Em todo o mundo, o site do portal de empregos é um recurso bem conhecido do cenário da Internet. Grandes players como o Indeed e o Monster transformaram a caça e o recrutamento de empregos em uma verdadeira indústria online. Vamos mergulhar nos recursos elementares aproveitados pelos portais de emprego e construir um modelo de dados que possa suportá-los.
As pessoas adoram economizar tempo usando inovações tecnológicas; o portal de empregos online é outra versão do trabalho mais inteligente, não mais difícil. Os candidatos a emprego e as empresas percebem o valor de fazer sua pesquisa on-line:eles obtêm um alcance melhor em velocidades mais altas e custos mais baixos.
A indústria de portais de empregos está bastante estabilizada agora, pelo menos em relação aos volumes de tráfego. Os caçadores de empregos estão usando esses portais para encontrar vagas em muitos setores, indo além da TI para setores como engenharia, vendas, manufatura e serviços financeiros. No entanto, eles estão recebendo forte concorrência de mídias sociais e sites de redes profissionais como o LinkedIn. Mas ainda há oportunidades a serem exploradas, como expandir sua penetração para áreas rurais e cidades menores.
Então, como dissemos, vamos explorar esse tópico a partir de uma perspectiva de design de banco de dados. Vamos começar enumerando as expectativas fundamentais para um portal de empregos.
O que as pessoas esperam de um portal de empregos online?
Tanto os empregadores como os candidatos a emprego esperam as seguintes funcionalidades de um site de emprego online:
- As pessoas podem se registrar como candidatos a emprego, criar seus perfis e procurar empregos que correspondam às suas habilidades.
- Os usuários podem fazer upload de seus currículos existentes. Se eles não tiverem um, devem preencher um formulário e criar um currículo para eles.
- As pessoas podem se inscrever diretamente nas vagas publicadas.
- As empresas podem se registrar, publicar vagas e pesquisar perfis de candidatos a vagas.
- Vários representantes de uma empresa devem poder registrar e publicar vagas.
- Os representantes da empresa podem visualizar uma lista de candidatos a emprego e entrar em contato com eles, iniciar uma entrevista ou realizar alguma outra ação relacionada ao cargo.
- Usuários registrados devem poder pesquisar vagas e filtrar os resultados com base na localização, habilidades necessárias, salário, nível de experiência etc.
Construindo o modelo de dados
Depois de considerar os requisitos acima, criei três amplas categorias funcionais:
- Gerenciando usuários – Como o portal gerencia os usuários, ou seja, candidatos a emprego, pessoal de RH e recrutadores independentes ou de consultoria. (Para os fins deste modelo, representantes individuais de RH e recrutadores independentes ou de consultoria são tratados como empresas, pelo menos em termos de como usam o portal.)
- Criação de perfis – Como o portal permite que candidatos a emprego e organizações criem perfis e currículos.
- Postar e procurar vagas – Como o portal facilita o processo de publicação, pesquisa e candidatura a empregos.
Vejamos cada uma dessas áreas separadamente.
1. Gerenciando usuários
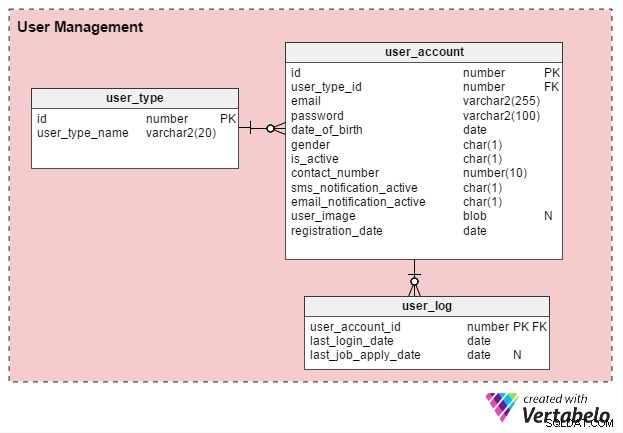
Existem basicamente dois tipos de usuários do portal de empregos online:candidatos a emprego individuais e recrutadores de RH (ou consultores de recrutamento independentes). Vamos criar uma tabela chamada user_type para armazenar esses registros. Para começar, terá dois registros – um para candidatos a emprego e outro para recrutadores. (Sempre podemos criar tipos de registro adicionais conforme necessário.)
Os usuários são obrigados a se registrar antes de poderem usar o portal. A user_account tabela armazena os detalhes básicos de sua conta. Anteriormente, considerei nomear essa tabela como “user”, mas como user é uma palavra-chave definida pelo sistema em quase todos os bancos de dados, prefiro ficar com “user_account”.
A user_account tabela tem as seguintes colunas:
- ID – Esta é a chave primária da tabela e um identificador exclusivo para cada usuário. Esse ID será referido por outras tabelas no modelo de dados.
- user_type_id – Isso significa se o usuário é um candidato a emprego ou um recrutador.
- e-mail – Esta coluna contém o endereço de e-mail do usuário. Ele atua como outro ID de usuário para o portal.
- senha – Isso armazena uma senha de conta criptografada (criada pelos usuários durante o registro).
- data_de_nascimento e gênero – Como seus nomes sugerem, essas colunas contêm a data de nascimento e o sexo dos usuários.
- is_ativo – Inicialmente esta coluna seria “Y”, mas os usuários podem definir seu perfil como inativo ou “N”. Esta coluna armazena sua escolha.
- número_contato – Este é o número de telefone (geralmente celular) fornecido durante o registro. Os usuários podem receber notificações por SMS (texto) neste número. Pode ser o mesmo número (ou não) da lista de candidatos a emprego em seu perfil ou currículo.
- sms_notification_active e email_notification_active – Essas colunas armazenam as preferências dos usuários em relação ao recebimento de notificações por texto e/ou e-mail.
- user_image – Este é um atributo do tipo BLOB que armazena a imagem de perfil de cada usuário. Como este portal permite apenas uma imagem de perfil por usuário, faz sentido armazená-la aqui.
- data_registro – Esta coluna mantém um registro de quando o usuário se registrou no portal.
Criaremos mais uma tabela,
user_log , que armazena um registro da última data de login dos usuários e sua última data de candidatura a emprego. Existem muitos recursos que podem ser construídos a partir desse conhecimento. Por exemplo, podemos usar essas informações para responder à pergunta O usuário X está procurando um emprego ativamente ? Nesse caso, eles podem receber um produto para criar um currículo eficaz. Os usuários que não estão procurando ativamente um emprego não receberiam essa oferta. 2. Construindo Perfis
Podemos dividir ainda mais esta seção em duas áreas:perfis empresariais ou organizacionais e perfis de candidatos a emprego.
Perfis da empresa
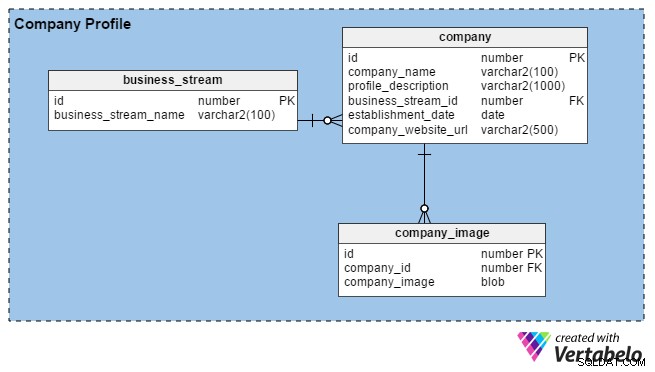
Normalmente, as equipes de RH criam perfis de empresas inserindo detalhes sobre sua organização e imagens de seus escritórios, prédios, etc. Seu principal objetivo é atrair bons talentos. Quando os recrutadores se registram no portal, eles também podem construir perfis de suas empresas (ou sua marca pessoal, se forem independentes) fornecendo alguns detalhes básicos, como há quanto tempo estão no negócio, sua localização e seu principal fluxo de negócios ( ex., manufatura, serviços de TI, financeiro, etc).
O portal permite que recrutadores de RH e consultoria carreguem quantas imagens quiserem (ao contrário dos candidatos a emprego, que só podem enviar uma). Portanto, criamos a company_image table para armazenar várias imagens para cada conta de recrutador. O company_id coluna nesta tabela é uma chave estrangeira que se refere ao identificador exclusivo usado na company tabela.
Na company tabela, temos as seguintes colunas:
- ID – A chave primária desta tabela também é usada para identificar empresas de forma exclusiva.
- nome_da empresa – Como o nome da coluna sugere, ela contém o nome legal de uma empresa.
- profile_description – Contém uma breve descrição de cada empresa.
- business_stream_id – Esta coluna descreve a qual fluxo de negócios uma empresa pertence. Por exemplo, uma empresa de exploração de petróleo e gás pode contratar engenheiros de TI , mas seu principal fluxo de negócios continua sendo "Petróleo e gás".
- estabelecimento_data – Esta coluna informa a idade de uma empresa.
- company_website_url – Esta é uma coluna obrigatória (não anulável). Ele contém um ponteiro para o site oficial da empresa para que os candidatos a emprego possam encontrar mais informações.
Por fim, o
business_stream table tem apenas dois atributos, um id que é a chave primária para esta tabela e uma descrição do fluxo de negócios principal da empresa (business_stream_name ). Perfis de candidatos a emprego
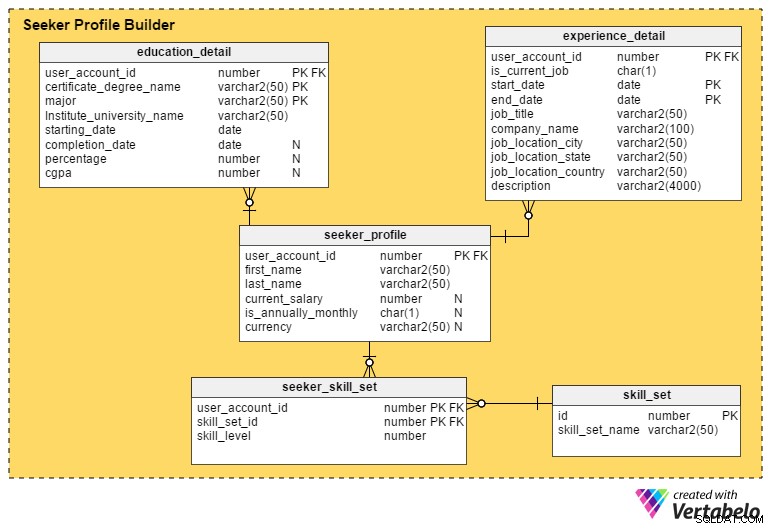
Esta é a seção mais crítica de um portal de empregos. A menos que um portal capture o máximo de detalhes possível dos candidatos a emprego, é difícil para os recrutadores selecionarem os perfis ou candidatos.
O seeker_profile tabela contém detalhes adicionais que não foram capturados durante o processo de registro. Ele contém estes campos:
- user_account_id – Esta coluna é referenciada a partir da
user_accounttabela, e atua como a chave primária para esta tabela. Ele garante que haverá no máximo um perfil por candidato a emprego. - nome_nome e sobrenome – Como os nomes sugerem, essas colunas contêm o nome e o sobrenome do candidato.
- salário_atual – Este atributo contém o salário atual do candidato a emprego. É anulável porque as pessoas podem não querer divulgá-lo.
- é_annually_monthly – Isso define se o valor do salário é por ano ou por mês.
- moeda – Isso armazena a moeda do salário.
O
education_detail table armazena o histórico educacional de cada candidato a emprego, conforme fornecido por eles. Ele tem uma chave primária composta composta pelo user_account_id , certificate_degree_name e principal colunas. Isso garante que os usuários insiram apenas um registro para cada grau ou certificado. A tabela contém estes atributos:- user_account_id – Esta coluna é referenciada a partir da
user_accounttabela e serve como chave primária para esta tabela. - certificate_degree_name – Este é o tipo de certificado ou grau; por exemplo. ensino médio, ensino médio, graduação, pós-graduação ou certificado profissional.
- principal – Esta coluna contém o curso principal de estudo para o certificado ou grau – ex. um diploma de bacharel com especialização em ciência da computação.
- institute_university_name – Este é o instituto, escola ou universidade que concedeu o diploma ou certificado.
- data_inicial – Este atributo armazena a data em que o usuário foi aceito em um programa educacional.
- data_conclusão – Esta é a data em que o diploma ou certificado foi concedido. No entanto, esse atributo é anulável; as pessoas ainda podem estar concluindo o programa enquanto procuram um emprego ou podem ter desistido completamente do programa.
- porcentagem e cgpa – Essas colunas armazenam a porcentagem de notas ou CGPA (média de notas cumulativas) alcançadas pelos usuários em seu curso de graduação ou certificado.
O
experience_detail table mantém registros da experiência profissional passada e atual dos usuários. Ele contém as seguintes colunas importantes:- user_account_id – Esta coluna é referenciada a partir da
user_accounttable e é a chave primária para esta tabela. - is_current_job – Esta é uma coluna indicadora que significa o trabalho atual do usuário. Essa coluna também desempenha um papel importante na determinação da localização atual dos usuários e por quanto tempo eles ocupam sua posição atual.
- data_inicial – Isso armazena quando um usuário inicia um trabalho.
- data_final – Isso armazena quando um usuário termina um trabalho.
- job_title – Contém informações sobre a função do usuário.
- nome_da empresa – Este atributo contém o nome da empresa relevante associado a um trabalho.
- job_location_city – Isso significa a cidade onde o trabalho estava localizado.
- job_location_state – Isso significa o estado em que o trabalho estava localizado.
- job_location_country – Isso significa o país onde o trabalho estava localizado.
- descrição – Esta coluna armazena detalhes sobre funções e responsabilidades, desafios e conquistas.
Os candidatos a emprego podem possuir várias habilidades. Para manter registros de todos esses conjuntos de habilidades, criaremos a tabela
seeker_skill_set . As colunas são:- user_account_id – Esta coluna é referenciada a partir da
user_accounttable e é a chave primária para esta tabela. - skill_set_id – Esse ID significa qual conjunto de habilidades o usuário possui.
- skill_level – Esse atributo numérico quantifica a experiência dos candidatos a emprego em uma habilidade específica. Um número de 1 (iniciante) a 10 (especialista) indica o nível de experiência deles.
Por fim, o
skill_set A tabela contém descrições de todas as habilidades mencionadas no skill_set_id da tabela acima atributo. Ele contém apenas duas colunas, um skill_set_name e seu id relacionado . 3. Publicação e pesquisa de empregos
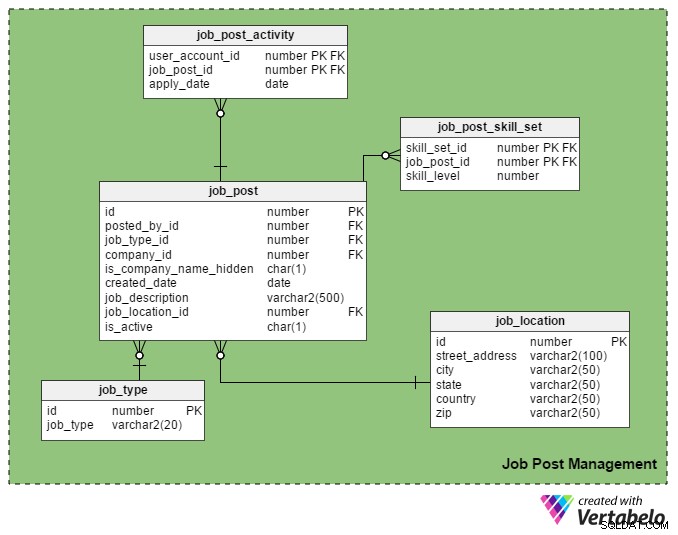
Este é o principal USP (Unique Selling Point) de um portal de empregos. Apenas recrutadores registrados podem postar uma vaga no portal e somente candidatos registrados podem se candidatar a eles.
O job_post table é a tabela principal nesta área de assunto. Como você pode imaginar, ele contém detalhes sobre postagens de emprego. Todas as outras tabelas nesta seção são criadas em torno dela e vinculadas a ela.
- ID – Esta é a chave primária desta tabela. Cada anúncio de emprego recebe um número exclusivo, e esse número é referido em outras tabelas.
- posted_by_id – Esta coluna contém o register_user_id do recrutador que postou a vaga.
- job_type_id – Esta coluna indica se a duração do trabalho é permanente ou temporária (contrato).
- ID_da empresa – Esta coluna armazena o ID da empresa relacionada ao anúncio de emprego. É uma referência à
companytabela. - is_company_name_hidden – Esta é uma coluna de sinalização que mostra se o nome da empresa deve ser mostrado aos candidatos a emprego. Os recrutadores podem preferir não mostrar os nomes das empresas em suas postagens. Em vez disso, eles usam termos como "Global Automobile Company", "California-Based IT Company" e assim por diante.
- data_criada – Isso armazena a data em que o trabalho foi publicado.
- job_description – Contém uma breve descrição do trabalho.
- job_location_id – Refere-se a um atributo no
job_locationtabela que armazena a localização real do trabalho:endereço, cidade, estado, país e código postal. - is_ativo – Isso significa que um trabalho ainda está aberto. Os recrutadores podem marcar suas postagens como inativas assim que as vagas forem preenchidas.
O
job_post_skill_set A tabela armazena detalhes sobre os conjuntos de habilidades necessários para um trabalho. A estrutura da tabela é idêntica ao seeker_skill_set tabela. E a última tabela desta seção, a
job_post_activity tabela, contém detalhes sobre quais candidatos a emprego se candidatam a um emprego e quando. O que você adicionaria a este modelo de dados do portal de empregos on-line?
Os portais de empregos online de hoje fazem mais do que fornecer uma plataforma para postar e se candidatar a empregos. Eles geralmente incluem outros serviços profissionais como:
- Um painel pessoal para acompanhar os pedidos de emprego
- Atualizações em tempo real dos aplicativos
- Criadores de currículos em vídeo
- Serviços especializados de redação de currículos
- LinkedIn ou outros criadores de perfil de mídia social
- Relatórios de salários em cargos, empresas, setores ou localizações geográficas
Se quiséssemos construir esses recursos em nosso sistema, que alterações adicionais precisaríamos fazer? Você consegue pensar em outros itens obrigatórios em um portal de empregos?
Por favor, deixe-nos saber suas opiniões na seção de comentários.