[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
O problema do Halloween pode ter vários efeitos importantes nos planos de execução. Nesta parte final da série, veremos os truques que o otimizador pode empregar para evitar o problema do Halloween ao compilar planos para consultas que adicionam, alteram ou excluem dados.
Plano de fundo
Ao longo dos anos, várias abordagens foram tentadas para evitar o problema do Halloween. Uma técnica inicial era simplesmente evitar a construção de qualquer plano de execução que envolvesse leitura e gravação em chaves do mesmo índice. Isso não foi muito bem-sucedido do ponto de vista do desempenho, principalmente porque geralmente significava varrer a tabela base em vez de usar um índice não clusterizado seletivo para localizar as linhas a serem alteradas.
Uma segunda abordagem foi separar completamente as fases de leitura e escrita de uma consulta de atualização, primeiro localizando todas as linhas que se qualificam para a alteração, armazenando-as em algum lugar e só então começando a realizar as alterações. No SQL Server, essa separação de fase completa é obtido colocando o agora familiar Eager Table Spool no lado de entrada do operador de atualização:
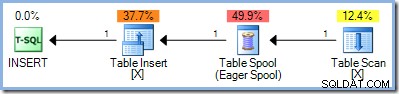
O spool lê todas as linhas de sua entrada e as armazena em um tempdb oculto mesa de trabalho. As páginas desta tabela de trabalho podem permanecer na memória ou podem exigir espaço em disco físico se o conjunto de linhas for grande ou se o servidor estiver sob pressão de memória.
A separação total de fases pode ser menos do que ideal porque geralmente queremos executar o máximo possível do plano como um pipeline, onde cada linha é totalmente processada antes de passar para a próxima. O pipeline tem muitas vantagens, incluindo evitar a necessidade de armazenamento temporário e tocar apenas uma vez em cada linha.
O Otimizador do SQL Server
O SQL Server vai muito além das duas técnicas descritas até agora, embora, é claro, inclua ambas como opções. O otimizador de consultas do SQL Server detecta consultas que exigem proteção de Halloween, determina quanto proteção é necessária e usa baseado em custo análise para encontrar o método mais barato de fornecer essa proteção.
A maneira mais fácil de entender esse aspecto do problema do Halloween é observar alguns exemplos. Nas seções a seguir, a tarefa é adicionar um intervalo de números a uma tabela existente – mas apenas números que ainda não existem:
CREATE TABLE dbo.Test(pk integer NOT NULL, CONSTRAINT PK_Test PRIMARY KEY CLUSTERED (pk));
5 linhas
O primeiro exemplo processa um intervalo de números de 1 a 5 inclusive:
INSERT dbo.Test (pk)SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n ENTRE 1 E 5 E NÃO EXISTE (SELECT NULL FROM dbo.Test AS t WHERE t.pk =Num.n);
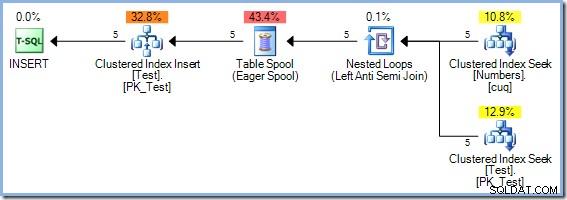
Como essa consulta lê e grava nas chaves do mesmo índice na tabela de teste, o plano de execução requer proteção de Halloween. Nesse caso, o otimizador usa a separação de fase completa usando um Eager Table Spool:
50 linhas
Com cinco linhas agora na tabela Test, executamos a mesma consulta novamente, alterando oWHEREcláusula para processar os números de 1 a 50 inclusive :
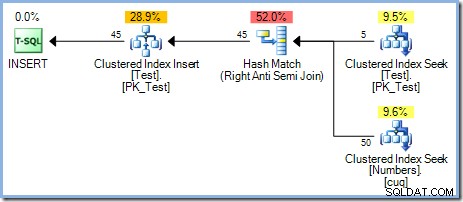
Este plano fornece proteção correta contra o problema do Halloween, mas não possui um Eager Table Spool. O otimizador reconhece que o operador de junção Hash Match está bloqueando sua entrada de compilação; todas as linhas são lidas em uma tabela de hash antes que o operador inicie o processo de correspondência usando as linhas da entrada do probe. Como consequência, este plano naturalmente fornece separação de fases (apenas para a mesa de teste) sem a necessidade de um carretel.
O otimizador escolheu um plano de junção de correspondência de hash em vez da junção de loops aninhados vista no plano de 5 linhas por motivos baseados em custo. O plano de correspondência de hash de 50 linhas tem um custo total estimado de 0,0347345 unidades. Podemos forçar o plano de loops aninhados usado anteriormente com uma dica para ver por que o otimizador não escolheu loops aninhados:
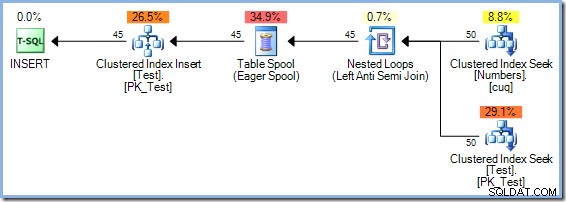
Este plano tem um custo estimado de 0,0379063 unidades incluindo o carretel, um pouco mais do que o plano Hash Match.
500 linhas
Com 50 linhas agora na tabela de teste, aumentamos ainda mais o intervalo de números para 500 :
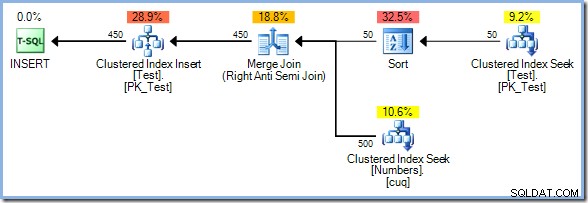
Desta vez, o otimizador escolhe um Merge Join e, novamente, não há Eager Table Spool. O operador Sort fornece a separação de fases necessária neste plano. Ele consome totalmente sua entrada antes de retornar a primeira linha (a classificação não pode saber qual linha classifica primeiro até que todas as linhas tenham sido vistas). O otimizador decidiu que classificar 50 linhas da tabela de teste seriam mais baratas do que o spool antecipado 450 linhas imediatamente antes do operador de atualização.
O plano Sort plus Merge Join tem um custo estimado de 0,0362708 unidades. As alternativas de plano Hash Match e Nested Loops são lançadas em 0,0385677 unidades e 0,112433 unidades respectivamente.
Algo estranho sobre o Sort
Se você está executando esses exemplos por conta própria, pode ter notado algo estranho sobre esse último exemplo, principalmente se você olhou as dicas da ferramenta Plan Explorer para a tabela de teste Seek e Sort:
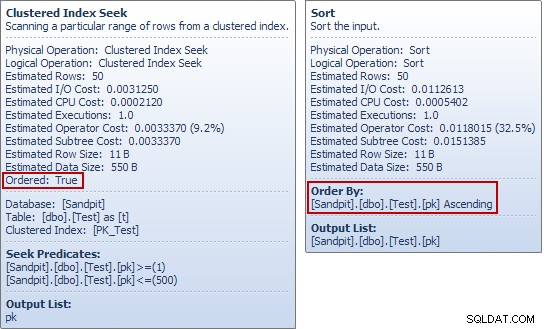
The Seek produz um pedido fluxo de pk valores, então qual é o ponto de classificação na mesma coluna imediatamente depois? Para responder a essa pergunta (muito razoável), começamos examinando apenas oSELECTparte doINSERTinquerir:
SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n BETWEEN 1 AND 500 AND NOT EXISTS (SELECT 1 FROM dbo.Test AS t WHERE t.pk =Num.n )ORDER BY Num.n;
Esta consulta produz o plano de execução abaixo (com ou sem oORDER BYEu adicionei para resolver certas objeções técnicas que você possa ter):
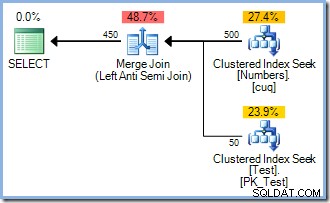
Observe a falta de um operador Sort. Então, por que oINSERTplano inclui um Sort? Simplesmente para evitar o problema do Halloween. O otimizador considerou que realizar uma classificação redundante (com sua separação de fases integrada) era a maneira mais barata de executar a consulta e garantir resultados corretos. Inteligente.
Níveis e propriedades de proteção do Dia das Bruxas
O otimizador do SQL Server possui recursos específicos que permitem raciocinar sobre o nível de Proteção de Halloween (HP) necessário em cada ponto do plano de consulta e o efeito detalhado de cada operador. Esses recursos extras são incorporados à mesma estrutura de propriedades que o otimizador usa para acompanhar centenas de outras informações importantes durante suas atividades de pesquisa.
Cada operador tem um obrigatório propriedade da HP e um entregue propriedade HP. O necessário indica o nível de HP necessário naquele ponto na árvore para resultados corretos. O entregue reflete o HP fornecido pelo operador atual e o valor cumulativo Efeitos HP fornecidos por sua subárvore.
O otimizador contém lógica para determinar como cada operador físico (por exemplo, um Compute Scalar) afeta o nível de HP. Ao explorar uma ampla gama de alternativas de planos e rejeitar planos em que o HP entregue é menor do que o HP necessário no operador de atualização, o otimizador tem uma maneira flexível de encontrar planos corretos e eficientes que nem sempre exigem um Eager Table Spool.
Mudanças de planos para a Proteção do Dia das Bruxas
Vimos o otimizador adicionar uma classificação redundante para a Proteção de Halloween no exemplo anterior de Merge Join. Como podemos ter certeza de que isso é mais eficiente do que um simples Eager Table Spool? E como podemos saber quais recursos de um plano de atualização estão disponíveis apenas para a Proteção do Dia das Bruxas?
Ambas as perguntas podem ser respondidas (em um ambiente de teste, naturalmente) usando o sinalizador de rastreamento não documentado 8692 , que força o otimizador a usar um Eager Table Spool para proteção de Halloween. Lembre-se de que o plano Merge Join com a classificação redundante teve um custo estimado de 0,0362708 unidades otimizadoras mágicas. Podemos comparar isso com a alternativa Eager Table Spool recompilando a consulta com o sinalizador de rastreamento 8692 ativado:
INSERT dbo.Test (pk)SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n ENTRE 1 E 500 E NÃO EXISTE (SELECT 1 FROM dbo.Test AS t WHERE t.pk =Num.n) OPÇÃO ( QUERYTRACEON 8692);
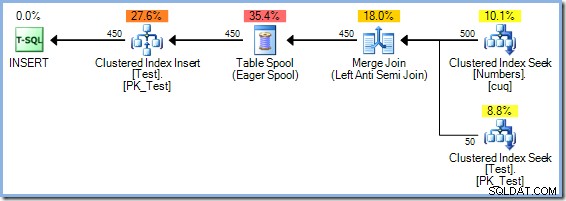
O plano Eager Spool tem um custo estimado de 0,0378719 unidades (acima de 0,0362708 com a ordenação redundante). As diferenças de custo mostradas aqui não são muito significativas devido à natureza trivial da tarefa e ao pequeno tamanho das linhas. As consultas de atualização do mundo real com árvores complexas e contagens de linhas maiores geralmente produzem planos muito mais eficientes, graças à capacidade do otimizador do SQL Server de pensar profundamente sobre a Proteção do Dia das Bruxas.
Outras opções sem spool
Posicionar um operador de bloqueio de forma otimizada dentro de um plano não é a única estratégia aberta ao otimizador para minimizar o custo de fornecer proteção contra o problema do Halloween. Ele também pode raciocinar sobre o intervalo de valores que está sendo processado, como demonstra o exemplo a seguir:
CREATE TABLE #Test( pk integer IDENTITY PRIMARY KEY, some_value integer); CREATE INDEX i ON #Test (some_value); -- Finja que a tabela contém muitos dados UPDATE STATISTICS #TestWITH ROWCOUNT =123456, PAGECOUNT =1234; UPDATE #TestSET some_value =10WHERE some_value =5;
O plano de execução não mostra a necessidade de proteção de Halloween, apesar de estarmos lendo e atualizando as chaves de um índice comum:
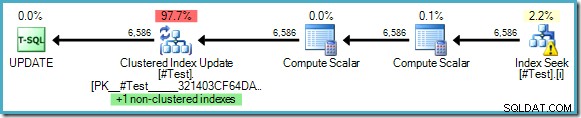
O otimizador pode ver que alterar 'some_value' de 5 para 10 nunca poderia fazer com que uma linha atualizada fosse vista uma segunda vez pelo Index Seek (que está apenas procurando por linhas onde some_value é 5). Esse raciocínio só é possível onde valores literais são usados na consulta ou quando a consulta especificaOPTION (RECOMPILE), permitindo que o otimizador detecte os valores dos parâmetros para um plano de execução único.
Mesmo com valores literais na consulta, o otimizador pode ser impedido de aplicar essa lógica se a opção de banco de dadosFORCED PARAMETERIZATIONestáON. Nesse caso, os valores literais na consulta são substituídos por parâmetros e o otimizador não pode mais ter certeza de que a Proteção de Halloween não é necessária (ou não será necessária quando o plano for reutilizado com valores de parâmetros diferentes):

Caso você esteja se perguntando o que acontece seFORCED PARAMETERIZATIONestá ativado e a consulta especificaOPTION (RECOMPILE), a resposta é que o otimizador compila um plano para os valores rastreados e, portanto, pode aplicar a otimização. Como sempre comOPTION (RECOMPILE), o plano de consulta de valor específico não é armazenado em cache para reutilização.
Principal
Este último exemplo mostra como oTopoperador pode remover a necessidade de proteção de Halloween:
UPDATE TOP (1) tSET some_value +=1FROM #Test AS tWHERE some_value <=10;

Nenhuma proteção é necessária porque estamos atualizando apenas uma linha. O valor atualizado não pode ser encontrado pelo Index Seek, porque o pipeline de processamento é interrompido assim que a primeira linha é atualizada. Novamente, essa otimização só pode ser aplicada se um valor literal constante for usado noTOP, ou se uma variável retornando o valor '1' for detectada usandoOPTION (RECOMPILE).
Se alterarmos oTOP (1)na consulta a umTOP (2), o otimizador escolhe um Clustered Index Scan em vez de Index Seek:

Não estamos atualizando as chaves do índice clusterizado, portanto, este plano não requer proteção de Halloween. Forçando o uso do índice não clusterizado com uma dica noTOP (2)consulta torna o custo da proteção aparente:

O otimizador estimou que o Clustered Index Scan seria mais barato do que este plano (com sua proteção extra de Halloween).
Odds and Ends
Há alguns outros pontos que quero fazer sobre a Proteção do Dia das Bruxas que não encontraram um lugar natural na série até agora. A primeira é a questão da proteção de Halloween quando um nível de isolamento de versão de linha está em uso.
Versão de linha
O SQL Server fornece dois níveis de isolamento,READ COMMITTED SNAPSHOTeSNAPSHOT ISOLATIONque usam um armazenamento de versão em tempdb para fornecer uma visão consistente em nível de instrução ou transação do banco de dados. O SQL Server pode evitar completamente a proteção de Halloween sob esses níveis de isolamento, pois o armazenamento de versão pode fornecer dados não afetados por quaisquer alterações que a instrução em execução no momento possa ter feito até agora. Essa ideia atualmente não está implementada em uma versão lançada do SQL Server, embora a Microsoft tenha registrado uma patente descrevendo como isso funcionaria, então talvez uma versão futura incorpore essa tecnologia.
Heaps e registros encaminhados
Se você estiver familiarizado com as partes internas das estruturas de heap, poderá estar se perguntando se um problema de Halloween específico pode ocorrer quando os registros encaminhados são gerados em uma tabela de heap. Caso isso seja novo para você, um registro de heap será encaminhado se uma linha existente for atualizada de forma que não caiba mais na página de dados original. O mecanismo deixa para trás um stub de encaminhamento e move o registro expandido para outra página.
Pode ocorrer um problema se um plano contendo uma varredura de heap atualizar um registro de forma que ele seja encaminhado. A varredura de heap pode encontrar a linha novamente quando a posição de varredura atingir a página com o registro encaminhado. No SQL Server, esse problema é evitado porque o Mecanismo de Armazenamento garante sempre seguir os ponteiros de encaminhamento imediatamente. Se a verificação encontrar um registro que foi encaminhado, ela o ignorará. Com essa proteção em vigor, o otimizador de consulta não precisa se preocupar com esse cenário.
SCHEMABINDING e funções escalares T-SQL
Há muito poucas ocasiões em que usar uma função escalar T-SQL é uma boa ideia, mas se você precisar usar uma, você deve estar ciente de um efeito importante que ela pode ter em relação à Proteção do Dia das Bruxas. A menos que uma função escalar seja declarada com oSCHEMABINDINGopção, o SQL Server assume que a função acessa tabelas. Para ilustrar, considere a função escalar T-SQL simples abaixo:
CREATE FUNCTION dbo.ReturnInput( @value integer)RETURNS integerASBEGIN RETURN @value;END;
Esta função não acessa nenhuma tabela; na verdade, ele não faz nada, exceto retornar o valor do parâmetro passado para ele. Agora veja o seguinteINSERTinquerir:
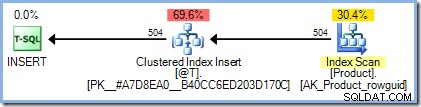
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;
O plano de execução é exatamente como esperávamos, sem necessidade de proteção de Halloween:
Adicionar nossa função do-nothing tem um efeito dramático, no entanto:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID)SELECT dbo.ReturnInput(p.ProductID)FROM AdventureWorks2012.Production.Product AS p;

O plano de execução agora inclui um Eager Table Spool para proteção de Halloween. O SQL Server assume que a função acessa dados, o que pode incluir a leitura da tabela Product novamente. Como você deve se lembrar, umINSERTO plano que contém uma referência à tabela de destino no lado de leitura do plano requer proteção de Halloween completa e, até onde o otimizador sabe, esse pode ser o caso aqui.
Adicionando oSCHEMABINDINGopção para a definição da função significa que o SQL Server examina o corpo da função para determinar quais tabelas ele acessa. Ele não encontra esse acesso e, portanto, não adiciona nenhuma proteção de Halloween:
ALTER FUNCTION dbo.ReturnInput( @value integer)RETURNS integerWITH SCHEMABINDINGASBEGIN RETURN @value;END;GODECLAR @T AS TABLE (ProductID int PRIMARY KEY); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;
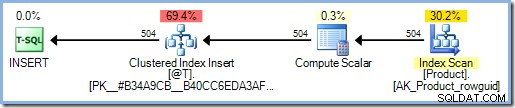
Este problema com funções escalares T-SQL afeta todas as consultas de atualização –INSERT,UPDATE,DELETEeMERGE. Saber quando você está enfrentando esse problema é mais difícil porque a proteção desnecessária de Halloween nem sempre aparecerá como um Eager Table Spool extra, e as chamadas de função escalar podem estar ocultas em exibições ou definições de colunas computadas, por exemplo.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]