Na Parte 5 da minha série sobre expressões de tabela, forneci a seguinte solução para gerar uma série de números usando CTEs, um construtor de valor de tabela e junções cruzadas:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Há muitos casos de uso práticos para essa ferramenta, incluindo a geração de uma série de valores de data e hora, a criação de dados de amostra e muito mais. Reconhecendo a necessidade comum, algumas plataformas fornecem uma ferramenta integrada, como a função generate_series do PostgreSQL. No momento em que escrevo, o T-SQL não fornece uma ferramenta integrada, mas sempre podemos esperar e votar para que essa ferramenta seja adicionada no futuro.
Em um comentário ao meu artigo, Marcos Kirchner mencionou que testou minha solução com diferentes cardinalidades do construtor de valores de tabela e obteve diferentes tempos de execução para as diferentes cardinalidades.
 Eu sempre usei minha solução com uma cardinalidade de construtor de valor de tabela base de 2, mas o comentário de Marcos me fez pensar. Esta ferramenta é tão útil que nós, como comunidade, devemos unir forças para tentar criar a versão mais rápida possível. Testar diferentes cardinalidades da tabela base é apenas uma dimensão para tentar. Pode haver muitos outros. Vou apresentar os testes de performance que fiz com minha solução. Eu experimentei principalmente com diferentes cardinalidades de construtor de valor de tabela, com processamento serial versus paralelo e com processamento de modo de linha versus modo de lote. No entanto, pode ser que uma solução totalmente diferente seja ainda mais rápida que a minha melhor versão. Então, o desafio está lançado! Estou chamando todos os jedi, padawan, mago e aprendiz. Qual é a solução de melhor desempenho que você pode conjurar? Você tem dentro de você para vencer a solução mais rápida postada até agora? Em caso afirmativo, compartilhe o seu como um comentário a este artigo e sinta-se à vontade para melhorar qualquer solução postada por outras pessoas.
Eu sempre usei minha solução com uma cardinalidade de construtor de valor de tabela base de 2, mas o comentário de Marcos me fez pensar. Esta ferramenta é tão útil que nós, como comunidade, devemos unir forças para tentar criar a versão mais rápida possível. Testar diferentes cardinalidades da tabela base é apenas uma dimensão para tentar. Pode haver muitos outros. Vou apresentar os testes de performance que fiz com minha solução. Eu experimentei principalmente com diferentes cardinalidades de construtor de valor de tabela, com processamento serial versus paralelo e com processamento de modo de linha versus modo de lote. No entanto, pode ser que uma solução totalmente diferente seja ainda mais rápida que a minha melhor versão. Então, o desafio está lançado! Estou chamando todos os jedi, padawan, mago e aprendiz. Qual é a solução de melhor desempenho que você pode conjurar? Você tem dentro de você para vencer a solução mais rápida postada até agora? Em caso afirmativo, compartilhe o seu como um comentário a este artigo e sinta-se à vontade para melhorar qualquer solução postada por outras pessoas. Requisitos:
- Implemente sua solução como uma função com valor de tabela embutido (iTVF) chamada dbo.GetNumsYourName com os parâmetros @low AS BIGINT e @high AS BIGINT. Como exemplo, veja os que eu envio no final deste artigo.
- Você pode criar tabelas de suporte no banco de dados do usuário, se necessário.
- Você pode adicionar dicas conforme necessário.
- Como mencionado, a solução deve oferecer suporte a delimitadores do tipo BIGINT, mas você pode assumir uma cardinalidade de série máxima de 4.294.967.296.
- Para avaliar o desempenho da sua solução e compará-la com outras, vou testá-la com o intervalo de 1 a 100.000.000, com Descartar resultados após a execução ativado no SSMS.
Boa sorte para todos nós! Que vença a melhor comunidade.;)
Diferentes cardinalidades para o construtor de valor da tabela base
Experimentei várias cardinalidades do CTE de base, começando com 2 e avançando em uma escala logarítmica, elevando ao quadrado a cardinalidade anterior em cada passo:2, 4, 16 e 256.
Antes de começar a experimentar com diferentes cardinalidades de base, pode ser útil ter uma fórmula que, dada a cardinalidade de base e a cardinalidade de alcance máximo, diga quantos níveis de CTEs você precisa. Como passo preliminar, é mais fácil primeiro chegar a uma fórmula que, dada a cardinalidade básica e o número de níveis de CTEs, calcule qual é a cardinalidade máxima do intervalo resultante. Aqui está uma fórmula expressa em T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Com os valores de entrada de amostra acima, esta expressão produz uma cardinalidade de intervalo máxima de 4.294.967.296.
Então, a fórmula inversa para calcular o número de níveis CTE necessários envolve aninhar duas funções de log, assim:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Com os valores de entrada de exemplo acima, essa expressão produz 5. Observe que esse número é um acréscimo ao CTE base que possui o construtor de valor de tabela, que chamei de L0 (para nível 0) em minha solução.
Não me pergunte como cheguei a essas fórmulas. A história em que estou me apegando é que Gandalf as pronunciou para mim em élfico em meus sonhos.
Vamos prosseguir para o teste de desempenho. Certifique-se de ativar Descartar resultados após a execução na caixa de diálogo Opções de consulta do SSMS em Grade, Resultados. Use o código a seguir para executar um teste com cardinalidade CTE básica de 2 (requer 5 níveis adicionais de CTEs):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Eu tenho o plano mostrado na Figura 1 para esta execução.
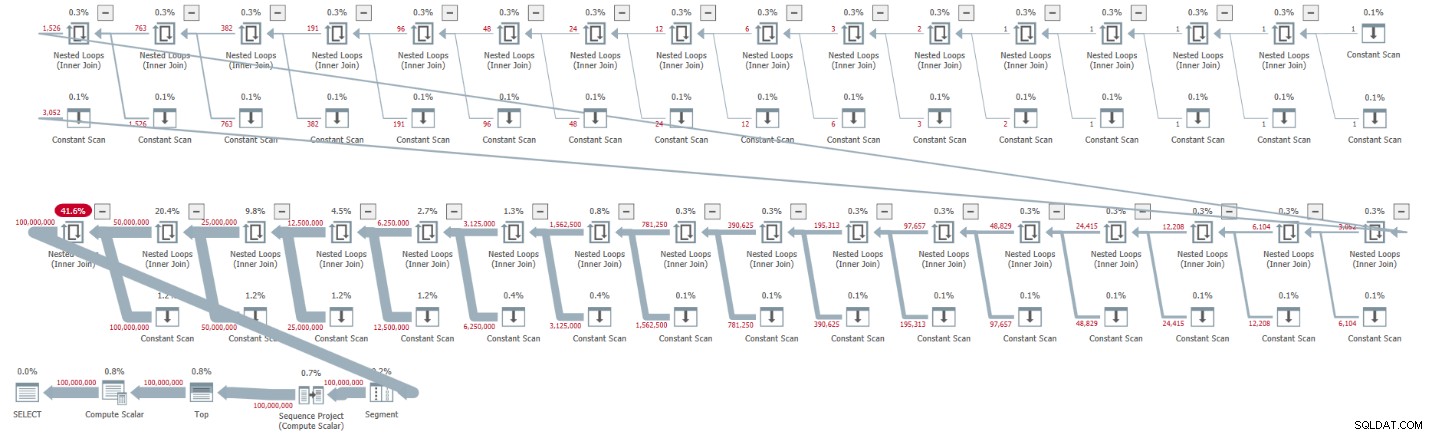 Figura 1:Plano para cardinalidade CTE base de 2
Figura 1:Plano para cardinalidade CTE base de 2 O plano é serial e todos os operadores no plano usam o processamento do modo de linha por padrão. Se você está recebendo um plano paralelo por padrão, por exemplo, ao encapsular a solução em um iTVF e usar um intervalo grande, por enquanto, force um plano serial com uma dica MAXDOP 1.
Observe como a descompactação dos CTEs resultou em 32 instâncias do operador Constant Scan, cada uma representando uma tabela com duas linhas.
Eu obtive as seguintes estatísticas de desempenho para esta execução:
CPU time = 30188 ms, elapsed time = 32844 ms.
Use o código a seguir para testar a solução com uma cardinalidade CTE básica de 4, que, de acordo com nossa fórmula, requer quatro níveis de CTEs:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Eu tenho o plano mostrado na Figura 2 para esta execução.
 Figura 2:plano para cardinalidade CTE básica de 4
Figura 2:plano para cardinalidade CTE básica de 4 A descompactação dos CTEs resultou em 16 operadores Constant Scan, cada um representando uma tabela de 4 linhas.
Eu obtive as seguintes estatísticas de desempenho para esta execução:
CPU time = 23781 ms, elapsed time = 25435 ms.
Esta é uma melhoria decente de 22,5 por cento em relação à solução anterior.
Examinando as estatísticas de espera relatadas para a consulta, o tipo de espera dominante é SOS_SCHEDULER_YIELD. De fato, a contagem de espera curiosamente caiu 22,8% em comparação com a primeira solução (contagem de espera 15.280 versus 19.800).
Use o código a seguir para testar a solução com uma cardinalidade CTE básica de 16, que, de acordo com nossa fórmula, requer três níveis de CTEs:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Eu tenho o plano mostrado na Figura 3 para esta execução.
 Figura 3:plano para cardinalidade CTE básica de 16
Figura 3:plano para cardinalidade CTE básica de 16 Desta vez, a descompactação dos CTEs resultou em 8 operadores Constant Scan, cada um representando uma tabela com 16 linhas.
Eu obtive as seguintes estatísticas de desempenho para esta execução:
CPU time = 22968 ms, elapsed time = 24409 ms.
Esta solução reduz ainda mais o tempo decorrido, embora em apenas alguns por cento adicionais, totalizando uma redução de 25,7 por cento em comparação com a primeira solução. Novamente, a contagem de espera do tipo de espera SOS_SCHEDULER_YIELD continua caindo (12.938).
Avançando em nossa escala logarítmica, o próximo teste envolve uma cardinalidade CTE básica de 256. É longo e feio, mas experimente:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Eu tenho o plano mostrado na Figura 4 para esta execução.
 Figura 4:Plano para cardinalidade CTE base de 256
Figura 4:Plano para cardinalidade CTE base de 256 Desta vez, a descompactação dos CTEs resultou em apenas quatro operadores Constant Scan, cada um com 256 linhas.
Eu obtive os seguintes números de desempenho para esta execução:
CPU time = 23516 ms, elapsed time = 25529 ms.
Desta vez, parece que o desempenho diminuiu um pouco em comparação com a solução anterior com uma cardinalidade CTE básica de 16. De fato, a contagem de espera do tipo de espera SOS_SCHEDULER_YIELD aumentou um pouco para 13.176. Então, parece que encontramos nosso número de ouro – 16!
Planos paralelos versus planos em série
Experimentei forçar um plano paralelo usando a dica ENABLE_PARALLEL_PLAN_PREFERENCE, mas acabou prejudicando o desempenho. De fato, ao implementar a solução como iTVF, obtive um plano paralelo em minha máquina por padrão para grandes intervalos e tive que forçar um plano serial com uma dica MAXDOP 1 para obter o desempenho ideal.
Processamento em lote
O principal recurso utilizado nos planos das minhas soluções é CPU. Dado que o processamento em lote visa melhorar a eficiência da CPU, especialmente ao lidar com um grande número de linhas, vale a pena tentar essa opção. A principal atividade aqui que pode se beneficiar do processamento em lote é o cálculo do número da linha. Testei minhas soluções no SQL Server 2019 Enterprise Edition. O SQL Server escolheu o processamento do modo de linha para todas as soluções mostradas anteriormente por padrão. Aparentemente, essa solução não passou na heurística necessária para habilitar o modo de lote no rowstore. Existem algumas maneiras de fazer com que o SQL Server use o processamento em lote aqui.
A opção 1 é envolver uma tabela com um índice columnstore na solução. Você pode conseguir isso criando uma tabela fictícia com um índice columnstore e introduzindo uma junção esquerda fictícia na consulta mais externa entre nosso Nums CTE e essa tabela. Aqui está a definição da tabela fictícia:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Em seguida, revise a consulta externa contra Nums para usar FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Aqui está um exemplo com uma cardinalidade CTE básica de 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Eu tenho o plano mostrado na Figura 5 para esta execução.
 Figura 5:planejamento com processamento em lote
Figura 5:planejamento com processamento em lote Observe o uso do operador Window Aggregate do modo em lote para calcular os números das linhas. Observe também que o plano não envolve a mesa fictícia. O otimizador o otimizou.
A vantagem da opção 1 é que ela funciona em todas as edições do SQL Server e é relevante no SQL Server 2016 ou posterior, pois o operador Window Aggregate em modo batch foi introduzido no SQL Server 2016. A desvantagem é a necessidade de criar a tabela fictícia e incluir isso na solução.
A opção 2 para obter processamento em lote para nossa solução, desde que você esteja usando o SQL Server 2019 Enterprise Edition, é usar a dica autoexplicativa não documentada OVERRIDE_BATCH_MODE_HEURISTICS (detalhes no artigo de Dmitry Pilugin), assim:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); A vantagem da opção 2 é que você não precisa criar uma tabela fictícia e envolvê-la em sua solução. As desvantagens são que você precisa usar a edição Enterprise, usar no mínimo o SQL Server 2019 onde o modo de lote no rowstore foi introduzido e a solução envolve o uso de uma dica não documentada. Por estas razões, prefiro a opção 1.
Aqui estão os números de desempenho que obtive para as várias cardinalidades básicas do CTE:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
A Figura 6 apresenta uma comparação de desempenho entre as diferentes soluções:
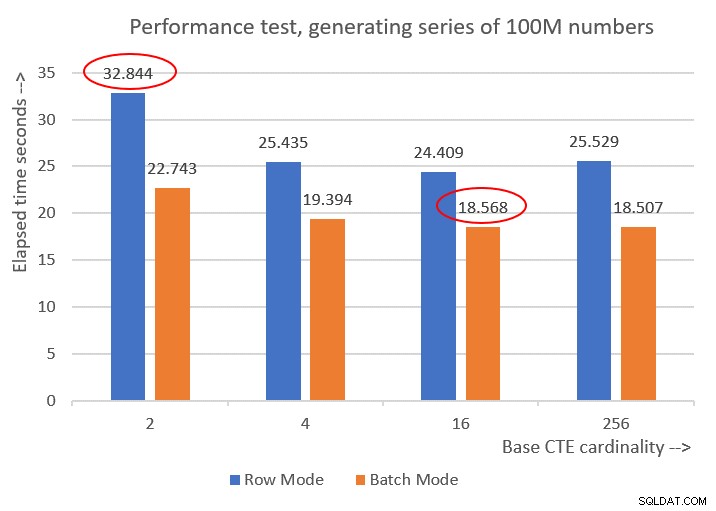 Figura 6:comparação de desempenho
Figura 6:comparação de desempenho Você pode observar uma melhoria de desempenho decente de 20 a 30 por cento em relação às contrapartes do modo de linha.
Curiosamente, com o processamento em lote, a solução com cardinalidade CTE básica de 256 se saiu melhor. No entanto, é apenas um pouco mais rápido do que a solução com cardinalidade CTE básica de 16. A diferença é tão pequena, e a última tem uma clara vantagem em termos de brevidade de código, que eu ficaria com 16.
Assim, meus esforços de ajuste acabaram gerando uma melhoria de 43,5% em relação à solução original com a cardinalidade básica de 2 usando o processamento em modo de linha.
O desafio começou!
Apresento duas soluções como minha contribuição da comunidade para este desafio. Se você estiver executando o SQL Server 2016 ou posterior e conseguir criar uma tabela no banco de dados do usuário, crie a seguinte tabela fictícia:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
E use a seguinte definição de iTVF:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Use o código a seguir para testá-lo (certifique-se de verificar os resultados de descarte após a execução):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Este código termina em 18 segundos na minha máquina.
Se, por qualquer motivo, você não puder atender aos requisitos da solução de processamento em lote, envio a seguinte definição de função como minha segunda solução:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Use o seguinte código para testá-lo:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Este código termina em 24 segundos na minha máquina.
Sua vez!



