O Ansible é simplesmente ótimo e o PostgreSQL certamente é incrível, vamos ver como eles funcionam incrivelmente juntos!

====================Anúncio em horário nobre! ====================
PGConf Europe 2015 será de 27 a 30 de outubro em Viena deste ano.
Suponho que você esteja possivelmente interessado em gerenciamento de configuração, orquestração de servidores, implantação automatizada (é por isso que você está lendo esta postagem no blog, certo?) e gosta de trabalhar com PostgreSQL (com certeza) na AWS (opcionalmente), então você pode querer participar da minha palestra “Managing PostgreSQL with Ansible” em 28 de outubro, 15-15:50.
Confira a programação incrível e não perca a chance de participar do maior evento PostgreSQL da Europa!
Espero ver você lá, sim, eu gosto de tomar café depois das palestras 🙂
====================Anúncio em horário nobre! ====================
O que é o Ansible e como ele funciona?
O lema da Ansible é “sautomação de TI de código aberto simples, sem agentes e poderosa ” citando os documentos do Ansible.
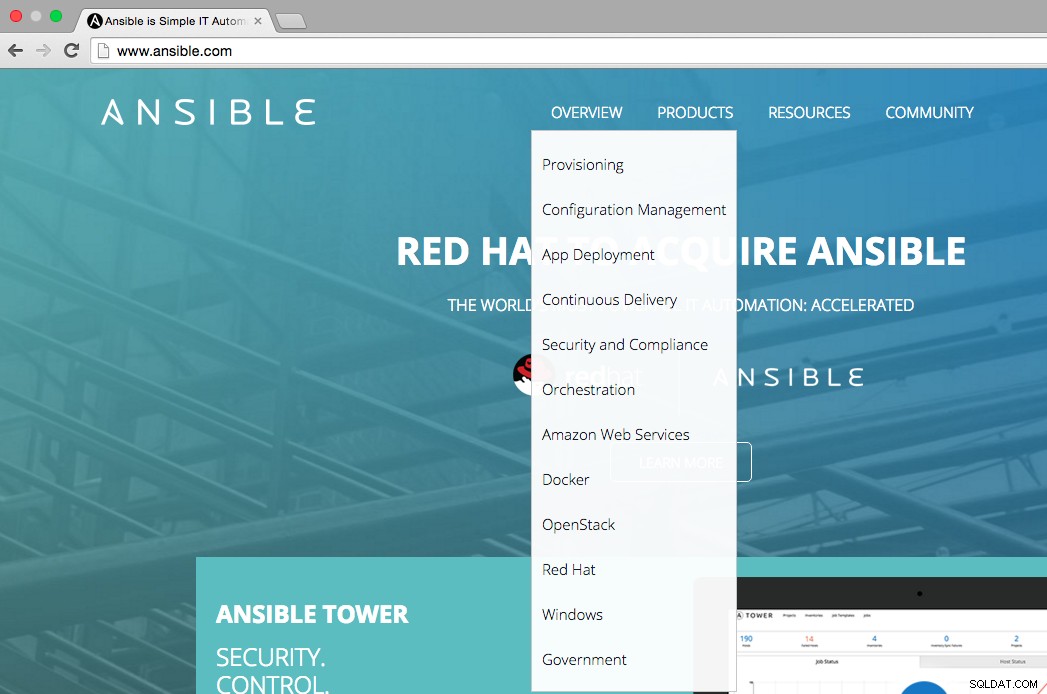
Como pode ser visto na figura abaixo, a página inicial do Ansible afirma que as principais áreas de uso do Ansible são:provisionamento, gerenciamento de configuração, implantação de aplicativos, entrega contínua, segurança e conformidade, orquestração. O menu de visão geral também mostra em quais plataformas podemos integrar o Ansible, ou seja, AWS, Docker, OpenStack, Red Hat, Windows.
Vamos verificar os principais casos de uso do Ansible para entender como ele funciona e como ele é útil para ambientes de TI.
Provisionamento
O Ansible é seu amigo fiel quando você deseja automatizar tudo em seu sistema. É sem agente e você pode simplesmente gerenciar suas coisas (ou seja, servidores, balanceadores de carga, switches, firewalls) via SSH. Independentemente de seus sistemas serem executados em servidores bare-metal ou em nuvem, o Ansible estará lá para ajudá-lo a provisionar suas instâncias. Suas características idempotentes garantem que você sempre estará no estado que deseja (e espera) estar.
Gerenciamento de configuração
Uma das coisas mais difíceis é não se repetir em tarefas operacionais repetitivas e aqui o Ansible volta à mente como um salvador. Nos bons velhos tempos, quando os tempos eram ruins, os administradores de sistema escreviam muitos scripts e se conectavam a muitos servidores para aplicá-los e, obviamente, não era a melhor coisa em suas vidas. Como todos sabemos, as tarefas manuais são propensas a erros e levam a um ambiente heterogêneo em vez de um homogêneo e mais gerenciável e definitivamente tornam nossa vida mais estressante.
Com o Ansible, você pode escrever playbooks simples (com a ajuda de documentação muito informativa e o suporte de sua enorme comunidade) e, depois de escrever suas tarefas, pode chamar uma ampla variedade de módulos (por exemplo, AWS, Nagios, PostgreSQL, SSH, APT, File módulos). Como resultado, você pode se concentrar em mais atividades criativas do que gerenciar configurações manualmente.
Implantação de aplicativos
Tendo os artefatos prontos, é super fácil implantá-los em vários servidores. Como o Ansible está se comunicando por SSH, não há necessidade de extrair de um repositório em cada servidor ou problemas com métodos antigos, como copiar arquivos por FTP. O Ansible pode sincronizar artefatos e garantir que apenas arquivos novos ou atualizados sejam transferidos e arquivos obsoletos sejam removidos. Isso também acelera as transferências de arquivos e economiza muita largura de banda.
Além de transferir arquivos, o Ansible também ajuda a preparar os servidores para uso em produção. Antes da transferência, ele pode pausar o monitoramento, remover servidores de balanceadores de carga e interromper serviços. Após a implantação, ele pode iniciar serviços, adicionar servidores a balanceadores de carga e retomar o monitoramento.
Tudo isso não precisa acontecer de uma vez para todos os servidores. O Ansible pode trabalhar em um subconjunto de servidores por vez para fornecer implantações sem tempo de inatividade. Por exemplo, em uma única vez, ele pode implantar 5 servidores de uma vez e, em seguida, pode implantar nos próximos 5 servidores quando eles terminarem.
Após a implementação deste cenário, ele pode ser executado em qualquer lugar. Desenvolvedores ou membros da equipe de controle de qualidade podem fazer implantações em suas próprias máquinas para fins de teste. Além disso, para reverter uma implantação por qualquer motivo, tudo o que o Ansible precisa é a localização dos últimos artefatos de trabalho conhecidos. Ele pode então reimplantá-los facilmente em servidores de produção para colocar o sistema de volta em um estado estável.
Entrega Contínua
Entrega contínua significa adotar uma abordagem rápida e simples para lançamentos. Para atingir esse objetivo, é fundamental usar as melhores ferramentas que permitem lançamentos frequentes sem tempos de inatividade e requerem o mínimo de intervenção humana possível. Como aprendemos sobre os recursos de implantação de aplicativos do Ansible acima, é muito fácil realizar implantações com tempo de inatividade zero. O outro requisito para entrega contínua é menos processos manuais e isso significa automação. O Ansible pode automatizar qualquer tarefa, desde o provisionamento de servidores até a configuração de serviços para se tornarem prontos para a produção. Depois de criar e testar cenários no Ansible, torna-se trivial colocá-los na frente de um sistema de integração contínua e deixar o Ansible fazer seu trabalho.
Segurança e conformidade
A segurança é sempre considerada a coisa mais importante, mas manter os sistemas seguros é uma das coisas mais difíceis de alcançar. Você precisa ter certeza sobre a segurança de seus dados, bem como a segurança dos dados de seus clientes. Para ter certeza da segurança de seus sistemas, definir segurança não é suficiente, você precisa ser capaz de aplicar essa segurança e monitorar constantemente seus sistemas para garantir que eles permaneçam em conformidade com essa segurança.
O Ansible é fácil de usar, seja para configurar regras de firewall, bloquear usuários e grupos ou aplicar políticas de segurança personalizadas. É seguro por natureza, pois você pode aplicar repetidamente a mesma configuração e só fará as alterações necessárias para colocar o sistema novamente em conformidade.
Orquestração
O Ansible garante que todas as tarefas estejam na ordem correta e estabelece uma harmonia entre todos os recursos que gerencia. A orquestração de implantações complexas de várias camadas é mais fácil com os recursos de gerenciamento e implantação de configuração do Ansible. Por exemplo, considerando a implantação de uma pilha de software, preocupações como garantir que todos os servidores de banco de dados estejam prontos antes de ativar os servidores de aplicativos ou configurar a rede antes de adicionar servidores ao balanceador de carga não são mais problemas complicados.
O Ansible também ajuda na orquestração de outras ferramentas de orquestração, como CloudFormation da Amazon, Heat do OpenStack, Swarm do Docker, etc. Dessa forma, ao invés de aprender diferentes plataformas, linguagens e regras; os usuários podem se concentrar apenas na sintaxe YAML do Ansible e nos módulos poderosos.
O que é um módulo Ansible?
Módulos ou bibliotecas de módulos fornecem meios Ansible para controlar ou gerenciar recursos em servidores locais ou remotos. Eles executam uma variedade de funções. Por exemplo, um módulo pode ser responsável por reiniciar uma máquina ou pode simplesmente exibir uma mensagem na tela.
O Ansible permite que os usuários escrevam seus próprios módulos e também fornece módulos de núcleo ou extras prontos para uso.
E os manuais do Ansible?
O Ansible nos permite organizar nosso trabalho de várias maneiras. Em sua forma mais direta, podemos trabalhar com módulos Ansible usando o método “ansible ” ferramenta de linha de comando e o arquivo de inventário.
Inventário
Um dos conceitos mais importantes é o inventário . Precisamos de um arquivo de inventário para permitir que o Ansible saiba quais servidores ele precisa se conectar usando SSH, quais informações de conexão ele requer e, opcionalmente, quais variáveis estão associadas a esses servidores.
O arquivo de inventário está em um formato semelhante ao INI. No arquivo de inventário, podemos especificar mais de um host e agrupá-los em mais de um grupo de hosts.
Nosso arquivo de inventário de exemplo hosts.ini é semelhante ao seguinte:
[dbservers]
db.example.com
Aqui temos um único host chamado “db.example.com” em um grupo de hosts chamado “dbservers”. No arquivo de inventário, também podemos incluir portas SSH personalizadas, nomes de usuário SSH, chaves SSH, informações de proxy, variáveis etc.
Como temos um arquivo de inventário pronto, para ver os tempos de atividade de nossos servidores de banco de dados, podemos invocar o “comando do Ansible ” e execute o “uptime ” nesses servidores:
ansible dbservers -i hosts.ini -m command -a "uptime"
Aqui instruímos o Ansible a ler os hosts do arquivo hosts.ini, conectá-los usando SSH, executar o “uptime ” em cada um deles e, em seguida, imprima sua saída na tela. Este tipo de execução de módulo é chamado de comando ad-hoc .
A saída do comando será como:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
No entanto, se nossa solução contiver mais de uma única etapa, fica difícil gerenciá-los apenas usando comandos ad-hoc.
Aí vem os manuais do Ansible. Permite organizar nossa solução em um arquivo playbook integrando todas as etapas por meio de tarefas, variáveis, papéis, templates, handlers e um inventário.
Vamos dar uma breve olhada em alguns desses termos para entender como eles podem nos ajudar.
Tarefas
Outro conceito importante são as tarefas. Cada tarefa do Ansible contém um nome, um módulo a ser chamado, parâmetros do módulo e, opcionalmente, pré/pós-condições. Eles nos permitem chamar módulos Ansible e passar informações para tarefas consecutivas.
Variáveis
Há também variáveis. Eles são muito úteis para reutilizar informações que fornecemos ou coletamos. Podemos defini-los no inventário, em arquivos YAML externos ou em manuais.
Manual
Os playbooks do Ansible são escritos usando a sintaxe YAML. Pode conter mais de uma jogada. Cada jogo contém o nome dos grupos de hosts aos quais se conectar e as tarefas que precisa executar. Ele também pode conter variáveis/funções/manipuladores, se definido.
Agora podemos olhar para um manual muito simples para ver como ele pode ser estruturado:
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeNeste manual muito simples, dissemos ao Ansible que ele deveria operar em servidores definidos no grupo de hosts “dbservers”. Criamos uma variável chamada “who” e então definimos nossas tarefas. Observe que na primeira tarefa em que imprimimos uma mensagem de depuração, usamos a variável “who” e fizemos com que o Ansible imprimisse “Hello World” na tela. Na segunda tarefa, dissemos ao Ansible para se conectar a cada host e executar o comando “uptime” lá.
Módulos PostgreSQL do Ansible
O Ansible fornece vários módulos para PostgreSQL. Alguns deles estão localizados em módulos principais, enquanto outros podem ser encontrados em módulos extras.
Todos os módulos do PostgreSQL requerem que o pacote Python psycopg2 seja instalado na mesma máquina com o servidor PostgreSQL. Psycopg2 é um adaptador de banco de dados PostgreSQL na linguagem de programação Python.
Nos sistemas Debian/Ubuntu, o pacote psycopg2 pode ser instalado usando o seguinte comando:
apt-get install python-psycopg2
Agora vamos examinar esses módulos em detalhes. Para fins de exemplo, estaremos trabalhando em um servidor PostgreSQL no host db.example.com na porta 5432 com postgres usuário e uma senha vazia.
postgresql_db
Este módulo principal cria ou remove um determinado banco de dados PostgreSQL. Na terminologia Ansible, garante que um determinado banco de dados PostgreSQL esteja presente ou ausente.
A opção mais importante é o parâmetro obrigatório “nome ”. Ele representa o nome do banco de dados em um servidor PostgreSQL. Outro parâmetro significativo é “estado ”. Requer um dos dois valores:presente ou ausente . Isso nos permite criar ou remover um banco de dados identificado pelo valor fornecido no nome parâmetro.
Alguns fluxos de trabalho também podem exigir a especificação de parâmetros de conexão, como login_host , porta , login_user e login_password .
Vamos criar um banco de dados chamado “module_test ” em nosso servidor PostgreSQL adicionando as linhas abaixo ao nosso arquivo de playbook:
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Aqui, nos conectamos ao nosso servidor de banco de dados de teste em db.example.com com o usuário; postgres . No entanto, não precisa ser o postgres user como o nome de usuário pode ser qualquer coisa.
Remover o banco de dados é tão fácil quanto criá-lo:
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Observe o valor “ausente” no parâmetro “estado”.
postgresql_ext
O PostgreSQL é conhecido por ter extensões muito úteis e poderosas. Por exemplo, uma extensão recente é tsm_system_rows que ajuda a buscar o número exato de linhas na amostragem de tabelas. (Para mais informações, você pode verificar meu post anterior sobre métodos de amostragem de tabelas.)
Este módulo extras adiciona ou remove extensões PostgreSQL de um banco de dados. Requer dois parâmetros obrigatórios:db e nome . O banco parâmetro refere-se ao nome do banco de dados e ao nome parâmetro refere-se ao nome da extensão. Também temos o estado parâmetro que precisa presente ou ausente valores e os mesmos parâmetros de conexão do módulo postgresql_db.
Vamos começar criando a extensão sobre a qual falamos:
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
postgresql_user
Este módulo central permite adicionar ou remover usuários e funções de um banco de dados PostgreSQL.
É um módulo muito poderoso porque, ao mesmo tempo que garante a presença de um usuário no banco de dados, também permite a modificação de privilégios ou funções ao mesmo tempo.
Vamos começar analisando os parâmetros. O único parâmetro obrigatório aqui é “nome ”, que se refere a um nome de usuário ou função. Além disso, como na maioria dos módulos Ansible, o “estado ” é importante. Ele pode ter um de presente ou ausente valores e seu valor padrão é presente .
Além dos parâmetros de conexão como nos módulos anteriores, alguns outros parâmetros opcionais importantes são:
- db :Nome do banco de dados onde as permissões serão concedidas
- senha :Senha do usuário
- privado :Privilégios em “priv1/priv2” ou privilégios de tabela em formato “table:priv1,priv2,…”
- role_attr_flags :atributos da função. Os valores possíveis são:
- [NO]SUPERUSER
- [NO]CREATEROLE
- [NO]CREATEUSER
- [NO]CREATEDB
- [NO]HERDAR
- [NO]LOGIN
- [NO]REPLICAÇÃO
Para criar um novo usuário chamado ada com senha lovelace e um privilégio de conexão ao banco de dados module_test , podemos adicionar o seguinte ao nosso manual:
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Agora que temos o usuário pronto, podemos atribuir a ele alguns papéis. Para permitir que “ada” faça login e crie bancos de dados:
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
Também podemos conceder privilégios globais ou baseados em tabela, como “INSERT ”, “ATUALIZAÇÃO ”, “SELECIONAR ” e “EXCLUIR ” usando o priv parâmetro. Um ponto importante a ser considerado é que um usuário não pode ser removido até que todos os privilégios concedidos sejam revogados primeiro.
postgresql_privs
Este módulo principal concede ou revoga privilégios em objetos de banco de dados PostgreSQL. Os objetos suportados são:table , sequência , função , banco de dados , esquema , idioma , espaço de tabela e grupo .
Os parâmetros obrigatórios são “banco de dados”; nome do banco de dados para conceder/revogar privilégios e “funções”; uma lista separada por vírgulas de nomes de funções.
Os parâmetros opcionais mais importantes são:
- tipo :Tipo do objeto para definir os privilégios. Pode ser um dos seguintes:tabela, sequência, função, banco de dados, esquema, idioma, espaço de tabela, grupo . O valor padrão é tabela .
- objs :Objetos de banco de dados para definir privilégios. Pode ter vários valores. Nesse caso, os objetos são separados por vírgula.
- privados :lista separada por vírgulas de privilégios para conceder ou revogar. Os valores possíveis incluem:ALL , SELECIONAR , ATUALIZAÇÃO , INSERIR .
Vamos ver como isso funciona concedendo todos os privilégios na área “pública ” esquema para “ada ”:
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
Uma das características muito poderosas do PostgreSQL é o suporte para virtualmente qualquer linguagem a ser usada como linguagem procedural. Este módulo extras adiciona, remove ou altera linguagens procedurais com um banco de dados PostgreSQL.
O único parâmetro obrigatório é “lang ”; nome da linguagem procedural a ser adicionada ou removida. Outras opções importantes são “db ”; nome do banco de dados onde o idioma foi adicionado ou removido e “confiança ”; opção para tornar o idioma confiável ou não confiável para o banco de dados selecionado.
Vamos habilitar a linguagem PL/Python para nosso banco de dados:
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Juntando tudo
Agora que sabemos como um manual do Ansible é estruturado e quais módulos do PostgreSQL estão disponíveis para uso, podemos combinar nosso conhecimento em um manual do Ansible.
A forma final do nosso playbook main.yml é como a seguinte:
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Agora podemos executar nosso playbook usando o comando “ansible-playbook”:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Você pode encontrar o inventário e o arquivo do manual no meu repositório GitHub criado para esta postagem do blog. Há também outro manual chamado “remove.yml” que desfaz tudo o que fizemos no manual principal.
Para obter mais informações sobre o Ansible:
- Confira os documentos bem escritos.
- Assista ao vídeo de início rápido do Ansible, que é um tutorial muito útil.
- Siga a programação de webinars, há alguns webinars interessantes na lista.