O
IGNORE_DUP_KEY opção para índices exclusivos especifica como o SQL Server responde a uma tentativa de INSERT valores duplicados:aplica-se apenas a tabelas (não visualizações) e apenas a inserções. Qualquer parte de inserção de um MERGE instrução ignora qualquer IGNORE_DUP_KEY configuração de índice. Quando
IGNORE_DUP_KEY está OFF , a primeira duplicata encontrada resulta em um erro , e nenhuma das novas linhas é inserida. Quando
IGNORE_DUP_KEY está ON , as linhas inseridas que violariam a exclusividade são descartadas. As linhas restantes são inseridas com sucesso. Um aviso mensagem é emitida em vez de um erro:A chave duplicada foi ignorada.
Resumo do artigo
O
IGNORE_DUP_KEY A opção index pode ser especificada para índices exclusivos clusterizados e não clusterizados. Usá-lo em um índice clusterizado pode resultar em desempenho muito pior do que para um índice exclusivo não clusterizado. O tamanho da diferença de desempenho depende de quantas violações de exclusividade são encontradas durante o
INSERT Operação. Quanto mais violações, pior o desempenho do índice único clusterizado em comparação. Se não houver nenhuma violação, a inserção do índice clusterizado poderá ter um desempenho ainda melhor. Inserções de índice exclusivo em cluster
Para um índice exclusivo clusterizado com
IGNORE_DUP_KEY definido, as duplicatas são tratadas pelo mecanismo de armazenamento . Muito do trabalho envolvido na inserção de cada linha é executado antes que a duplicata seja detectada. Por exemplo, uma Inserção de índice agrupado O operador navega pela árvore b do índice clusterizado até o ponto em que a nova linha iria, pegando travas de página e a hierarquia usual de travas, antes de descobrir a chave duplicada.
Quando a condição de chave duplicada é detectada, um erro é levantada. Em vez de cancelar a execução e retornar o erro ao cliente, o erro é tratado internamente. A linha problemática não é inserida e a execução continua, procurando a próxima linha a ser inserida. Se essa linha encontrar uma chave duplicada, outro erro será gerado e tratado e assim por diante.
Exceções são muito caras para jogar e pegar. Um número significativo de duplicatas retardará a execução muito visivelmente.
Inserções de índice exclusivo não clusterizado
Para um índice exclusivo não clusterizado com
IGNORE_DUP_KEY definido, as duplicatas são tratadas pelo processador de consultas . Duplicatas são detectadas e um aviso é emitido antes que cada inserção seja tentada. O processador de consulta remove duplicatas do fluxo de inserção, garantindo que nenhuma duplicata seja vista pelo mecanismo de armazenamento. Como resultado, nenhum erro de violação de chave exclusivo é gerado ou tratado internamente.
A troca
Há uma compensação entre o custo de detectar e remover chaves duplicadas no plano de execução, versus o custo de realizar um trabalho significativo relacionado à inserção e lançar e capturar erros quando uma duplicata é encontrada.
Se for esperado que duplicatas sejam muito raras , a solução do mecanismo de armazenamento (índice clusterizado) pode ser mais eficiente. Quando as duplicatas são menos raras, a abordagem do processador de consultas provavelmente pagará dividendos. O ponto de cruzamento exato dependerá de fatores como a eficiência do tempo de execução dos componentes do plano de execução usados para detectar e remover duplicatas.
O restante deste artigo fornece uma demonstração e analisa com mais detalhes por que a abordagem do mecanismo de armazenamento pode ter um desempenho tão ruim.
Demonstração
O script a seguir cria uma tabela temporária com um milhão de linhas. Ele tem 1.000 valores exclusivos e 1.000 linhas para cada valor exclusivo. Esse conjunto de dados será usado como fonte de dados para inserções em tabelas com diferentes configurações de índice.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Linha de base
A inserção a seguir em uma variável de tabela com um índice clusterizado não exclusivo leva cerca de 900ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Observe a falta de
IGNORE_DUP_KEY na variável da tabela de destino. Índice exclusivo em cluster
Inserindo os mesmos dados em um único clustered indexar com
IGNORE_DUP_KEY definir ON leva cerca de 15.900 ms — quase 18 vezes pior:DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Índice exclusivo não clusterizado
Inserindo os dados em um não clusterizado exclusivo indexar com
IGNORE_DUP_KEY definir ON leva cerca de 700 ms :DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Resumo do desempenho
O teste de linha de base leva 900 ms para inserir todas as um milhão de linhas. O teste de índice não clusterizado leva 700 ms para inserir apenas as 1.000 chaves distintas. O teste de índice clusterizado leva 15.900 ms para inserir as mesmas 1.000 linhas exclusivas.
Esse teste é deliberadamente configurado para destacar o baixo desempenho da implementação do mecanismo de armazenamento, gerando 999 unidades de trabalho desperdiçado (travas, travas, tratamento de erros) para cada linha bem-sucedida.
A mensagem pretendida não é aquela
IGNORE_DUP_KEY sempre terá um desempenho ruim em índices clusterizados, apenas que pode, e pode haver uma grande diferença entre índices clusterizados e não clusterizados. Plano de execução de índice clusterizado
Não há muito para ver no plano de inserção de índice clusterizado:
Há 1.000.000 de linhas sendo passadas para a Inserção de índice clusterizado operador, que é mostrado como 'retornando' 1.000 linhas. Analisando os detalhes do plano, podemos ver:
- 1.244.008 leituras lógicas no operador de inserção.
- A maior parte do tempo de execução é gasto no Inserir operador.
- 11 ms de
SOS_SCHEDULER_YIELDesperas (ou seja, nenhuma outra espera).
Nada que realmente explique os 15.900 ms do tempo decorrido.
Por que o desempenho é tão ruim
É evidente que este plano terá que fazer muito trabalho para cada linha:
- Navegue pelos níveis da árvore b do índice clusterizado, travando e bloqueando conforme o processo for encontrado, para encontrar o ponto de inserção para o novo registro.
- Se alguma das páginas de índice necessárias não estiver na memória, será necessário buscá-las no disco.
- Construa uma nova linha de árvore b na memória.
- Prepare registros de log.
- Se uma duplicata de chave for encontrada (que não seja um registro fantasma), gere um erro, trate esse erro internamente, libere a linha atual e retome em um ponto adequado no código para processar a próxima linha candidata. l>
Isso é uma quantidade razoável de trabalho, e lembre-se de que tudo acontece para cada linha .
A parte em que quero me concentrar é no levantamento e tratamento de erros, porque é extremamente caro. Os aspectos restantes mencionados acima já foram feitos o mais barato possível usando uma variável de tabela e uma tabela temporária na demonstração.
Exceções
A primeira coisa que quero fazer é mostrar que a Inserção de índice clusterizado O operador realmente gera uma exceção quando encontra uma chave duplicada.
Uma maneira de mostrar isso diretamente é anexando um depurador e capturando um rastreamento de pilha no ponto em que a exceção é lançada:
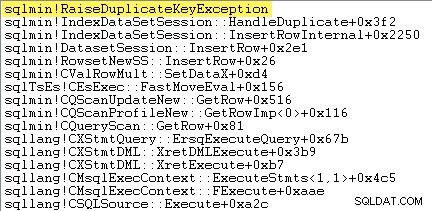
O ponto importante aqui é que lançar e capturar exceções é muito caro.
Monitorar o SQL Server usando o Windows Performance Recorder durante a execução do teste e analisar os resultados no Windows Performance Analyzer mostra:
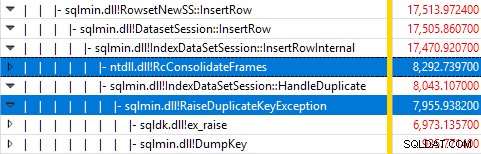
Quase todo o tempo de execução da consulta é gasto em
sqlmin!IndexDataSetSession::InsertRowInternal como seria esperado para uma consulta que faz pouco além de inserir linhas. A surpresa é que 45% desse tempo é gasto levantando exceções via
sqlmin!RaiseDuplicateKeyException e outros 47% são gastos no bloco de captura de exceção associado (o ntdll!RcConsolidateFrames hierarquia) . Para resumir:gerar e capturar exceções compõe 92% do tempo de execução da nossa consulta de inserção de índice clusterizado de teste.
Problemas de coleta de dados
Leitores atentos podem notar uma quantidade significativa – cerca de 12% – de tempo de aumento de exceção gasto em
sqlmin!DumpKey no gráfico do Windows Performance Analyzer. Vale a pena explorar rapidamente, juntamente com alguns itens relacionados. Como parte da geração de uma exceção, o SQL Server precisa coletar alguns dados que só estão disponíveis no momento em que o erro ocorreu. O número do erro associado a uma exceção de chave duplicada é 2627. O texto da mensagem em
sys.messages para esse número de erro é:Violação da restrição %ls '%.*ls'. Não é possível inserir a chave duplicada no objeto '%.*ls'. O valor da chave duplicada é %ls.
As informações para preencher esses marcadores de lugar precisam ser coletadas no momento em que o erro é gerado - elas não estarão disponíveis mais tarde! Isso significa pesquisar e formatar o tipo de restrição, seu nome, o nome completo do objeto de destino e o valor de chave específico. Tudo isso leva tempo.
O rastreamento de pilha a seguir mostra o servidor formatando o valor da chave duplicada como uma string Unicode durante o
DumpKey ligar: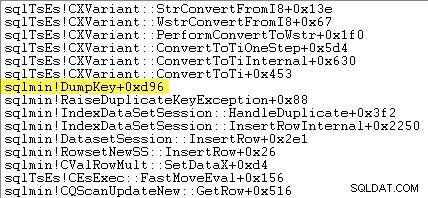
O tratamento de exceções também envolve a captura de um rastreamento de pilha:
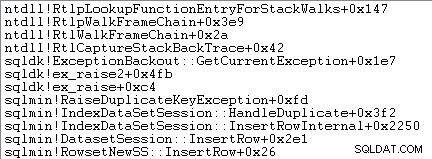
O SQL Server também registra informações sobre exceções (incluindo quadros de pilha) em um pequeno buffer de anel, conforme mostrado a seguir:
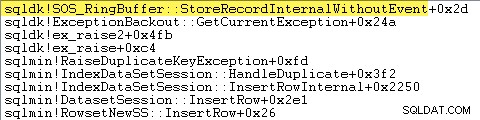
Você pode ver essas entradas de buffer de anel usando um comando como:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Segue um exemplo do registro xml para uma exceção de chave duplicada. Observe os quadros de pilha:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Todo esse trabalho em segundo plano acontece para todas as exceções. Em nosso teste, isso significa que isso acontece 999.000 vezes — uma vez para cada linha que encontra uma violação de chave duplicada.
Há muitas maneiras de ver isso, por exemplo, executando um rastreamento do Profiler usando a Exception evento em Erros e avisos aula. Em nosso caso de teste, isso eventualmente produza 999.000 linhas com TextData elementos como este:
Violação da restrição UNIQUE KEY 'UQ__#AC166DE__3213663B8B6E2E0E'
Não é possível inserir chave duplicada no objeto 'dbo.@T'.
O valor da chave duplicada é (173).
Anexar o Profiler significa que cada evento de manipulação de exceção adquire uma grande sobrecarga adicional, pois os dados extras necessários são coletados e formatados. Os dados padrão mencionados anteriormente são sempre coletados, mesmo que ninguém esteja consumindo ativamente as informações.
Para ser claro:os números de desempenho relatados neste artigo foram todos obtidos sem um depurador anexado e nenhum outro monitoramento ativo.
Plano de execução de índice não clusterizado
Apesar de ser muito mais rápido, o plano de inserção de índice não clusterizado é um pouco mais complexo, então vou dividi-lo em duas partes.
O tema geral é que este plano é mais rápido porque elimina duplicatas antes tentando inseri-los na tabela de destino.
Parte 1
Primeiro, o lado direito do plano de índice não clusterizado:
Esta parte do plano rejeita todas as linhas que tenham uma correspondência de chave na tabela de destino para o índice exclusivo com
IGNORE_DUP_KEY definir ON . Você pode estar esperando ver um Anti Semi Join aqui, mas o SQL Server não tem a infraestrutura necessária para emitir o aviso de chave duplicada necessário com um Anti Semi Join operador. (Se isso ainda não faz sentido, deve fazer em breve.)
Em vez disso, obtemos um plano com vários recursos interessantes:
- A Verificação de índice agrupado é
Ordered:Truepara fornecer entrada para a Mesclar Semi Junção Esquerda ordenado pela colunac1em#Datatabela. - A Verificação de índice da variável da tabela é
Ordered:False - A Classificação ordena linhas por coluna
c1na variável da tabela. Este pedido pode ter sido fornecido por um pedido varredura do índice da variável da tabela emc1, mas o otimizador decide a Classificação é a maneira mais barata de fornecer o nível necessário de Proteção para o Dia das Bruxas. - A variável de tabela Varredura de índice tem
UPDLOCKinterno eSERIALIZABLEdicas aplicadas para garantir a estabilidade do alvo durante a execução do plano. - A Merge Left Semi Join verifica se há correspondências na variável da tabela para cada valor de
c1retornado do#Datatabela. Ao contrário de uma semi-junção regular, ela emite todas as linhas recebidas em sua entrada superior. Ele define um sinalizador em uma coluna de teste para indicar se a linha atual encontrou uma correspondência ou não. A coluna de sondagem é emitida a partir do Mesclar Semi Junção Esquerda como uma expressão chamadaExpr1012. - A Afirmação operador verifica o valor da coluna de sonda
Expr1012. Na primeira vez que ele vê uma linha com um valor de coluna de teste não nulo (indicando que uma correspondência de chave de índice foi encontrada), ele emite um “A chave duplicada foi ignorada” mensagem. - A Afirmação só passa em linhas em que a coluna de teste é nula. Isso elimina as linhas de entrada que produziriam um erro de chave duplicada.
Isso tudo pode parecer complexo, mas é essencialmente tão simples quanto definir um sinalizador se uma correspondência for encontrada, emitindo um aviso na primeira vez que o sinalizador é definido e apenas passando as linhas para a inserção que ainda não existem na tabela de destino .
Parte 2
A segunda parte do plano segue o Assert operador:
A parte anterior do plano removeu as linhas que tinham uma correspondência na tabela de destino. Esta parte do plano remove duplicatas dentro do conjunto de inserções .
Por exemplo, imagine que não haja linhas na tabela de destino em que
c1 = 1 . Ainda podemos causar um erro de chave duplicada se tentarmos inserir duas linhas com c1 = 1 da tabela de origem. Precisamos evitar isso para honrar a semântica de IGNORE_DUP_KEY = ON . Este aspecto é tratado pelo Segmento e Top operadores.
O Segmento operador define um novo sinalizador (rotulado
Segment1015 ) quando encontra uma linha com um novo valor para c1 . Como as linhas são apresentadas em c1 pedido (graças ao Mesclar que preserva o pedido ), o plano pode contar com todas as linhas com o mesmo c1 valor que chega em um fluxo contíguo. O Top operador passa uma linha para cada grupo de duplicatas, conforme indicado pelo Segmento bandeira. Se o Top operador encontra mais de uma linha para o mesmo Segmento grupo (
c1 valor), ele emite um “A chave duplicada foi ignorada” aviso, se for a primeira vez que o plano encontrou essa condição. O efeito líquido de tudo isso é que apenas uma linha é passada para os operadores de inserção para cada valor exclusivo de
c1 , e um aviso é gerado, se necessário. O plano de execução agora eliminou todas as possíveis violações de chave duplicada, portanto, a Inserção de tabela restante e Inserção de índice os operadores podem inserir linhas com segurança no heap e no índice não clusterizado sem medo de um erro de chave duplicada.
Lembre-se que o
UPDLOCK e SERIALIZABLE dicas aplicadas à tabela de destino garantem que o conjunto não possa ser alterado durante a execução. Em outras palavras, uma instrução concorrente não pode alterar a tabela de destino de forma que um erro de chave duplicada ocorra no Inserir operadores. Isso não é uma preocupação aqui, pois estamos usando uma variável de tabela privada, mas o SQL Server ainda adiciona as dicas como uma medida geral de segurança. Sem essas dicas, um processo simultâneo poderia adicionar uma linha à tabela de destino que geraria uma violação de chave duplicada, apesar das verificações feitas pela parte 1 do plano. O SQL Server precisa ter certeza de que os resultados da verificação de existência permanecem válidos.
O leitor curioso pode ver alguns dos recursos descritos acima habilitando os sinalizadores de rastreamento 3604 e 8607 para ver a árvore de saída do otimizador:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Considerações finais
O
IGNORE_DUP_KEY opção de índice não é algo que a maioria das pessoas usará com muita frequência. Ainda assim, é interessante observar como essa funcionalidade é implementada e por que pode haver grandes diferenças de desempenho entre IGNORE_DUP_KEY em índices clusterizados e não clusterizados. Em muitos casos, valerá a pena seguir a liderança do processador de consultas e procurar escrever consultas que eliminem duplicatas explicitamente, em vez de depender de
IGNORE_DUP_KEY . Em nosso exemplo, isso significaria escrever:DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Isso é executado em cerca de 400 ms , apenas para constar.