SQL Server 2014 SP2 e versões posteriores produzem planos de execução de tempo de execução (“reais”) que podem incluir tempo decorrido e uso da CPU para cada operador de plano de execução (consulte KB3170113 e esta postagem de blog de Pedro Lopes).
Interpretar esses números nem sempre é tão simples quanto se poderia esperar. Existem diferenças importantes entre o modo de linha e modo em lote execução, bem como problemas complicados com o modo de linha paralelismo . O SQL Server faz alguns ajustes de tempo em planos paralelos para promover a consistência, mas eles não são perfeitamente implementados. Isso pode dificultar a obtenção de conclusões sólidas de ajuste de desempenho.
Este artigo tem como objetivo ajudá-lo a entender de onde vêm os tempos em cada caso e como eles podem ser melhor interpretados no contexto.
Configuração
Os exemplos a seguir usam o Stack Overflow 2013 público banco de dados (detalhes do download), com um único índice adicionado:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
As consultas de teste retornam o número de perguntas com resposta aceita, agrupadas por mês e ano. Eles são executados no SQL Server 2019 CU9 , em um laptop com 8 núcleos e 16 GB de memória alocados para a instância do SQL Server 2019. Nível de compatibilidade 150 é usado exclusivamente.
Execução serial em modo de lote
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); O plano de execução é (clique para ampliar):
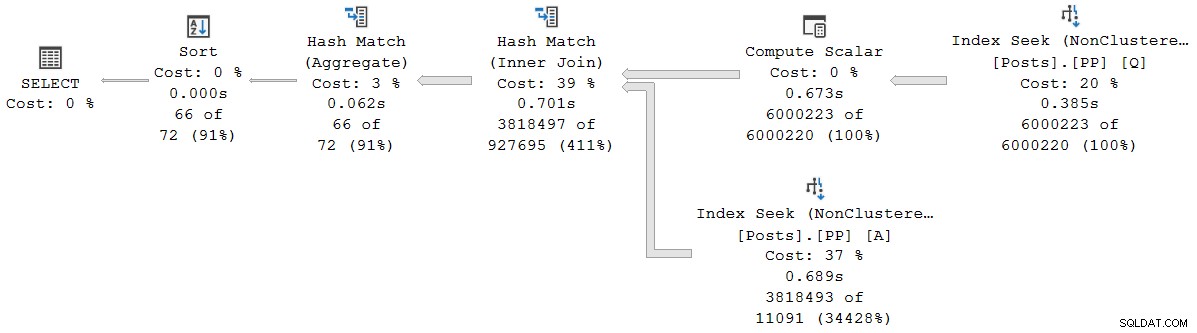
Todos os operadores neste plano são executados em modo de lote, graças ao modo de lote no rowstore Recurso de processamento de consulta inteligente no SQL Server 2019 (sem necessidade de índice columnstore). A consulta é executada por 2.523 ms com tempo de CPU de 2.522ms usado, quando todos os dados necessários já estão no buffer pool.
Como Pedro Lopes observa na postagem do blog vinculada anteriormente, os tempos decorridos e de CPU relatados para o modo de lote individual operadores representam o tempo usado por somente por esse operador .
O SSMS exibe tempo decorrido na representação gráfica. Para ver os tempos de CPU , selecione um operador de plano e procure nas Propriedades janela. Essa visualização detalhada mostra o tempo decorrido e de CPU, por operador e por encadeamento.
Os horários do showplan (incluindo a representação XML) são truncados a milissegundos. Se você precisar de maior precisão, use o
query_thread_profile evento estendido, que relata em microssegundos . A saída deste evento para o plano de execução mostrado acima é: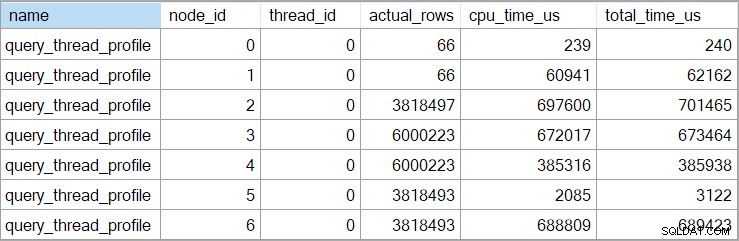
Isso mostra que o tempo decorrido para a junção (nó 2) é de 701.465µs (truncado para 701ms no plano de exibição). O agregado tem um tempo decorrido de 62.162µs (62ms). A busca do índice de 'questões' é exibida como sendo executada por 385ms, enquanto o evento estendido mostra que o valor real para o nó 4 foi de 385.938µs (quase 386ms).
O SQL Server usa o alta precisão QueryPerformanceCounter API para capturar dados de tempo. Isso usa hardware, normalmente um oscilador de cristal, que produz tiques a uma taxa constante muito alta, independentemente da velocidade do processador, configurações de energia ou qualquer coisa dessa natureza. O relógio continua funcionando na mesma taxa, mesmo durante o sono. Veja o artigo muito detalhado vinculado se estiver interessado em todos os detalhes mais sutis. O breve resumo é que você pode confiar que os números de microssegundos são precisos.
Neste plano de modo de lote puro, o tempo total de execução é muito próximo da soma dos tempos decorridos do operador individual. A diferença se deve em grande parte ao trabalho pós-extrato não associado aos operadores de plano (que já foram todos fechados até então), embora o truncamento de milissegundos também desempenhe um papel.
Em planos de modo de lote puro, você precisa somar manualmente os tempos atuais e do operador filho para obter o cumulativo tempo decorrido em qualquer nó.
Execução paralela do modo de lote
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); O plano de execução é:
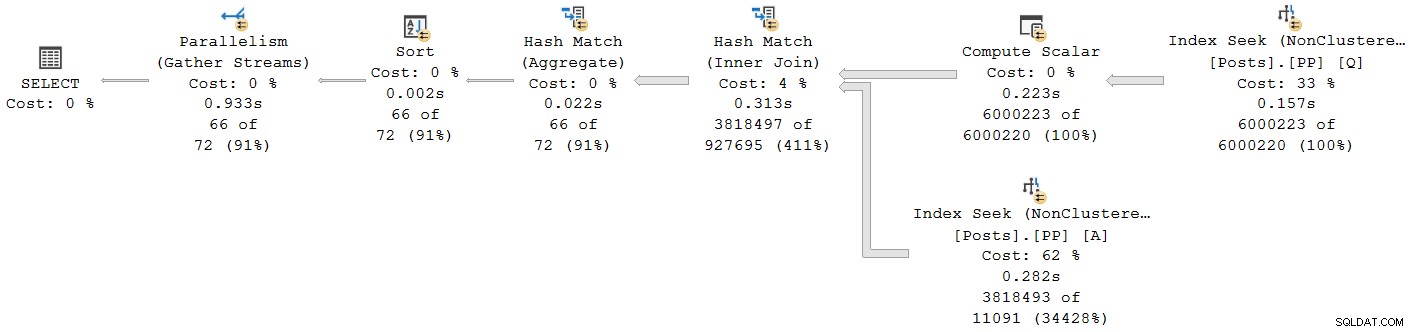
Todos os operadores, exceto a troca de fluxo de coleta final, são executados no modo de lote. O tempo total decorrido é 933ms com 6.673ms de tempo de CPU com cache quente.
Selecionando a junção de hash e procurando nas Propriedades do SSMS janela, vemos decorrido e tempo de CPU por thread para esse operador:
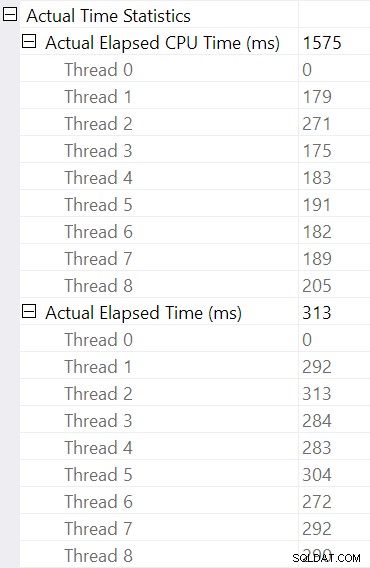
O tempo de CPU informado para o operador é a soma dos tempos de CPU de thread individuais. O operador informado tempo decorrido é o máximo dos tempos decorridos por thread. Ambos os cálculos são executados sobre os valores de milissegundos truncados por thread. Como antes, o tempo total de execução é muito próximo da soma dos tempos decorridos do operador individual.
Os planos paralelos do modo de lote não usam trocas para distribuir o trabalho entre os encadeamentos. Os operadores de lote são implementados para que vários threads possam trabalhar com eficiência em uma única estrutura compartilhada (por exemplo, tabela de hash). Alguma sincronização entre threads ainda é necessária nos planos paralelos do modo de lote, mas os pontos de sincronização e outros detalhes não são visíveis na saída do plano de exibição.
Execução serial em modo de linha
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); O plano de execução é visualmente igual ao plano serial do modo de lote, mas todos os operadores agora estão executando no modo de linha:
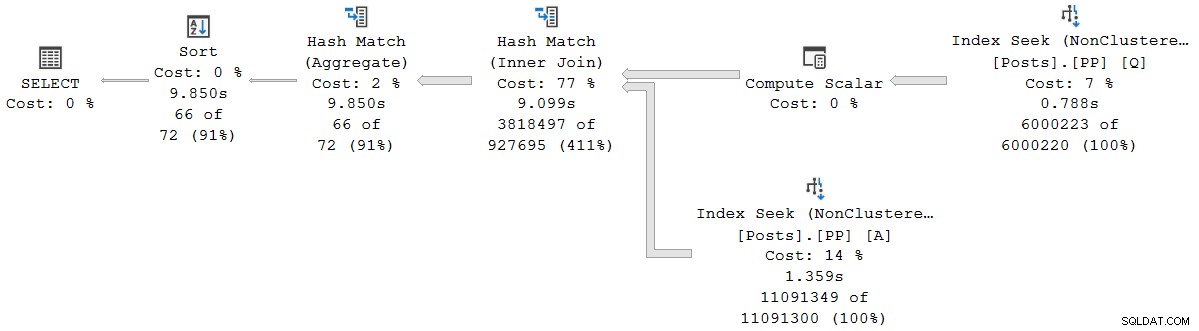
A consulta é executada por 9.850 ms com tempo de CPU de 9.845ms. Isso é muito mais lento do que a consulta do modo de lote serial (2523ms/2522ms), conforme esperado. Mais importante para a presente discussão, o modo de linha operador decorrido e tempos de CPU representam o tempo usado pelo operador atual e todos os seus filhos .
O evento estendido também mostra a CPU cumulativa e os tempos decorridos em cada nó (em microssegundos):
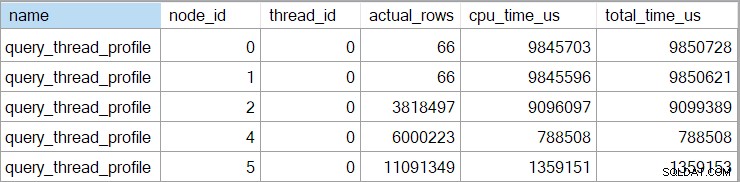
Não há dados para o operador escalar de computação (nó 3) porque a execução no modo de linha pode adiar a maioria dos cálculos de expressão para o operador que consome o resultado. No momento, isso não está implementado para execução em modo de lote.
O cumulativo relatado o tempo decorrido para operadores de modo de linha significa que o tempo mostrado para o operador de classificação final corresponde ao tempo total de execução da consulta (para resolução de milissegundos de qualquer maneira). O tempo decorrido para a junção de hash também inclui contribuições das duas buscas de índice abaixo dele, bem como seu próprio tempo. Para calcular o tempo decorrido para a junção de hash do modo de linha sozinha, precisaríamos subtrair os dois tempos de busca dela.
Existem vantagens e desvantagens em ambas as apresentações (cumulativo para o modo de linha, operador individual apenas para o modo de lote). Seja qual você preferir, é importante estar ciente das diferenças.
Planos de modo de execução misto
Em geral, os planos de execução modernos podem conter qualquer combinação de operadores de modo de linha e modo de lote. Os operadores do modo de lote reportarão os horários apenas para eles. Os operadores de modo de linha incluirão um total cumulativo até esse ponto no plano, incluindo todos operadores filhos. Para ser claro:os tempos cumulativos de um operador de modo de linha incluem qualquer operador filho do modo de lote.
Vimos isso anteriormente no plano de modo de lote paralelo:o operador de fluxos de coleta final (modo de linha) teve um tempo decorrido (cumulativo) exibido de 0,933s — incluindo todos os seus operadores de modo de lote filho. Os outros operadores eram todos em modo de lote e, portanto, informavam os tempos apenas para o operador individual.
Esta situação, onde algumas operadoras de planos no mesmo plano têm tempos cumulativos e outros não, sem dúvida serão considerados confusos por muitas pessoas.
Execução paralela do modo de linha
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); O plano de execução é:

Todo operador é modo de linha. A consulta é executada por 4.677 ms com tempo de CPU de 23.311ms (soma de todos os threads).
Como um plano exclusivamente de modo de linha, esperamos que todos os tempos sejam cumulativos . Passando de filho para pai (da direita para a esquerda), os tempos devem aumentar nessa direção.
Vejamos apenas a seção mais à direita do plano:
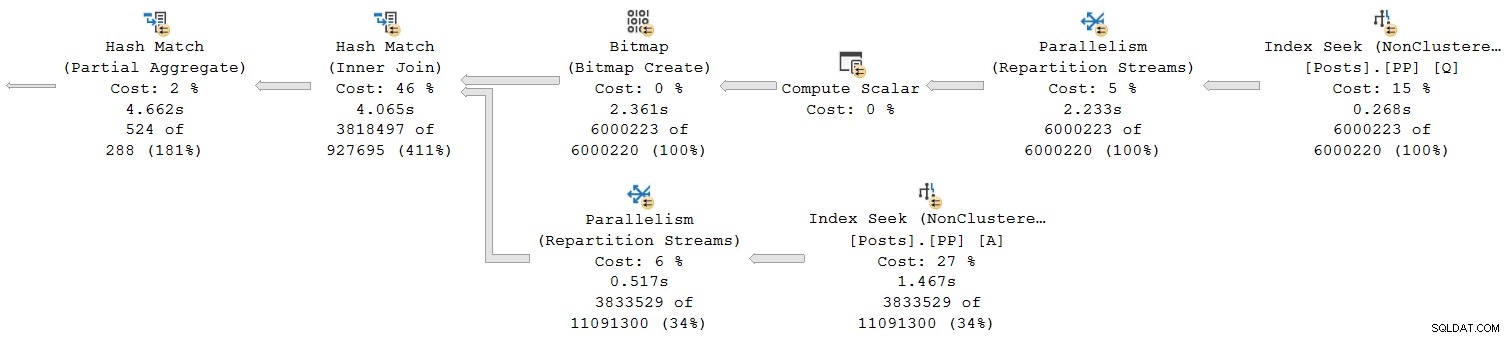
Trabalhando da direita para a esquerda na linha superior, os tempos cumulativos certamente parecem ser o caso. Mas há uma exceção na entrada inferior para a junção de hash:a busca do índice tem um tempo decorrido de 1,467s , enquanto seu pai os fluxos de repartição têm um tempo decorrido de apenas 0,517s .
Como um pai pode operador executado por menos tempo do que seu filho se os tempos decorridos são cumulativos nos planos de modo de linha?
Horas inconsistentes
Existem várias partes para a resposta a este quebra-cabeça. Vamos analisar parte por parte, porque é bastante complexo:
Primeiro, lembre-se de que uma troca (operador de paralelismo) tem duas partes. A mão esquerda (consumidor ) está conectado a um conjunto de threads executando operadores na ramificação paralela à esquerda. A mão direita (produtor ) da troca está conectado a um conjunto diferente de threads executando operadores na ramificação paralela à direita.
As linhas do lado do produtor são montadas em pacotes e depois transferido para o lado do consumidor. Isso fornece um grau de buffer e controle de fluxo entre os dois conjuntos de threads conectados. (Se você precisar de uma atualização sobre exchanges e branches de planos paralelos, consulte meu artigo Parallel Execution Plans – Branches and Threads.)
O escopo dos tempos cumulativos
Olhando para a ramificação paralela no produtor lado da troca:
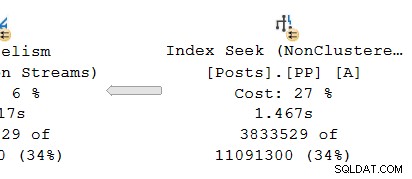
Como de costume, os threads de trabalho adicionais do DOP (grau de paralelismo) executam uma serial independente cópia das operadoras do plano nesta filial. Assim, no DOP 8, existem 8 buscas de índice serial independentes cooperando para realizar a parte de varredura de alcance da operação de busca de índice geral (paralela). Cada busca de thread único é conectada a uma entrada (porta) diferente no lado do produtor do único compartilhado operador de câmbio.
Uma situação semelhante existe no consumidor lado da troca. No DOP 8, existem 8 cópias single-thread separadas desta ramificação, todas rodando independentemente:
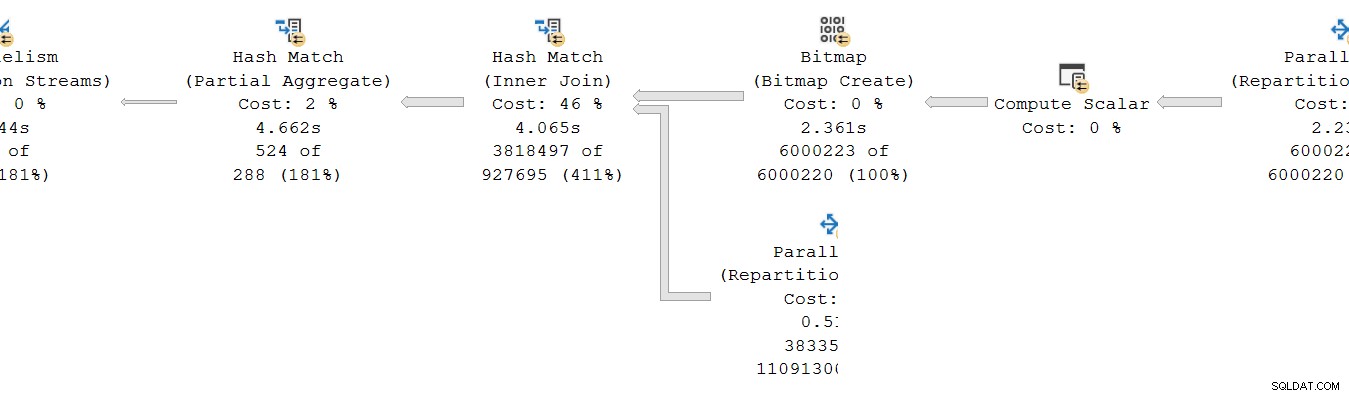
Cada um desses subplanos de encadeamento único é executado da maneira usual, com cada operador acumulando totais de tempo de CPU e decorridos em cada nó. Sendo operadores de modo de linha, cada total representa o tempo gasto no total cumulativo para o nó atual e cada um de seus filhos.
O ponto crucial é que os totais cumulativos incluir apenas operadores no mesmo tópico e somente dentro da ramificação atual . Felizmente, isso faz sentido intuitivo, porque cada thread não tem ideia do que pode estar acontecendo em outro lugar.
Como as métricas do modo de linha são coletadas
A segunda parte do quebra-cabeça está relacionada à maneira como a contagem de linhas e as métricas de tempo são coletadas nos planos de modo de linha. Quando as informações do plano de tempo de execução (“reais”) são necessárias, o mecanismo de execução adiciona um invisível operador de criação de perfil à esquerda imediata (pai) de cada operador no plano que será executado em tempo de execução.
Esse operador pode registrar (entre outras coisas) a diferença entre a hora em que passou o controle para seu operador filho e a hora em que o controle foi retornado. Essa diferença de tempo representa o tempo decorrido para o operador monitorado e todos os seus filhos , já que o filho chama seu próprio filho por linha e assim por diante. Um operador pode ser chamado muitas vezes (para inicializar, depois uma vez por linha, finalmente para fechar) para que o tempo coletado pelo operador de perfil seja um acumulação em potencialmente muitas iterações por linha.
Para obter mais detalhes sobre os dados de criação de perfil coletadas usando diferentes métodos de captura, consulte a documentação do produto que abrange a infraestrutura de criação de perfil de consulta. Para aqueles interessados em tais coisas, o nome do operador de perfil invisível usado pela infraestrutura padrão é
sqlmin!CQScanProfileNew . Como todos os iteradores de modo de linha, ele tem Open , GetRow e Close métodos, entre outros. Cada método contém chamadas para o Windows QueryPerformanceCounter API para coletar o valor atual do temporizador de alta resolução. Como o operador de criação de perfil está à esquerda do operador de destino, ele mede apenas o consumidor lado da troca. Não há nenhum operador de criação de perfil para o produtor lado da troca (infelizmente). Se houvesse, ele corresponderia ou excederia o tempo decorrido mostrado na busca de índice, porque a busca de índice e o lado do produtor estão executando o mesmo conjunto de encadeamentos e o lado do produtor da troca é o operador pai da busca de índice.
Tempo revisitado

Com tudo isso dito, você ainda pode ter problemas com os horários mostrados acima. Como uma busca de índice pode levar 1,467s para passar linhas para o lado do produtor de uma troca, mas o lado do consumidor leva apenas 0,517s para recebê-los? Independentemente de threads separados, buffer e outros enfeites, certamente a troca deve ser executada (de ponta a ponta) por mais tempo do que a busca?
Bem, sim, mas essa é uma medição diferente do tempo decorrido ou da CPU. Vamos ser precisos sobre o que estamos medindo aqui.
Para o modo de linha tempo decorrido , imagine um cronômetro por thread em cada operador. O cronômetro começa quando o SQL Server insere o código de um operador de seu pai e para (mas não reinicia) quando esse código deixa o operador retornar o controle de volta ao pai (não ao filho). Tempo decorrido inclui quaisquer esperas ou atrasos de agendamento - nenhum deles interrompe o relógio.
Para o modo de linha tempo de CPU , imagine o mesmo cronômetro com as mesmas características, exceto que ele para durante esperas e atrasos de agendamento. Ele só acumula tempo quando o operador ou um de seus filhos está executando ativamente em um agendador (CPU). O tempo total em um cronômetro por fio e por operador é construído de um ciclo de partida-parada para cada linha.
Vamos aplicar isso à situação atual com o lado do consumidor da bolsa e o índice busca:
Lembre-se de que o lado do consumidor da troca e a busca de índice estão em ramificações separadas, então elas estão sendo executadas em linhas separadas . O lado do consumidor não tem filhos no mesmo segmento. A busca de índice tem o lado produtor da bolsa como seu pai de mesmo segmento, mas não temos um cronômetro lá.
Cada segmento consumidor inicia sua observação quando seu operador pai (o lado da sondagem da junção de hash) passa o controle (por exemplo, para buscar uma linha). O relógio continua funcionando enquanto o consumidor recupera uma linha do pacote de troca atual. O relógio para quando o controle deixa o consumidor e retorna ao lado da sonda de junção de hash. Outros pais (o agregado parcial e sua troca pai) também funcionarão nessa linha (e podem esperar) antes que o controle retorne ao lado do consumidor de nossa troca para buscar a próxima linha. Nesse ponto, o lado do consumidor de nossa troca começa a acumular o tempo decorrido e de CPU novamente.
Enquanto isso, independentemente do que os encadeamentos de ramificação do lado do consumidor possam estar fazendo, a busca de índice os encadeamentos continuam a localizar linhas no índice e a alimentá-las na troca. Um segmento de busca de índice inicia seu cronômetro quando o lado produtor da bolsa solicita uma linha. O cronômetro é pausado quando a linha é passada para a bolsa. Quando a bolsa solicita a próxima linha, o cronômetro de busca de índice é retomado.
Observe que o lado produtor da troca pode experimentar
CXPACKET espera enquanto os buffers de troca são preenchidos, mas isso não será adicionado aos tempos decorridos registrados na busca do índice porque seu cronômetro não está funcionando quando isso acontece. Se tivéssemos um cronômetro para o lado do produtor da troca, o tempo decorrido que faltava apareceria lá. Para aproximar visualmente um resumo da situação, o diagrama a seguir mostra quando cada operador acumula o tempo decorrido nos dois ramos paralelos:
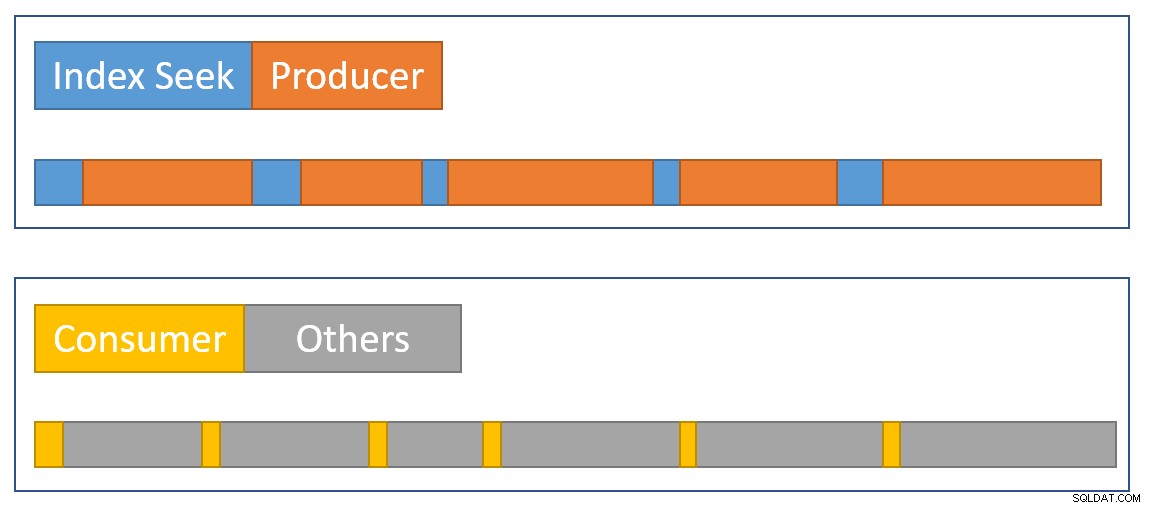
O azul As barras de tempo de busca de índice são curtas porque buscar uma linha de um índice é rápido. A laranja os tempos do produtor podem ser longos devido ao
CXPACKET espera. O amarelo os tempos do consumidor são curtos porque é rápido recuperar uma linha da troca quando os dados estão disponíveis. O cinza os segmentos de tempo representam o tempo usado pelos outros operadores (lado da sonda de junção de hash, agregado parcial e seu lado do produtor da troca pai) acima do lado do consumidor da troca. Esperamos que os pacotes de troca sejam preenchidos rapidamente pela busca do índice, mas esvaziou lentamente (relativamente falando) pelos operadores do lado do consumidor porque eles têm mais trabalho a fazer. Isso significa que os pacotes na troca geralmente estarão cheios ou quase cheios. O consumidor poderá recuperar uma linha em espera rapidamente, mas o produtor pode ter que esperar que o espaço do pacote apareça.
É uma pena que não possamos ver os tempos decorridos no lado do produtor da bolsa. Há muito tempo sou da opinião de que uma troca deve ser representada por dois diferentes operadores nos planos de execução. Seria difícil
CXPACKET /CXCONSUMER espere a análise muito menos necessária e os planos de execução muito mais fáceis de entender. O operador produtor de câmbio naturalmente teria seu próprio operador de perfil. Projetos alternativos
Há muitas maneiras de o SQL Server conseguir resultados cumulativos consistentes. decorrido e tempo de CPU em ramificações paralelas em princípio . Em vez de operadores de perfil, cada linha poderia conter informações sobre quanto tempo de CPU decorrido e acumulado até agora em sua jornada pelo plano. Com o histórico associado a cada linha, não importa como as exchanges redistribuem as linhas entre os encadeamentos e assim por diante.
Não é assim que o produto foi projetado, então não é isso que temos (e pode ser ineficiente de qualquer maneira). Para ser justo, o design original do modo de linha se preocupava apenas com coisas como coletar contagens de linhas reais e o número de iterações em cada operador. Adicionar o tempo decorrido por operador aos planos era um recurso muito solicitado , mas não foi fácil incorporá-lo à estrutura existente.
Quando o processamento em lote foi adicionado ao produto, uma abordagem diferente (tempo apenas para o operador atual) pode ser implementada como parte do desenvolvimento original sem quebrar nada. Novamente, em princípio , os operadores de modo de linha poderiam ter sido modificados para funcionar da mesma maneira que os operadores de modo de lote, mas isso exigiria muito trabalho de reengenharia de cada operador de modo de linha existente. Adicionar um novo ponto de dados aos operadores de perfil do modo de linha existente foi muito mais fácil. Dados os recursos de engenharia limitados e uma longa lista de melhorias de produto desejadas, compromissos como esse geralmente precisam ser feitos.
O segundo problema
Outra inconsistência cumulativa de tempo ocorre no presente plano do lado esquerdo:

À primeira vista, parece ser o mesmo problema:a agregação parcial tem um tempo decorrido de 4,662s , mas a troca acima só funciona por 2.844s . A mesma mecânica básica de antes está em jogo, é claro, mas há outro fator importante. Uma pista está nos tempos suspeitosamente iguais relatados para a troca de agregação, classificação e reparticionamento de fluxo.
Lembra dos “ajustes de tempo” que mencionei na introdução? É aqui que eles entram. Vejamos os tempos decorridos individuais para encadeamentos no lado do consumidor da troca de fluxos de repartição:
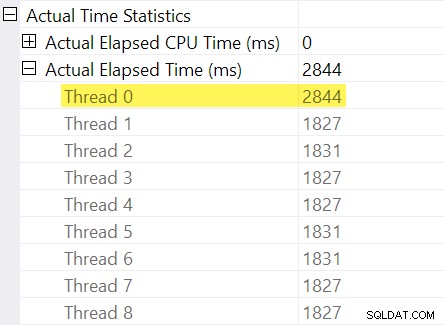
Lembre-se de que os planos mostram o tempo decorrido para um operador paralelo como o máximo dos tempos por thread. Todos os 8 threads tiveram um tempo decorrido em torno de 1.830ms, mas há uma entrada adicional para “Thread 0” com 2.844ms. Na verdade, todos os operadores nesta ramificação paralela (o consumidor de troca, a classificação e o agregado de fluxo) têm o mesmo Contribuição de 2.844ms do “Thread 0”.
O thread zero (também conhecido como tarefa pai ou coordenador) executa apenas operadores diretamente à esquerda do operador de fluxos de coleta final. Por que há trabalho atribuído a ele aqui, em uma filial paralela?
Explicação
Esse problema pode ocorrer quando há um operador de bloqueio na ramificação paralela abaixo (à direita) do atual. Sem esse ajuste, os operadores da filial atual subnotificariam o tempo decorrido pelo tempo necessário para abrir o branch filho (há complicados razões arquitetônicas para isso).
O SQL Server procura explicar isso registrando o atraso da ramificação filha na troca no operador de criação de perfil invisível. O valor de tempo é registrado em relação à tarefa pai (“Thread 0”) na diferença entre seu primeiro ativo e último ativo vezes. (Pode parecer estranho registrar o número dessa maneira, mas no momento em que o número precisa ser registrado, os threads de trabalho paralelos adicionais ainda não foram criados).
No caso atual, o ajuste de 2.844 ms surge predominantemente devido ao tempo que leva a junção de hash para construir sua tabela de hash. (Observe que este tempo é diferente do total tempo de execução da junção de hash, que inclui o tempo necessário para processar o lado da sondagem da junção).
A necessidade de um ajuste surge porque uma junção de hash está bloqueando sua entrada de compilação. (Curiosamente, o hash agregação parcial no plano não é considerado bloqueio neste contexto porque é atribuído apenas uma quantidade mínima de memória, nunca derrama para tempdb , e simplesmente para de agregar se ficar sem memória (retornando assim a um modo de streaming). Craig Freedman explica isso em seu post, Agregação Parcial).
Dado que o ajuste de tempo decorrido representa um atraso de inicialização no branch filho, o SQL Server deve para tratar o valor “Thread 0” como um deslocamento para os números de tempo decorridos por thread medidos dentro da ramificação atual. Tirando o máximo de todos os encadeamentos, pois o tempo decorrido é razoável em geral, porque os encadeamentos tendem a iniciar ao mesmo tempo. Ele não faz sentido fazer isso quando um dos valores de thread é um deslocamento para todos os outros valores!
Podemos fazer o cálculo correto do deslocamento manualmente usando os dados disponíveis no plano. No lado do consumidor da bolsa temos:
O tempo máximo decorrido entre os threads de trabalho adicionais é 1.831 ms (excluindo o valor de deslocamento armazenado em “Thread 0”). Adicionando o deslocamento de 2.844ms dá um total de 4.675ms .
Em qualquer plano em que os tempos por encadeamento sejam menores que o deslocamento, o operador incorretamente mostrar o deslocamento como o tempo total decorrido. Isso provavelmente ocorrerá quando o operador de bloqueio anterior for lento (talvez uma classificação ou agregação global sobre um grande conjunto de dados) e os operadores de ramificação posteriores consumirem menos tempo.
Revisitando esta parte do plano:
Substituindo o deslocamento de 2.844ms atribuído erroneamente aos fluxos de repartição, classificação e operadores de agregação de fluxo por nossos 4.675ms calculados value coloca seus tempos cumulativos decorridos ordenadamente entre os 4.662ms no agregado parcial e os 4.676ms nos fluxos de coleta final. (A classificação e a agregação operam em um pequeno número de linhas para que seus cálculos de tempo decorrido sejam iguais à classificação, mas em geral eles seriam diferentes):

Todos os operadores no fragmento de plano acima têm 0ms de tempo de CPU decorrido em todos os encadeamentos (com exceção do agregado parcial, que tem 14.891ms). O plano com nossos números calculados, portanto, faz muito mais sentido do que o exibido:
- 4.675ms – 4.662ms =13ms decorrido é um número muito mais razoável para o tempo consumido pelos fluxos de repartição sozinhos . Este operador não consome tempo de CPU e processa apenas 524 linhas.
- 0ms decorrido (para resolução de milissegundos) é razoável para a pequena classificação e agregação de fluxo (novamente, excluindo seus filhos).
- 4.676ms – 4.675ms =1ms parece bom que os fluxos de coleta finais coletem 66 linhas no encadeamento da tarefa pai para retornar ao cliente.
Além da óbvia inconsistência no plano fornecido entre o agregado parcial (4.662ms) e os fluxos de repartição (2.844ms), não é razoável pensar que os fluxos de coleta finais de 66 linhas poderiam ser responsáveis por 4.676ms – 2.844ms = 1.832 ms do tempo decorrido. O número corrigido (1ms) é muito mais preciso e não enganará os sintonizadores de consulta.
Agora, mesmo que esse cálculo de deslocamento tenha sido executado corretamente, os planos de modo de linha paralela podem não mostram tempos cumulativos consistentes em todos os casos, pelas razões discutidas anteriormente. Alcançar a consistência completa pode ser difícil, ou mesmo impossível, sem grandes mudanças arquitetônicas.
Para antecipar uma pergunta que pode surgir neste momento:Não, a análise anterior de câmbio e busca de índice não envolveu um erro de cálculo de compensação “Thread 0”. Não há operador de bloqueio abaixo dessa troca, portanto, não ocorre atraso na inicialização.
Um último exemplo
Esta próxima consulta de exemplo usa o mesmo banco de dados e índice de antes. Não vou explorá-lo com muitos detalhes porque serve apenas para expandir pontos que já fiz, para o leitor interessado.
Os recursos desta demonstração são:
- Sem um
ORDER GROUPdica, ele mostra como um agregado parcial não é considerado um operador de bloqueio, portanto, nenhum ajuste de “Thread 0” surge na troca de fluxos de repartição. Os tempos decorridos são consistentes. - Com a dica, as classificações de bloqueio são introduzidas em vez de uma agregação parcial de hash. Dois diferentes Os ajustes de “Thread 0” aparecem nas duas trocas de reparticionamento. Os tempos decorridos são inconsistentes em ambas as ramificações, de maneiras diferentes.
Inquerir:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
); Plano de execução sem
ORDER GROUP (sem ajuste, tempos consistentes):
Plano de execução com
ORDER GROUP (dois ajustes diferentes, tempos inconsistentes):
Resumo e conclusões
Os operadores de plano de modo de linha relatam cumulativo times inclusive de todos os operadores filho no mesmo thread. Os operadores do modo de lote registram o tempo usado dentro desse operador sozinho .
Um único plano pode incluir operadores de modo de linha e de lote; os operadores de modo de linha registrarão o tempo decorrido cumulativo, incluindo quaisquer operadores de lote. Interpretando corretamente os tempos decorridos no modo misto planos podem ser desafiadores.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (
CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli. Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.