No mês passado, engajei com vários clientes que tiveram problemas de conversão implícita no lado da coluna associados a suas cargas de trabalho OLTP. Em duas ocasiões, o efeito acumulado das conversões implícitas do lado da coluna foi a causa subjacente do problema geral de desempenho do SQL Server sendo revisado e, infelizmente, não há uma configuração mágica ou opção de configuração que possamos ajustar para melhorar a situação quando este for o caso. Embora possamos oferecer sugestões para corrigir outras frutas mais fáceis que podem estar afetando o desempenho geral, o efeito das conversões implícitas do lado da coluna é algo que requer uma alteração no design do esquema para corrigir ou uma alteração no código para evitar a alteração da coluna. conversão lateral ocorra completamente contra o esquema de banco de dados atual.
As conversões implícitas são o resultado do mecanismo de banco de dados comparando valores de diferentes tipos de dados durante a execução da consulta. Uma lista das possíveis conversões implícitas que podem ocorrer dentro do mecanismo de banco de dados pode ser encontrada no tópico Conversão de Tipo de Dados (Database Engine) dos Manuais Online. As conversões implícitas sempre ocorrem com base na precedência do tipo de dados para os tipos de dados que estão sendo comparados durante a operação. A ordem de precedência do tipo de dados pode ser encontrada no tópico Data Type Precedence (Transact-SQL) dos Manuais Online. Recentemente, escrevi no blog sobre as conversões implícitas que resultam em uma verificação de índice e forneci gráficos que também podem ser usados para determinar as conversões implícitas mais problemáticas.
Configurando os testes
Para demonstrar a sobrecarga de desempenho associada às conversões implícitas do lado da coluna que resultam em uma verificação de índice, executei uma série de testes diferentes no banco de dados AdventureWorks2012 usando a tabela Sales.SalesOrderDetail para criar tabelas de teste e conjuntos de dados. A conversão implícita do lado da coluna mais comum que vejo como consultor ocorre quando o tipo de coluna é char ou varchar, e o código do aplicativo passa um parâmetro que é nchar ou nvarchar e filtra na coluna char ou varchar. Para simular esse tipo de cenário, criei uma cópia da tabela SalesOrderDetail (chamada SalesOrderDetail_ASCII) e alterei a coluna CarrierTrackingNumber de nvarchar para varchar. Além disso, adicionei um índice não clusterizado na coluna CarrierTrackingNumber à tabela SalesOrderDetail original, bem como à nova tabela SalesOrderDetail_ASCII.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO A nova tabela SalesOrderDetail_ASCII tem 121.317 linhas e 17,5 MB de tamanho e será usada para avaliar a sobrecarga de uma tabela pequena. Também criei uma tabela que é dez vezes maior, usando uma versão modificada do script Enlarging the AdventureWorks Sample Databases do meu blog, que contém 1.334.487 linhas e tem 190 MB de tamanho. O servidor de teste para isso é a mesma VM de 4 vCPU com 4 GB de RAM, executando Windows Server 2008 R2 e SQL Server 2012, com Service Pack 1 e Atualização Cumulativa 3, que usei em artigos anteriores, para que as tabelas caibam inteiramente na memória , eliminando a sobrecarga de E/S de disco de afetar os testes que estão sendo executados.
A carga de trabalho de teste foi gerada usando uma série de scripts do PowerShell que selecionam a lista de CarrierTrackingNumbers da tabela SalesOrderDetail criando uma ArrayList e, em seguida, selecionam aleatoriamente um CarrierTrackingNumber da ArrayList para consultar a tabela SalesOrderDetail_ASCII usando um parâmetro varchar e, em seguida, um parâmetro nvarchar e em seguida, para consultar a tabela SalesOrderDetail usando um parâmetro nvarchar para fornecer uma comparação de onde a coluna e o parâmetro são nvarchar. Cada um dos testes individuais executa a instrução 10.000 vezes para permitir medir a sobrecarga de desempenho em uma carga de trabalho sustentada.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now Um segundo conjunto de testes foi executado nas tabelas SalesOrderDetailEnlarged_ASCII e SalesOrderDetailEnlarged usando a mesma parametrização do primeiro conjunto de testes para mostrar a diferença de sobrecarga à medida que o tamanho dos dados armazenados na tabela aumenta com o tempo. Um conjunto final de testes também foi executado na tabela SalesOrderDetail usando a coluna ProductID como uma coluna de filtro com tipos de parâmetro int, bigint e smallint para fornecer uma comparação da sobrecarga de conversões implícitas que não resultam em uma verificação de índice para comparação.
Nota:Todos os scripts estão anexados a este artigo para permitir a reprodução dos testes de conversão implícitos para posterior avaliação e comparação.
Resultados do teste
Durante cada uma das execuções de teste, o Monitor de Desempenho foi configurado para executar um Conjunto de Coletores de Dados que incluía os contadores Processor\% Processor Time e SQL Server:SQLStatisitics\Batch Requests/s para rastrear a sobrecarga de desempenho para cada um dos testes. Além disso, o Extended Events foi configurado para rastrear o evento rpc_completed para permitir o rastreamento da duração média, cpu_time e leituras lógicas para cada um dos testes.
Resultados do número de rastreamento do transportador de mesa pequena
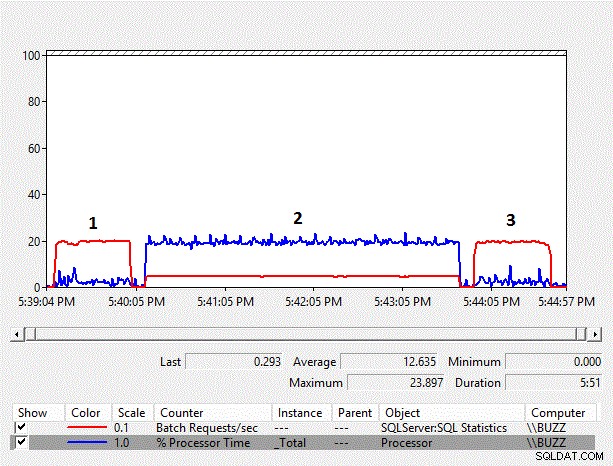
Figura 1 – Gráfico de contadores do Monitor de desempenho
| ID de teste | Tipo de dados da coluna | Tipo de dados de parâmetro | % de tempo médio do processador | Média de solicitações de lote/s | Duração h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2.5 | 192,3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19.4 | 46,7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192,3 | 0:00:51 |
Tabela 2 – Médias de dados do Monitor de desempenho
A partir dos resultados, podemos ver que a conversão implícita do lado da coluna de varchar para nvarchar e a verificação de índice resultante têm um impacto significativo no desempenho da carga de trabalho. A média de % de tempo do processador para o teste de conversão implícita do lado da coluna (TestID =2) é quase dez vezes maior do que os outros testes em que a conversão implícita do lado da coluna, resultando em uma verificação de índice, não ocorreu. Além disso, a média de solicitações de lote/s para o teste de conversão implícita do lado da coluna foi pouco menos de 25% dos outros testes. A duração dos testes em que não ocorreram conversões implícitas levou 51 segundos, embora os dados tenham sido armazenados como nvarchar no teste número 3 usando um tipo de dados nvarchar, exigindo o dobro do espaço de armazenamento. Isso é esperado porque a tabela ainda é menor que o buffer pool.
| ID de teste | Tempo médio de CPU (µs) | Duração média (µs) | Média de leituras lógicas |
|---|---|---|---|
| 1 | 40,7 | 154,9 | 51,6 |
| 2 | 15.640,8 | 15.760,0 | 385,6 |
| 3 | 45,3 | 169,7 | 52,7 |
Tabela 3 – Médias de eventos estendidos
Os dados coletados pelo evento rpc_completed em Extended Events mostram que a média de cpu_time, duração e leituras lógicas associadas às consultas que não executam uma conversão implícita do lado da coluna são aproximadamente equivalentes, onde a conversão implícita do lado da coluna incorre em uma CPU significativa sobrecarga, bem como uma duração média mais longa com leituras lógicas significativamente mais.
Resultados do número de rastreamento do transportador de mesa ampliado
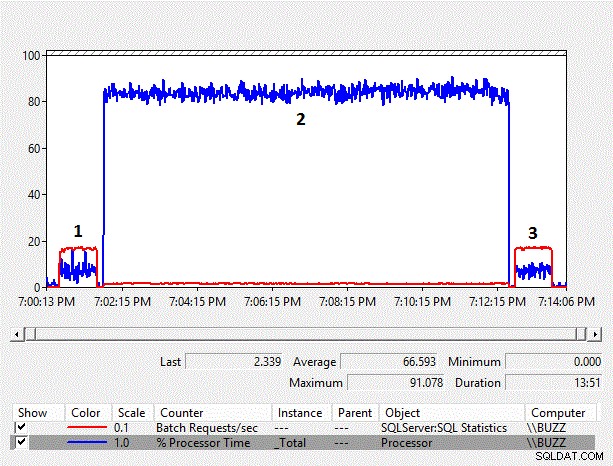
Figura 4 – Gráfico de contadores do Monitor de desempenho
| ID de teste | Tipo de dados da coluna | Tipo de dados de parâmetro | % de tempo médio do processador | Média de solicitações de lote/s | Duração h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164.0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83,8 | 15.4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166,7 | 0:01:00 |
Tabela 5 – Médias de dados do Monitor de desempenho
À medida que o tamanho dos dados aumenta, a sobrecarga de desempenho da conversão implícita do lado da coluna também aumenta. A % média de tempo do processador para o teste de conversão implícita do lado da coluna (TestID =2) é, novamente, quase dez vezes maior do que os outros testes em que a conversão implícita do lado da coluna, resultando em uma varredura de índice, não ocorreu. Além disso, a média de solicitações em lote/s para o teste de conversão implícita do lado da coluna foi pouco menos de 10% dos outros testes. A duração dos testes em que não ocorreram conversões implícitas levou um minuto, enquanto o teste de conversão implícita no lado da coluna exigiu cerca de onze minutos para ser executado.
| ID de teste | Tempo médio de CPU (µs) | Duração média (µs) | Média de leituras lógicas |
|---|---|---|---|
| 1 | 728,5 | 1.036,5 | 569,6 |
| 2 | 214.174,6 | 59.519,1 | 4.358,2 |
| 3 | 821,5 | 1.032,4 | 553,5 |
Tabela 6 – Médias de eventos estendidos
Os resultados dos Eventos Estendidos realmente começam a mostrar a sobrecarga de desempenho causada pelas conversões implícitas do lado da coluna para a carga de trabalho. O cpu_time médio por execução salta para mais de 214 ms e é mais de 200 vezes o cpu_time para as instruções que não têm as conversões implícitas do lado da coluna. A duração também é quase 60 vezes maior do que as instruções que não possuem as conversões implícitas do lado da coluna.
Resumo
À medida que o tamanho dos dados continua a aumentar, a sobrecarga associada às conversões implícitas do lado da coluna que resultam em uma verificação de índice para a carga de trabalho também continuará a crescer, e o importante a ser lembrado é que, em algum momento, nenhuma quantidade de hardware será capaz de lidar com a sobrecarga de desempenho. Conversões implícitas são fáceis de evitar quando existe um bom design de esquema de banco de dados e os desenvolvedores seguem boas técnicas de codificação de aplicativos. Em situações em que as práticas de codificação do aplicativo resultam em parametrização que aproveita a parametrização nvarchar, é melhor combinar o design do esquema do banco de dados com a parametrização da consulta do que usar colunas varchar no design do banco de dados e incorrer na sobrecarga de desempenho da conversão implícita do lado da coluna.
Baixe os scripts de demonstração:Implicit_Conversion_Tests.zip (5 KB)