[ Parte 1 | Parte 2 | Parte 3 | Parte 4]
O
MERGE instrução (introduzida no SQL Server 2008) nos permite executar uma mistura de INSERT , UPDATE e DELETE operações usando uma única instrução. Os problemas de proteção de Halloween para MERGE são principalmente uma combinação dos requisitos das operações individuais, mas existem algumas diferenças importantes e algumas otimizações interessantes que se aplicam apenas a MERGE . Evitando o problema do Halloween com MERGE
Começamos olhando novamente para o exemplo Demo e Staging da parte dois:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
); Como você deve se lembrar, este exemplo foi usado para mostrar que um
INSERT requer proteção de Halloween quando a tabela de destino de inserção também é referenciada no SELECT parte da consulta (o EXISTS cláusula neste caso). O comportamento correto para o INSERT declaração acima é tentar adicionar ambos 1234 valores e, consequentemente, falhar com uma PRIMARY KEY violação. Sem separação de fases, o INSERT adicionaria incorretamente um valor, completando sem que um erro fosse gerado. O plano de execução INSERT
O código acima tem uma diferença daquele usado na parte dois; um índice não clusterizado na tabela de preparo foi adicionado. O
INSERT plano de execução ainda requer proteção de Halloween embora: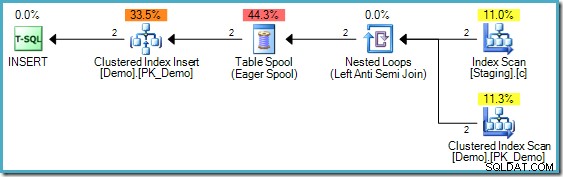
O plano de execução do MERGE
Agora tente a mesma inserção lógica expressa usando
MERGE sintaxe:MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Caso você não esteja familiarizado com a sintaxe, a lógica existe para comparar linhas nas tabelas Staging e Demo no valor SomeKey e, se nenhuma linha correspondente for encontrada na tabela de destino (Demo), inserimos uma nova linha. Isto tem exatamente a mesma semântica que o anterior
INSERT...WHERE NOT EXISTS código, claro. O plano de execução é bem diferente, no entanto: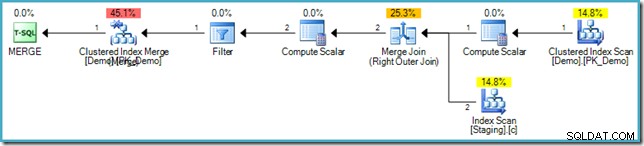
Observe a falta de um Eager Table Spool neste plano. Apesar disso, a consulta ainda produz a mensagem de erro correta. Parece que o SQL Server encontrou uma maneira de executar o
MERGE planeje iterativamente respeitando a separação lógica de fases exigida pelo padrão SQL. A otimização de preenchimento de furos
Nas circunstâncias certas, o otimizador do SQL Server pode reconhecer que o
MERGE declaração é preenchimento de buracos , que é apenas outra maneira de dizer que a instrução apenas adiciona linhas onde há uma lacuna existente na chave da tabela de destino. Para que essa otimização seja aplicada, os valores usados no
WHEN NOT MATCHED BY TARGET cláusula deve exatamente corresponder ao ON parte do USING cláusula. Além disso, a tabela de destino deve ter uma chave exclusiva (um requisito atendido pela PRIMARY KEY no presente caso). Quando esses requisitos forem atendidos, o MERGE declaração não requer proteção contra o problema do Halloween. Claro, o
MERGE declaração é logicamente não mais ou menos preenchimento de buracos que o INSERT...WHERE NOT EXISTS original sintaxe. A diferença é que o otimizador tem controle total sobre a implementação do MERGE instrução, enquanto o INSERT a sintaxe exigiria que ele raciocinasse sobre a semântica mais ampla da consulta. Um humano pode ver facilmente que o INSERT também preenche os buracos, mas o otimizador não pensa nas coisas da mesma maneira que nós. Para ilustrar a correspondência exata requisito que mencionei, considere a seguinte sintaxe de consulta, que não se beneficiam da otimização de preenchimento de furos. O resultado é a proteção completa de Halloween fornecida por um Eager Table Spool:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1); 
A única diferença é a multiplicação por um no
VALUES cláusula – algo que não altera a lógica da consulta, mas que é suficiente para evitar que a otimização de preenchimento de furos seja aplicada. Preenchimento de furos com loops aninhados
No exemplo anterior, o otimizador optou por unir as tabelas usando uma junção Merge. A otimização de preenchimento de furos também pode ser aplicada onde uma junção de loops aninhados é escolhida, mas isso requer uma garantia extra de exclusividade na tabela de origem e uma busca de índice no lado interno da junção. Para ver isso em ação, podemos limpar os dados de teste existentes, adicionar exclusividade ao índice não clusterizado e tentar o
MERGE novamente:-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); O plano de execução resultante usa novamente a otimização de preenchimento de furos para evitar a proteção de Halloween, usando uma junção de loops aninhados e uma busca interna na tabela de destino:
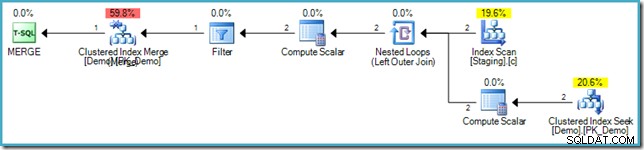
Evitando travessias de índice desnecessárias
Onde a otimização de preenchimento de furos se aplica, o mecanismo também pode aplicar uma otimização adicional. Ele pode lembrar a posição atual do índice enquanto lendo a tabela de destino (processando uma linha por vez, lembre-se) e reutilize essa informação ao executar a inserção, em vez de procurar na árvore b para encontrar o local da inserção. O raciocínio é que é muito provável que a posição de leitura atual esteja na mesma página em que a nova linha deve ser inserida. Verificar se a linha realmente pertence a esta página é muito rápido, pois envolve verificar apenas as chaves mais baixas e mais altas atualmente armazenadas lá.
A combinação de eliminar o Eager Table Spool e salvar uma navegação de índice por linha pode fornecer um benefício significativo em cargas de trabalho OLTP, desde que o plano de execução seja recuperado do cache. O custo de compilação para
MERGE instruções é um pouco maior do que para INSERT , UPDATE e DELETE , portanto, planejar a reutilização é uma consideração importante. Também é útil garantir que as páginas tenham espaço livre suficiente para acomodar novas linhas, evitando divisões de página. Isso normalmente é alcançado através da manutenção normal do índice e da atribuição de um FILLFACTOR adequado . Menciono as cargas de trabalho OLTP, que normalmente apresentam um grande número de alterações relativamente pequenas, porque o
MERGE otimizações podem não ser uma boa escolha onde um grande número de linhas são processadas por instrução. Outras otimizações como INSERTs minimamente registrados atualmente não pode ser combinado com preenchimento de furos. Como sempre, as características de desempenho devem ser avaliadas para garantir que os benefícios esperados sejam alcançados. A otimização de preenchimento de furos para
MERGE inserções podem ser combinadas com atualizações e exclusões usando MERGE adicional cláusulas; cada operação de mudança de dados é avaliada separadamente para o Problema de Halloween. Evitando a junção
A otimização final que veremos pode ser aplicada onde o
MERGE contém operações de atualização e exclusão, bem como uma inserção de preenchimento de furos, e a tabela de destino possui um índice clusterizado exclusivo. O exemplo a seguir mostra um MERGE comum padrão onde as linhas não correspondentes são inseridas e as linhas correspondentes são atualizadas ou excluídas dependendo de uma condição adicional:CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90); O
MERGE declaração necessária para fazer todas as alterações necessárias é notavelmente compacta:MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
O plano de execução é bastante surpreendente:

Sem proteção de Halloween, sem junção entre as tabelas de origem e destino, e não é frequente você ver um operador Clustered Index Insert seguido por um Clustered Index Merge para a mesma tabela. Essa é outra otimização direcionada a cargas de trabalho OLTP com alta reutilização de planos e indexação adequada.
A ideia é ler uma linha da tabela de origem e imediatamente tentar inseri-la no destino. Se ocorrer uma violação de chave, o erro será suprimido, o operador Insert exibirá a linha conflitante encontrada e essa linha será processada para uma operação de atualização ou exclusão usando o operador Merge plan normalmente.
Se a inserção original for bem-sucedida (sem violação de chave), o processamento continua com a próxima linha da origem (o operador Merge processa apenas atualizações e exclusões). Essa otimização beneficia principalmente
MERGE consultas em que a maioria das linhas de origem resulta em uma inserção. Novamente, é necessário um benchmarking cuidadoso para garantir que o desempenho seja melhor do que usar instruções separadas. Resumo
O
MERGE declaração fornece várias oportunidades de otimização exclusivas. Nas circunstâncias certas, pode evitar a necessidade de adicionar proteção explícita de Halloween em comparação com um equivalente INSERT operação, ou talvez até mesmo uma combinação de INSERT , UPDATE e DELETE declarações. Adicional MERGE -otimizações específicas podem evitar a travessia da árvore b do índice que normalmente é necessária para localizar a posição de inserção de uma nova linha e também podem evitar a necessidade de unir completamente as tabelas de origem e destino. Na parte final desta série, veremos como o otimizador de consultas raciocina sobre a necessidade de proteção de Halloween e identificamos mais alguns truques que ele pode empregar para evitar a necessidade de adicionar Spools de tabela ansiosos a planos de execução que alteram dados.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4]