF-8, o tamanho é de apenas 27 bytes. Por que 27? Verifique como isso é calculado.

Assim, 9 dos caracteres são 1 byte cada. Isso é interessante porque, com NVARCHAR, as letras em inglês também são 2 bytes. O resto dos caracteres japoneses são 3 bytes cada.
Se forem todos os caracteres japoneses, a string de 15 caracteres teria 45 bytes e também consumiria o tamanho máximo do VarcharUTF8 coluna. Observe que o tamanho do NVarcharValue coluna é menor que VarcharUTF8 .
Os tamanhos não podem ser iguais ao converter de NVARCHAR, ou os dados podem não caber. Você pode consultar a Tabela 1 anterior.
Considere o impacto no tamanho ao converter NVARCHAR em VARCHAR com suporte a UTF-8.
Não usar VARCHAR no SQL Server
1. Quando o tamanho da string for fixo e não anulável, use CHAR em vez disso.
A regra geral quando uma string de tamanho fixo é necessária é usar CHAR. Eu sigo isso quando tenho um requisito de dados que precisa de espaços preenchidos à direita. Caso contrário, usarei VARCHAR. Eu tive alguns casos de uso quando precisei despejar strings de comprimento fixo sem delimitadores em um arquivo de texto para um cliente.
Além disso, eu uso colunas CHAR somente se as colunas não forem anuláveis. Por quê? Porque o tamanho em bytes das colunas CHAR quando NULL é igual ao tamanho definido da coluna. No entanto, VARCHAR quando NULL tem um tamanho de 1, não importa quanto seja o tamanho definido. Execute o código abaixo e veja por si mesmo.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Não use VARCHAR(n) se n Excederá 8000 Bytes. Use VARCHAR(MAX) em vez disso.
Você tem uma string que excederá 8000 bytes? Este é o momento de usar VARCHAR(MAX). Mas para as formas mais comuns de dados, como nomes e endereços, VARCHAR(MAX) é um exagero e afetará o desempenho. Na minha experiência pessoal, não me lembro de um requisito que usei VARCHAR(MAX).
3. Ao usar caracteres multilíngues com o SQL Server 2017 e abaixo. Use NVARCHAR em vez disso.
Essa é uma escolha óbvia se você ainda usa o SQL Server 2017 e inferior.
O resultado final
O tipo de dados VARCHAR nos serviu bem para muitos aspectos. Isso aconteceu comigo desde o SQL Server 7. No entanto, às vezes, ainda fazemos escolhas ruins. Neste post, SQL VARCHAR é definido e comparado a outros tipos de dados de string com exemplos. E, novamente, aqui estão os prós e contras para um banco de dados mais rápido:
Faça:
- Especifique o tamanho n em VARCHAR[(n)] mesmo que seja opcional.
- Use-o quando o tamanho da string variar consideravelmente.
- Considere as colunas VARCHAR como chaves de índice em vez de CHAR.
- E se você estiver usando o SQL Server 2019, considere VARCHAR para strings multilíngues com suporte a UTF-8.
Não é:
- Não use VARCHAR quando o tamanho da string for fixo e não anulável.
- Não use VARCHAR(n) quando o tamanho da string exceder 8.000 bytes.
- E não use VARCHAR para dados multilíngues ao usar o SQL Server 2017 e versões anteriores.
Você tem alguma coisa a mais a acrescentar? Deixe-nos saber na seção de comentários. Se você acha que isso ajudará seus amigos desenvolvedores, compartilhe isso em suas plataformas de mídia social favoritas.