Esta é a segunda parte de uma série de duas partes sobre o repmgr do 2ndQuadrant, uma ferramenta de alta disponibilidade de código aberto para PostgreSQL.
Na primeira parte, configuramos um cluster PostgreSQL 12 de três nós junto com um nó “testemunha”. O cluster consistia em um nó primário e dois nós de espera. O cluster e o nó testemunha foram hospedados em uma Amazon Web Service Virtual Private Cloud (VPC). Os servidores EC2 que hospedam as instâncias do Postgres foram colocados em sub-redes em diferentes zonas de disponibilidade (AZ), conforme mostrado abaixo:
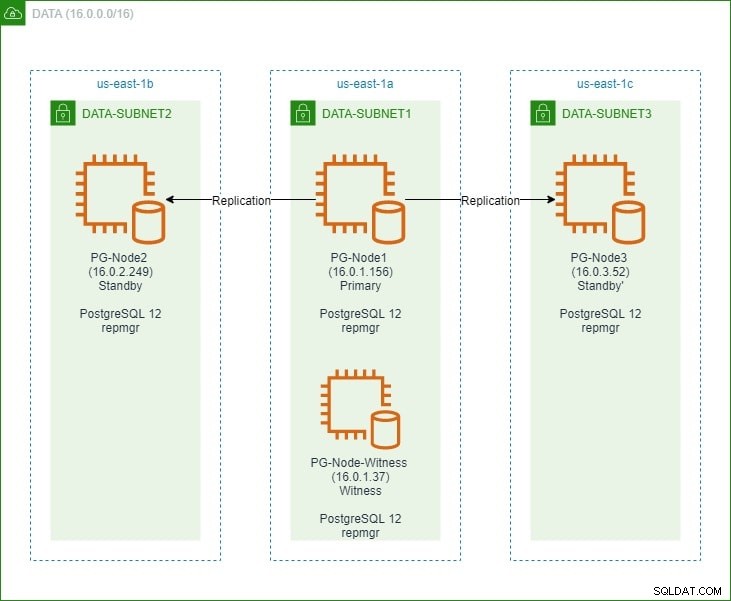
Faremos referências extensas aos nomes dos nós e seus endereços IP, então aqui está a tabela novamente com os detalhes dos nós:
| Nome do nó | Endereço IP | Função | Aplicativos em execução |
| PG-Nó1 | 16.0.1.156 | Primário | PostgreSQL 12 e repmgr |
| PG-Node2 | 16.0.2.249 | Em espera 1 | PostgreSQL 12 e repmgr |
| PG-Node3 | 16.0.3.52 | Em espera 2 | PostgreSQL 12 e repmgr |
| PG-Node-Testemunha | 16.0.1.37 | Testemunha | PostgreSQL 12 e repmgr |
Instalamos o repmgr nos nós primário e em espera e, em seguida, registramos o nó primário com repmgr. Em seguida, clonamos os dois nós de espera do primário e os iniciamos. Ambos os nós de espera também foram registrados com repmgr. O comando “repmgr cluster show” nos mostrou que tudo estava funcionando conforme o esperado:

Problema atual
Configurar a replicação de streaming com repmgr é muito simples. O que precisamos fazer a seguir é garantir que o cluster funcione mesmo quando o primário ficar indisponível. É isso que abordaremos neste artigo.
Na replicação do PostgreSQL, um primário pode ficar indisponível por alguns motivos. Por exemplo:
- O sistema operacional do nó principal pode falhar ou não responder
- O nó primário pode perder sua conectividade de rede
- O serviço PostgreSQL no nó primário pode travar, parar ou ficar indisponível inesperadamente
- O serviço PostgreSQL no nó primário pode ser interrompido intencionalmente ou acidentalmente
Sempre que um primário fica indisponível, um standby não promover-se automaticamente para a função principal. Uma espera ainda continua a servir consultas somente leitura – embora os dados estejam atualizados até o último LSN recebido do primário. Qualquer tentativa de uma operação de gravação falhará.
Existem duas maneiras de mitigar isso:
- O modo de espera é manualmente atualizado para uma função principal. Geralmente, esse é o caso de um failover planejado ou “troca”
- O modo de espera é automaticamente promovido a um papel principal. Esse é o caso de ferramentas não nativas que monitoram continuamente a replicação e executam ações de recuperação quando o primário não está disponível. repmgr é uma dessas ferramentas.
Vamos considerar o segundo cenário aqui. Esta situação tem alguns desafios extras:
- Se houver mais de um standby, como a ferramenta (ou os standbys) decide qual deles deve ser promovido como principal? Como funciona o quórum e o processo de promoção?
- Para várias esperas, se uma se tornar primária, como os outros nós começam a “segui-la” como a nova primária?
- O que acontece se o primário estiver funcionando, mas por algum motivo temporariamente desconectado da rede? Se um dos standbys for promovido a primário e o primário original voltar a ficar online, como evitar uma situação de “cérebro dividido”?
Resposta do remgr:Witness Node e o daemon repmgr
Para responder a essas perguntas, o repmgr usa algo chamado nó de testemunha . Quando o primário não está disponível – é o trabalho do nó testemunha ajudar os standbys a atingir um quorum se um deles for promovido a uma função primária. As esperas atingem esse quorum determinando se o nó primário está realmente offline ou apenas temporariamente indisponível. O nó testemunha deve estar localizado no mesmo centro de dados/segmento de rede/sub-rede que o nó primário, mas NUNCA deve ser executado no mesmo host físico que o nó primário.
Lembre-se de que, na primeira parte desta série, implementamos um nó testemunha na mesma zona de disponibilidade e sub-rede do nó primário. Nós o chamamos de PG-Node-Witness e instalamos uma instância do PostgreSQL 12 lá. Neste post, instalaremos o repmgr lá também, mas falaremos mais sobre isso mais tarde.
O segundo componente da solução é o repmgr daemon (repmgrd) em execução em todos os nós do cluster e no nó testemunha. Novamente, não iniciamos esse daemon na primeira parte desta série, mas faremos isso aqui. O daemon vem como parte do pacote repmgr – quando habilitado, ele é executado como um serviço regular e monitora continuamente a integridade do cluster. Ele inicia um failover quando um quorum é atingido sobre o primário estar offline. Além de promover automaticamente um standby, ele também pode reiniciar outros standbys em um cluster de vários nós para seguir o novo primário .
O Processo de Quórum
Quando um standby percebe que não pode ver o primário, ele consulta outros standbys. Todas as esperas em execução no cluster atingem um quórum para escolher um novo primário usando uma série de verificações:
- Cada standby interroga outros standbys sobre a última vez em que “viu” o primário. Se o último LSN replicado de um standby ou a hora da última comunicação com o primário for mais recente que o último LSN replicado do nó atual ou a hora da última comunicação, o nó não faz nada e aguarda a restauração da comunicação com o primário
- Se nenhum dos standbys puder ver o primário, eles verificarão se o nó testemunha está disponível. Se o nó testemunha também não puder ser alcançado, os standbys assumem que há uma interrupção de rede no lado primário e não prosseguem para escolher um novo primário
- Se a testemunha puder ser alcançada, as esperas assumem que o primário está inativo e procedem para escolher um primário
- O nó que foi configurado como primário “preferido” será então promovido. Cada espera terá sua replicação reinicializada para seguir o novo primário.
Configurando o cluster para failover automático
Agora vamos configurar o cluster e o nó testemunha para failover automático.
Etapa 1:instalar e configurar repmgr no Witness
Já vimos como instalar o pacote repmgr em nosso último artigo. Também fazemos isso no nó testemunha:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
E então:
# yum install repmgr12 -y
Em seguida, adicionamos as seguintes linhas no arquivo postgresql.conf do nó testemunha:
listen_addresses ='*'shared_preload_libraries ='repmgr'
Também adicionamos as seguintes linhas no arquivo pg_hba.conf no nó testemunha. Observe como estamos usando o intervalo CIDR do cluster em vez de especificar endereços IP individuais.
Replicação local Repmgr Trusthost Replicação REPMGR 127.0.0.1/32 TRUSTHOST REPLAÇÃO REPMGR 16.0.0.0/16 REPMGR REPMGR REPMGR TRUSTHOST REPMGR REPMGR 127.0.0.1/32 TRUSTHOST REPMGRGRGRHRGR 16.0.0.0.0.0.0.0 127.0.0.1/32 TRUSTHOST REPMGRgr 16.0.0.0.0.0.0.0.0.0.0.0.0.0.0 127.0.0.1/32 TRUSTHost
Observação
[As etapas descritas aqui são apenas para fins de demonstração. Nosso exemplo aqui está usando IPs acessíveis externamente para os nós. Usar listen_address =‘*’ junto com o mecanismo de segurança “trust” do pg_hba, portanto, representa um risco de segurança e NÃO deve ser usado em cenários de produção. Em um sistema de produção, todos os nós estarão dentro de uma ou mais sub-redes privadas, acessíveis por IPs privados de jumphosts.]
Com as alterações postgresql.conf e pg_hba.conf feitas, criamos o usuário repmgr e o banco de dados repmgr na testemunha e alteramos o caminho de pesquisa padrão do usuário repmgr:
[example@sqldat.comitness ~]$ createuser --superuser repmgr[example@sqldat.com ~]$ createdb --owner=repmgr repmgr[example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Finalmente, adicionamos as seguintes linhas ao arquivo repmgr.conf, localizado em /etc/repmgr/12/
node_id =4node_name ='PG-Node-Witness'conninfo ='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'diretório_dados ='/var/lib/pgsql/12/data'
Depois que os parâmetros de configuração são definidos, reiniciamos o serviço PostgreSQL no nó testemunha:
# systemctl reinicie postgresql-12.service
Para testar a conectividade com o repmgr do nó testemunha, podemos executar este comando a partir do nó primário:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Em seguida, registramos o nó testemunha com repmgr executando o comando “repmgr testemunha register” como o usuário postgres. Observe como estamos usando o endereço do primário node e NÃO o node testemunha no comando abaixo:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf registo de testemunha -h 16.0.1.156
Isso ocorre porque o comando “repmgr testemunha register” adiciona os metadados do nó testemunha ao banco de dados repmgr do nó primário e, se necessário, inicializa o nó testemunha instalando a extensão repmgr e copiando os metadados repmgr para o nó testemunha.
A saída ficará assim:
INFO:conectando ao nó de testemunha "PG-Node-Witness" (ID:4)INFO:conectando ao nó primárioNOTICE:tentando instalar a extensão "repmgr"NOTICE:extensão "repmgr" instalada com sucessoINFO:registro de testemunha completo AVISO:nó testemunha "PG-Node-Witness" (ID:4) com sucesso registrado
Por fim, verificamos o status da configuração geral de qualquer nó:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
A saída fica assim:

Etapa 2:modificando o arquivo sudoers
Com o cluster e a testemunha em execução, adicionamos as seguintes linhas no arquivo sudoers Em cada nó do cluster e no nó testemunha:
Padrões:postgres !requirettypostgres ALL =NOPASSWD:/usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service , /usr/bin/systemctl recarregar postgresql-12.service, /usr/bin/systemctl iniciar repmgr12.service, /usr/bin/systemctl parar repmgr12.serviceEtapa 3:configuração dos parâmetros repmgrd
Já adicionamos quatro parâmetros no arquivo repmgr.conf em cada nó. Os parâmetros adicionados são os básicos necessários para a operação do repmgr. Para habilitar o daemon repmgr e o failover automático, vários outros parâmetros precisam ser habilitados/adicionados. Nas subseções a seguir, descreveremos cada parâmetro e o valor para o qual eles serão definidos em cada nó.
failover
O parâmetro de failover é um dos parâmetros obrigatórios para o daemon repmgr. Esse parâmetro informa ao daemon se ele deve iniciar um failover automático quando uma situação de failover for detectada. Pode ter um dos dois valores:“manual” ou “automático”. Vamos definir isso como automático em cada nó:
failover ='automático'promova_comando
Este é outro parâmetro obrigatório para o daemon repmgr. Este parâmetro informa ao daemon repmgr qual comando ele deve executar para promover um modo de espera. O valor desse parâmetro será normalmente o comando “repmgr standby promote” ou o caminho para um script de shell que chama o comando. Para nosso caso de uso, definimos isso para o seguinte em cada nó:
promote_comando ='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'follow_command
Este é o terceiro parâmetro obrigatório para o daemon repmgr. Este parâmetro diz a um nó em espera para seguir o novo primário. O daemon repmgr substitui o espaço reservado %n pelo ID do nó do novo primário em tempo de execução:
follow_command ='/usr/pgsql-12/bin/repmgr espera siga -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'prioridade
O parâmetro de prioridade adiciona peso à elegibilidade de um nó para se tornar um primário. Definir esse parâmetro com um valor mais alto fornece a um nó maior elegibilidade para se tornar o nó principal. Além disso, definir esse valor como zero para um nó garantirá que o nó nunca seja promovido como primário.
Em nosso caso de uso, temos dois standbys:PG-Node2 e PG-Node3. Queremos promover o PG-Node2 como o novo primário quando o PG-Node1 ficar offline e o PG-Node3 seguir o PG-Node2 como seu novo primário. Definimos o parâmetro com os seguintes valores nos dois nós de espera:
| Nome do nó | Configuração de parâmetros |
| PG-Node2 | prioridade =60 |
| PG-Node3 | prioridade =40 |
monitor_interval_secs
Esse parâmetro informa ao daemon repmgr com que frequência (em número de segundos) ele deve verificar a disponibilidade do nó upstream. Em nosso caso, há apenas um nó upstream:o nó primário. O valor padrão é 2 segundos, mas vamos definir isso explicitamente de qualquer maneira em cada nó:
monitor_interval_secs =2
connection_check_type
O parâmetro connection_check_type determina o protocolo que o daemon repmgr usará para alcançar o nó upstream. Este parâmetro pode assumir três valores:
- ping :repmgr usa o método PQPing()
- conexão :repmgr tenta criar uma nova conexão com o nó upstream
- consulta :repmgr tenta executar uma consulta SQL no nó upstream usando a conexão existente
Novamente, definiremos este parâmetro com o valor padrão de ping em cada nó:
connection_check_type ='ping'
reconnect_attempts e reconnect_interval
Quando o primário ficar indisponível, o daemon repmgr nos nós de espera tentará se reconectar ao primário por reconnect_attempts vezes. O valor padrão para este parâmetro é 6. Entre cada tentativa de reconexão, ele aguardará reconnect_interval segundos, que tem um valor padrão de 10. Para fins de demonstração, usaremos um intervalo curto e menos tentativas de reconexão. Definimos este parâmetro em cada nó:
reconnect_attempts =4reconnect_interval =8
primary_visibility_consensus
Quando o primário fica indisponível em um cluster de vários nós, os standbys podem consultar uns aos outros para criar um quorum sobre um failover. Isso é feito perguntando a cada espera sobre a última vez que viu o primário. Se a última comunicação de um nó for muito recente e posterior à hora em que o nó local viu o primário, o nó local assume que o primário ainda está disponível e não avança com uma decisão de failover.
Para habilitar esse modelo de consenso, o parâmetro primary_visibility_consensus precisa ser definido como "true" em cada nó - incluindo a testemunha:
primary_visibility_consensus =true
standby_disconnect_on_failover
Quando o parâmetro standby_disconnect_on_failover é definido como “true” em um nó de espera, o daemon repmgr garantirá que seu receptor WAL esteja desconectado do primário e não receba nenhum segmento WAL. Ele também aguardará que os receptores WAL de outros nós em espera parem antes de tomar uma decisão de failover. Este parâmetro deve ser definido com o mesmo valor em cada nó. Estamos definindo isso como "true".
standby_disconnect_on_failover =true
Definir esse parâmetro como true significa que cada nó em espera parou de receber dados do primário à medida que o failover ocorre. O processo terá um atraso de 5 segundos mais o tempo que o receptor WAL leva para parar antes que uma decisão de failover seja tomada. Por padrão, o daemon repmgr aguardará 30 segundos para confirmar que todos os nós irmãos pararam de receber segmentos WAL antes que o failover aconteça.
repmgrd_service_start_command e repmgrd_service_stop_command
Esses dois parâmetros especificam como iniciar e parar o daemon repmgr usando os comandos “repmgr daemon start” e “repmgr daemon stop”.
Basicamente, esses dois comandos são wrappers em torno de comandos do sistema operacional para iniciar/parar o serviço. Os dois valores de parâmetro mapeiam esses comandos para suas versões específicas do SO. Definimos esses parâmetros para os seguintes valores em cada nó:
repmgrd_service_start_command ='sudo /usr/bin/systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo /usr/bin/systemctl stop repmgr12.service'
Comandos de início/parada/reinicialização do serviço PostgreSQL
Como parte de sua operação, o daemon repmgr geralmente precisará parar, iniciar ou reiniciar o serviço PostgreSQL. Para garantir que isso ocorra sem problemas, é melhor especificar os comandos do sistema operacional correspondentes como valores de parâmetro no arquivo repmgr.conf. Vamos definir quatro parâmetros em cada nó para esta finalidade:
service_start_command ='sudo /usr/bin/systemctl start postgresql-12.service'service_stop_command ='sudo /usr/bin/systemctl stop postgresql-12.service'service_restart_command ='sudo /usr/bin/systemctl restart postgresql-12.service'service_reload_command ='sudo /usr/bin/systemctl recarregar postgresql-12.service'
monitoring_history
Definir o parâmetro monitoring_history como "yes" garantirá que o repmgr esteja salvando seus dados de monitoramento de cluster. Definimos isso como "sim" em cada nó:
monitoring_history =sim
log_status_interval
Definimos o parâmetro em cada nó para especificar com que frequência o daemon repmgr registrará uma mensagem de status. Nesse caso, estamos definindo isso a cada 60 segundos:
log_status_interval =60
Etapa 4:Iniciando o daemon repmgr
Com os parâmetros agora definidos no cluster e no nó testemunha, executamos uma simulação do comando para iniciar o daemon repmgr. Testamos isso primeiro no nó primário e, em seguida, nos dois nós de espera, seguidos pelo nó testemunha. O comando deve ser executado como o usuário postgres:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
A saída deve ficar assim:
INFO:pré-requisitos para iniciar repmgrd atendidos DETAIL:o seguinte comando seria executado: sudo /usr/bin/systemctl start repmgr12.service
Em seguida, iniciamos o daemon em todos os quatro nós:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
A saída em cada nó deve mostrar que o daemon foi iniciado:
AVISO:executando:"sudo /usr/bin/systemctl start repmgr12.service"AVISO:repmgrd foi iniciado com sucesso
Também podemos verificar o evento de inicialização do serviço dos nós primários ou de espera:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
A saída deve mostrar que o daemon está monitorando as conexões:
ID do nó | Nome | Evento | OK | Carimbo de data e hora | Detalhes --------+-----------------+---------------+----+- --------------------+----------------------------- --------------------------4 | PG-Node-Testemunha | repmgrd_start | t | 2020-02-05 11:37:31 | testemunha a conexão de monitoramento com o nó primário "PG-Node1" (ID:1) 3 | PG-Nó3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitorando a conexão com o nó upstream "PG-Node1" (ID:1) 2 | PG-Nó2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitorando a conexão com o nó upstream "PG-Node1" (ID:1) 1 | PG-Nó1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitorando cluster primário "PG-Node1" (ID:1)
Finalmente, podemos verificar a saída do daemon do syslog em qualquer um dos standbys:
# cat /var/log/messages | grep repmgr | menos
Aqui está a saída do PG-Node3:
Fev 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [AVISO] usando o arquivo de configuração fornecido "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) inicializando 5 de fevereiro 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] conectando-se ao banco de dados "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2"Feb 5 11:37:24 PG-Node3 systemd[1]:repmgr12.service:Não é possível abrir o arquivo PID /run/repmgr/repmgrd-12.pid (ainda?) após o início:Arquivo ou diretório inexistenteFeb 5 11:37 :24 PG-Node3 repmgrd[2014]:INFO: set_repmgrd_pid():o pidfile fornecido é /run/repmgr/repmgrd-12.pid 5 de fevereiro 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [NOTICE] iniciando o monitoramento do nó "PG-Node3" (ID:3) 5 de fevereiro 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] "connection_check_type" definido como "ping" 5 de fevereiro 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] monitorando a conexão com o nó upstream "PG-Node1" (ID:1) 5 de fevereiro 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [INFO] nó "PG-Node3" (ID:3) monitorando o nó upstream "PG- Node1" (ID:1) em estado normal 5 de fevereiro 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [DETAIL] a última atualização das estatísticas de monitoramento foi há 2 segundos 5 de fevereiro 11:39:26 PG-Node3 repmgrd[2014]:[2020-02-05 11:39:26] [INFO] nó "PG-Node3" (ID:3) monitorando o nó upstream "PG- Node1" (ID:1) em estado normal … …
A verificação do syslog no nó primário mostra um tipo diferente de saída:
Fev 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [AVISO] usando o arquivo de configuração fornecido "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) inicializando 5 de fevereiro 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] conectando-se ao banco de dados "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2"fev 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [NOTICE] iniciando o monitoramento do nó "PG-Node1" (ID:1) 5 de fevereiro 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] "connection_check_type" definido como "ping" 5 de fevereiro 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [NOTICE] monitoramento do cluster primário "PG-Node1" (ID:1) 5 de fevereiro 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] nó filho "PG-Node-Witness" (ID:4) ainda não está anexado 5 de fevereiro 11 :37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] o nó filho "PG-Node3" (ID:3) está anexado 5 de fevereiro 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] o nó filho "PG-Node2" (ID:2) está anexado 5 de fevereiro 11:37:32 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:32] [NOTICE] nova testemunha "PG-Node-Witness" (ID:4) se conectou 5 de fevereiro 11:38:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:38:14] [INFO] monitorando o nó primário "PG-Node1" (ID:1) em estado normal 5 de fevereiro 11:39:15 PG-Node1 repmgrd[2017]:[2020-02-05 11:39:15] [INFO] monitorando o nó primário "PG-Node1" (ID:1) em estado normal … …
Etapa 5:simulando um primário com falha
Agora vamos simular um primário com falha parando o nó primário (PG-Node1). No prompt do shell do nó, executamos o seguinte comando:
# systemctl stop postgresql-12.service
O processo de failover
Quando o processo parar, esperamos cerca de um minuto ou dois e, em seguida, verificamos o arquivo syslog do PG-Node2. As seguintes mensagens são mostradas. Para maior clareza e simplicidade, temos grupos de mensagens codificados por cores e adicionamos espaços em branco entre as linhas:
… 5 de fevereiro 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [WARNING] não foi possível fazer ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"Feb 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [ DETALHE] PQping() retornou "PQPING_NO_RESPONSE" 5 de fevereiro 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [INFO] dormindo 8 segundos até a próxima tentativa de reconexão 5 de fevereiro 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] verificando o estado do nó 1, 2 de 4 tentativas 5 de fevereiro 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [WARNING] não foi possível fazer ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"05 de fevereiro 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [ DETALHE] PQping() retornou "PQPING_NO_RESPONSE" 5 de fevereiro 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] dormindo 8 segundos até a próxima tentativa de reconexão 5 de fevereiro 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] verificando o estado do nó 1, 3 de 4 tentativas 5 de fevereiro 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [WARNING] não foi possível fazer ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"05 de fevereiro 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [ DETALHE] PQping() retornou "PQPING_NO_RESPONSE" 5 de fevereiro 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] dormindo 8 segundos até a próxima tentativa de reconexão 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] verificando o estado do nó 1, 4 de 4 tentativas 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [WARNING] não foi possível fazer ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr"05 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [ DETALHE] PQping() retornou "PQPING_NO_RESPONSE" 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [WARNING] não foi possível reconectar ao nó 1 após 4 tentativas 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] configurando "wal_retrieve_retry_interval" para 86405000 milissegundos 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVISO] wal receiver não está funcionando 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVISO] Receptor WAL desconectado em todos os nós irmãos 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] Receptor WAL desconectado em todos os 2 nós irmãos 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] último lsn de recebimento do nó local:0/2214A000 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] verificando o estado do nó irmão "PG-Node3" (ID:3) 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] nó "PG-Node3" (ID:3) informa que seu upstream é o nó 1 , visto pela última vez há 26 segundo(s) 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] nó 3 viu o nó principal pela última vez há 26 segundos 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] último LSN de recebimento para o nó irmão "PG-Node3" (ID:3) é :0/2214A000 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] o nó "PG-Node3" (ID:3) tem o mesmo LSN do candidato atual "PG-Node2" (ID:2) 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] o nó "PG-Node3" (ID:3) tem prioridade mais baixa (40) do que o candidato atual "PG-Node2" (ID:2) (60) 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] verificando o estado do nó irmão "PG-Node-Witness" (ID:4) 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] o nó "PG-Node-Witness" (ID:4) informa que seu upstream é nó 1, visto pela última vez há 26 segundos 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] o nó 4 viu pela última vez o nó principal 26 segundos atrás 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] nós visíveis:3; nós totais:3; nenhum nó viu o primário nos últimos 4 segundos …… 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] candidato a promoção é "PG-Node2" (ID:2) 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] configurando "wal_retrieve_retry_interval" para 5000 ms 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVISO] este nó é o vencedor, agora se promoverá e informará outros nós …… 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [AVISO] promovendo o modo de espera para primário 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [DETAIL] promovendo o servidor "PG-Node2" (ID:2) usando pg_promote() 5 de fevereiro 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] aguardando até 60 segundos (parâmetro "promote_check_timeout") para que a promoção seja concluída 5 de fevereiro 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [AVISO] PROMOÇÃO EM ESPERA bem-sucedida 5 de fevereiro 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [DETAIL] o servidor "PG-Node2" (ID:2) foi promovido com sucesso para primário 5 de fevereiro 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] 2 seguidores para notificar 5 de fevereiro 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] notificando o nó "PG-Node3" (ID:3) para seguir o nó 2 5 de fevereiro 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] notificando o nó "PG-Node-Witness" (ID:4) para seguir o nó 2 5 de fevereiro 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] alternando para o modo de monitoramento primário 5 de fevereiro 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] monitoramento do cluster primário "PG-Node2" (ID:2) 5 de fevereiro 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [NOTICE] nova testemunha "PG-Node-Witness" (ID:4) se conectou 5 de fevereiro 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [AVISO] novo "PG-Node3" em espera (ID:3) conectado 5 de fevereiro 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [AVISO] novo modo de espera "PG-Node3" (ID:3) conectou-se 5 de fevereiro 11:55:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:55:02] [INFO] monitorando o nó primário "PG-Node2" (ID:2) em estado normal 5 de fevereiro 11:56:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:56:02] [INFO] monitorando o nó primário "PG-Node2" (ID:2) em estado normal … …
Há muitas informações aqui, mas vamos detalhar como os eventos se desenrolaram. Para simplificar, agrupamos as mensagens e colocamos espaços em branco entre os grupos.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
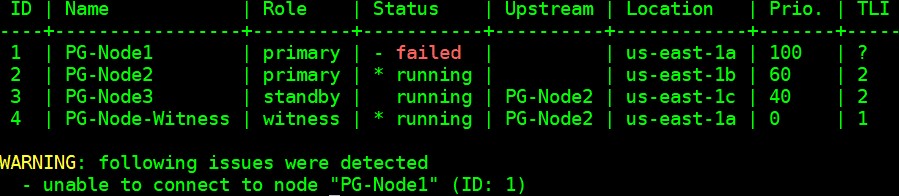
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID:2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID:3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID:4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID:2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID:2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID:2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID:4) has connected
Conclusão
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1



