O particionamento de tabela no SQL Server é essencialmente uma maneira de fazer com que várias tabelas físicas (conjuntos de linhas) pareçam uma única tabela. Essa abstração é realizada inteiramente pelo processador de consultas, um design que torna as coisas mais simples para os usuários, mas que torna as demandas complexas do otimizador de consultas. Esta postagem analisa dois exemplos que excedem as habilidades do otimizador no SQL Server 2008 em diante.
Ingressar na Ordem das Colunas
Este primeiro exemplo mostra como a ordem textual de
ON as condições da cláusula podem afetar o plano de consulta produzido ao unir tabelas particionadas. Para começar, precisamos de um esquema de particionamento, uma função de particionamento e duas tabelas:CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Em seguida, carregamos ambas as tabelas com 150.000 linhas. Os dados não importam muito; este exemplo usa uma tabela Numbers padrão contendo todos os valores inteiros de 1 a 150.000 como fonte de dados. Ambas as tabelas são carregadas com os mesmos dados.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Nossa consulta de teste executa uma junção interna simples dessas duas tabelas. Novamente, a consulta não é importante ou pretende ser particularmente realista, ela é usada para demonstrar um efeito estranho ao unir tabelas particionadas. A primeira forma da consulta usa um
ON cláusula escrita na ordem das colunas c3, c2, c1:SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
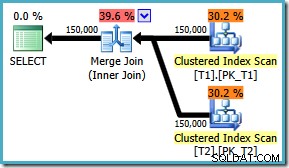
AND t1.c1 = t2.c1; O plano de execução produzido para esta consulta (no SQL Server 2008 e posterior) apresenta uma junção de hash paralela, com um custo estimado de 2,6953 :
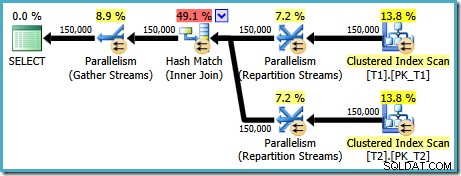
Isso é um pouco inesperado. Ambas as tabelas têm um índice clusterizado na ordem (c1, c2, c3), particionado por c1, portanto, esperaríamos uma junção de mesclagem, aproveitando a ordenação do índice. Vamos tentar escrever o
ON cláusula na ordem (c1, c2, c3) em vez disso:SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; O plano de execução agora usa a junção de mesclagem esperada, com um custo estimado de 1,64119 (reduzido de 2,6953 ). O otimizador também decide que não vale a pena usar a execução paralela:
Observando que o plano de junção de mesclagem é claramente mais eficiente, podemos tentar forçar uma junção de mesclagem para o
ON original ordem da cláusula usando uma dica de consulta:SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); O plano resultante usa uma junção de mesclagem conforme solicitado, mas também apresenta classificações em ambas as entradas e volta a usar o paralelismo. O custo estimado deste plano é de impressionantes 8,71063 :
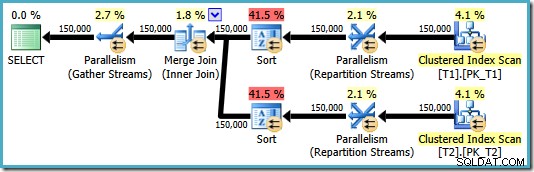
Ambos os operadores de classificação têm as mesmas propriedades:
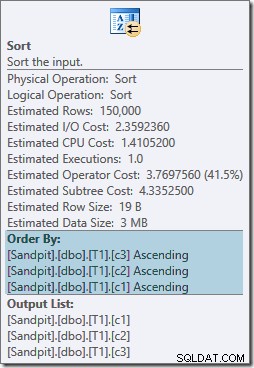
O otimizador acha que a junção de mesclagem precisa de suas entradas classificadas na ordem estrita de escrita do
ON cláusula, introduzindo classificações explícitas como resultado. O otimizador está ciente de que uma junção de mesclagem requer suas entradas classificadas da mesma maneira, mas também sabe que a ordem das colunas não importa. A junção de mesclagem em (c1, c2, c3) fica igualmente feliz com entradas classificadas em (c3, c2, c1) como com entradas classificadas em (c2, c1, c3) ou qualquer outra combinação. Infelizmente, esse raciocínio é quebrado no otimizador de consulta quando o particionamento está envolvido. Este é um bug do otimizador que foi corrigido no SQL Server 2008 R2 e posterior, embora o sinalizador de rastreamento 4199 é necessário para ativar a correção:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199); Você normalmente habilitaria este sinalizador de rastreamento usando
DBCC TRACEON ou como uma opção de inicialização, porque o QUERYTRACEON dica não está documentada para uso com 4199. O sinalizador de rastreamento é necessário no SQL Server 2008 R2, SQL Server 2012 e SQL Server 2014 CTP1. De qualquer forma, sempre que o sinalizador estiver ativado, a consulta agora produz a junção de mesclagem ideal, qualquer que seja o
ON ordenação da cláusula: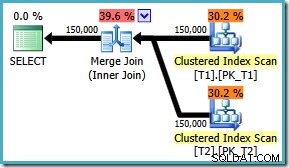
Não há nenhuma correção para o SQL Server 2008 , a solução alternativa é escrever o
ON cláusula na ordem "certa"! Se você encontrar uma consulta como essa no SQL Server 2008, tente forçar uma junção de mesclagem e observe as classificações para determinar a maneira 'correta' de escrever o ON da sua consulta cláusula. Esse problema não surge no SQL Server 2005 porque essa versão implementou consultas particionadas usando o
APPLY modelo:
O plano de consulta do SQL Server 2005 une uma partição de cada tabela por vez, usando uma tabela na memória (o Constant Scan) contendo números de partição a serem processados. Cada partição é unida separadamente no lado interno da junção, e o otimizador de 2005 é inteligente o suficiente para ver que o
ON a ordem das colunas da cláusula não importa. Este plano mais recente é um exemplo de uma junção de mesclagem colocada , um recurso que foi perdido ao migrar do SQL Server 2005 para a nova implementação de particionamento no SQL Server 2008. Uma sugestão em Conectar para restabelecer junções de mesclagem colocadas foi fechada como não será corrigida.
Agrupar por questões de pedido
A segunda peculiaridade que quero observar segue um tema semelhante, mas está relacionado à ordem das colunas em um
GROUP BY cláusula em vez da ON cláusula de uma junção interna. Vamos precisar de uma nova tabela para demonstrar:CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; A tabela tem um índice não clusterizado alinhado, onde ‘alinhado’ significa simplesmente que é particionado da mesma forma que o índice clusterizado (ou heap):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Nossa consulta de teste agrupa dados nas três colunas de índice não clusterizadas e retorna uma contagem para cada grupo:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
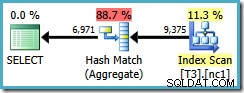
O plano de consulta verifica o índice não clusterizado e usa um Hash Match Aggregate para contar as linhas em cada grupo:
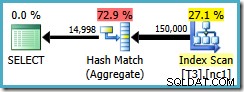
Existem dois problemas com o Hash Aggregate:
- É um operador de bloqueio. Nenhuma linha é retornada ao cliente até que todas as linhas tenham sido agregadas.
- Requer uma concessão de memória para manter a tabela de hash.
Em muitos cenários do mundo real, preferimos um Stream Aggregate aqui porque esse operador está bloqueando apenas por grupo e não requer uma concessão de memória. Usando essa opção, o aplicativo cliente começaria a receber dados mais cedo, não precisaria esperar a concessão de memória e o SQL Server poderia usar a memória para outros fins.
Podemos exigir que o otimizador de consulta use um Stream Aggregate para essa consulta adicionando uma
OPTION (ORDER GROUP) dica de consulta. Isso resulta no seguinte plano de execução:
O operador Sort está bloqueando totalmente e também requer uma concessão de memória, portanto, esse plano parece ser pior do que simplesmente usar um agregado de hash. Mas por que o tipo é necessário? As propriedades mostram que as linhas estão sendo classificadas na ordem especificada pelo nosso
GROUP BY cláusula: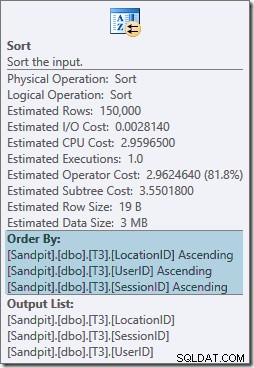
Essa classificação é esperada porque o alinhamento de partição do índice (no SQL Server 2008 em diante) significa que o número da partição é adicionado como uma coluna inicial do índice. Na verdade, as chaves de índice não clusterizadas são (partição, usuário, sessão, local) devido ao particionamento. As linhas no índice ainda são classificadas por usuário, sessão e local, mas apenas dentro de cada partição.
Se restringirmos a consulta a uma única partição, o otimizador poderá usar o índice para alimentar um Stream Aggregate sem classificar. Caso isso exija alguma explicação, especificar uma única partição significa que o plano de consulta pode eliminar todas as outras partições da varredura de índice não clusterizado, resultando em um fluxo de linhas ordenado por (usuário, sessão, local).
Podemos conseguir essa eliminação de partição explicitamente usando o
$PARTITION função:SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Infelizmente, esta consulta ainda usa um Hash Aggregate, com um custo de plano estimado de 0,287878 :
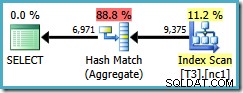
A varredura agora é um pouco mais de uma partição, mas a ordenação (usuário, sessão, local) não ajudou o otimizador a usar um Stream Aggregate. Você pode objetar que a ordenação (usuário, sessão, local) não é útil porque o
GROUP BY cláusula é (local, usuário, sessão), mas a ordem das chaves não importa para uma operação de agrupamento. Vamos adicionar um
ORDER BY cláusula na ordem das chaves de índice para provar o ponto:SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Observe que o
ORDER BY cláusula corresponde à ordem de chave de índice não clusterizado, embora o GROUP BY cláusula não. O plano de execução para esta consulta é: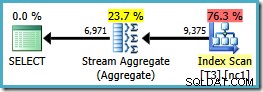
Agora temos o Stream Aggregate que procurávamos, com um custo de plano estimado de 0,0423925 (comparado com 0,287878 para o plano Hash Aggregate – quase 7 vezes mais).
A outra maneira de obter um Stream Aggregate aqui é reordenar o
GROUP BY colunas para corresponder às chaves de índice não clusterizadas:SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Essa consulta produz o mesmo plano Stream Aggregate mostrado imediatamente acima, com exatamente o mesmo custo. Essa sensibilidade para
GROUP BY a ordem das colunas é específica para consultas de tabela particionada no SQL Server 2008 e posterior. Você pode reconhecer que a causa raiz do problema aqui é semelhante ao caso anterior envolvendo um Merge Join. Tanto o Merge Join quanto o Stream Aggregate exigem entrada classificada nas chaves de junção ou agregação, mas nenhum deles se preocupa com a ordem dessas chaves. Uma junção de mesclagem em (x, y, z) é tão feliz recebendo linhas ordenadas por (y, z, x) ou (z, y, x) e o mesmo vale para Stream Aggregate.
Essa limitação do otimizador também se aplica a
DISTINCT nas mesmas circunstâncias. A consulta a seguir resulta em um plano Hash Aggregate com um custo estimado de 0,286539 :SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
Se escrevermos o
DISTINCT colunas na ordem das chaves de índice não clusterizadas… SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…somos recompensados com um plano Stream Aggregate com um custo de 0,041455 :

Para resumir, esta é uma limitação do otimizador de consulta no SQL Server 2008 e posterior (incluindo SQL Server 2014 CTP 1) que não é resolvido usando o sinalizador de rastreamento 4199 como foi o caso do exemplo Merge Join. O problema ocorre apenas com tabelas particionadas com um
GROUP BY ou DISTINCT em três ou mais colunas usando um índice particionado alinhado, onde uma única partição é processada. Assim como no exemplo Merge Join, isso representa um retrocesso do comportamento do SQL Server 2005. O SQL Server 2005 não adicionou uma chave principal implícita a índices particionados, usando um
APPLY técnica em vez disso. No SQL Server 2005, todas as consultas apresentadas aqui usando $PARTITION para especificar uma única partição resulta em planos de consulta que executam a eliminação de partição e usam Stream Aggregates sem qualquer reordenação de texto de consulta. As alterações no processamento de tabelas particionadas no SQL Server 2008 melhoraram o desempenho em várias áreas importantes, principalmente relacionadas ao processamento paralelo eficiente de partições. Infelizmente, essas mudanças tiveram efeitos colaterais que nem todos foram resolvidos em versões posteriores.