Ser responsável pelo desempenho do SQL Server pode ser uma tarefa assustadora. Há muitas áreas que temos que monitorar e entender. Também devemos ser capazes de acompanhar todas essas métricas e saber o que está acontecendo em nossos servidores o tempo todo. Eu gosto de perguntar aos DBAs qual é a primeira coisa que eles pensam quando ouvem a frase “tuning SQL Server”; a resposta esmagadora que recebo é “ajuste de consulta”. Concordo que o ajuste de consultas é muito importante e é uma tarefa sem fim que enfrentamos porque as cargas de trabalho estão mudando continuamente.
No entanto, há muitos outros aspectos a serem considerados ao pensar no desempenho do SQL Server. Há muitas configurações de instância, SO e banco de dados que precisam ser ajustadas a partir dos padrões. Ser consultor me permite trabalhar em muitas linhas de negócios diferentes e obter exposição a todos os tipos de problemas de desempenho. Ao trabalhar com um novo cliente procuro sempre realizar uma auditoria de integridade do servidor para saber com o que estou lidando. Ao realizar essas auditorias, uma das coisas que encontrei repetidamente foram as latências excessivas de leitura e gravação nos discos onde residem os dados e os arquivos de log do SQL Server.
Latência de leitura/gravação
Para visualizar suas latências de disco no SQL Server, você pode consultar de forma rápida e fácil o DMV
sys.dm_io_virtual_file_stats . Este DMV aceita dois parâmetros:database_id e file_id . O que é incrível é que você pode passar NULL como ambos os valores e retornam as latências de todos os arquivos de todos os bancos de dados. As colunas de saída incluem:- database_id
- file_id
- amostra_ms
- num_of_reads
- num_of_bytes_read
- io_stall_read_ms
- num_of_writes
- num_of_bytes_written
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
Como você pode ver na lista de colunas, há informações realmente úteis que esse DMV recupera, no entanto, basta executar
SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); não ajuda muito, a menos que você tenha memorizado seus database_ids e possa fazer algumas contas de cabeça. Quando consulto as estatísticas do arquivo, uso uma consulta da postagem do blog de Paul Randal, “Como examinar latências do subsistema de E/S de dentro do SQL Server”. Esse script facilita a leitura dos nomes das colunas, inclui a unidade em que o arquivo está, o nome do banco de dados e o caminho para o arquivo.
Ao consultar este DMV, você pode facilmente dizer onde estão os pontos de acesso de E/S para seus arquivos. Você pode ver onde estão as maiores latências de gravação e leitura e quais bancos de dados são os culpados. Saber disso permitirá que você comece a analisar as oportunidades de ajuste para esses bancos de dados específicos. Isso pode incluir ajuste de índice, verificação para ver se o pool de buffers está sob pressão de memória, possivelmente movendo o banco de dados para uma parte mais rápida do subsistema de E/S ou possivelmente particionando o banco de dados e espalhando os grupos de arquivos entre outros LUNs.
Então você executa a consulta e ela retorna muitos valores em ms para latência – quais valores estão corretos e quais são ruins?
Quais valores são bons ou ruins?
Se você perguntar ao SQLskills, nós lhe diremos algo como:
- Excelente:<1 ms
- Muito bom:<5ms
- Bom:5 – 10ms
- Ruim:10 – 20ms
- Ruim:20 – 100 ms
- Muito ruim:100 – 500 ms
- OMG!:> 500ms
Se você fizer uma pesquisa no Bing, encontrará artigos da Microsoft fazendo recomendações semelhantes a:
- Bom:<10ms
- Ok:10 – 20ms
- Ruim:20 – 50ms
- Muito ruim:> 50ms
Como você pode ver, existem algumas pequenas variações nos números, mas o consenso é que qualquer coisa acima de 20ms pode ser considerada problemática. Com isso dito, sua latência média de gravação pode ser de 20 ms e isso é 100% aceitável para sua organização e tudo bem. Você precisa conhecer as latências gerais de E/S do seu sistema para que, quando as coisas ficarem ruins, você saiba o que é normal.
Minhas latências de leitura/gravação são ruins. O que eu faço?
Se você está descobrindo que as latências de leitura e gravação são ruins em seu servidor, há vários lugares em que você pode começar a procurar problemas. Esta não é uma lista abrangente, mas algumas orientações sobre por onde começar.
- Analise sua carga de trabalho. Sua estratégia de indexação está correta? Não ter os índices adequados fará com que muito mais dados sejam lidos do disco. Varreduras em vez de buscas.
- Suas estatísticas estão atualizadas? Estatísticas ruins podem resultar em escolhas ruins para planos de execução.
- Você tem problemas de detecção de parâmetros que estão causando planos de execução insatisfatórios?
- O pool de buffers está sob pressão de memória, por exemplo, de um cache de plano inchado?
- Algum problema de rede? Sua malha SAN está funcionando corretamente? Peça para seu engenheiro de armazenamento validar o caminho e a rede.
- Mova os pontos de acesso para diferentes matrizes de armazenamento. Em alguns casos, pode ser um único banco de dados ou apenas alguns bancos de dados que estão causando todos os problemas. Isolá-los em um conjunto diferente de disco ou em um disco de ponta mais rápido, como SSDs, pode ser a melhor solução lógica.
- Você pode particionar o banco de dados para mover tabelas problemáticas para um disco diferente para distribuir a carga?
Estatísticas de espera
Assim como monitorar suas estatísticas de arquivo, monitorar suas estatísticas de espera pode dizer muito sobre gargalos em seu ambiente. Temos a sorte de ter outro DMV incrível (
sys.dm_os_wait_stats ) que podemos consultar que extrairá todas as informações de espera disponíveis coletadas desde a última reinicialização ou desde a última vez que as esperas foram redefinidas; há esperas relacionadas ao desempenho do disco também. Este DMV retornará informações importantes, incluindo:- wait_type
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
Consultar este DMV em minha máquina SQL Server 2014 retornou 771 tipos de espera. O SQL Server está sempre esperando algo, mas há muitas esperas com as quais não devemos nos preocupar. Por esta razão, utilizo outra consulta de Paul Randal; seu post no blog, “Wait Statistics, or please tell me where it does”, tem um excelente script que exclui um monte de esperas com as quais não nos importamos. Paul também lista muitas das esperas problemáticas comuns, bem como oferece orientação para as esperas comuns.
Por que as estatísticas de espera são importantes?
O monitoramento de altos tempos de espera para determinados eventos informará quando houver problemas. Você precisa de uma linha de base para saber o que é normal e quando as coisas excedem um limite ou nível de dor. Se você tiver
PAGEIOLATCH_XX realmente alto então você sabe que o SQL Server está tendo que esperar que uma página de dados seja lida do disco. Isso pode ser disco, memória, alteração de carga de trabalho ou vários outros problemas. Um cliente recente com quem eu estava trabalhando estava vendo um comportamento muito incomum. Quando me conectei ao servidor de banco de dados e pude observar o servidor sob uma carga de trabalho, comecei imediatamente a verificar estatísticas de arquivos, estatísticas de espera, utilização de memória, uso de tempdb, etc. Uma coisa que se destacou imediatamente foi
WRITELOG sendo a espera mais prevalente. Eu sei que essa espera tem a ver com um log flush to disk e me lembrou da série de Paul sobre Trimming the Transaction Log Fat. Alta WRITELOG as esperas geralmente podem ser identificadas por latências de gravação alta para o arquivo de log de transações. Então, usei meu script de estatísticas de arquivo para revisar as latências de leitura e gravação no disco. Consegui ver alta latência de gravação no arquivo de dados, mas não no meu arquivo de log. Ao olhar para o WRITELOG foi uma espera alta, mas o tempo de espera em ms foi extremamente baixo. No entanto, algo no segundo post da série de Paul ainda estava na minha cabeça. Eu deveria olhar para as configurações de crescimento automático para o banco de dados apenas para descartar “Morte por mil cortes”. Ao olhar para as propriedades do banco de dados do banco de dados, vi que o arquivo de dados foi configurado para aumentar automaticamente em 1 MB e o log de transações configurado para aumentar automaticamente em 10%. Ambos os arquivos tinham quase 0 espaço não utilizado. Compartilhei com o cliente o que encontrei e como isso estava matando seu desempenho. Rapidamente fizemos a mudança apropriada e os testes foram em frente, muito melhor por sinal. Infelizmente, esta não é a única vez que encontrei esse problema exato. Em outra ocasião, um banco de dados com 66 GB de tamanho, chegou lá com crescimentos de 1 MB.
Capturando seus dados
Muitos profissionais de dados criaram processos para capturar estatísticas de arquivos e esperas regularmente para análise. Como as estatísticas de espera são cumulativas, você deve capturá-las e comparar os deltas entre diferentes horários do dia ou antes e depois de determinados processos serem executados. Isso não é muito complicado e existem inúmeras postagens de blog disponíveis onde as pessoas compartilham como conseguiram isso. O importante é estar medindo esses dados para que você possa monitorá-los. Como você sabe hoje que as coisas estão melhores ou piores em seu servidor de banco de dados, a menos que você conheça os dados de ontem?
Como o SQL Sentry pode ajudar?
Que bom que você perguntou! O SQL Sentry Performance Advisor traz latência e espera na frente e no centro do painel. Quaisquer anomalias são fáceis de detectar; você pode alternar para o modo histórico e ver a tendência anterior e compará-la com períodos anteriores também. Isso pode ser inestimável ao analisar aqueles “o que aconteceu?” momentos. Todo mundo recebeu aquela ligação:“Ontem, por volta das 15h, o sistema pareceu congelar, você pode nos dizer o que aconteceu?” Hum, claro, deixe-me abrir o Profiler e voltar no tempo. Se você tiver uma ferramenta de monitoramento como o Performance Advisor, terá essas informações históricas na ponta dos dedos.
Além das tabelas e gráficos no painel, você pode usar alertas integrados para condições como altas esperas de disco, altas contagens de VLF, alta CPU, baixa expectativa de vida útil da página e muito mais. Você também tem a capacidade de criar suas próprias condições personalizadas e pode aprender com os exemplos no site SQL Sentry ou através do Condition Exchange (Aaron Bertrand escreveu sobre isso no blog). Eu toquei no lado dos alertas disso em meu último artigo sobre Alertas do SQL Server Agent.
Na guia Espaço em disco do Performance Advisor, é muito fácil ver coisas como configurações de crescimento automático e altas contagens de VLF. Você deve saber, mas caso não saiba, o crescimento automático de 1 MB ou 10% não é a melhor configuração. Se você vir esses valores (o Performance Advisor os destaca para você), você pode rapidamente anotar e agendar o tempo para fazer os ajustes adequados. Eu amo como ele exibe Total VLFs também; muitos VLFs podem ser muito problemáticos. Você deve ler a postagem de Kimberly “VLFs de log de transações – muitos ou poucos?” se você ainda não o fez.
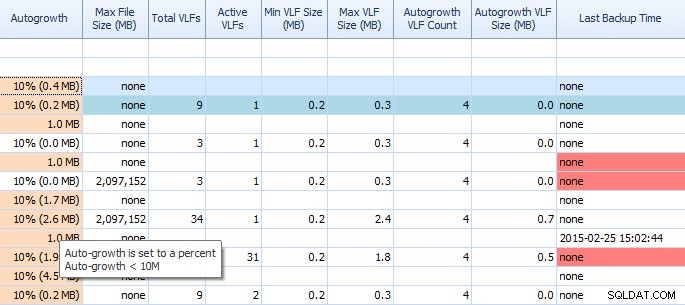 Grade parcial na guia Espaço em disco do Performance Advisor
Grade parcial na guia Espaço em disco do Performance Advisor
Outra maneira que o Performance Advisor pode ajudar é por meio de seu módulo patenteado de atividade de disco. Aqui você pode ver que tempdb em F:está apresentando latência de gravação substancial; você pode dizer isso pelas grossas linhas vermelhas abaixo dos gráficos do disco. Você também pode notar que F:é a única letra de unidade cujo disco é representado em vermelho; esta é uma indicação visual de que a unidade tem uma partição desalinhada, o que pode contribuir para problemas de E/S.
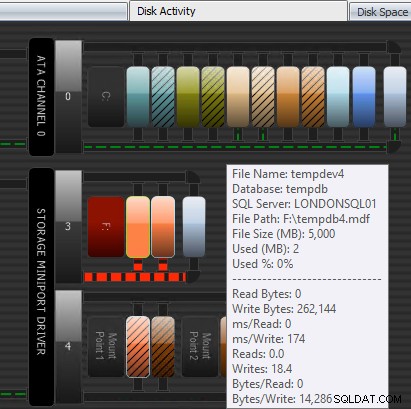 Módulo de atividade de disco do Performance Advisor
Módulo de atividade de disco do Performance Advisor
E você pode correlacionar essas informações nas grades abaixo – os problemas são destacados nas grades também, e dê uma olhada no ms/Write coluna:
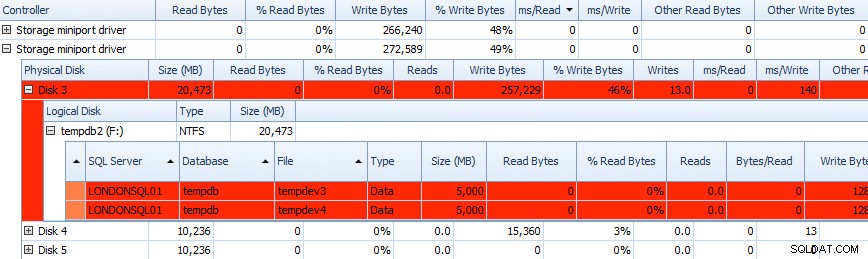 Grade parcial de dados de atividade de disco do Performance Advisor
Grade parcial de dados de atividade de disco do Performance Advisor
Você também pode consultar essas informações retroativamente; se alguém reclamar sobre um gargalo de disco percebido na tarde de ontem ou na terça-feira passada, você pode simplesmente voltar usando os seletores de data na barra de ferramentas e ver a taxa de transferência média e a latência de qualquer intervalo. Para obter mais informações sobre o módulo Atividade de disco, consulte o Guia do usuário.
O Performance Advisor também tem muitos relatórios integrados nas categorias Performance, Blocking, Top SQL, Disk/File Space e Deadlocks. A imagem abaixo mostra como obter os relatórios de espaço em disco/arquivo. Ter os relatórios a apenas alguns cliques do mouse é muito valioso para poder acessar imediatamente e visualizar o que está (ou estava) acontecendo em seu servidor.
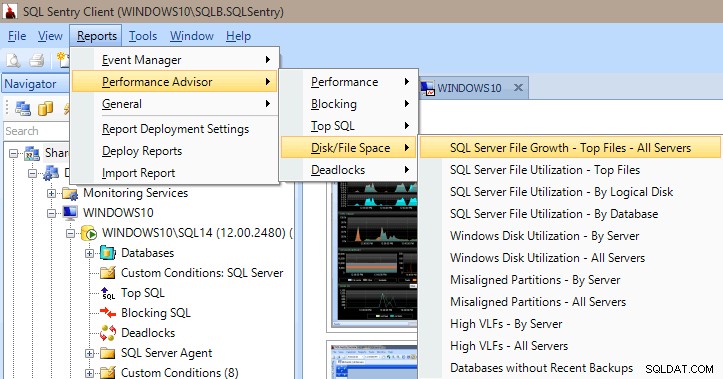 Relatórios do Performance Advisor
Relatórios do Performance Advisor
Resumo
A lição importante deste post é conhecer suas métricas de desempenho. Uma afirmação comum entre os profissionais de dados é que o disco é nosso gargalo nº 1. Conhecer as estatísticas do arquivo do seu servidor ajudará bastante a entender os pontos problemáticos do seu servidor. Em conjunto com as estatísticas do arquivo, suas estatísticas de espera também são um ótimo lugar para procurar. Muitas pessoas, inclusive eu, começam por aí. Ter uma ferramenta como o SQL Sentry Performance Advisor pode ajudá-lo drasticamente a solucionar problemas e encontrar problemas de desempenho antes que eles se tornem muito problemáticos; no entanto, se você não tiver essa ferramenta, familiarize-se com sys.dm_os_wait_stats e sys.dm_io_virtual_file_stats irá atendê-lo bem para começar a ajustar seu servidor.