Introdução
Desde sua introdução no SQL Server 2005, as funções de janela como
ROW_NUMBER e RANK provaram ser extremamente úteis na solução de uma ampla variedade de problemas comuns de T-SQL. Em uma tentativa de generalizar essas soluções, os designers de banco de dados geralmente procuram incorporá-las às visualizações para promover o encapsulamento e a reutilização do código. Infelizmente, uma limitação no otimizador de consulta do SQL Server geralmente significa que as exibições que contêm funções de janela não funcionam tão bem quanto o esperado. Esta postagem funciona com um exemplo ilustrativo do problema, detalha os motivos e fornece várias soluções alternativas. Esse problema também pode ocorrer em tabelas derivadas, expressões de tabela comuns e funções em linha, mas eu o vejo com mais frequência com visualizações porque elas são escritas intencionalmente para serem mais genéricas.
Funções da janela
As funções de janela são distinguidas pela presença de um
OVER() cláusula e vêm em três variedades:- Funções da janela de classificação
ROW_NUMBERRANKDENSE_RANKNTILE
- Funções de janela agregadas
MIN,MAX,AVG,SUMCOUNT,COUNT_BIGCHECKSUM_AGGSTDEV,STDEVP,VAR,VARP
- Funções da janela analítica
LAG,LEADFIRST_VALUE,LAST_VALUEPERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC,CUME_DIST
As funções de classificação e de janela agregada foram introduzidas no SQL Server 2005 e consideravelmente estendidas no SQL Server 2012. As funções de janela analítica são novas no SQL Server 2012.
Todas as funções de janela listadas acima são suscetíveis à limitação do otimizador detalhada neste artigo.
Exemplo
Usando o banco de dados de exemplo AdventureWorks, a tarefa em mãos é escrever uma consulta que retorne todas as transações do produto nº 878 que ocorreram na data mais recente disponível. Existem várias maneiras de expressar esse requisito em T-SQL, mas escolheremos escrever uma consulta que use uma função de janela. O primeiro passo é encontrar registros de transações para o produto nº 878 e classificá-los em ordem decrescente de data:
SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( ORDER BY th.TransactionDate DESC)FROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY rnk;
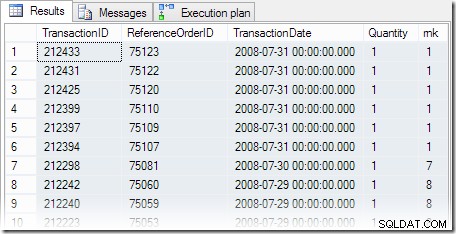

Os resultados da consulta são os esperados, com seis transações ocorrendo na data mais recente disponível. O plano de execução contém um triângulo de aviso, alertando-nos para um índice ausente:

Como de costume para sugestões de índices ausentes, precisamos lembrar que a recomendação não é resultado de uma análise minuciosa da consulta – é mais uma indicação de que precisamos pensar um pouco sobre como essa consulta acessa os dados de que precisa.
O índice sugerido certamente seria mais eficiente do que escanear a tabela completamente, pois permitiria uma busca de índice para o produto específico que nos interessa. O índice também cobriria todas as colunas necessárias, mas não evitaria a ordenação (porTransactionDatedescendente). O índice ideal para esta consulta permitiria uma busca emProductID, retorna os registros selecionados emTransactionDatereverso order e cubra as outras colunas retornadas:
CRIAR ÍNDICE NÃO CLUSTERADO ixON Production.TransactionHistory (ProductID, TransactionDate DESC)INCLUDE (ReferenceOrderID, Quantity);
Com esse índice em vigor, o plano de execução é muito mais eficiente. A varredura de índice clusterizado foi substituída por uma busca de intervalo e uma classificação explícita não é mais necessária:

A etapa final para essa consulta é limitar os resultados apenas às linhas classificadas como #1. Não podemos filtrar diretamente noWHEREcláusula de nossa consulta porque as funções da janela só podem aparecer noSELECTeORDER BYcláusulas.
Podemos contornar essa restrição usando uma tabela derivada, expressão de tabela comum, função ou exibição. Nesta ocasião, usaremos uma expressão de tabela comum (também conhecida como visualização em linha):
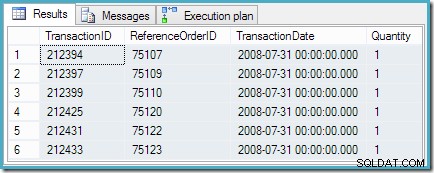
COM transações classificadas AS( SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( ORDER BY th.TransactionDate DESC) FROM Production.TransactionHistory AS th WHERE th.ProductID =878 )SELECT TransactionID, ReferenceOrderID, TransactionDate, QuantityFROM RankedTransactionsWHERE rnk =1;
O plano de execução é o mesmo de antes, com um filtro extra para retornar apenas as linhas classificadas como #1:

A consulta retorna as seis linhas igualmente classificadas que esperamos:
Generalizando a consulta
Acontece que nossa consulta é muito útil, então é tomada a decisão de generalizá-la e armazenar a definição em uma visão. Para que isso funcione para qualquer produto, precisamos fazer duas coisas:retornar oProductIDda visualização e particione a função de classificação por produto:
CREATE VIEW dbo.MostRecentTransactionsPerProductWITH SCHEMABINDINGASSELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.QuantityFROM ( SELECT th.ProductID, th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( PARTITION BY th.ProductID ORDER POR th.TransactionDate DESC) FROM Production.TransactionHistory AS th) AS sq1WHERE sq1.rnk =1;
A seleção de todas as linhas da visualização resulta no seguinte plano de execução e resultados corretos:

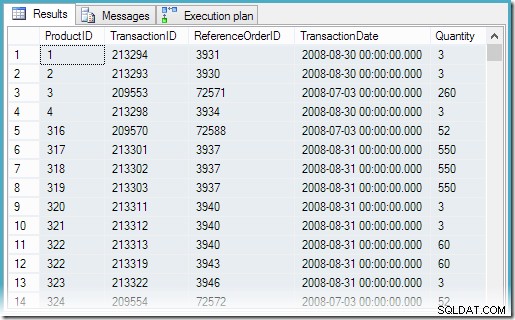
Agora podemos encontrar as transações mais recentes do produto 878 com uma consulta muito mais simples na visualização:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;
Nossa expectativa é que o plano de execução para essa nova consulta seja exatamente o mesmo de antes de criarmos a visualização. O otimizador de consulta deve ser capaz de enviar o filtro especificado emWHEREcláusula para baixo na exibição, resultando em uma busca de índice.
Precisamos parar e pensar um pouco neste momento, no entanto. O otimizador de consulta só pode produzir planos de execução que garantem produzir os mesmos resultados que a especificação de consulta lógica – é seguro enviar nossoWHEREcláusula na exibição?PARTITION BY cláusula da função de janela na exibição. O raciocínio é que eliminar grupos completos (partições) da função de janela não afetará a classificação das linhas retornadas pela consulta. A questão é:o otimizador de consultas do SQL Server sabe disso? A resposta depende de qual versão do SQL Server estamos executando.
Plano de execução do SQL Server 2005

Uma olhada nas propriedades do filtro neste plano mostra a aplicação de dois predicados:
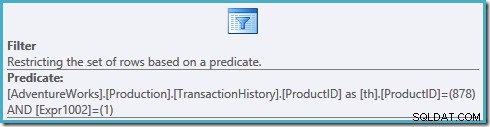
OProductID = 878o predicado não foi empurrado para baixo na exibição, resultando em um plano que verifica nosso índice, classificando cada linha na tabela antes de filtrar o produto nº 878 e as linhas classificadas como nº 1.
O otimizador de consulta do SQL Server 2005 não pode enviar predicados adequados além de uma função de janela em um escopo de consulta inferior (exibição, expressão de tabela comum, função em linha ou tabela derivada). Essa limitação se aplica a todas as compilações do SQL Server 2005.
Plano de execução do SQL Server 2008+
Este é o plano de execução para a mesma consulta no SQL Server 2008 ou posterior:

OProductIDo predicado foi empurrado com sucesso pelos operadores de classificação, substituindo a varredura de índice pela busca de índice eficiente.
O otimizador de consulta de 2008 inclui uma nova regra de simplificaçãoSelOnSeqPrj(selecione no projeto de sequência) que é capaz de enviar predicados de escopo externo seguros para além das funções da janela. Para produzir o plano menos eficiente para essa consulta no SQL Server 2008 ou posterior, precisamos desabilitar temporariamente esse recurso de otimizador de consulta:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878OPTION (QUERYRULEOFF SelOnSeqPrj);

Infelizmente, oSelOnSeqPrjregra de simplificação só funciona quando o predicado realiza uma comparação com uma constante . Por esse motivo, a consulta a seguir produz o plano abaixo do ideal no SQL Server 2008 e posterior:
DECLARE @ProductID INT =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;

O problema ainda pode ocorrer mesmo quando o predicado usa um valor constante. O SQL Server pode decidir parametrizar automaticamente consultas triviais (uma para a qual existe um melhor plano óbvio). Se a parametrização automática for bem-sucedida, o otimizador verá um parâmetro em vez de uma constante e oSelOnSeqPrjregra não é aplicada.
Para consultas em que a parametrização automática não é tentada (ou onde é determinada como insegura), a otimização ainda pode falhar, se a opção de banco de dados paraFORCED PARAMETERIZATIONestá ligado. Nossa consulta de teste (com o valor constante 878) não é segura para parametrização automática, mas a configuração de parametrização forçada substitui isso, resultando no plano ineficiente:
ALTER DATABASE AdventureWorksSET PARAMETERIZATION FORCED;GOSELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;GOALTER DATABASE AdventureWorksSET PARAMETERIZAÇÃO SIMPLE;

Solução alternativa do SQL Server 2008+
Para permitir que o otimizador ‘veja’ um valor constante para consulta que faz referência a uma variável ou parâmetro local, podemos adicionar umaOPTION (RECOMPILE)dica de consulta:
DECLARE @ProductID INT =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductIDOPTION (RECOMPILE);
Observação: O plano de execução de pré-execução ("estimado") ainda mostra uma varredura de índice porque o valor da variável ainda não está definido. Quando a consulta é executada , no entanto, o plano de execução mostra o plano de busca de índice desejado:

OSelOnSeqPrjregra não existe no SQL Server 2005, entãoOPTION (RECOMPILE)não pode ajudar lá. Caso você esteja se perguntando, aOPTION (RECOMPILE)A solução alternativa resulta em uma busca mesmo se a opção de banco de dados para parametrização forçada estiver ativada.
Solução nº 1 para todas as versões
Em alguns casos, é possível substituir a visão problemática, a expressão de tabela comum ou a tabela derivada por uma função com valor de tabela em linha parametrizada:
CREATE FUNCTION dbo.MostRecentTransactionsForProduct( @ProductID integer) RETURNS TABLECOM SCHEMABINDING ASRETURN SELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.Quantity FROM ( SELECT th.ProductID, th.TransactionID, th. ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( PARTIÇÃO POR th.ProductID ORDER POR th.TransactionDate DESC) DE Production.TransactionHistory AS th WHERE th.ProductID =@ProductID ) AS sq1 WHERE sq1.rnk =1;
Esta função coloca explicitamente oProductIDpredicado no mesmo escopo da função window, evitando a limitação do otimizador. Escrito para usar a função in-line, nossa consulta de exemplo se torna:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsForProduct(878) AS mrt;
Isso produz o plano de busca de índice desejado em todas as versões do SQL Server que oferecem suporte a funções de janela. Essa solução alternativa produz uma busca mesmo quando o predicado faz referência a um parâmetro ou variável local –OPTION (RECOMPILE)não é necessário.PARTITION BY cláusula e não retornar mais o ProductIDcoluna. Deixei a definição igual à visão que ela substituiu para ilustrar mais claramente a causa das diferenças do plano de execução.
Solução nº 2 para todas as versões
A segunda solução só se aplica a funções de janela de classificação que são filtradas para retornar linhas numeradas ou classificadas como #1 (usandoROW_NUMBER,RANK, ouDENSE_RANK). Este é um uso muito comum no entanto, por isso vale a pena mencionar.
Um benefício adicional é que essa solução alternativa pode produzir planos ainda mais eficientes do que o índice busca planos vistos anteriormente. Como lembrete, o melhor plano anterior era assim:

Esse plano de execução classifica 1.918 linhas, embora retorne apenas 6 . Podemos melhorar este plano de execução usando a função window em umORDER BYcláusula em vez de classificar as linhas e, em seguida, filtrar pela classificação nº 1:
SELECT TOP (1) COM LIGAÇÕES th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY RANK() OVER ( ORDER BY th.TransactionDate DESC);

Essa consulta ilustra bem o uso de uma função de janela noORDER BYcláusula, mas podemos fazer ainda melhor, eliminando completamente a função window:
SELECT TOP (1) COM LIGAÇÕES th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY th.TransactionDate DESC;
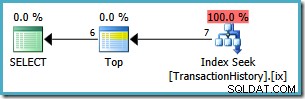
Este plano lê apenas 7 linhas da tabela para retornar o mesmo conjunto de resultados de 6 linhas. Por que 7 linhas? O operador Top está sendo executado emWITH TIESmodo:
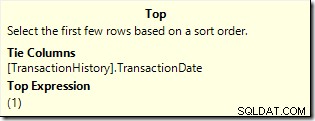
Ele continua a solicitar uma linha por vez de sua subárvore até que a TransactionDate seja alterada. A sétima linha é necessária para que o Top tenha certeza de que nenhuma outra linha de valor empatado será qualificada.
Podemos estender a lógica da consulta acima para substituir a definição de visão problemática:
ALTER VIEW dbo.MostRecentTransactionsPerProductWITH SCHEMABINDINGASSELECT p.ProductID, Classificado1.TransactionID, Classificado1.ReferenceOrderID, Classificado1.TransactionDate, Classificado1.QuantityFROM -- Lista de IDs de produtos (SELECT ProductID FROM Production.Product) AS pCROSS APPLY( -- Retorna a classificação #1 resultados para cada ID de produto SELECT TOP (1) WITH TIES th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity FROM Production.TransactionHistory AS th WHERE th.ProductID =p.ProductID ORDER TH.TransactionDate DESC) AS Classificado1;
A visualização agora usa umCROSS APPLYpara combinar os resultados do nossoORDER BYotimizado consulta para cada produto. Nossa consulta de teste permanece inalterada:
DECLARE @ProductID integer;SET @ProductID =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;
Os planos de pré e pós-execução mostram uma busca de índice sem precisar de umaOPTION (RECOMPILE)dica de consulta. O seguinte é um plano pós-execução ('real'):
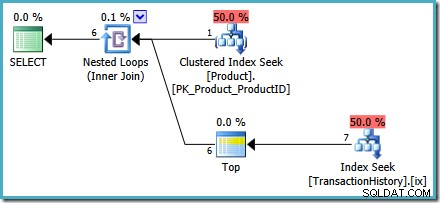
Se a visualização tiver usadoROW_NUMBERem vez deRANK, a visualização de substituição simplesmente teria omitido oWITH TIEScláusula noTOP (1). A nova visão também pode ser escrita como uma função com valor de tabela em linha parametrizada, é claro.
Pode-se argumentar que o plano de busca de índice original com ornk = 1o predicado também pode ser otimizado para testar apenas 7 linhas. Afinal, o otimizador deve saber que as classificações são produzidas pelo operador Sequence Project em estrita ordem crescente, de modo que a execução pode terminar assim que uma linha com uma classificação maior que um for vista. O otimizador não contém essa lógica hoje, no entanto.
Considerações finais
As pessoas geralmente ficam desapontadas com o desempenho de visualizações que incorporam funções de janela. O motivo muitas vezes pode ser rastreado até a limitação do otimizador descrita nesta postagem (ou talvez porque o designer de exibição não tenha apreciado que os predicados aplicados à exibição devem aparecer noPARTITION BYcláusula seja empurrada para baixo com segurança).
Quero enfatizar que essa limitação não se aplica apenas às visualizações, nem está limitada aROW_NUMBER,RANKeDENSE_RANK. Você deve estar ciente dessa limitação ao usar qualquer função com umOVERcláusula em uma exibição, expressão de tabela comum, tabela derivada ou função com valor de tabela em linha.
Os usuários do SQL Server 2005 que encontrarem esse problema terão a opção de reescrever a exibição como uma função com valor de tabela em linha parametrizada ou usar a funçãoAPPLYtécnica (quando aplicável).
Os usuários do SQL Server 2008 têm a opção extra de usar umaOPTION (RECOMPILE)dica de consulta se o problema puder ser resolvido permitindo que o otimizador veja uma constante em vez de uma variável ou referência de parâmetro. Lembre-se de verificar os planos de pós-execução ao usar esta dica:o plano de pré-execução geralmente não pode mostrar o plano ideal.



