Esta é a 4ª e última parte da série Benchmarking Managed PostgreSQLCloud Solutions . No momento da redação deste artigo, o Microsoft Azure PostgreSQL estava na versão 10.7, mais recente que os dois concorrentes:Amazon Aurora PostgreSQL na versão 10.6 e Google Cloud SQL para PostgreSQL na versão 9.6.
A Microsoft decidiu executar o Azure PostgreSQL no Windows:
postgres=> select version();
version
------------------------------------------------------------
PostgreSQL 10.7, compiled by Visual C++ build 1800, 64-bit
(1 row)Para este teste em particular que não funcionou muito bem, e arrisco adivinhar que a Microsoft está bem ciente das limitações, a razão pela qual, sob o guarda-chuva do PostgreSQL, eles também oferecem uma versão prévia da versão Citus Data do PostgreSQL. A abordagem é semelhante aos sabores do AWS PostgreSQL, RDS e, respectivamente, Aurora.
Como uma observação lateral, ao configurar minha conta do Azure, fiquei surpreso com a falta de autenticação 2FA/MFA (dois fatores/multifatores) que tomei como garantida com o AWS Virtual MFA da Amazon e a verificação em duas etapas do Google. A Microsoft oferece MFA apenas para clientes corporativos inscritos no Active Directory ou Office 365. Como o Citus Cloud impõe 2FA para banco de dados de produção, talvez a Microsoft não esteja tão longe de implementá-lo no Azure.
TL;DR
Não há resultados para o Azure. Na instância de banco de dados de 8 núcleos, idêntica em número de núcleos aos usados na AWS e G Cloud, os testes não foram concluídos devido a erros no banco de dados. Em uma instância de 16 núcleos, o pgbench foi concluído e o sysbench chegou ao ponto de criar as 3 primeiras tabelas, momento em que interrompi o processo. Embora eu estivesse disposto a gastar uma quantidade razoável de esforço, tempo e dinheiro para realizar os testes e documentar os erros e suas causas, o objetivo deste exercício era executar o benchmark, portanto, nunca considerei buscar qualquer solução de problemas avançada ou entrar em contato com Suporte do Azure, nem terminei o teste do sysbench no banco de dados de 16 núcleos.
Instâncias de nuvem
Cliente
A instância do cliente do Azure mais próxima da instância da AWS selecionada no início desta série de blogs foi uma instância do E32s v3 com as seguintes especificações:
- vCPU:32 (16 núcleos x 2 threads/núcleo)
- RAM:256 GiB
- Armazenamento:SSD Premium do Azure
- Rede:rede acelerada de até 30 Gbps
Aqui está uma captura de tela do portal com os detalhes da instância:
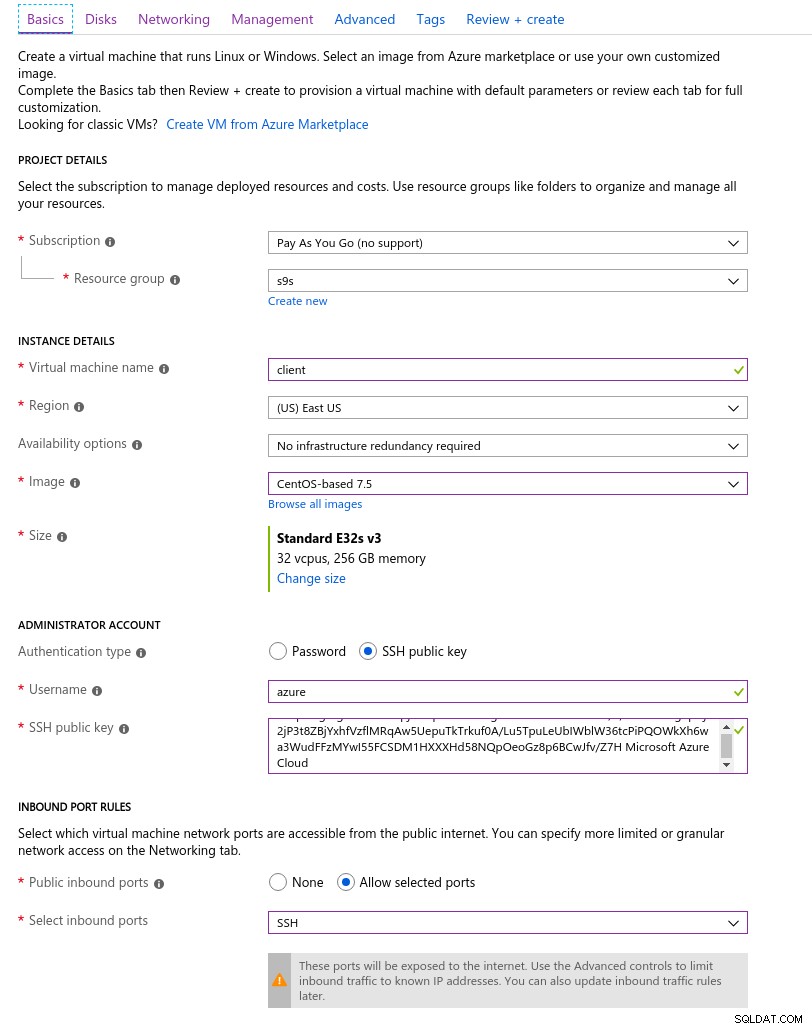 Detalhes da instância do cliente
Detalhes da instância do cliente A Rede Acelerada é habilitada por padrão ao escolher qualquer uma das máquinas virtuais com suporte:
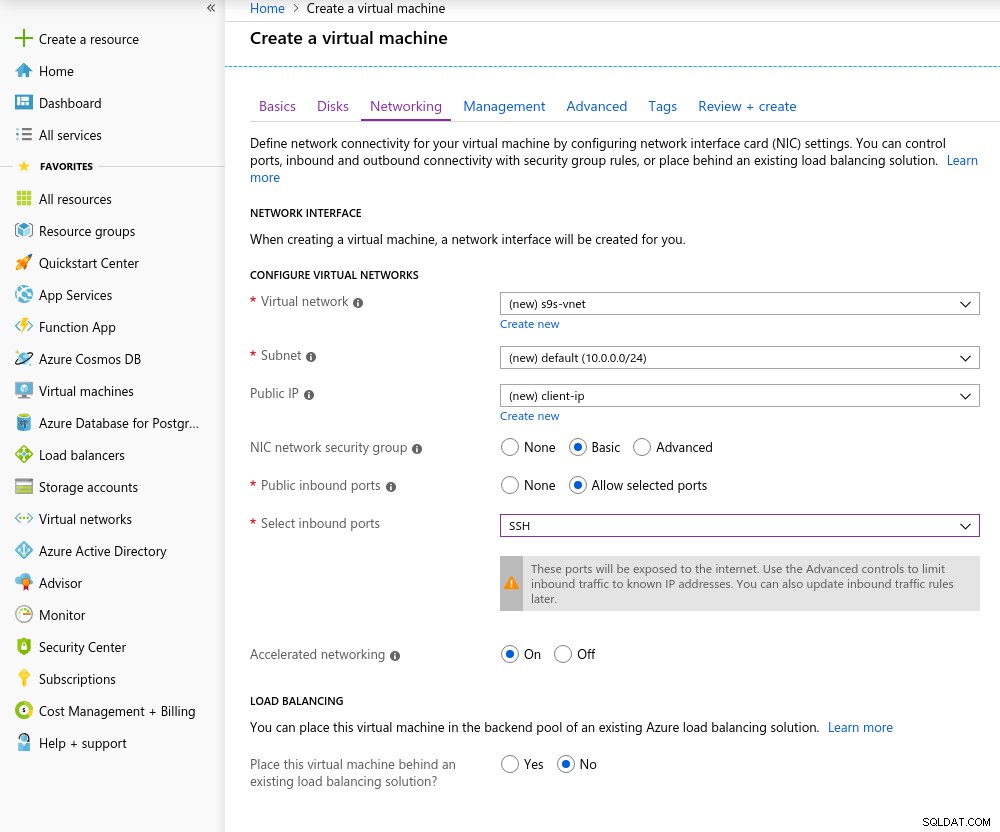 Rede acelerada ativada
Rede acelerada ativada Como é regra na nuvem, para obter o melhor desempenho de rede, o cliente e o servidor devem estar localizados na mesma zona de disponibilidade, o que fiz configurando o ambiente na zona leste dos EUA.
Da mesma forma que o Google Cloud, um aumento de cota deve ser solicitado para instâncias com mais de 10 núcleos. A Microsoft tornou isso muito fácil. Depois de mudar para uma conta paga, recebi a confirmação de aprovação antes que pudesse terminar minha resposta no ticket explicando por que estou solicitando o aumento.
Banco de dados
Ao selecionar o tamanho da instância, tentei combinar as especificações das instâncias usadas na AWS e no Google Cloud:
- vCPU:8
- RAM:80 GiB (máximo)
- Armazenamento:6.000 IOPS (tamanho de 2 TiB a 3 IOPS/GB)
- Rede:2.000 MB/s
O tamanho baixo da memória decorre da fórmula de memória por vCore usada para alocar memória:
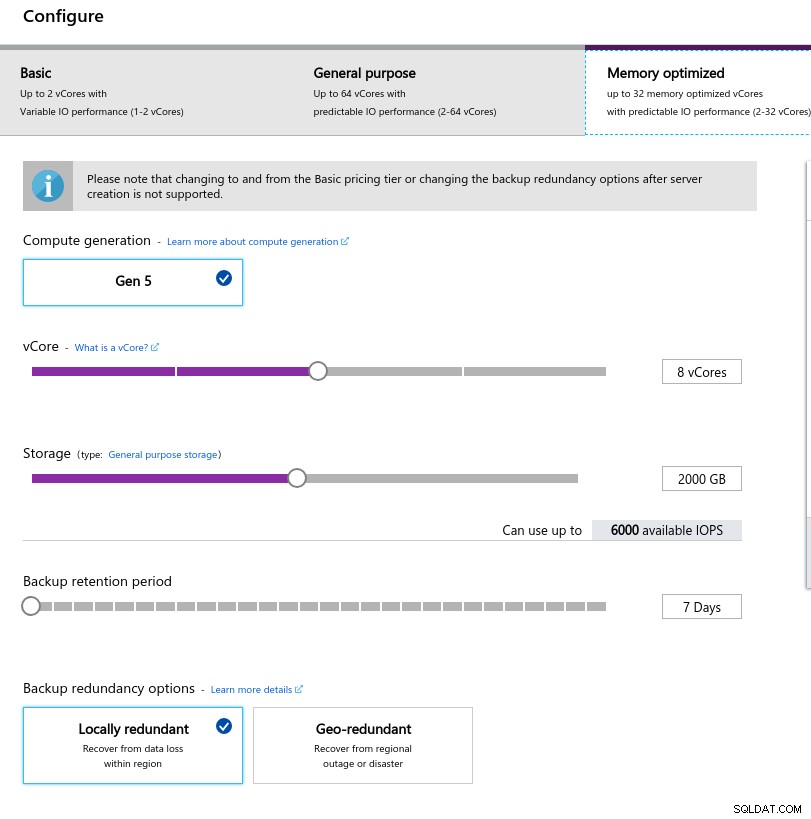 Configuração da instância do banco de dados
Configuração da instância do banco de dados Semelhante ao Google Cloud, e diferentemente da AWS, quanto maior o armazenamento, maior o IOPS, com um aumento de 3:1 na proporção, porém, quando o tamanho atinge 2TiB o IOPS é limitado a 6000 IOPS.
Executando os comparativos de mercado
Configuração
A configuração seguiu o processo descrito nas partes anteriores da série de blogs, com o patch de sincronização do AWS pgbench para 11.1 se aplicando de forma limpa ao Azure PostgreSQL versão 10.7. Os patches também podem ser obtidos nas contribuições do AWS Labs para o repositório PostgreSQL Github.
Ao longo da execução dos benchmarks, usei o script a seguir, que segue apenas o guia da Amazon e, neste caso, é adaptado para a versão do PostgreSQL no Azure (10.7). A máquina cliente executa o CentOS 7.5:
#!/bin/bash
set -eE
trap "exit 1" ERR
yum -y install \
wget ant git php gnuplot gcc make readline-devel zlib-devel \
postgresql-jdbc bzr automake libtool patch libevent-devel \
openssl-devel ncurses-devel
wget https://ftp.postgresql.org/pub/source/v10.7/postgresql-10.7.tar.gz
rm -rf postgresql-10.7
tar -xzf postgresql-10.7.tar.gz
cd postgresql-10.7
wget https://s3.amazonaws.com/aurora-pgbench-patches/pgbench-init-timing.patch
patch --verbose -p1 -b < pgbench-init-timing.patch
./configure
make -j 4 all
make install
cd ..
rm -rf sysbench
git clone -b 0.5 https://github.com/akopytov/sysbench.git
cd sysbench
./autogen.sh
CFLAGS="-L/usr/local/pgsql/lib/ -I /usr/local/pgsql/include/" \
| ./configure \
--with-pgsql \
--without-mysql \
--with-pgsql-includes=/usr/local/pgsql/include/ \
--with-pgsql-libs=/usr/local/pgsql/lib/
make
make install
cd sysbench/tests
make install
sed -i \
'/^export PGHOST=/,/^export LD_LIBRARY_PATH.*pgsql/d' \
~/.bashrc
cat << "__eot__" >> ~/.bashrc
export PGHOST=CHANGEME
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=/usr/local/pgsql/bin:/usr/local/bin:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib
__eot__
echo "All done."Quando o script for concluído, edite .bashrc para definir as variáveis de ambiente do PostgreSQL. O Azure é peculiar quanto ao formato do nome de usuário do PostgreSQL, esperando um formato {username}@{host} em vez do onipresente {username}:
[example@sqldat.com scripts]# psql
psql: FATAL: Invalid Username specified. Please check the Username and retry connection. The Username should be in <example@sqldat.com> format.Antes de iniciar os testes, verifique se estamos usando a versão correta das ferramentas do cliente:
[example@sqldat.com scripts]# psql --version
psql (PostgreSQL) 10.7[example@sqldat.com scripts]# pgbench --version
pgbench (PostgreSQL) 10.7[example@sqldat.com scripts]# sysbench --version
sysbench 0.5pgench
Inicialize o banco de dados pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000… e vários minutos depois:
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.04 s, remaining 426.44 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 427.22 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.18 s, remaining 600.63 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 530.99 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.30 s, remaining 595.12 s)
...
584300000 of 1000000000 tuples (58%) done (elapsed 2421.82 s, remaining 1723.01 s)
584400000 of 1000000000 tuples (58%) done (elapsed 2421.86 s, remaining 1722.32 s)
584500000 of 1000000000 tuples (58%) done (elapsed 2422.81 s, remaining 1722.29 s)
584600000 of 1000000000 tuples (58%) done (elapsed 2422.84 s, remaining 1721.60 s)
584700000 of 1000000000 tuples (58%) done (elapsed 2422.88 s, remaining 1720.92 s)
584800000 of 1000000000 tuples (58%) done (elapsed 2425.06 s, remaining 1721.76 s)
584900000 of 1000000000 tuples (58%) done (elapsed 2425.09 s, remaining 1721.07 s)
585000000 of 1000000000 tuples (58%) done (elapsed 2425.28 s, remaining 1720.50 s)
...
999700000 of 1000000000 tuples (99%) done (elapsed 4142.69 s, remaining 1.24 s)
999800000 of 1000000000 tuples (99%) done (elapsed 4142.95 s, remaining 0.83 s)
999900000 of 1000000000 tuples (99%) done (elapsed 4142.98 s, remaining 0.41 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 4143.92 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 14805.73 s (insert 4146.94 s, commit 0.02 s, vacuum 6581.15 s, index 4077.61 s)
done.Até agora tudo bem.
Uma rápida olhada no banco de dados para confirmar que ele está pronto:
example@sqldat.com:5432 postgres> \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Table space | Description
-------------------+-----------------+----------+----------------------------+----------------------------+-------------------------------------+-----------+------------+--------------------------------------------
azure_maintenance | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | azure_superuser=CTc/azure_superuser | No Access | pg_default |
azure_sys | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 12 MB | pg_default |
postgres | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | | 160 GB | pg_default | default administrative connection database
template0 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | unmodifiable empty database
| | | | | azure_superuser=CTc/azure_superuser | | |
template1 | azure_superuser | UTF8 | English_United States.1252 | English_United States.1252 | =c/azure_superuser +| 7865 kB | pg_default | default template for new databases
| | | | | azure_superuser=CTc/azure_superuser | | |
(5 rows)Como o Azure não permite alterar max_connections e dado que, para a instância selecionada, o limite é limitado a 960, teremos que ajustar o número de clientes pgbench adequadamente:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not known
connection to database "postgres" failed:
could not translate host name "postgresql-10-7.postgres.database.azure.com" to address: Name or service not knownE aí está, o primeiro soluço.
Uma verificação rápida da resolução do DNS do host não mostra nenhum problema:
[example@sqldat.com scripts]# dig +short $PGHOST
cr1.eastus1-a.control.database.windows.net.
191.238.6.43[example@sqldat.com scripts]# cat /etc/resolv.conf
; generated by /usr/sbin/dhclient-script
search 11jv1qvdjs5utlhtlyb5vdyeth.bx.internal.cloudapp.net
nameserver 168.63.129.16Uma revisão do meu log de tela mostra que quase metade das conexões foram encerradas:
~$ cat screenlog.1 | nl | grep 'could not translate host name "postgresql-10-7.*Name or service not known' | wc -l
469pg_stat_activity conta uma história mais detalhada — aumentamos em 950 conexões:
example@sqldat.com:5432 postgres> select now(), count(*) from pg_stat_activity where usename = 'postgres' and application_name = 'pgbench'; now | count
-------------------------------+-------
2019-05-03 23:39:18.200291+00 | 950
(1 row)…porém, o monitoramento da consulta acima mostra uma queda repentina no número de conexões de 950 para 628, em apenas 10 segundos:
example@sqldat.com:5432 postgres> \watch 10
Fri 03 May 2019 11:41:05 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:41:05.044025+00 | 950
(1 row)
...
Fri 03 May 2019 11:43:10 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:10.512766+00 | 950
(1 row)
Fri 03 May 2019 11:43:20 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:17.419011+00 | 628
(1 row)
Fri 03 May 2019 11:43:30 PM UTC (every 10s)
now | count
-------------------------------+-------
2019-05-03 23:43:31.434638+00 | 613
(1 row)Para contornar o problema de DNS, atribuí ao PGHOST o endereço IP do host:
[example@sqldat.com scripts]# set | grep PG
PGDATABASE=postgres
PGHOST=191.238.6.43
example@sqldat.com
PGPORT=5432
example@sqldat.comCom essa solução alternativa, reiniciei o teste:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
progress: 61.1 s, 457.7 tps, lat 559.138 ms stddev 1755.888
progress: 120.1 s, 78.8 tps, lat 3883.772 ms stddev 10551.545
progress: 180.1 s, 17.6 tps, lat 50831.708 ms stddev 31214.512
progress: 240.1 s, 15.2 tps, lat 42474.763 ms stddev 32702.050
progress: 300.1 s, 16.1 tps, lat 43584.559 ms stddev 29818.142
progress: 360.1 s, 26.5 tps, lat 36914.096 ms stddev 37152.588
progress: 420.0 s, 33.4 tps, lat 27542.926 ms stddev 37075.457
progress: 480.0 s, 20.2 tps, lat 47149.060 ms stddev 47087.474
progress: 540.0 s, 13.5 tps, lat 55609.260 ms stddev 60394.287
progress: 600.0 s, 36.5 tps, lat 49566.853 ms stddev 99155.598
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 950
number of threads: 950
duration: 600 s
number of transactions actually processed: 44293
latency average = 12493.888 ms
latency stddev = 40490.231 ms
tps = 60.907130 (including connections establishing)
tps = 64.213520 (excluding connections establishing)À primeira vista, as coisas pareciam ter funcionado bem, no entanto, os valores de latência extremamente altos, juntamente com os problemas anteriores de DNS e o cliente habilitado para “rede acelerada”, sugerem que algo está errado no nível da rede, e esse é o provável causa de resultados de tps baixos. Mas o pior ainda está por vir.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
sysbench
Primeiro, crie as tabelas:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepare
After a little while:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
FATAL: PQexec() failed: 7 server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
FATAL: failed query: CREATE TABLE sbtest1 (
id SERIAL NOT NULL,
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id)
)
FATAL: failed to execute function `prepare': 3Isso não parecia nada bom, então verifiquei os logs do PostgreSQL:
2019-05-03 23:51:12 UTC-5ccbbe4f.88-WARNING: worker took too long to start; canceled
2019-05-03 23:51:14 UTC-5ccbbe4f.84-PANIC: could not write to log file 000000010000001F000000CD at offset 13664256, length 8192: Invalid argument
+++ NT HARD ERROR (0xd0000144) +++
Parameter 0: 0xffffffffc0000005
Parameter 1: 0x1b80f0f73b
Parameter 2: 0x1
Parameter 3: 0x0Embora o serviço deva se recuperar sozinho, decidi reiniciar a instância para acelerar o processo.
2019-05-04 00:43:23 UTC-5ccce02a.2c-HINT: Is another postmaster already running on port 20108? If not, wait a few seconds and retry.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-04 00:43:23 UTC-5ccce02a.2c-LOG: listening on IPv4 address "0.0.0.0", port 20108
2019-05-04 00:43:24 UTC-5ccce02a.2c-LOG: database system is ready to accept connections
...
2019-05-05 00:03:35 UTC-5cce2856.2c-HINT: Is another postmaster already running on port 20326? If not, wait a few seconds and retry.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: could not bind IPv6 address "::": A socket operation was attempted to an unreachable host.
2019-05-05 00:03:35 UTC-5cce2856.2c-LOG: listening on IPv4 address "0.0.0.0", port 20326
2019-05-05 00:03:38 UTC-5cce285a.3c-FATAL: the database system is starting up
2019-05-05 00:03:38 UTC-5cce285a.3c-LOG: connection received: host=127.0.0.1 port=47247 pid=60
2019-05-05 00:03:49 UTC-5cce2865.40-FATAL: the database system is starting up
2019-05-05 00:03:49 UTC-5cce2865.40-LOG: connection received: host=127.0.0.1 port=47284 pid=64
2019-05-05 00:03:59 UTC-5cce286f.44-FATAL: the database system is starting up
2019-05-05 00:03:59 UTC-5cce286f.44-LOG: connection received: host=127.0.0.1 port=47312 pid=68
2019-05-05 00:04:00 UTC-5cce2856.2c-LOG: database system is ready to accept connections
2019-05-05 00:04:00 UTC-5cce2870.38-LOG: database system was shut down at 2019-05-05 00:03:34 UTCNeste ponto, também habilitei insights de desempenho de consulta:
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pgms_wait_sampling.query_capture_mode" changed to "ALL"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: parameter "pg_qs.query_capture_mode" changed to "TOP"
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce2856.2c-LOG: received SIGHUP, reloading configuration files
2019-05-05 00:04:13 UTC-5cce287a.6c-ERROR: database "azure_sys" already exists
2019-05-05 00:04:13 UTC-5cce287a.6c-STATEMENT: CREATE DATABASE azure_sys TEMPLATE template0Antes de reiniciar a tarefa sysbench, eu queria garantir que o banco de dados estivesse íntegro e, portanto, iniciei um segundo teste pgbench:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=950 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to database "postgres" failed:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.De acordo com o monitor de consulta pg_stat_activity, o servidor morreu quando o número de conexões atingiu 710:
example@sqldat.com:5432 postgres> \watch 1
Sun 05 May 2019 12:44:11 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:11.010413+00 | 220
(1 row)
Sun 05 May 2019 12:44:12 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:44:12.041667+00 | 231
(1 row)
...
now | count
------------------------------+-------
2019-05-05 00:47:33.16533+00 | 710
(1 row)
Sun 05 May 2019 12:47:40 AM UTC (every 1s)
now | count
-------------------------------+-------
2019-05-05 00:47:40.524662+00 | 710
(1 row)E pelos logs do PostgreSQL aprendemos que algo aconteceu ao longo do tubo de conexão:
2019-05-05 00:44:11 UTC-5cce31da.c60-LOG: connection received: host=40.114.85.62 port=50925 pid=3168
2019-05-05 00:44:11 UTC-5cce31db.c58-LOG: connection received: host=40.114.85.62 port=55256 pid=3160
2019-05-05 00:44:11 UTC-5cce31db.c5c-LOG: connection received: host=40.114.85.62 port=34526 pid=3164
2019-05-05 00:44:11 UTC-5cce31db.c64-LOG: connection received: host=40.114.85.62 port=1178 pid=3172
...
2019-05-05 00:47:32 UTC-5cce329a.146c-LOG: connection received: host=40.114.85.62 port=41769 pid=5228
2019-05-05 00:47:33 UTC-5cce3287.1404-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3288.1428-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3289.1434-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce3291.1448-LOG: connection authorized: user=postgresdatabase=postgres SSL enabled (protocol=TLSv1.1, cipher=ECDHE-RSA-AES256-SHA, compression=off)
2019-05-05 00:47:33 UTC-5cce32a3.1484-LOG: connection received: host=40.114.85.62 port=50296 pid=5252
2019-05-05 00:47:33 UTC-5cce32a5.1488-LOG: connection received: host=40.114.85.62 port=28304 pid=5256
2019-05-05 00:47:39 UTC-5cce31d2.a24-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31d5.ae8-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e3.ee4-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce31e9.1054-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:39 UTC-5cce3291.1444-LOG: could not receive data from client: An existing connection was forcibly closed by the remote host.
2019-05-05 00:47:40 UTC-5cce31cd.8ec-LOG: could not send data to client: An existing connection was forcibly closed by the remote host.Diante da limitação em max_connections e dos problemas encontrados durante os testes pgbench e sysbench, comecei a ficar curioso sobre se um banco de dados de 16 núcleos exibiria o mesmo comportamento.
Instância de banco de dados de 16 núcleos
Em uma instância de banco de dados de 16 núcleos, o limite max_connections é suficientemente grande para acomodar 1.000 clientes:
example@sqldat.com:5432 postgres> show max_connections ;
max_connections
-----------------
1900
(1 row)Isso me permitiu executar os mesmos comandos de benchmark que usei nos provedores de nuvem anteriores.
O benchmark foi concluído com sucesso e os resultados são mostrados abaixo:
pgbench
- Inicialização:
[example@sqldat.com scripts]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.08 s, remaining 807.39 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 628.37 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.16 s, remaining 527.89 s) ... 600100000 of 1000000000 tuples (60%) done (elapsed 2499.90 s, remaining 1665.90 s) 600200000 of 1000000000 tuples (60%) done (elapsed 2500.07 s, remaining 1665.33 s) ... 999900000 of 1000000000 tuples (99%) done (elapsed 4170.91 s, remaining 0.42 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 4171.29 s, remaining 0.00 s) vacuum... set primary keys... total time: 13701.50 s (insert 4173.33 s, commit 0.05 s, vacuum 7098.74 s, index 2429.39 s) done. - Executar:
[example@sqldat.com scripts]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048 starting vacuum...end. progress: 81.4 s, 5639.1 tps, lat 80.094 ms stddev 73.213 progress: 120.0 s, 4091.0 tps, lat 224.161 ms stddev 608.523 progress: 180.0 s, 6932.1 tps, lat 145.143 ms stddev 228.925 progress: 240.0 s, 7287.9 tps, lat 136.521 ms stddev 156.643 progress: 300.0 s, 7567.8 tps, lat 132.722 ms stddev 158.754 progress: 360.0 s, 8077.9 tps, lat 123.801 ms stddev 139.033 progress: 420.0 s, 6076.9 tps, lat 163.886 ms stddev 201.121 progress: 480.0 s, 5376.2 tps, lat 186.678 ms stddev 191.270 progress: 540.0 s, 4864.0 tps, lat 205.696 ms stddev 164.261 progress: 600.0 s, 3759.3 tps, lat 266.073 ms stddev 542.717 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 3614386 latency average = 152.935 ms latency stddev = 248.593 ms tps = 6002.082008 (including connections establishing) tps = 6513.306467 (excluding connections establishing)
Isso correu razoavelmente bem, no entanto, não há uma maneira válida de comparar esses resultados com os da AWS e G Cloud, pois não estamos testando em uma plataforma semelhante. Mas isso é bom o suficiente para nos levar ao próximo ponto.
sysbench
Como os testes do pgbench foram concluídos com sucesso, decidi aproveitar ao máximo o crédito de US$ 200 do Azure e confirmar que o sysbench vai além da execução anterior na instância de 8 núcleos:
sysbench \
--test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=191.238.6.43 \
--pgsql-db=postgres \
example@sqldat.com \
example@sqldat.com \
--pgsql-port=5432 \
--oltp-tables-count=250 \
--oltp-table-size=450000 prepare
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
Creating secondary indexes on 'sbtest2'...
Creating table 'sbtest3'...
Inserting 450000 records into 'sbtest3'
Creating secondary indexes on 'sbtest3'...
Creating table 'sbtest4'...Isso parecia estar funcionando bem e, como eu estava chegando perto do meu orçamento, decidi interromper a tarefa.
Hiperescala (Citus)
Embora não esteja pronta para produção, essa opção merece ser analisada, pois fornece recursos avançados não disponíveis na AWS e G Cloud.
Como resultado da aquisição da Citus Data, a Microsoft oferece uma versão prévia de seu principal produto PostgreSQL, sob o nome de Hyperscale (Citus).
O assistente do portal facilita a configuração de um ambiente complicado:
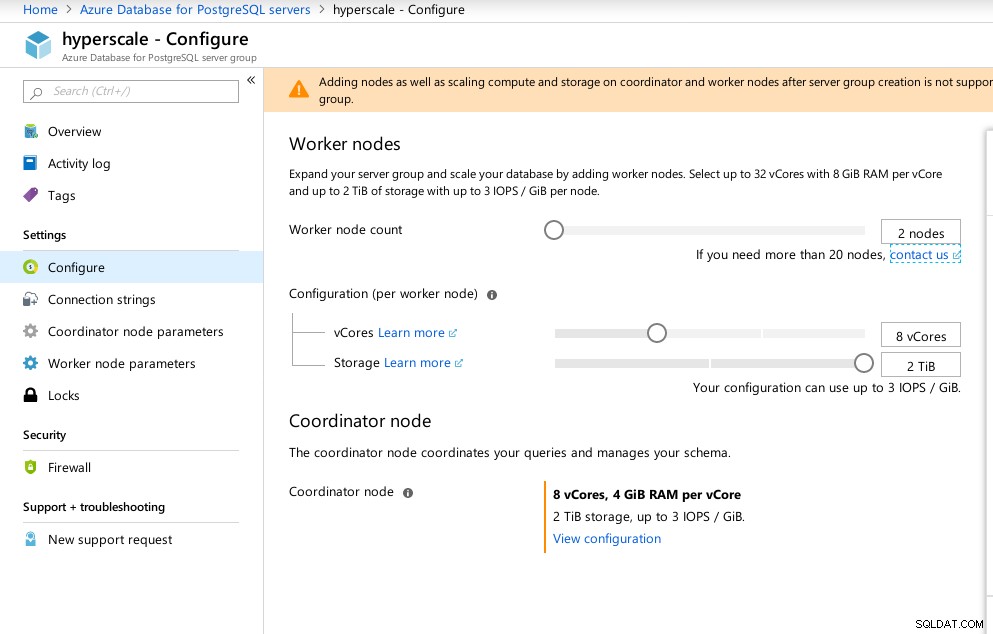 Configuração de hiperescala do Azure (Citus)
Configuração de hiperescala do Azure (Citus) Observei que, ao contrário do Azure PostgreSQL, que é executado no Windows, o Hyperscale é executado no Linux:
example@sqldat.com:5432 citus> select version();
version
----------------------------------------------------------------------------------------------------------------
PostgreSQL 11.2 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609, 64-bit
(1 row)Infelizmente, enquanto o Hyperscale estava prometendo uma jornada emocionante, neste momento não pude prosseguir com a execução dos testes, pois max_connections está atualmente limitado a 300, sem opção de ajuste, embora a capacidade esteja documentada para o Citus PosgreSQL nativo:
example@sqldat.com:5432 citus> show max_connections ;
max_connections
-----------------
300
(1 row)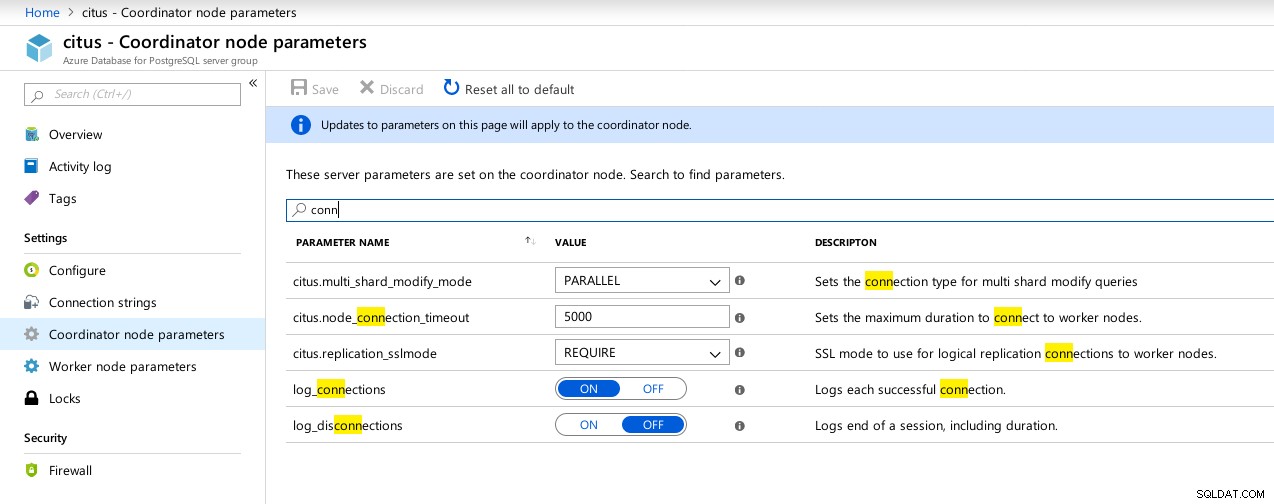 Hyperscale (Citus) Coordinator conexões disponíveis parâmetros
Hyperscale (Citus) Coordinator conexões disponíveis parâmetros 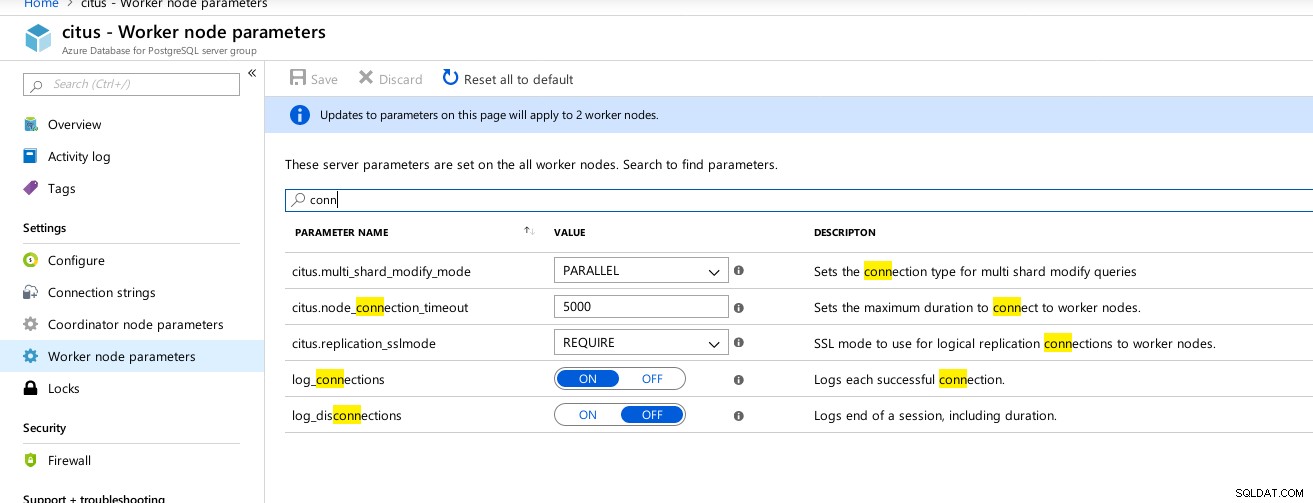 Hyperscale (Citus) Trabalhadores:max_connections não disponível
Hyperscale (Citus) Trabalhadores:max_connections não disponível Métricas de referência
Algumas métricas indicativas do desempenho e comportamento do cliente e do servidor:
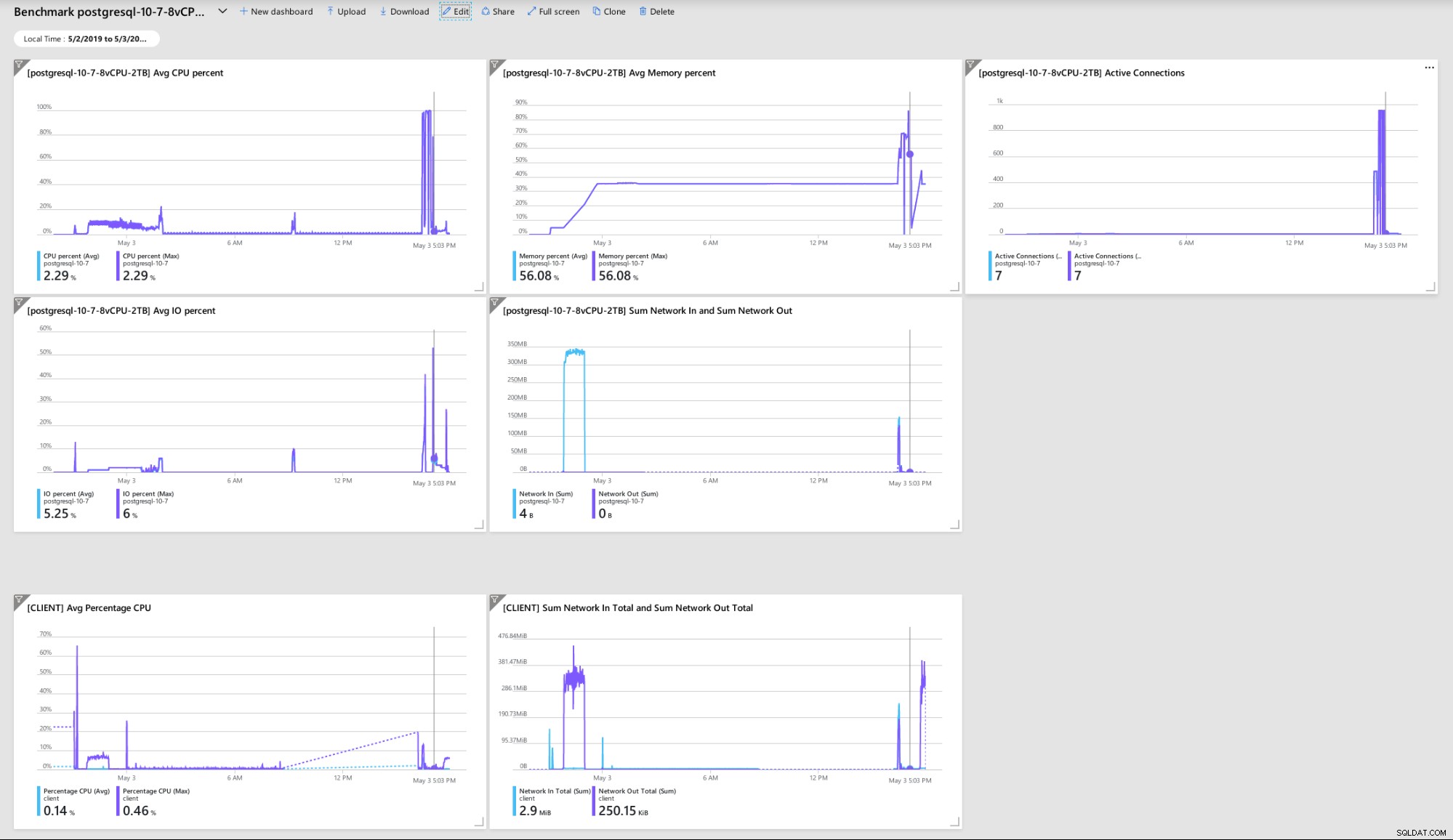 Azure Portal Dashboard - Métricas para cliente e servidor
Azure Portal Dashboard - Métricas para cliente e servidor Métricas do PostgreSQL coletadas usando o Query Performance Insight:
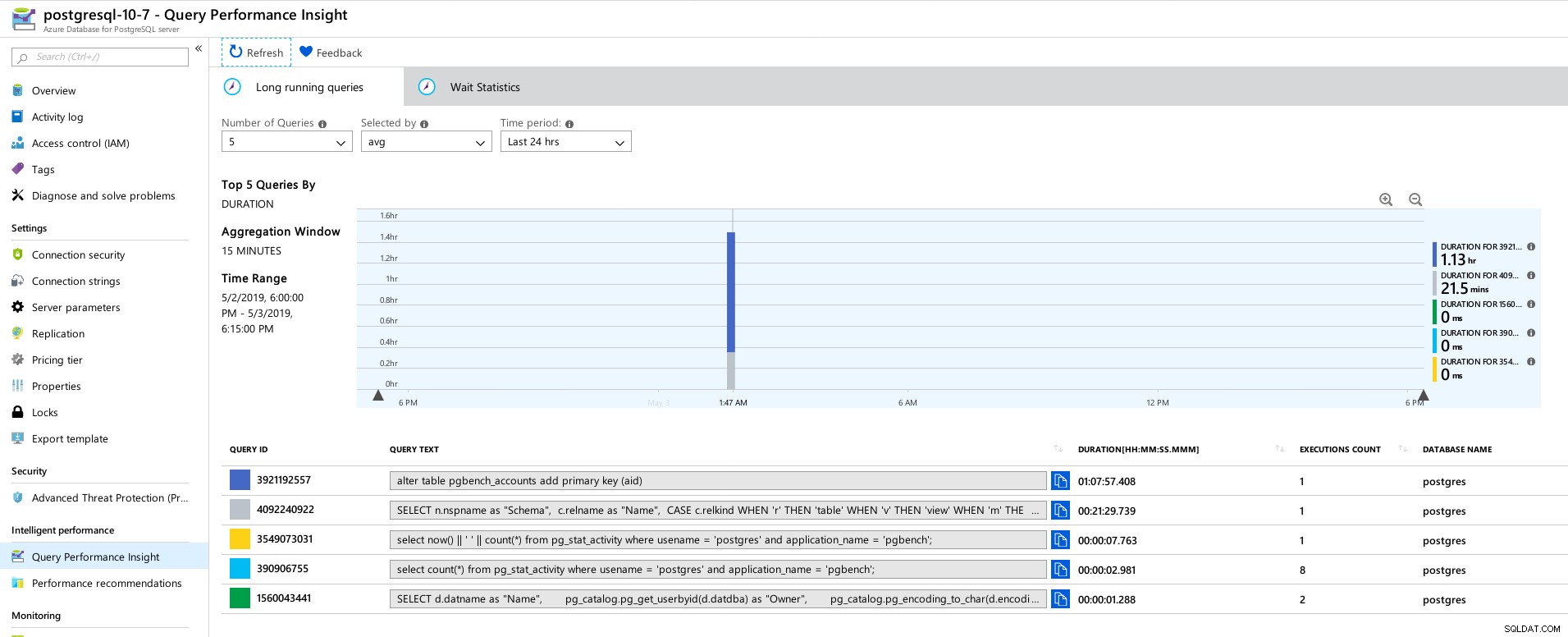 Azure PostgreSQL - Insights de desempenho da consulta:as 5 principais consultas
Azure PostgreSQL - Insights de desempenho da consulta:as 5 principais consultas 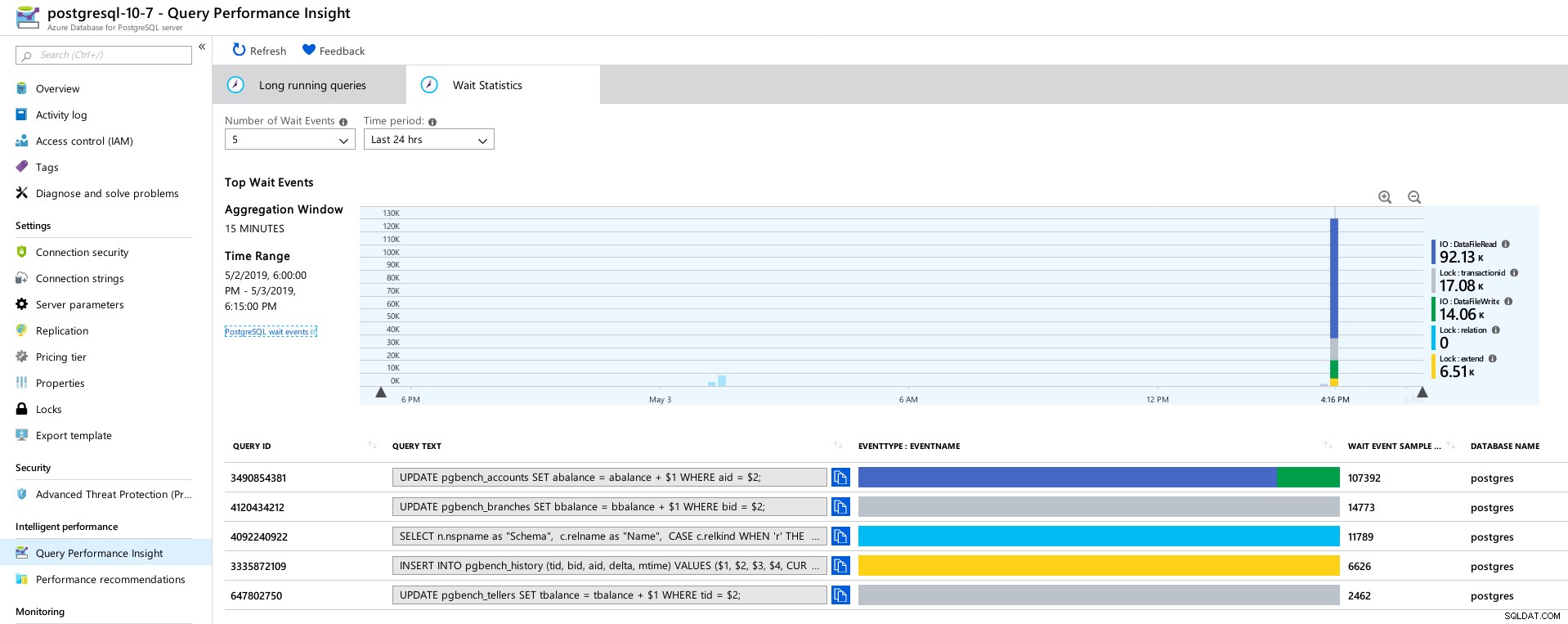 Azure PostgreSQL - Insights de desempenho da consulta:5 principais esperas
Azure PostgreSQL - Insights de desempenho da consulta:5 principais esperas Conclusão
Recursos relacionados Benchmarking de soluções de nuvem PostgreSQL gerenciados - parte um:Amazon Aurora Benchmarking de soluções de nuvem PostgreSQL gerenciados - parte dois:Amazon RDS Benchmarking de soluções de nuvem PostgreSQL gerenciados - parte três:Google CloudPrimeiro, se você chegou até aqui, obrigado por ler, e se você identificar algum erro que possa ter causado o mau comportamento do ambiente, eu agradeceria muito o feedback. Desde que eu tenha perdido algo óbvio, estou disposto a repetir os testes.
A falha do mecanismo de banco de dados que leva ao despejo hexadecimal “NT HARD ERROR” indica que algo fora do controle do usuário aconteceu e um bom serviço gerenciado se recuperaria por meio de automação ou alertando os SREs responsáveis. Se eu tivesse esperado mais tempo, poderia ter sido o caso, embora levante a questão de quanto tempo os usuários devem esperar até que o serviço seja restaurado.
Bloquear max_connections em um valor baseado no tipo de preço e vCores me pegou de surpresa, principalmente depois de testar os outros três serviços gerenciados, com o Google Cloud permitindo que o parâmetro fosse configurado pelo usuário, mesmo que o valor padrão fosse bem menor (600 no G Nuvem vs 960 no Azure).
Um teste com a instância de banco de dados no intervalo de 16 núcleos pode ser necessário para evitar alterar os valores padrão, embora naquele momento eu prefira testar usando ferramentas melhores, como o HammerDB (consulte a Parte 1 para uma discussão sobre ferramentas) .