No meu artigo anterior, iniciei uma nova série sobre travas explicando o que são, por que são necessárias e a mecânica de como funcionam, e recomendo fortemente que você leia esse artigo antes deste. Neste artigo vou discutir a trava FGCB_ADD_REMOVE e mostrar como ela pode ser um gargalo.
O que é a trava FGCB_ADD_REMOVE?
A maioria dos nomes de classes de travas está vinculada diretamente à estrutura de dados que eles protegem. A trava FGCB_ADD_REMOVE protege uma estrutura de dados chamada FGCB, ou Bloco de Controle de Grupo de Arquivos, e haverá uma dessas travas para cada grupo de arquivos online de cada banco de dados online em uma instância do SQL Server. Sempre que um arquivo em um grupo de arquivos é adicionado, descartado, aumentado ou reduzido, a trava deve ser adquirida no modo EX e, ao descobrir o próximo arquivo a ser alocado, a trava deve ser adquirida no modo SH para evitar alterações no grupo de arquivos. (Lembre-se de que as alocações de extensão para um grupo de arquivos são executadas em rodízio por meio dos arquivos no grupo de arquivos e também levam em consideração o preenchimento proporcional , que explico aqui.)
Como a trava se torna um gargalo?
O cenário mais comum quando essa trava se torna um gargalo é o seguinte:
- Há um banco de dados de arquivo único, portanto, todas as alocações devem vir desse arquivo de dados
- A configuração de crescimento automático para o arquivo está definida como muito pequena (lembre-se, antes do SQL Server 2016, a configuração de crescimento automático padrão para arquivos de dados era de 1 MB!)
- Existem muitas operações simultâneas que exigem espaço para alocação (por exemplo, uma carga de trabalho de inserção constante de muitas conexões de clientes)
Nesse caso, mesmo que haja apenas um arquivo, uma thread que requer uma alocação ainda precisa adquirir o latch FGCB_ADD_REMOVE no modo SH. Em seguida, ele tentará alocar a partir do arquivo de dados único, perceberá que não há espaço e, em seguida, adquirirá a trava no modo EX para que possa aumentar o arquivo.
Vamos imaginar que oito threads rodando em oito agendadores separados tentam alocar ao mesmo tempo, e todos percebem que não há espaço no arquivo, então eles precisam aumentá-lo. Cada um deles tentará adquirir a trava no modo EX. Apenas um deles poderá adquiri-lo e prosseguirá com o crescimento do arquivo e os demais terão que esperar, com um tipo de espera de LATCH_EX e uma descrição de recurso de FGCB_ADD_REMOVE mais o endereço de memória do latch.
Os sete encadeamentos em espera estão na fila de espera do primeiro a entrar, primeiro a sair (FIFO) da trava. Quando o thread que executa o crescimento do arquivo é concluído, ele libera a trava e a concede ao primeiro thread em espera. Esse novo dono do trinco vai aumentar o arquivo e descobre que já cresceu e não tem o que fazer. Portanto, ele libera a trava e a concede ao próximo thread em espera. E assim por diante.
Todos os sete threads em espera esperaram pelo latch no modo EX, mas acabaram não fazendo nada quando receberam o latch, então todos os sete threads essencialmente desperdiçaram tempo decorrido, com a quantidade de tempo desperdiçada aumentando um pouco para cada thread mais para baixo a fila de espera FIFO era.
Mostrando o gargalo
Agora vou mostrar o cenário exato acima, usando eventos estendidos. Eu criei um banco de dados de arquivo único com uma pequena configuração de crescimento automático e centenas de conexões simultâneas simplesmente inserindo dados em uma tabela.
Posso usar a seguinte sessão de evento estendida para ver o que está acontecendo:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO A sessão está rastreando quando um encadeamento entra na fila de espera da trava, quando sai da fila (ou seja, quando recebe a trava) e quando ocorre um crescimento de arquivo de dados. Usar o rastreamento de causalidade significa que podemos ver uma linha do tempo das ações de cada thread.
Usando o SQL Server Management Studio, posso selecionar a opção Watch Live Data para a sessão de evento estendido e ver toda a atividade do evento estendido. Se você quiser fazer o mesmo, na janela Live Data, clique com o botão direito do mouse em um dos nomes das colunas na parte superior e altere as colunas selecionadas como abaixo:
Deixei a carga de trabalho funcionar por alguns minutos para atingir um estado estável e então vi um exemplo perfeito do cenário que descrevi acima:
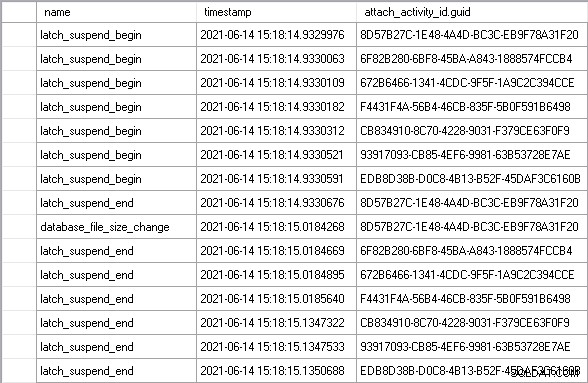
Usando o attach_activity_id.guid valores para identificar encadeamentos diferentes, podemos ver que sete encadeamentos começam a aguardar a trava em 61,5 microssegundos. A thread com o valor GUID começando em 8D57 adquire a trava no modo EX (o latch_suspend_end evento) e, em seguida, aumenta imediatamente o arquivo (o database_file_size_change evento). A thread 8D57 então libera a trava e a concede no modo EX para a thread 6F82, que esperou por 85 milissegundos. Ele não tem nada a fazer, então ele concede a trava ao thread 672B. E assim por diante, até que o encadeamento EDB8 receba a trava, após aguardar 202 milissegundos.
No total, os seis threads que esperaram sem motivo esperaram quase 1 segundo. Parte desse tempo é o tempo de espera do sinal, onde mesmo que o encadeamento tenha recebido o latch, ele ainda precisa subir para o topo da fila executável do escalonador antes de poder entrar no processador e executar o código. Você pode dizer que esta não é uma medida justa de tempo gasto esperando pela trava, mas é absolutamente, porque o tempo de espera do sinal não teria sido incorrido se o encadeamento não tivesse que esperar em primeiro lugar.
Além disso, você pode pensar que um atraso de 200 milissegundos não é muito, mas tudo depende dos acordos de nível de serviço de desempenho para a carga de trabalho em questão. Temos vários clientes de alto volume onde, se um lote demorar mais de 200 milissegundos para ser executado, não é permitido no sistema de produção!
Resumo
Se você estiver monitorando esperas em seu servidor e perceber que LATCH_EX é uma das principais esperas, você pode usar o código neste post para ver se FGCB_ADD_REMOVE é um dos culpados.
A maneira mais fácil de garantir que sua carga de trabalho não esteja atingindo um gargalo FGCB_ADD_REMOVE é certificar-se de que não há configurações de crescimento automático de arquivo de dados configuradas usando os padrões anteriores ao SQL Server 2016. Nos sys.master_files visualização, o padrão de 1 MB seria mostrado como um arquivo de dados (type_desc coluna definida como ROWS) com o is_percent_growth coluna definida como 0 e a coluna de crescimento definida como 128.
Dar uma recomendação para o que o crescimento automático deve ser definido é outra discussão, mas agora você sabe de um possível impacto no desempenho por não alterar os padrões em versões anteriores.