O Banco de Dados SQL do Azure é a oferta de banco de dados como serviço da Microsoft que oferece uma enorme flexibilidade e segurança e, como parte da Plataforma como serviço da Microsoft, aproveita recursos adicionais. Como o Banco de Dados SQL do Azure tem escopo de banco de dados, há algumas grandes diferenças quando se trata de ajuste de desempenho.
Ajustando a instância
Muitos itens de nível de instância que você costumava configurar em instalações completas estão fora dos limites. Alguns desses itens incluem:
- Configurando a memória mínima e máxima do servidor
- Como ativar a otimização para cargas de trabalho ad hoc
- Alteração do limite de custo para paralelismo
- Alterando o grau máximo de paralelismo no nível da instância
- Otimizando o tempdb com vários arquivos de dados
- Sinalizadores de rastreamento
Não fique muito chateado com alguns deles. A instrução ALTER DATABASE SCOPED CONFIGURATION permite algumas definições de configuração no nível de banco de dados individual. Isso foi introduzido com o Banco de Dados SQL do Azure e no SQL Server a partir do SQL Server 2016. Algumas dessas configurações incluem:
- Limpar o cache do procedimento
- Definindo o MAXDOP com um valor diferente de zero
- Defina o modelo de estimativa de cardinalidade do otimizador de consulta
- Ativar ou desativar hotfixes de otimização de consulta
- Ativar ou desativar a detecção de parâmetros
- Ative ou desative o cache de identidade
- Habilite ou desabilite um stub de plano compilado para ser armazenado em cache quando um lote for compilado pela primeira vez.
- Habilite ou desabilite a coleta de estatísticas de execução para módulos T-SQL compilados nativamente.
- Habilite ou desabilite online por opções padrão para instruções DDL que suportam a sintaxe ONLINE=ON/OFF.
- Ative ou desative as opções retomáveis por padrão para instruções DDL que suportam a sintaxe RESUMABLE=ON/OFF.
- Ative ou desative a funcionalidade de descarte automático de tabelas temporárias globais
Como você pode ver na lista de configurações com escopo, você tem muito controle e precisão para ajustar comportamentos específicos para bancos de dados individuais. Para alguns clientes, as limitações do controle em nível de instância podem ter um impacto negativo, enquanto outros verão isso como um benefício.
Para empresas que possuem um banco de dados por cliente, que precisam de isolamento completo, integrado ao Banco de Dados SQL do Azure. Para aqueles que precisam dos recursos de nível de instância do SQL Server, mas gostariam de aproveitar a oferta de PaaS da Microsoft, existe o Azure SQL Managed Instance, que tem escopo de instância. O objetivo é ter 100% de compatibilidade de área de superfície com o SQL Server; assim, você pode definir a memória mínima e máxima do servidor, habilitar a otimização para cargas de trabalho ad hoc e alterar o MAXDOP e o limite de custo para paralelismo. Tempdb em uma instância gerenciada já tem vários arquivos, mas você pode adicionar mais e aumentar o tamanho padrão. De muitas maneiras, realmente parece a instalação completa do SQL Server.
Ajuste de consulta
Outra diferença entre o Banco de Dados SQL do Azure e o SQL Server é que o Repositório de Consultas é habilitado por padrão no Banco de Dados SQL do Azure. Você pode desativar o Repositório de Consultas, mas limita as ferramentas de Desempenho Inteligente no Portal do Azure que o utilizam. O Repositório de Consultas é um recurso que fornece informações sobre o desempenho da consulta e a escolha do plano. O Repositório de Consultas também captura um histórico de consultas, planos e estatísticas de tempo de execução para que você possa revisar o que está acontecendo. Você quer saber qual consulta tem o maior tempo de recompilação, tempo de execução, contagem de execução, uso de CPU, uso de memória, mais leituras/gravações físicas e muito mais? O Query Store tem essas informações. Para SQL Server, você deve habilitar esse recurso por banco de dados. Se você é novo no Query Store, minha colega Erin Stellato tem um curso de três horas no Pluralsight que o ajudará a começar.
A categoria de ferramentas de desempenho inteligente tem quatro recursos. Em primeiro lugar, a visão geral do desempenho fornece um resumo do desempenho geral do banco de dados listando as 5 principais consultas por consumo de CPU, quaisquer recomendações de ajuste automático, atividade de ajuste e configurações atuais de ajuste automático. Esta página de destino fornece uma visão rápida do seu desempenho.
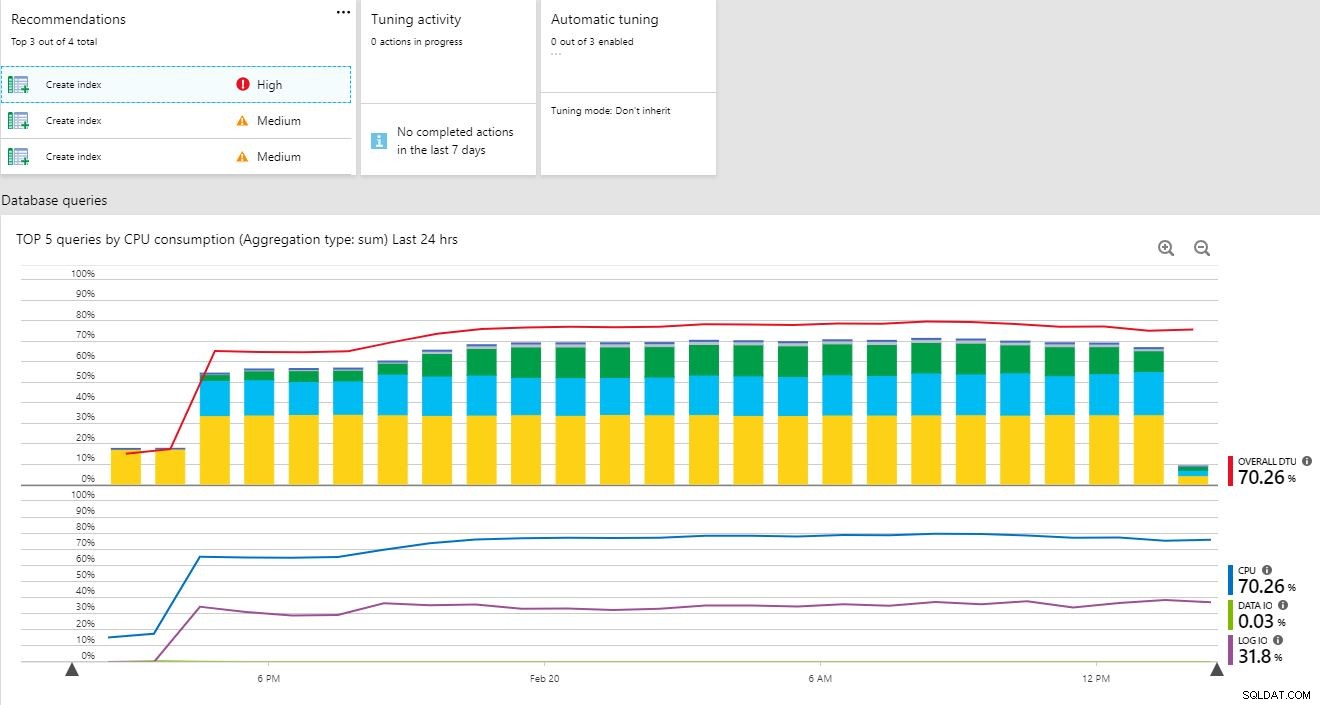
Em segundo lugar, a opção de recomendações de desempenho listará todas as recomendações atuais para criações de índice ou se algum índice deve ser descartado. Se alguma ação recente foi concluída, você também verá o histórico.
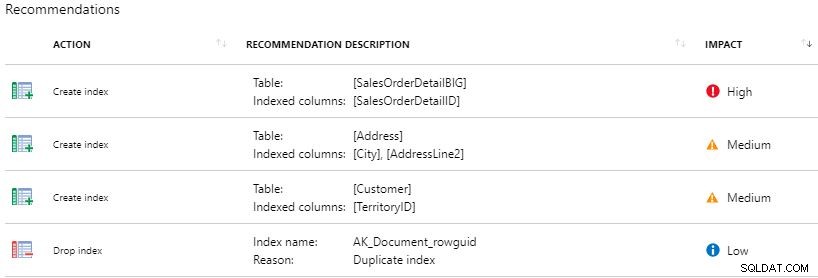
Em terceiro lugar, o Query Performance Insight é onde você pode encontrar uma visão mais profunda do consumo de recursos visualizando as 5 principais consultas por CPU, E/S de dados ou E/S de log. As 5 principais consultas são codificadas por cores para que você possa ver visualmente a porcentagem do consumo geral. Você pode clicar no id da consulta para obter mais detalhes, incluindo o texto SQL. Há também uma guia de consultas de longa duração. Eu realmente gosto que a Microsoft tenha incluído um recurso como esse no Portal do Azure sem nenhum custo. Ele fornece valor ao oferecer aos clientes um portal para ver as principais consultas ofensivas. O que acho desafiador aqui é ter uma maneira de ver uma linha de base geral para comparação de dia a dia, semana a semana e mês anterior. No entanto, para uma análise e visão geral rápidas, o Query Performance Insight é útil.
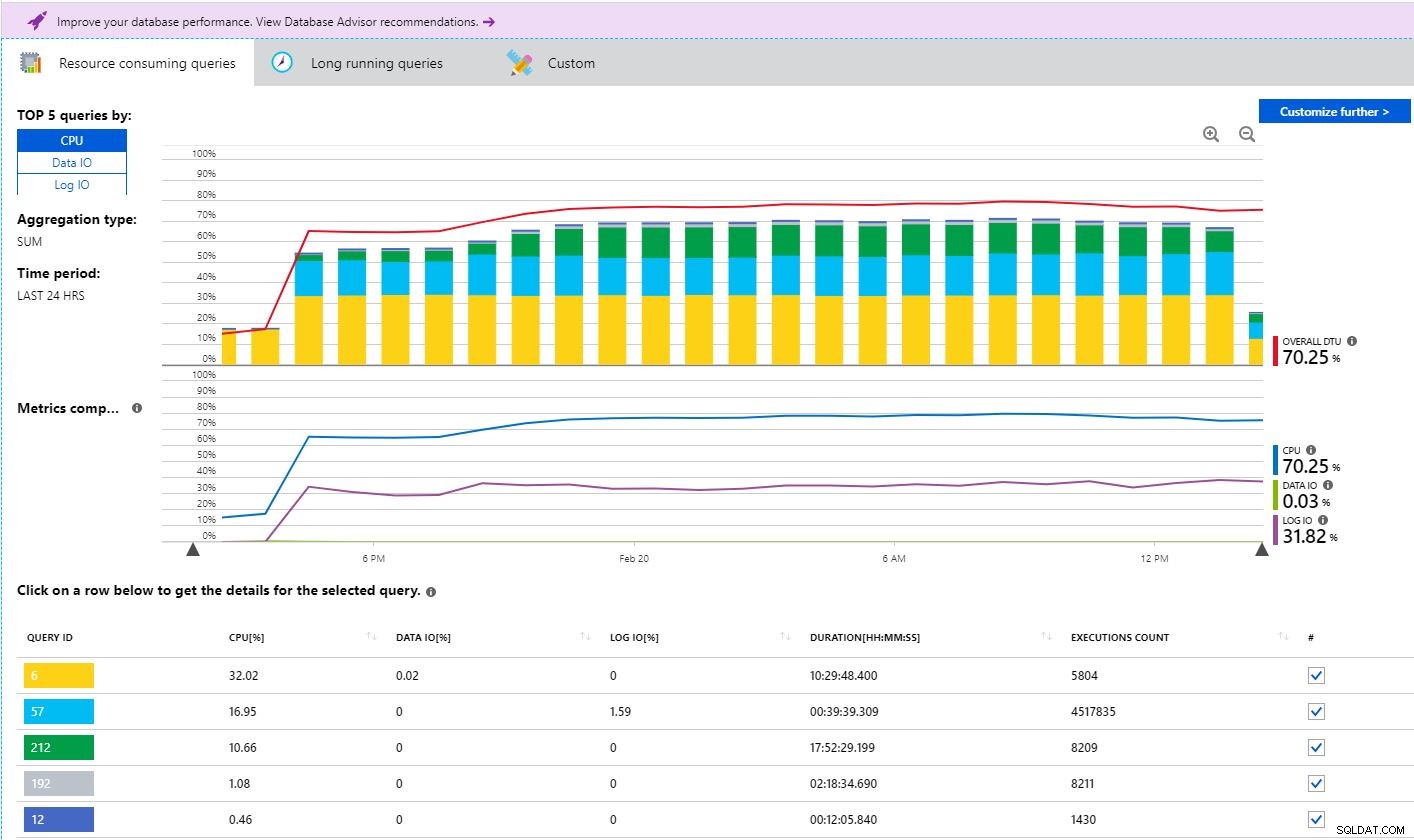
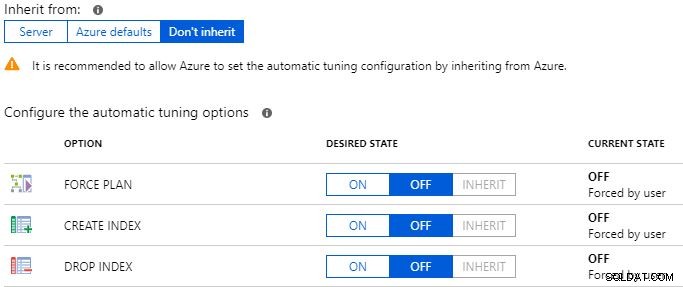
O recurso final nesta categoria é o ajuste automático. É aqui que você pode configurar o plano de força, criar índice e descartar as configurações de índice. Você pode forçá-lo, desativá-lo ou optar por herdar do servidor. O plano de força permite que o Azure escolha o que parece ser o melhor dos planos de execução para consultas regredidas. Esse recurso também existe no SQL Server 2017 Enterprise Edition como correção automática de plano. Alguns DBAs ficam nervosos quando ouvem falar dos recursos de ajuste automático, pois temem que isso possa substituir a necessidade de DBAs no futuro. Eu sempre gosto de fazer a pergunta:“Quanto tempo por dia você gasta proativamente ajustando as consultas?”. A resposta esmagadora é que as pessoas podem realmente gastar muito pouco tempo ajustando proativamente, e a maioria responde que a única vez que eles realmente “ajustam” é após o lançamento de um código ou quando os usuários começam a reclamar.
Além das ferramentas internas e do valor de usar o Query Store, os DMVs também estão prontamente disponíveis. Glenn Berry tem uma coleção inteira de scripts apenas para o Banco de Dados SQL do Azure que você pode utilizar. Um DMV em particular que eu quero chamar é sys.dm_os_wait_stats. Isso será extraído do nível do servidor, portanto, se você realmente quiser ver as estatísticas de espera para o nível do banco de dados, precisará usar sys.dm_db_wait_stats.
Hardware – Dimensionamento
Outra área de consideração ao analisar o desempenho com o Banco de Dados SQL do Azure é o hardware subjacente. O Banco de Dados SQL do Azure é cobrado por Unidades de Transação de Banco de Dados (DTUs) e vCores. As DTUs são uma medida combinada de CPU, memória e E/S e vêm em três camadas; Básico, Padrão e Premium. O básico é de apenas 5 DTUs, o padrão varia de 10 a 3.000 DTUs e o Premium varia de 125 a 4.000 DTUs. Para as camadas baseadas em vCore, temos Uso geral e Negócios críticos que variam de 1 a 80 vCores.
No modelo DTU, o Basic deve ser considerado para desenvolvimento e teste. Ele só tem uma retenção de backup de 7 dias, então não considero viável para nenhum dado de produção. Padrão é bom para demanda de CPU baixa, média e alta com demanda de E/S moderada a baixa. O nível Básico e Padrão oferece 2,5 IOPS por DTU com 5 ms (leitura), 10 ms (gravação). A camada Premium é para demanda de CPU média a alta e E/S alta, oferecendo 48 IOPS por DTU com 2 ms (leitura/gravação). A camada Premium tem armazenamento que é muito mais rápido que o padrão. No modelo vCore, você tem processadores Gen4 que oferecem 7 GB de RAM por núcleo físico e processadores Gen 5 que oferecem 5,1 GB de RAM por núcleo lógico. De uma perspectiva de E/S, o General Purpose oferece 500 IOPS por vCore com um máx. de 7.000 IOPS. A Business Critical oferece 5.000 IOPS por núcleo com um máximo de 200.000 IOPS.
Resumo
O Banco de Dados SQL do Azure é ótimo para os sistemas que precisam de isolamento de banco de dados, enquanto a Instância Gerenciada do SQL do Azure é ótima para os ambientes em que você precisa de compatibilidade em nível de instância (suporte a consultas entre bancos de dados). Quando você precisa ajustar o Banco de Dados SQL do Azure, deve fazer as coisas no nível do banco de dados, pois as opções no nível da instância estão fora dos limites, portanto, as definições de configuração no escopo do banco de dados são suas opções de ajuste fino. Com a solução de problemas de consultas de baixo desempenho, você tem algumas ferramentas internas que ajudam, incluindo o Query Store, e a maioria dos seus scripts de ajuste regulares funcionará. Você pode achar que ainda precisa de mais, como linhas de base, mais dados históricos e a capacidade de criar condições de consultoria para ajudá-lo a gerenciar suas cargas de trabalho. É aqui que soluções de monitoramento poderosas como o SentryOne DB Sentry podem ajudar.
Quando tudo mais falhar, ou sua carga de trabalho simplesmente aumentou além dos recursos de hardware atuais, dimensione para um nível mais alto.