Para qualquer novo banco de dados criado no SQL Server, o valor padrão da opção Estatísticas de atualização automática é ativado . Suspeito que a maioria dos DBAs deixa a opção habilitada, pois permite que o otimizador atualize automaticamente as estatísticas quando elas são invalidadas, e geralmente é recomendável deixá-la habilitada. As estatísticas também são atualizadas quando os índices são reconstruídos e, embora não seja incomum que as estatísticas sejam bem gerenciadas por meio da opção de estatísticas de atualização automática e por meio de recompilações de índice, de tempos em tempos um DBA pode achar necessário configurar um trabalho regular para atualizar um estatística ou conjunto de estatísticas.
O gerenciamento personalizado de estatísticas geralmente envolve o comando UPDATE STATISTICS, que parece bastante benigno. Ele pode ser executado para todas as estatísticas de uma tabela ou exibição indexada ou para uma estatística específica. A amostra padrão pode ser usada, uma taxa de amostragem específica ou um número de linhas para amostrar podem ser especificados ou você pode usar o mesmo valor de amostra que foi usado anteriormente. Se as estatísticas forem atualizadas para uma tabela ou exibição indexada, você poderá optar por atualizar todas as estatísticas, apenas estatísticas de índice ou apenas estatísticas de coluna. E, finalmente, você pode desativar a opção de estatísticas de atualização automática para uma estatística.
Para a maioria dos DBAs, a maior consideração pode ser quando para executar a instrução UPDATE STATISTICS. Mas os DBAs também decidem, conscientemente ou não, o tamanho da amostra para a atualização. O tamanho da amostra selecionado pode afetar o desempenho da atualização real, bem como o desempenho das consultas.
Compreendendo os efeitos do tamanho da amostra
O tamanho da amostra padrão para UPDATE STATISTICS vem de um algoritmo não linear, e o tamanho da amostra diminui à medida que o tamanho da tabela aumenta, como Joe Sack mostrou em seu post Auto-Update Stats Default Sampling Test. Em alguns casos, o tamanho da amostra pode não ser grande o suficiente para capturar informações interessantes o suficiente ou o certo informações, para o histograma de estatísticas, conforme observado por Conor Cunningham em seu post Statistics Sample Rates. Se a amostra padrão não criar um bom histograma, os DBAs podem optar por atualizar as estatísticas com uma taxa de amostragem mais alta, até um FULLSCAN (varrendo todas as linhas na tabela ou exibição indexada). Mas, como Conor mencionou em seu post, a varredura de mais linhas tem um custo, e o DBA é desafiado a decidir se deve executar um FULLSCAN para tentar criar o “melhor” histograma possível ou amostrar uma porcentagem menor para minimizar o impacto no desempenho de a atualização.
Para tentar entender em que ponto uma amostra demora mais do que um FULLSCAN, executei as seguintes instruções em cópias da tabela SalesOrderDetail que foram ampliadas usando o script de Jonathan Kehayias:
| ID do extrato | instrução ATUALIZAR ESTATÍSTICAS |
|---|---|
| 1 | ATUALIZAR ESTATÍSTICAS [Vendas].[SalesOrderDetailEnlarged] COM FULLSCAN; |
| 2 | ATUALIZAR ESTATÍSTICAS [Vendas].[SalesOrderDetailEnlarged]; |
| 3 | ATUALIZAR ESTATÍSTICAS [Vendas].[SalesOrderDetailEnlarged] COM AMOSTRA 10 POR CENTO; |
| 4 | ATUALIZAR ESTATÍSTICAS [Vendas].[SalesOrderDetailEnlarged] COM AMOSTRA 25 POR CENTO; |
| 5 | ATUALIZAR ESTATÍSTICAS [Vendas].[SalesOrderDetailEnlarged] COM AMOSTRA 50 POR CENTO; |
| 6 | ATUALIZAR ESTATÍSTICAS [Vendas].[SalesOrderDetailEnlarged] COM AMOSTRA 75 POR CENTO; |
Eu tinha três cópias da tabela SalesOrderDetailEnlarged, com as seguintes características*:
| Contagem de linhas | Contagem de páginas | MAXDOP | Memória máxima | Armazenamento | Máquina |
|---|---|---|---|---|---|
| 23.899.449 | 363.284 | 4 | 8 GB | SSD_1 | Computador portátil |
| 607.312.902 | 7.757.200 | 16 | 54 GB | SSD_2 | Servidor de teste |
| 607.312.902 | 7.757.200 | 16 | 54 GB | 15K | Servidor de teste |
*Os detalhes adicionais sobre o hardware estão no final desta postagem.
Todas as cópias da tabela tinham as seguintes estatísticas e nenhuma das três estatísticas de índice incluía colunas:
| Estatística | Tipo | Colunas na chave |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Índice | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Índice | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Índice | ProductId |
| user_CarrierTrackingNumber | Coluna | CarrierTrackingNumber |
Eu executei as instruções UPDATE STATISTICS acima quatro vezes cada na tabela SalesOrderDetailEnlarged no meu laptop e duas vezes cada nas tabelas SalesOrderDetailEnlarged no TestServer. As instruções eram executadas em ordem aleatória a cada vez, e o cache de procedimento e o cache de buffer eram limpos antes de cada instrução de atualização. A duração e o uso do tempdb para cada conjunto de instruções (média) estão nos gráficos abaixo:
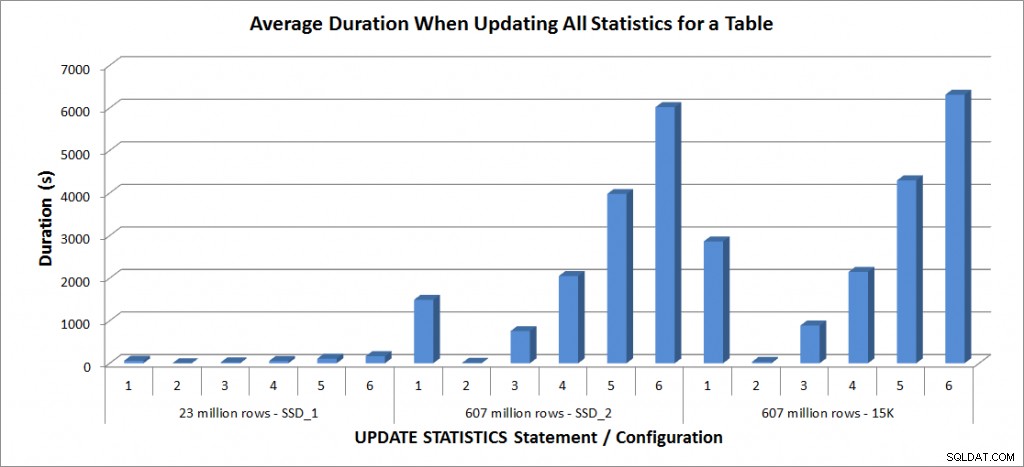
Duração média – atualizar todas as estatísticas para SalesOrderDetailEnlarged
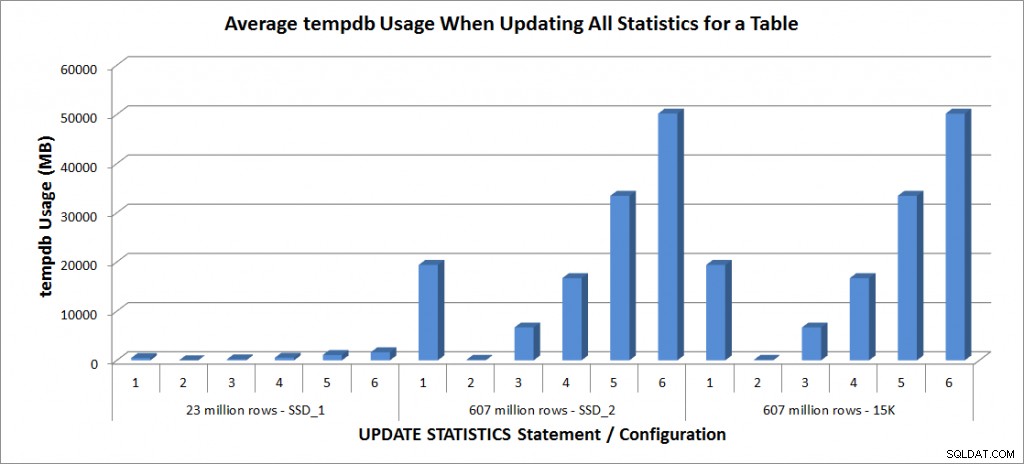
Uso de tempdb – Atualizar todas as estatísticas para SalesOrderDetailEnlarged
As durações da tabela de 23 milhões de linhas foram todas inferiores a três minutos e são descritas com mais detalhes na próxima seção. Para a tabela nos discos SSD_2, a instrução FULLSCAN levou 1.492 segundos (quase 25 minutos) e a atualização com uma amostra de 25% levou 2.051 segundos (mais de 34 minutos). Em contraste, nos discos de 15K, a instrução FULLSCAN levou 2864 segundos (mais de 47 minutos) e a atualização com uma amostra de 25% levou 2147 segundos (quase 36 minutos) – menos que o FULLSCAN. No entanto, a atualização com uma amostra de 50% levou 4296 segundos (mais de 71 minutos).
O uso de tempdb é muito mais consistente, mostrando um aumento constante à medida que o tamanho da amostra aumenta e usando mais espaço de tempdb do que um FULLSCAN em algum lugar entre 25% e 50%. O que é notável aqui é que ATUALIZAR ESTATÍSTICAS faz usar tempdb, que é importante lembrar ao dimensionar tempdb para um ambiente SQL Server. O uso do Tempdb é mencionado na entrada UPDATE STATISTICS BOL:
UPDATE STATISTICS pode usar tempdb para classificar a amostra de linhas para criar estatísticas.”
E o efeito está documentado no post de Linchi Shea, Impacto no desempenho:tempdb e estatísticas de atualização. No entanto, nem sempre é algo mencionado durante as discussões de dimensionamento de tempdb. Se você tiver tabelas grandes e realizar atualizações com FULLSCAN ou valores de amostra altos, esteja ciente do uso de tempdb.
Desempenho de atualizações seletivas
Em seguida, decidi testar as instruções UPDATE STATISTICS para as outras estatísticas da tabela, mas limitei meus testes à cópia da tabela com 23 milhões de linhas. As seis variações acima da instrução UPDATE STATISTICS foram repetidas quatro vezes cada uma para as seguintes estatísticas individuais e depois comparadas com a atualização de toda a tabela:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Todos os testes foram executados com a configuração mencionada no meu laptop, e os resultados estão no gráfico abaixo:
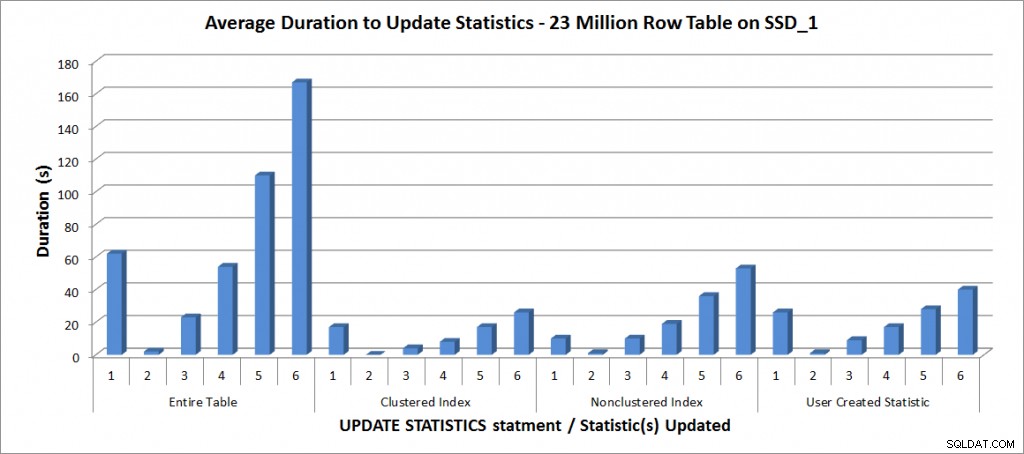
Duração média para ATUALIZAR ESTATÍSTICAS - Todas as estatísticas vs. selecionadas
Conforme esperado, as atualizações de uma estatística individual levaram menos tempo do que ao atualizar todas as estatísticas da tabela. O valor em que a atualização amostrada demorou mais do que um FULLSCAN variou:
| instrução UPDATE | Duração(ões) de FULLSCAN | Primeira ATUALIZAÇÃO que demorou mais |
|---|---|---|
| Tabela inteira | 62 | 50% – 110 segundos |
| Índice agrupado | 17 | 75% – 26 segundos |
| Índice não clusterizado | 10 | 25% – 19 segundos |
| Estatística criada pelo usuário | 26 | 50% – 28 segundos |
Conclusão
Com base nesses dados e nos dados FULLSCAN das tabelas de 607 milhões de linhas, não há específico ponto de inflexão em que uma atualização de amostra demora mais do que um FULLSCAN; esse ponto depende do tamanho da tabela e dos recursos disponíveis. Mas os dados ainda valem a pena, pois demonstram que existe um ponto em que um valor amostrado pode demorar mais para ser capturado do que um FULLSCAN. Novamente, tudo se resume a conhecer seus dados. Isso é fundamental não apenas para entender se uma tabela precisa de gerenciamento personalizado de estatísticas, mas também para entender o tamanho ideal da amostra para criar um histograma útil e também otimizar o uso de recursos.
Especificações
Especificações do laptop:Dell M6500, 1 Intel i7 (2,13 GHz 4 núcleos e HT habilitado para 8 núcleos lógicos), 32 GB de memória, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), arquivos de banco de dados armazenados em um SSD Samsung de 265 GB PM810Especificações do servidor de teste:Dell R720, 2 Intel E5-2670 (2,6 GHz 8 núcleos e HT habilitado para 16 núcleos lógicos por soquete), 64 GB de memória, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), arquivos de banco de dados para uma tabela está localizada em duas placas MLC Fusion-io Duo de 640 GB, os arquivos de banco de dados da outra tabela estão em nove discos de 15 K RPM em uma matriz RAID5