Todos cometemos erros e todos podemos aprender com os erros de outras pessoas. Neste post, vamos dar uma olhada em vários recursos online para evitar um design de banco de dados ruim que pode levar a muitos problemas e custar tempo e dinheiro. E em um próximo artigo, informaremos onde encontrar dicas e práticas recomendadas.
Erros e erros de design de banco de dados a serem evitados
Existem vários recursos online para ajudar os designers de banco de dados a evitar erros e enganos comuns. Obviamente, este artigo não é uma lista exaustiva de todos os artigos disponíveis. Em vez disso, analisamos e comentamos várias fontes diferentes para que você possa encontrar a que melhor se adequa a você.
Nossa recomendação
Se houver apenas um artigo entre esses recursos que você vai ler, deve ser 'Como obter um design de banco de dados horrivelmente errado' de Robert Sheldon
Vamos começar com o blog DATAVERSITY que fornece um amplo conjunto de recursos bastante bons:
Erros de chave primária e chave estrangeira a serem evitados
por Michael Blaha | blog DATAVERSITY | 2 de setembro de 2015
Mais erros de design de banco de dados – confusão com relacionamentos muitos-para-muitos
por Michael Blaha | blog DATAVERSITY | 30 de setembro de 2015
Erros de design de banco de dados diversos
por Michael Blaha | blog DATAVERSITY | 26 de outubro de 2015
Michael Blaha contribuiu com um belo conjunto de três artigos. Cada artigo aborda diferentes armadilhas de modelagem de banco de dados e design físico; os tópicos incluem chaves, relacionamentos e erros gerais. Além disso, há discussões com Michael sobre alguns dos pontos. Se você está procurando armadilhas em torno de chaves e relacionamentos, este seria um bom lugar para começar.
O Sr. Blaha afirma que “cerca de 20% dos bancos de dados violam as regras de chave primária”. Uau! Isso significa que cerca de 20% dos desenvolvedores de banco de dados não criaram chaves primárias corretamente. Se essa estatística for verdadeira, ela realmente mostra a importância das ferramentas de modelagem de dados que “incentivam” fortemente ou até exigem que os modeladores definam chaves primárias.
O Sr. Blaha também compartilha a heurística de que “cerca de 50% dos bancos de dados” têm problemas de chave estrangeira (de acordo com sua experiência com bancos de dados legados que ele estudou). Ele nos lembra de evitar ligações informais entre tabelas incorporando o valor de uma tabela em outra em vez de usar uma chave estrangeira.
Já vi esse problema muitas vezes. Admito que a vinculação informal pode ser exigida pela funcionalidade a ser implementada, mas ocorre mais frequentemente por simples preguiça. Por exemplo, podemos querer mostrar o ID do usuário de alguém que modificou algo, então armazenamos o ID do usuário diretamente na tabela. Mas e se esse usuário alterar seu ID de usuário? Então esse link informal é quebrado. Isso geralmente se deve a um design e modelagem inadequados.
Projetando seu banco de dados:os 5 principais erros a serem evitados
por Henrique Netzka | blog DATAVERSITY | 2 de novembro de 2015
Fiquei um pouco desapontado com este artigo, pois tinha alguns itens bastante específicos (armazenando protocolo em um CLOB) e alguns muito gerais (pense em localização). No geral, o artigo é bom, mas esses são realmente os 5 principais erros a serem evitados? Na minha opinião, existem vários outros erros comuns que devem fazer parte da lista.
No entanto, em uma nota positiva, este é um dos poucos artigos que menciona globalização e localização de forma significativa. Eu trabalho em um ambiente muito multilíngue e vi várias implementações horríveis de localização, então fiquei feliz em encontrar esse problema mencionado. Colunas de idioma e colunas de fuso horário podem parecer óbvias, mas aparecem muito raramente em modelos de banco de dados.
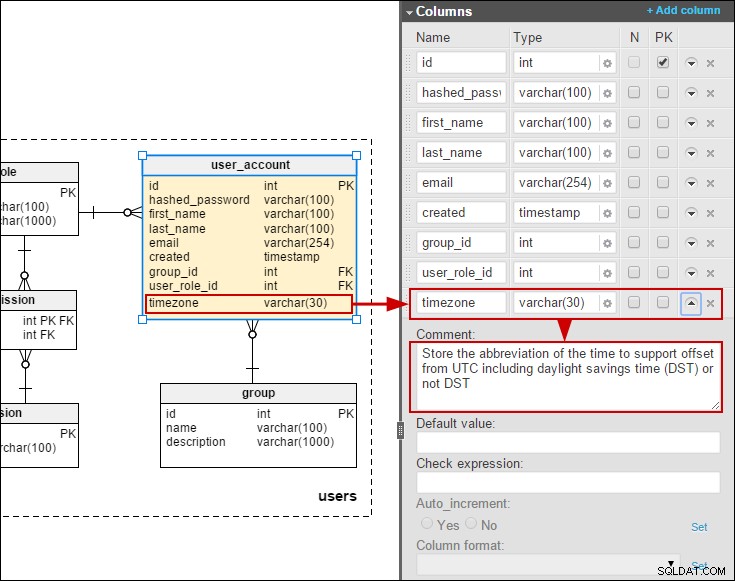
Dito isso, achei que seria interessante criar um modelo incluindo traduções que possam ser alteradas pelos usuários finais (em vez de usar pacotes de recursos). Algum tempo atrás, escrevi sobre um modelo para um banco de dados de pesquisa online. Aqui eu modelei uma tradução simplificada de perguntas e opções de resposta:
Supondo que devemos permitir que os usuários finais mantenham as traduções, o método preferido seria adicionar tabelas de tradução para perguntas e respostas:
Também adicionei um fuso horário à user_account tabela para que possamos armazenar datas/horas na hora local dos usuários:
7 erros comuns de design de banco de dados
por Grzegorz Kaczor | Vertabelo blog | 17 de julho de 2015
Vou fazer uma pequena autopromoção aqui. Nós nos esforçamos para publicar regularmente artigos interessantes e envolventes aqui.
Este artigo em particular aponta várias áreas importantes de preocupação, como nomenclatura, indexação, considerações de volume e trilhas de auditoria. O artigo ainda aborda questões relacionadas a sistemas DBM específicos, como limitações do Oracle em nomes de tabelas. Eu realmente gosto de bons exemplos claros, mesmo que eles ilustrem como os designers cometem erros e erros.
Obviamente, não é possível listar todos os erros de design, e os listados podem não ser seu erros mais comuns. Quando escrevemos sobre erros comuns, são aqueles que cometemos ou encontramos no trabalho de outras pessoas que nos baseamos. Uma lista completa de erros, classificados em termos de frequência, seria impossível para uma única pessoa compilar. No entanto, acho que este artigo fornece vários insights úteis sobre possíveis armadilhas. É um bom recurso sólido em geral.
Enquanto o Sr. Kaczor faz vários pontos interessantes em seu artigo, achei seus comentários sobre “não considerar o possível volume ou tráfego” bastante interessantes. Em particular, a recomendação de separar os dados usados com frequência dos dados históricos é particularmente pertinente. Esta é uma solução que usamos com frequência em nossos aplicativos de mensagens; devemos ter um histórico pesquisável de todas as mensagens, mas as mensagens com maior probabilidade de serem acessadas são aquelas que foram postadas nos últimos dias. Portanto, dividir dados “ativos” ou recentes que são acessados com frequência (um volume muito menor de dados) de dados históricos de longo prazo (a grande massa de dados) geralmente é uma técnica muito boa.
Erros comuns de projeto de banco de dados
por Troy Blake | Blog de DBA sênior | 11 de julho de 2015
O artigo de Troy Blake é outro bom recurso, embora eu possa ter renomeado este artigo “Erros comuns de design do SQL Server”.
Por exemplo, temos o comentário:“stored procedures são seus melhores amigos na hora de usar o SQL Server de forma eficaz”. Tudo bem, mas esse é um erro geral comum ou é mais específico do SQL Server? Eu teria que optar por isso ser um pouco específico do SQL Server, pois há desvantagens em usar procedimentos armazenados, como acabar com procedimentos armazenados específicos do fornecedor e, portanto, aprisionar o fornecedor. Portanto, não sou fã de incluir “Não usar procedimentos armazenados” nesta lista.
No entanto, pelo lado positivo, acho que o autor identificou alguns erros muito comuns, como planejamento ruim, design de sistema de má qualidade, documentação limitada, padrões de nomenclatura fracos e falta de testes.
Então eu classificaria isso como uma referência muito útil para os praticantes do SQL Server e uma referência útil para outros.
Sete erros de modelagem de dados
por Kurt Cagle | LinkedIn | 12 de junho de 2015
Gostei muito de ler a lista de erros de modelagem de banco de dados do Sr. Cagle. Estes são da visão de um arquiteto de banco de dados das coisas; ele identifica claramente erros de modelagem de alto nível que devem ser evitados. Com esta visão de imagem maior, você pode abortar uma potencial confusão de modelagem.
Alguns dos tipos mencionados no artigo podem ser encontrados em outros lugares, mas alguns deles são únicos:abstrair muito cedo ou misturar modelos conceituais, lógicos e físicos. Esses não são frequentemente mencionados por outros autores, provavelmente porque estão focando no processo de modelagem de dados e não na visão maior do sistema.
Em particular, o exemplo de “Getting Too Abstract Too Early” descreve um processo de pensamento interessante de criar algumas “histórias” de amostra e testar quais relacionamentos são importantes neste domínio. Isso foca o pensamento nas relações entre os objetos que estão sendo modelados. Isso resulta em perguntas como quais são os relacionamentos importantes neste domínio ?
Com base nesse entendimento, criamos o modelo em torno dos relacionamentos, em vez de começar em itens de domínio individuais e construir os relacionamentos em cima deles. Embora muitos de nós possam usar essa abordagem, entre esses recursos nenhum outro autor comentou sobre isso. Achei esta descrição e os exemplos bastante interessantes.
Como obter um design de banco de dados terrivelmente errado
por Robert Sheldon | Conversa Simples | 6 de março de 2015
Se houver apenas um artigo entre esses recursos que você vai ler, deve ser este de Robert Sheldon
O que eu realmente gosto neste artigo é que para cada um dos erros citados existem dicas de como fazer certo. A maioria deles se concentra em evitar a falha em vez de corrigi-la, mas ainda acho que são muito úteis. Há muito pouca teoria aqui; principalmente respostas diretas sobre como evitar erros durante a modelagem de dados. Existem alguns pontos específicos do SQL Server, mas principalmente o SQL Server é usado para fornecer exemplos de prevenção de erros ou saídas para falhas.
O escopo do artigo também é bastante amplo:abrange a negligência de planejar, não se preocupar com a documentação, usar convenções de nomenclatura ruins, ter problemas na normalização (muito ou muito pouco), falhar em chaves e restrições, indexar incorretamente e executar testes inadequados.
Em particular, gostei do conselho prático sobre integridade de dados – quando usar restrições de verificação e quando definir chaves estrangeiras. Além disso, o Sr. Sheldon também descreve a situação quando as equipes adiam o pedido para reforçar a integridade. Ele é direto ao afirmar que um banco de dados pode ser acessado de várias maneiras e por vários aplicativos. Ele conclui que “os dados devem ser protegidos onde residem:dentro do banco de dados”. Isso é tão verdadeiro que pode ser repetido para equipes de desenvolvimento e gerentes para explicar a importância de implementar verificações de integridade no modelo de dados.
Este é o meu tipo de artigo, e você pode dizer que os outros concordam com base nos inúmeros comentários que o endossam. Portanto, as melhores marcas aqui; é um recurso muito valioso.
Dez erros comuns de design de banco de dados
por Louis Davidson | Conversa Simples | 26 de fevereiro de 2007
Achei este artigo muito bom, pois cobriu muitos erros comuns de design. Havia analogias significativas, exemplos, modelos e até algumas citações clássicas de William Shakespeare e J.R.R. Tolkien.
Alguns dos erros foram explicados com mais detalhes do que outros, com longos exemplos e trechos de SQL que achei um pouco complicados. Mas isso é uma questão de gosto.
Novamente, temos alguns tópicos específicos do SQL Server. Por exemplo, o ponto de não usar Stored Procedures para acessar dados é bom para SQL, mas os SPs nem sempre são uma boa ideia quando o objetivo é o suporte a vários DBMSes. Além disso, somos advertidos contra tentar codificar objetos T-SQL genéricos. Como raramente trabalho com SQL Server ou Sybase, não achei essa dica relevante.
A lista é bastante semelhante à de Robert Sheldon, mas se você estiver trabalhando principalmente no SQL Server, encontrará algumas informações adicionais.
Cinco erros simples de design de banco de dados que você deve evitar
por Anith Sen Larson | Conversa Simples | 16 de outubro de 2009
Este artigo fornece alguns exemplos significativos para cada um dos erros de design simples que abrange. Por outro lado, é bastante focado em tipos semelhantes de erros:tabelas de pesquisa comuns, tabelas de valor de atributo de entidade e divisão de atributo.
As observações são boas, e o artigo tem até referências, que costumam ser raras. Ainda assim, gostaria de ver erros de design de banco de dados mais gerais. Esses erros pareciam bastante específicos, mas, como já escrevi, os erros sobre os quais escrevemos geralmente são aqueles com os quais temos experiência pessoal.
Um item que gostei foi uma regra prática específica para decidir quando usar uma restrição de verificação versus uma tabela separada com uma restrição de chave estrangeira. Vários autores fornecem recomendações semelhantes, mas Larson as divide em “devem”, “considerar” e “caso forte” – com a admissão de que “design é uma mistura de arte e ciência e, portanto, envolve trocas”. Acho isso muito verdadeiro.
Os dez erros mais comuns no projeto de banco de dados físico
por Craig Mullins | Dados e tecnologia hoje | 5 de agosto de 2013
Como o próprio nome indica, “Top Ten Most Most Common Physical Database Design Mistakes” é um pouco mais orientado ao design físico do que ao design lógico e conceitual. Nenhum dos erros que o autor Craig Mullins menciona realmente se destaca ou é único, então eu recomendaria essas informações para pessoas que trabalham no lado físico do DBA.
Além disso, as descrições são um pouco curtas, por isso às vezes é difícil ver por que um erro específico causará problemas. Não há nada inerentemente errado com descrições curtas, mas elas não dão muito o que pensar. E nenhum exemplo é apresentado.
Há um ponto interessante levantado em relação à falha no compartilhamento de dados. Este ponto é ocasionalmente mencionado em outros artigos, mas não como um erro de design. No entanto, vejo esse problema com bastante frequência com bancos de dados sendo “recriados” com base em requisitos muito semelhantes, mas por uma nova equipe ou para um novo produto
.
Muitas vezes acontece que a equipe do produto percebe mais tarde que gostaria de usar dados que já estavam presentes no “pai” de seu banco de dados atual. Na verdade, porém, eles deveriam ter aprimorado o pai em vez de criar uma nova prole. Os aplicativos são destinados a compartilhar dados; um bom design pode permitir que um banco de dados seja reutilizado com mais frequência.
Você comete esses 5 erros de design de banco de dados?
por Thomas Larock | Blog de Thomas Larock | 2 de janeiro de 2012
Você pode encontrar alguns pontos interessantes ao responder à pergunta de Thomas Larock:Você comete esses 5 erros de design de banco de dados?
Este artigo é um pouco pesado para chaves (chaves estrangeiras, chaves substitutas e chaves geradas). No entanto, ele tem um ponto importante:não se deve presumir que os recursos do DBMS são os mesmos em todos os sistemas. Eu acho que esse é um ponto muito bom. É também aquele que não é encontrado na maioria dos outros artigos, talvez porque muitos autores focam e trabalham predominantemente com um único SGBD.
Projetando um banco de dados:7 coisas que você não quer fazer
por Thomas Larock | Blog de Thomas Larock | 16 de janeiro de 2013
Larock reciclou alguns de seus “5 erros de design de banco de dados” ao escrever “7 coisas que você não quer fazer”, mas há outros pontos positivos aqui.
Curiosamente, alguns dos pontos que o Sr. Larock faz não são encontrados em muitas outras fontes. Você obtém algumas observações bastante exclusivas, como “não ter expectativas de desempenho”. Este é um erro grave e que, com base na minha experiência, acontece com bastante frequência. Mesmo ao desenvolver o código do aplicativo, muitas vezes é após a criação do modelo de dados, do banco de dados e do próprio aplicativo que as pessoas começam a pensar nos requisitos não funcionais (quando testes não funcionais devem ser criados) e começam a definir as expectativas de desempenho .
Por outro lado, existem alguns pontos que eu não incluiria na minha própria lista dos dez primeiros, como “ir grande, apenas por precaução”. Eu vejo o ponto, mas não é tão alto na minha lista ao criar um modelo de dados. Não há especificidade para um sistema DBM específico, então isso é um bônus.
Para concluir, muitos desses pontos podem ser encapsulados sob o ponto:“não entender os requisitos”, que realmente está na minha lista dos 10 principais erros.
Como evitar 8 erros comuns de desenvolvimento de banco de dados
por Base36 | 6 de dezembro de 2012
Fiquei bastante interessado em ler este artigo. No entanto, fiquei um pouco decepcionado. Não há muita discussão sobre evasão, e o ponto do artigo realmente parece ser “estes são erros comuns de banco de dados” e “por que são erros”; descrições de como evitar o erro são menos proeminentes.
Além disso, alguns dos 8 principais erros do artigo são realmente contestados. O uso indevido da chave primária é um exemplo. Base36 nos diz que eles devem ser gerados pelo sistema e não baseados em dados do aplicativo na linha. Embora eu concorde com isso até certo ponto, não estou convencido de que todos Os PKs devem sempre ser gerado; isso é um pouco categórico demais.
Por outro lado, o erro de “Hard Deletes” é interessante e raramente mencionado em outros lugares. As exclusões temporárias causam outros problemas, mas é verdade que simplesmente marcar uma linha como inativa tem suas vantagens quando você está tentando descobrir para onde foram os dados que estavam no sistema ontem. Pesquisar nos logs de transações não é minha ideia de uma maneira agradável de passar o dia.
Sete pecados capitais do design de banco de dados
por Jason Tiret | Jornal de Sistemas Empresariais | 16 de fevereiro de 2010
Fiquei bastante esperançoso quando comecei a ler o artigo de Jason Tiret, “Sete Pecados Capitais do Design de Banco de Dados”. Então, fiquei feliz em descobrir que não apenas reciclava erros encontrados em vários outros artigos. Ao contrário, oferecia um “pecado” que não havia encontrado em outras listas:tentar realizar todo o design do banco de dados “na frente” e não atualizar o modelo depois que o banco de dados está em produção, quando são feitas alterações no banco de dados. (Ou, como diz Jason, “Não tratar o modelo de dados como um organismo vivo que respira”).
Já vi esse erro muitas vezes. A maioria das pessoas só percebe seu erro quando precisa fazer atualizações em um modelo que não corresponde mais ao banco de dados real. Claro, o resultado é um modelo inútil. Como o artigo afirma, “as mudanças precisam encontrar o caminho de volta ao modelo”.
Por outro lado, a maioria dos itens da lista de Jason são bastante conhecidos. As descrições são boas, mas não há muitos exemplos. Mais exemplos e detalhes seriam úteis.
Os erros mais comuns no design de banco de dados
por Brian Prince | eWeek.com | 19 de março de 2008

O artigo “Os erros mais comuns no design de banco de dados” é na verdade uma série de slides de uma apresentação. Existem alguns pensamentos interessantes, mas alguns dos itens únicos são talvez um pouco esotéricos. Tenho em mente pontos como “Conheça o RAID” e o envolvimento das partes interessadas.
Em geral, eu não colocaria isso em sua lista de leitura a menos que você esteja focado em questões gerais (planejamento, nomenclatura, normalização, índices) e detalhes físicos.
10 erros comuns de design
por davidm | Blogs do SQL Server – SQLTeam.com | 12 de setembro de 2005
Alguns dos pontos em “Dez erros comuns de design” são interessantes e relativamente novos. No entanto, alguns desses erros são bastante controversos, como “usar NULLs” e desnormalizar.
Concordo que criar todas as colunas como anuláveis é um erro, mas definir uma coluna como anulável pode ser necessário para uma função de negócios específica. Pode, portanto, ser considerado um erro genérico? Eu acho que não.
Outro ponto que discordo é a desnormalização. Isso nem sempre é um erro de projeto. Por exemplo, a desnormalização pode ser necessária por motivos de desempenho.
Este artigo também é bastante carente de detalhes e exemplos. As conversas entre DBA e programador ou gerente são divertidas, mas eu teria preferido exemplos mais concretos e justificativas detalhadas para esses erros comuns.
OTLT e EAV:os dois grandes erros de design que todos os iniciantes cometem
por Tony Andrews | Tony Andrews sobre Oracle e Bancos de Dados | 21 de outubro de 2004
O artigo do Sr. Andrews nos lembra dos erros “One True Lookup Table” (OTLT) e Entity-Attribute-Value (EAV) que são mencionados em outros artigos. Um ponto interessante sobre esta apresentação é que ela se concentra nesses dois erros, portanto, as descrições e os exemplos são precisos. Além disso, é fornecida uma possível explicação de por que alguns designers implementam OTLT e EAV.
Para lembrá-lo, a tabela OTLT normalmente se parece com isso, com entradas de vários domínios lançadas na mesma tabela:
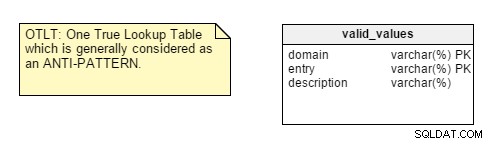
Como de costume, há uma discussão sobre se o OTLT é uma solução viável e um bom padrão de design. Devo dizer que estou do lado do grupo anti-OTLT; essas tabelas apresentam vários problemas. Podemos usar a analogia de usar um único enumerador para representar todos os valores possíveis de todas as constantes possíveis. Nunca vi isso, até agora.
Erros comuns de banco de dados
por John Paul Ashenfelter | do Dr. Dobb | 01 de janeiro de 2002
O artigo do Sr. Ashenfelter lista 15 erros comuns de banco de dados. Existem até alguns erros que não são frequentemente mencionados em outros artigos. Infelizmente, as descrições são relativamente curtas e não há exemplos. O mérito deste artigo é que a lista cobre muito terreno e pode ser usada como uma “lista de verificação” de erros a serem evitados. Embora eu possa não classificá-los como os erros de banco de dados mais importantes, eles certamente estão entre os mais comuns.
Como nota positiva, este é um dos poucos artigos que menciona a necessidade de lidar com a internacionalização de formatos para dados como data, moeda e endereço. Um exemplo seria bom aqui. Pode ser tão simples como “certifique-se de que State é uma coluna que permite valor nulo; em muitos países, não há estado associado a um endereço”.
Anteriormente neste artigo, mencionei outras preocupações e algumas abordagens para se preparar para a globalização de seu banco de dados, como fusos horários e traduções (localização). O fato de nenhum outro artigo mencionar a preocupação com os formatos de moeda e data é preocupante. Nossos bancos de dados estão preparados para o uso global de nossos aplicativos?
Menções Honrosas
Obviamente, existem outros artigos que descrevem erros e erros comuns de design de banco de dados, mas gostaríamos de fornecer uma ampla revisão de diferentes recursos. Você pode encontrar informações adicionais em artigos como:
10 Erros Comuns no Projeto de Banco de Dados | Blog da classe MIS | 29 de janeiro de 2012
10 Erros Comuns no Projeto de Banco de Dados | IDG.se | 24 de junho de 2010
Recursos online:por onde começar? Para onde ir?
Como mencionado anteriormente, esta lista definitivamente não pretende ser um exame exaustivo de todos os artigos on-line que descrevem erros e erros de design de banco de dados. Em vez disso, identificamos várias fontes que são particularmente úteis ou têm um foco específico que você pode achar útil.
Sinta-se à vontade para recomendar artigos adicionais.