O seguro de vida é algo que todos esperamos não precisar, mas como sabemos, a vida é imprevisível. Neste artigo, vamos nos concentrar na formulação de um modelo de dados que uma seguradora de vida pode usar para armazenar suas informações.
Seguro de vida como conceito
Antes de começarmos a discutir o modelo de dados real para uma companhia de seguros de vida, vamos nos lembrar brevemente do que é seguro e como ele funciona para termos uma ideia melhor do que estamos trabalhando.
O seguro é um conceito bastante antigo que remonta mesmo antes da Idade Média, quando muitas guildas ofereciam apólices para proteger seus membros em situações inesperadas. Até mesmo o famoso astrônomo, matemático, cientista e inventor Edmund Halley se interessou por seguros, trabalhando em estatísticas e taxas de mortalidade que formavam a espinha dorsal dos modelos modernos de seguros.
Por que você deve pagar pelo seguro? A ideia é bem simples – você paga uma certa quantia (o prêmio) em troca da garantia da seguradora de que você ou sua família serão compensados financeiramente se algo inesperado acontecer com você ou sua propriedade. No caso de uma apólice de seguro de vida, você designa um beneficiário que receberá uma quantia em dinheiro (o benefício) em caso de sua morte. A ideia é que esse dinheiro os ajude a se recuperar de sua perda, especialmente se sua morte criar algum problema financeiro.
É claro que as companhias de seguros normalmente pagam muito menos em benefícios do que ganham com prêmios e investindo seu dinheiro, digamos, no mercado de ações. Caso contrário, eles iriam à falência e todo o sistema desmoronaria!
Essa é praticamente a essência disso. Agora que resolvemos isso, vamos dar uma olhada no modelo de dados de uma típica companhia de seguros de vida.
O modelo de dados:visão geral
O modelo de dados com o qual trabalharemos consiste em cinco áreas temáticas:
- Funcionários
- Produtos
- Clientes
- Ofertas
- Pagamentos
Abordaremos cada uma dessas seções com mais detalhes, na ordem em que estão listadas acima.
Área de Assunto nº 1:Funcionários
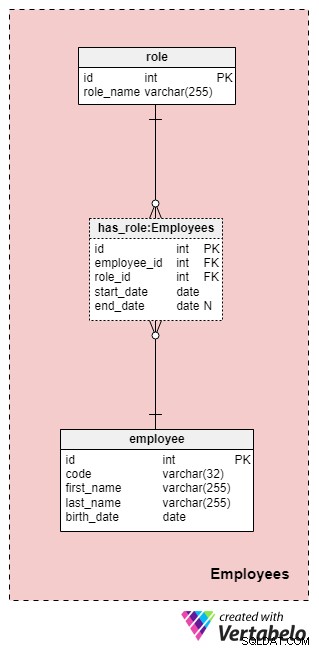
Esta área não é necessariamente específica para este modelo de dados, mas ainda é muito importante porque as tabelas aqui contidas serão referenciadas por outras áreas temáticas. Para fins de nosso modelo de dados da seguradora, é claro que precisamos saber quem executou qual ação (por exemplo, quem representou nossa empresa ao trabalhar com o cliente/cliente, quem assinou a apólice e assim por diante).
A lista de todos os funcionários da empresa é armazenada no arquivo employee tabela. Para cada funcionário, armazenaremos as seguintes informações:
code— uma chave exclusiva que identifica um único funcionário. Como o código será usado como atributo em outras tabelas, ele servirá como uma chave alternativa nesta tabela.first_nameelast_name— o nome e sobrenome do funcionário, respectivamente.birth_date— a data de nascimento do funcionário.
É claro que certamente poderíamos incluir muitos outros atributos relacionados aos funcionários nesta tabela, mas esses quatro são mais do que suficientes por enquanto. Seguiremos esse padrão ao longo do artigo e tentaremos manter as coisas o mais simples possível, mas observe que você pode definitivamente expandir esse modelo de dados para incluir informações adicionais.
Como os funcionários podem alterar suas funções em nossa empresa a qualquer momento, precisaremos de uma tabela de dicionário para representar as funções da empresa e uma tabela para armazenar valores. A lista de todas as funções possíveis que os funcionários podem assumir em nossa companhia de seguros de vida está armazenada na
role dicionário. Ele tem apenas um atributo chamado role_name que contém valores de identificação exclusiva. Relacionaremos funcionários e funções usando o
has_role tabela. Além das chaves estrangeiras employee_id e role_id , armazenaremos dois valores:start_date e end_date . Esses dois valores denotam o intervalo no qual essa função da empresa estava ativa para um determinado funcionário. O end_date conterá um valor nulo até que uma data final para a função desse funcionário seja determinada. A chave alternativa para esta tabela é a combinação de employee_id , role_id e start_date . Para evitar duplicar a mesma função para o mesmo funcionário, precisaremos verificar programaticamente se há sobreposições sempre que adicionarmos um novo registro à tabela ou atualizarmos um existente. Área de assunto nº 2:Produtos
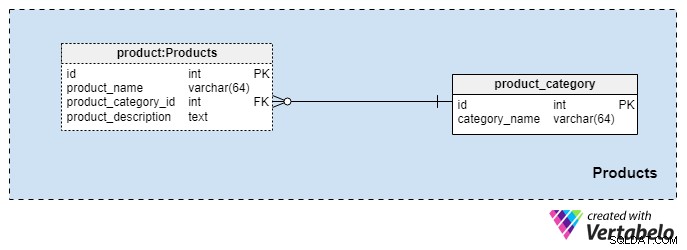
Esta área de assunto é bastante pequena e contém apenas duas tabelas. Os valores dessas tabelas são pré-requisitos para nossas outras áreas de assunto, então vamos discuti-los brevemente.
A product_category O dicionário armazena as categorias mais gerais de produtos que planejamos oferecer aos nossos clientes. O único valor que armazenaremos nesta tabela é o exclusivo category_name para denotar o tipo de seguro que oferecemos, que pode ser seguro de vida pessoal, seguro de vida familiar e assim por diante.
Classificaremos ainda mais nossos produtos usando o product tabela. Esta tabela representa os produtos reais que vendemos e não suas categorias. Como você pode imaginar, podemos agrupar produtos por duração (por exemplo, 10 ou 20 anos, ou até mesmo uma vida inteira). Se optarmos por fazer isso, provavelmente teremos produtos com o mesmo product_category_id mas nomes e descrições diferentes. Para cada produto, armazenaremos as seguintes informações básicas:
product_name— o nome deste produto. Ele é usado como uma chave alternativa para esta tabela em combinação com oproduct_category_idatributo. É improvável que tenhamos dois produtos com o mesmo nome que pertençam a categorias diferentes, mas não deixa de ser uma possibilidade.product_category_id— identifica a categoria à qual este produto pertence.product_description— descrição textual deste produto.
Área de assunto nº 3:Clientes
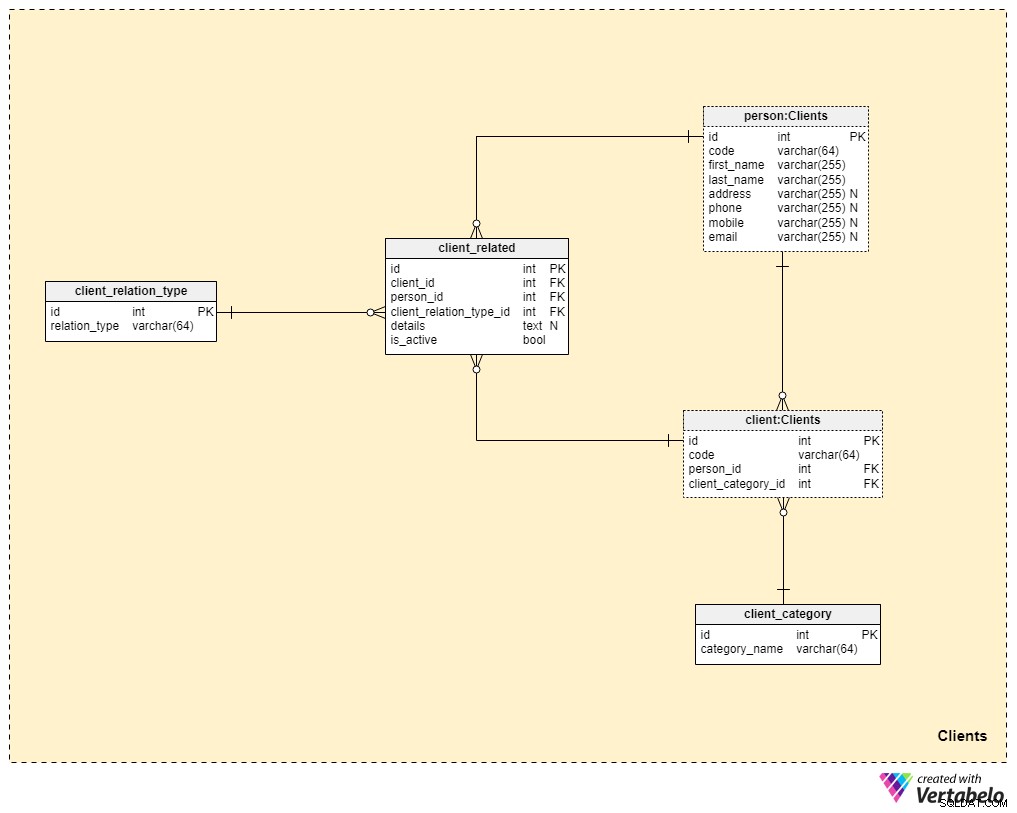
Agora estamos nos aproximando muito do núcleo do nosso modelo de dados, mas ainda não chegamos lá. O seguro de vida é único porque uma apólice pode ser transferida para um membro da família ou outra pessoa, enquanto as apólices de outras formas de seguro (como seguro saúde ou seguro de carro) pertencem a um único cliente e não podem ser transferidas. Por esse motivo, precisaremos armazenar não apenas informações sobre o cliente a quem a política pertence, mas também informações sobre quaisquer pessoas relacionadas e seu relacionamento com o cliente.
Começaremos com o client tabela. Para cada cliente, armazenaremos o código único gerado ou inserido manualmente para esse cliente, bem como as chaves estrangeiras que referenciam a tabela com seus dados pessoais (person_id ) e a tabela contendo nossa categorização interna (client_category_id ).
A client_category dicionário nos permite agrupar clientes com base em seus dados demográficos e financeiros. As categorias de clientes serão usadas para determinar a apólice de seguro que estamos prontos para oferecer a um determinado cliente. Aqui, armazenaremos apenas uma lista de valores exclusivos que atribuiremos aos clientes.
Como estamos falando de seguro de vida, vamos supor que um cliente é um único indivíduo. No entanto, como mencionamos anteriormente, pode haver outras pessoas relacionadas ao cliente para quem a apólice pode ser transferida ou que podem receber o benefício da apólice após o falecimento do cliente. Por esse motivo, criamos uma person tabela. Para cada registro nesta tabela, armazenaremos as seguintes informações:
code— um valor gerado automaticamente ou inserido manualmente usado para identificar exclusivamente a pessoa relacionada.first_nameelast_name— o nome e sobrenome da pessoa, respectivamente.address,phone,mobileeemail— detalhes de contato dessa pessoa, todos contendo valores arbitrários.
As duas tabelas restantes nesta área de assunto são necessárias para descrever a natureza do relacionamento entre clientes e outras pessoas.
A lista de todos os tipos de relação possíveis é armazenada no
client_relation_type dicionário. Assim como em outros dicionários, ele conterá uma lista de nomes exclusivos que usaremos posteriormente ao descrever o relacionamento entre um determinado cliente e outra pessoa. Os dados reais da relação são armazenados no
client_related tabela. Para cada registro nesta tabela, armazenaremos referências ao cliente (client_id ), a pessoa relacionada (person_id ), a natureza dessa relação (client_relation_type_id ), todos os detalhes da adição (details ), se houver, e um sinalizador indicando se a relação está ativa no momento (is_active ). A chave alternativa nesta tabela é definida pela combinação de client_id , person_id e client_relation_type_id . Área de assunto nº 4:Ofertas
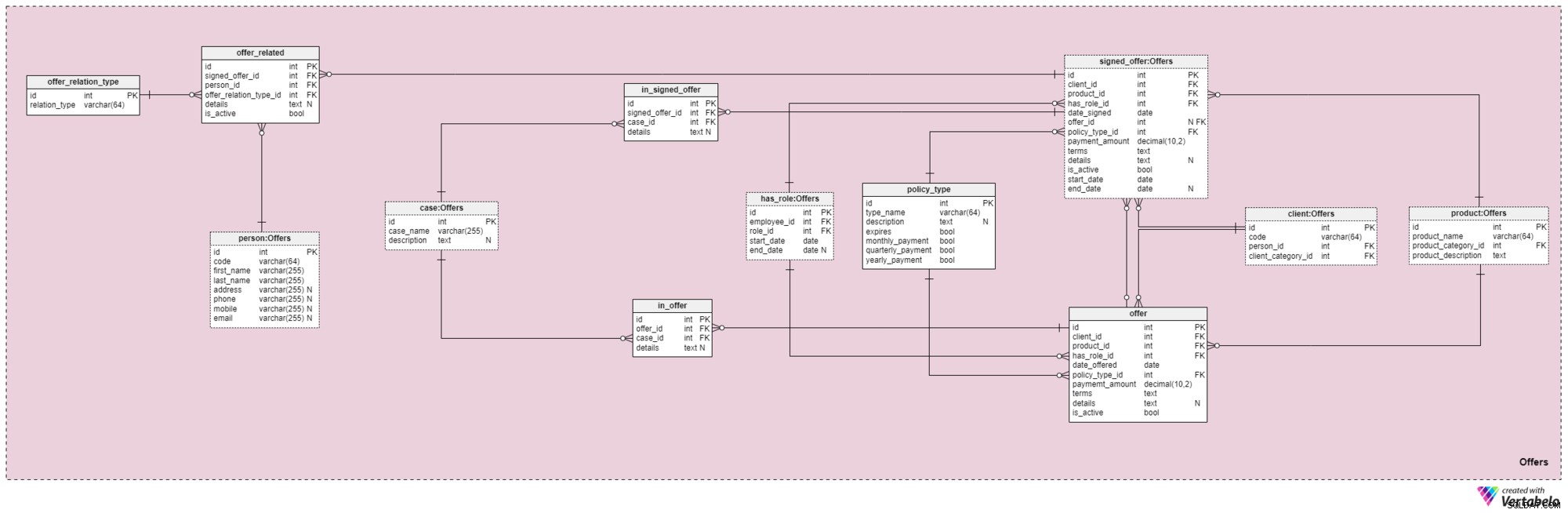
Esta área de assunto e a que se segue estão no centro deste modelo de dados. Eles cobrem ofertas e apólices assinadas, bem como pagamentos relacionados a ofertas. Primeiro, descreveremos a área de assunto Ofertas. Pode parecer complexo porque contém 12 tabelas. No entanto, quatro desses 12 (has_role , product , client e person ) foram descritos em áreas temáticas anteriores, por isso não vamos repetir nossa discussão aqui.
A offer e signed_offer as tabelas têm estruturas semelhantes porque serão usadas para armazenar dados muito semelhantes em nosso modelo. No entanto, enquanto offer será usado principalmente para armazenar quaisquer políticas (e seus detalhes) que oferecemos aos nossos clientes, a signed_offer table será estritamente usada para armazenar informações sobre clientes que realmente assinaram apólices com nossa empresa. Cobriremos essas tabelas juntos, observando quaisquer diferenças onde elas aparecem. Os atributos nessas duas tabelas são os seguintes:
client_id— referência ao identificador exclusivo do cliente que assinou uma oferta específica.product_id— referência ao identificador exclusivo do produto que foi incluído na oferta assinada.has_role_id— referência ao id do funcionário e à função que ele exercia no momento em que a oferta foi apresentada/assinada.date_offerededate_signed— datas reais que indicam quando esta oferta foi apresentada ao cliente e quando foi assinada, respectivamente.offer_id— uma referência à oferta anterior para este cliente. Isso pode conter um valor nulo porque o cliente pode ter assinado uma apólice sem ter nenhuma oferta anterior da empresa, como se nos abordasse por conta própria. Este atributo pertence estritamente àsigned_offertabela.policy_type_id— referência ao dicionário de tipo de política que indica o tipo de política que oferecemos ao cliente ou o fizemos assinar.payment_amount— o valor que o cliente deve pagar regularmente pela apólice.terms— todos os termos do contrato, em formato textual (XML). A ideia é armazenar todos os detalhes importantes referentes à parte financeira da apólice neste atributo. Exemplos de texto que podemos armazenar são o valor total da apólice, o número de pagamentos que o cliente deve fazer e assim por diante.details— quaisquer detalhes adicionais, em formato textual.is_active— sinalizador que indica se o registro ainda está ativo.start_dateeend_date— denota o intervalo de tempo em que esta política está/estava ativa. Se a política foi assinada por toda a vida, end_date conterá um valor nulo.
Há também o
policy_type dicionário que mencionamos brevemente antes. Precisamos de algum grau de flexibilidade na forma como oferecemos o mesmo produto para clientes diferentes, com base em fatores como idade, saúde, estado civil, risco de crédito e assim por diante. Para cada tipo de política, armazenaremos um type_name identificador, uma description textual adicional , um sinalizador denominado expira significando se a apólice pode expirar e outro sinalizador indicando se os prêmios desse tipo de apólice precisam ser pagos mensalmente, trimestralmente ou anualmente. Alguns tipos de apólices esperados são:vida a termo, vida inteira, vida universal, vida universal garantida, vida variável, vida universal variável e seguro de vida após a aposentadoria. Seguindo em frente, agora precisamos definir todos os casos e situações que uma determinada política pode cobrir. Precisamos relacionar esses casos a ofertas específicas e ofertas assinadas.
A lista de todos os casos possíveis que nossas políticas cobrem é armazenada no
case dicionário. Cada registro nesta tabela pode ser identificado exclusivamente por seu case_name e tem uma description adicional , se for necessário. A
in_offer e in_signed_offer as tabelas compartilham a mesma estrutura porque armazenam os mesmos dados. A única diferença entre os dois é que o primeiro armazena casos cobertos na apólice que foi meramente ofertada ao cliente, enquanto o segundo armazena casos na apólice assinada pelo cliente. Para cada registro nessas duas tabelas, armazenaremos o par exclusivo de offer_id /signed_offer_id e case_id , o último dos quais denota o caso ou incidente coberto pela apólice. Todos os outros detalhes serão armazenados em um atributo textual, se necessário. Como mencionamos anteriormente, as apólices de seguro de vida quase sempre estão relacionadas não apenas aos clientes, mas também a seus familiares ou parentes. Precisamos armazenar essas relações também nesta área. Eles serão definidos no momento em que uma apólice for assinada, mas também poderão ser alterados durante a vigência da apólice.
A primeira coisa que precisamos fazer é criar um dicionário contendo todos os valores possíveis que podem ser atribuídos a uma relação. Em nosso modelo, este é o
offer_relation_type dicionário. Além da chave primária, esta tabela contém apenas um atributo—o relation_type – que pode conter apenas valores únicos. Estamos quase lá! A última tabela nesta área de assunto é intitulada
offer_related . Refere-se a uma oferta assinada a qualquer pessoa relacionada ao cliente. Portanto, precisaremos armazenar referências à política assinada (signed_offer_id ) e a pessoa relacionada (person_id ) e também especificar a natureza dessa relação (offer_relation_type_id ). Além disso, precisaremos armazenar details relacionado a este registro e crie um sinalizador para verificar se ainda é válido em nosso sistema. Área de Assunto nº 5:Pagamentos
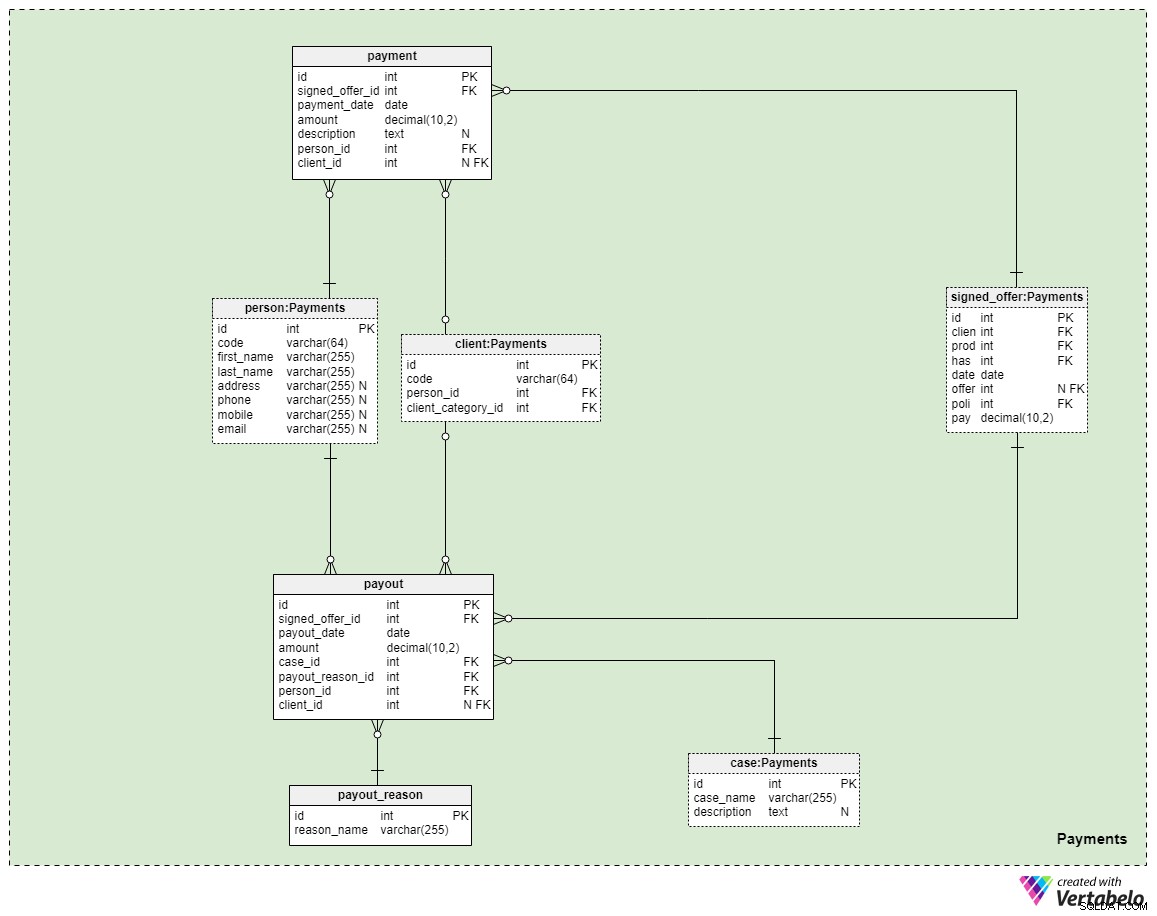
A última área de assunto em nosso modelo diz respeito a pagamentos. Aqui, estamos apresentando apenas três novas tabelas:payment , payout_reason e payment .
Todos os pagamentos relacionados às políticas são armazenados no payment tabela. Nós incluímos apenas os atributos mais importantes aqui:
signed_offer_id— referência ao identificador exclusivo da oferta assinada (política).payment_date— a data em que esse pagamento foi feito.amount— o valor real que foi pago.description— uma descrição opcional do pagamento, em formato textual.person_id— referência ao identificador único da pessoa que efetuou o pagamento. Observe que o cliente que assinou a oferta não é necessariamente a única pessoa que pode efetuar um pagamento.client_id— referência ao identificador único do cliente que efetuou o pagamento. Este atributo conterá um valor somente se o próprio cliente tiver feito o pagamento.
As duas tabelas restantes representam talvez a razão mais importante pela qual pagamos o seguro de vida – que no caso de algo acontecer conosco, os pagamentos serão feitos para nossos familiares ou parceiros de vida/negócios. Como isso acontece depende da sua situação e dos termos da apólice específica que você assinou. Usaremos duas tabelas simples para cobrir esses casos.
O primeiro é um dicionário intitulado
payout_reason e apresenta uma estrutura clássica de dicionário. Além do atributo de chave primária, temos apenas um atributo – o reason_name – que armazenará uma lista de valores únicos indicando por que esse pagamento foi feito. A última tabela no modelo é o
payment tabela. É muito semelhante ao payment tabela, mas as diferenças mais importantes são observadas abaixo:payment_date— a data em que o pagamento foi feito.case_id— referência ao identificador único do caso ou incidente relacionado que desencadeou o pagamento. Isso deve corresponder a um dos IDs incluídos na política.payout_reason_id— referência ao dicionário que descreve o motivo do pagamento com mais detalhes. Embora o caso de pagamento seja mais curto e mais geral, o motivo do pagamento oferecerá detalhes mais específicos sobre o que aconteceu.person_ideclient_id— faz referência à pessoa e ao cliente relacionados ao pagamento, respectivamente.
Resumo
Impressionante! Construímos com sucesso nosso modelo de dados de seguro de vida. Antes de encerrarmos nossa discussão, vale a pena notar que há muito mais coisas que podem ser abordadas neste modelo. Neste artigo, queríamos abordar principalmente o básico do modelo para dar uma ideia de como ele se parece e funciona. Aqui estão mais alguns detalhes que podem ser incorporados a esse modelo de dados:
- Atualizações de apólices adicionais não são cobertas em nosso modelo atual (por exemplo, se você quiser fazer ofertas anuais para apólices existentes, não poderá fazer isso com essa estrutura). Devemos adicionar mais algumas tabelas para armazenar todas as alterações de política para ofertas apresentadas/assinadas.
- Toda a documentação é omitida intencionalmente. Obviamente, haverá muita papelada associada a uma determinada apólice de seguro de vida, especialmente para o processo de assinatura e pagamentos. Poderíamos anexar documentos que descrevem o status do cliente no momento em que a apólice foi assinada e quaisquer alterações ao longo do caminho, bem como quaisquer documentos relacionados a pagamentos.
- Este modelo não incorpora a estrutura necessária para o cálculo do risco de apólice. Devemos ter todos os parâmetros que precisamos testar e quaisquer intervalos que determinem como o valor de um cliente afeta o cálculo geral. Os resultados desses cálculos precisariam ser armazenados para cada oferta e política assinada.
- Na realidade, a estrutura da fatura é muito mais complexa do que abordamos na área de pagamento. Nem mencionamos contas financeiras em nenhum lugar do nosso modelo.
Claramente, o negócio de seguros é bastante complexo. Discutimos apenas um modelo de dados para seguro de vida neste artigo – você pode imaginar como esse modelo de dados evoluiria se fôssemos administrar uma empresa que oferece vários tipos de seguro diferentes? Certamente seria necessário muito planejamento e reflexão para apresentar um modelo de dados organizado para uma empresa como essa.
Se você tiver alguma sugestão ou ideia para melhorar nosso modelo de dados, sinta-se à vontade para nos informar nos comentários abaixo!