Nesta era de competição acirrada, os portais de emprego não são apenas plataformas para publicar e encontrar empregos. Eles estão aproveitando serviços e recursos avançados para manter seus clientes engajados. Vamos mergulhar em alguns recursos avançados e construir um modelo de dados que possa lidar com eles.
Expliquei os recursos básicos necessários para um site de portal de empregos em um artigo anterior. O modelo é mostrado abaixo. Consideraremos este modelo como base, que alteraremos para atender aos novos requisitos. Primeiro, vamos considerar quais devem ser esses requisitos (ou aprimoramentos).
O que estamos adicionando ao modelo de dados do portal de empregos on-line?
Resumidamente, vamos adicionar quatro melhorias ao nosso antigo modelo de dados:
- Um painel pessoal para quem procura emprego. Isso acompanha todas as solicitações de emprego e fornece atualizações em tempo real sobre qualquer alteração de status (ou seja, uma solicitação muda de recebida para revisão).
- Um painel de perfil. Isso detalha quem está visitando o perfil de um candidato a emprego e quantas vezes seu currículo foi baixado no último dia, semana ou mês.
- Gerenciamento de serviços pagos. Os portais de emprego geralmente oferecem serviços como preparação de currículo especializado, gerenciamento de perfil social, consultoria de carreira etc. Nossas novas funcionalidades poderão oferecer suporte a ofertas pagas.
- Gerenciamento de formulários de pré-inscrição. À medida que os candidatos enviam uma solicitação de emprego, eles podem ser solicitados a preencher um pequeno questionário relacionado a horários de trabalho, locais e verificações de antecedentes. Criaremos formas para que este formulário seja personalizado pelos recrutadores e para que perguntas e respostas sejam capturadas pelo sistema.
Melhoria nº 1:painel pessoal
Perguntas a serem respondidas: Qual é o status atual de uma inscrição enviada? É pré-selecionado para uma entrevista? Já foi visto?
Podemos acompanhar os pedidos de emprego colocando o
job_application_status_id coluna na job_post_activity tabela. Esta coluna contém o status atual de um pedido de emprego. Precisamos criar outra tabela, job_application_status , para manter todos os status de aplicativos possíveis. Alguns status podem ser 'enviados', 'em análise', 'arquivados', 'rejeitados', 'selecionados para entrevista', 'em processo de recrutamento' e assim por diante. 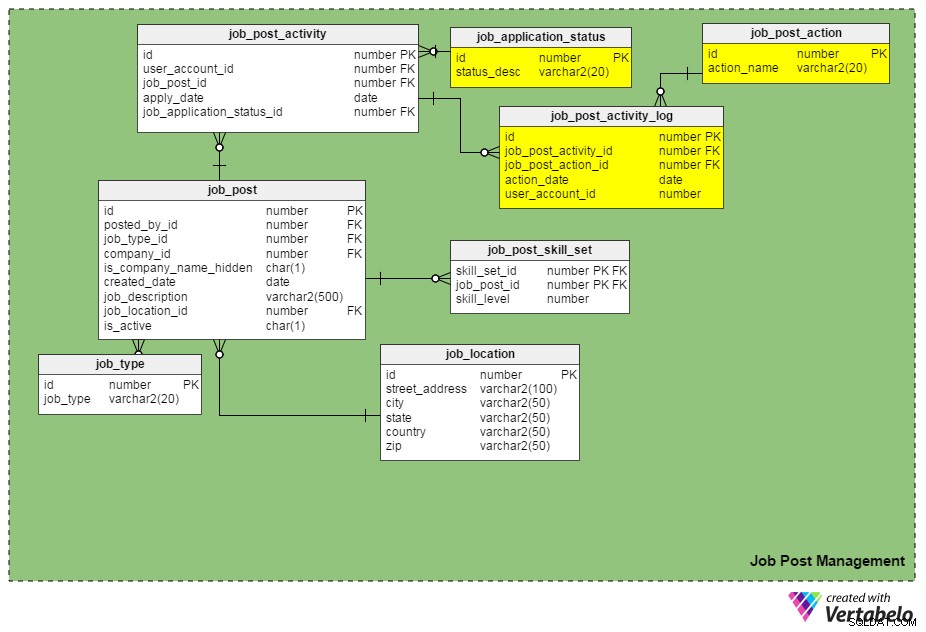
Outra nova tabela, job_post_activity_log , armazena informações sobre todas as ações executadas em formulários de emprego, quem executou a ação e quando foi realizada. Esta tabela contém as seguintes colunas:
id– A chave primária da tabela.job_post_activity_id– O ID do aplicativo no qual a ação é executada.job_post_action_id– O ID da ação executada. Esta é uma chave estrangeira vinculada aojob_post_actiontabela. Os tipos de ações que podemos armazenar aqui incluem 'enviado', 'visualizado', 'entrevistado', 'teste escrito realizado', 'oferta em andamento', 'oferta enviada', 'oferta aceita' etc.action_date– A data em que uma ação foi executada.user_account_id– O ID da pessoa que executou a ação.
O “job_post_action” é idêntico ao “job_application_status”? Como eles são diferentes?
Eles parecem idênticos no início, mas na verdade são diferentes. Existem razões válidas pelas quais precisamos de dois campos semelhantes:
- Um candidato é entrevistado por duas ou mais pessoas separadamente. Nesse caso, o status do pedido de emprego permanece o mesmo (ou seja, "em processo de recrutamento") até que todas as rodadas de entrevista sejam concluídas. No entanto, os registros de cada entrevistador individual são inseridos no
job_post_activity_logmesa, e eles têm a ação 'entrevistado'. - Uma inscrição pode ser visualizada por mais de um recrutador na mesma empresa. Ao usar esses dois atributos, você não perderá as informações de um candidato.
- Fazer uma oferta a um candidato selecionado está sujeito a várias aprovações (ou seja, aprovação da equipe financeira, aprovação do gerente do departamento de contratação e assim por diante). Nesse caso, o status de um pedido de emprego permanece como 'oferta em análise', mas o banco de dados pode registrar quais aprovações foram recebidas e quais não foram por meio do
job_post_activity_logtabela.
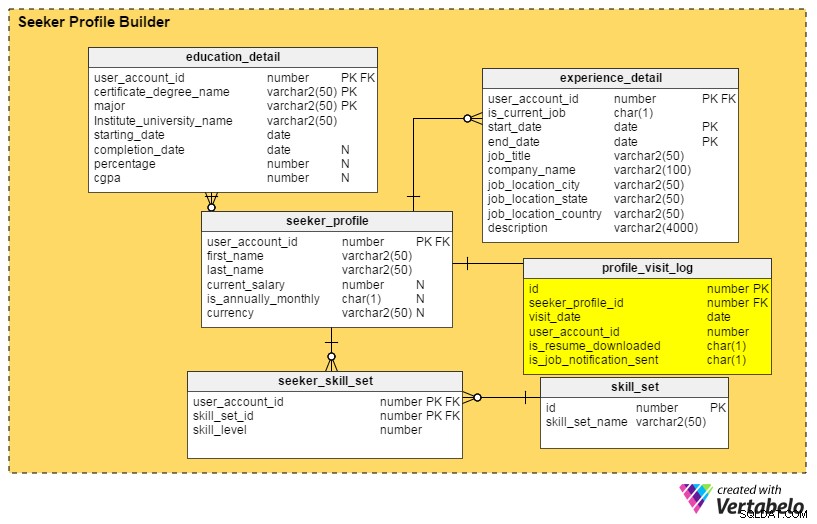
Melhoria nº 2:um painel de perfil
Perguntas a serem respondidas: Quem encontrou meu perfil recentemente? Quantas vezes foi visto pelos recrutadores no último mês, semana ou dia? Os recrutadores das principais empresas analisaram meu perfil?
As respostas para todas essas perguntas estão no
profile_visit_log tabela. Essa tabela captura todos os dados de visitas ao perfil, incluindo quem visitou um perfil, quando foi visualizado e assim por diante. As colunas desta tabela são:id– A chave primária da tabela.seeker_profile_id– Qual perfil foi visitado.visit_date– Quando o perfil foi acessado.user_account_id– Quem viu o perfil.is_resume_downloaded– Uma coluna de sinalização que indica se o currículo relacionado foi baixado durante a visita. Esta coluna nos ajudará a determinar quantas vezes um currículo é baixado pelos recrutadores.is_job_notification_sent– Outra coluna de sinalização, esta informando se uma notificação de trabalho foi enviada ao proprietário do perfil.
Melhoria nº 3:gerenciamento de serviços pagos
Pergunta a ser respondida: Como os portais on-line podem aproveitar serviços adicionais pagos?
Além de uma plataforma para publicação e busca de empregos, muitos portais online oferecem outros serviços, como criação de currículos especializados, consultoria de carreira, etc. Eles também oferecem produtos para ajudar os candidatos a encontrar o emprego dos sonhos na cidade dos sonhos. Por exemplo, um dos principais sites de emprego oferece um produto que mantém seu perfil no topo das listas de recrutadores para que você possa obter mais ofertas de entrevistas. A maioria desses produtos ou serviços está disponível por assinatura. Quando um usuário compra um serviço ou produto, ele paga durante um período de tempo específico (ou seja, um mês, três meses, um ano) pelo uso desse produto ou serviço.
Ao olhar para esses portais de empregos, notei que quase nenhum produto ou serviço é oferecido isoladamente. Na maioria das vezes, vários produtos e serviços são agrupados em um pacote, e esse pacote é oferecido a candidatos a emprego ou recrutadores.
Levando em conta todos esses pontos, criei o seguinte modelo de dados para incorporar serviços e produtos pagos em nosso site de empregos online existente:
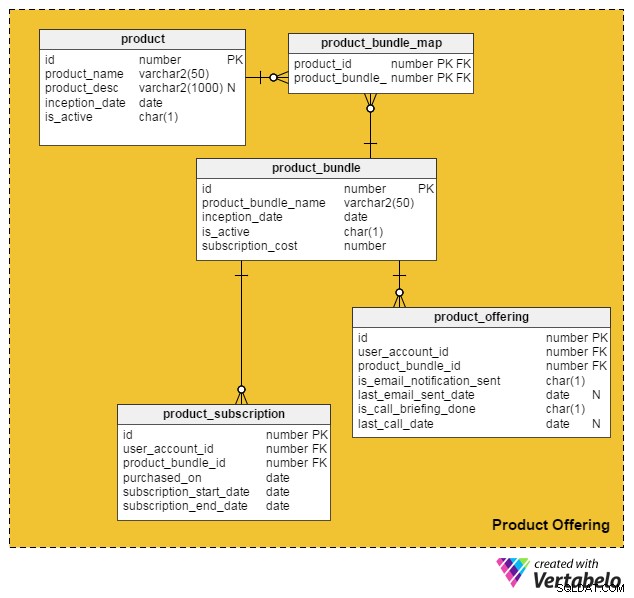
O product tabela contém detalhes sobre produtos individuais. (Vamos nos referir a produtos e serviços como “produtos”). As colunas desta tabela são:
id– A chave primária desta tabela, que dá um ID único para cada produto oferecido em nosso portal.product_name– Contém o nome do produto.product_desc– Armazena uma breve descrição do produto.inception_date– A data em que um produto foi lançado.is_active– Se um produto está ativo ou não.
Como produtos e serviços podem ser agrupados em um pacote e oferecidos aos clientes, criei o
product_bundle tabela para armazenar registros de todos esses pacotes. Os atributos são:id– A chave primária da tabela, que fornece um ID exclusivo para cada pacote de produtos.product_bundle_name– Armazena o nome do pacote.inception_date– A data em que o pacote foi lançado.is_active– Indica se um pacote está ativo ou não.subscription_cost– Armazena o preço solicitado pelo pacote.
Um único produto pode ser oferecido aos clientes?
Sim. Nesse modelo de dados, um único produto pode ser seu próprio “pacote”. As tabelas a seguir tratam desta e de algumas outras funcionalidades importantes.
O
product_bundle_map table armazena uma lista de todos os produtos que fazem parte de um pacote. Seus atributos são autoexplicativos. A próxima tabela,
product_subscription , entra em ação quando os clientes assinam pacotes de produtos. Ele registra os detalhes de quais clientes se inscreveram em quais pacotes. As colunas desta tabela são:id– A chave primária da tabela.user_account_id– O usuário que comprou o pacote.product_bundle_id– O pacote de produtos comprado pelo usuário.purchased_on– A data da compra.subscription_start_date– A data em que a assinatura começa. Observe que a data de compra do produto e a data de início da assinatura podem ser diferentes. Assim, temos duas colunas diferentes para eles.subscription_end_date– Quando a assinatura terminará.
A tabela final,
product_offering , é usado principalmente para marketing. Normalmente, os portais de emprego analisam as atividades recentes dos usuários (tanto candidatos a emprego quanto recrutadores) e decidem quais produtos serão benéficos para quais usuários. Em seguida, eles usam e-mails ou telefonemas para entrar em contato com os clientes com ofertas selecionadas. As colunas desta tabela são:id– A chave primária da tabela.user_account_id– O usuário a quem o portal de empregos está direcionado.product_bundle_id– O pacote de produtos que os profissionais de marketing do portal combinaram com o usuário.is_email_notification_sent– Se um e-mail sobre a oferta do produto foi enviado.last_email_sent_date– Quando o usuário recebeu pela última vez um e-mail de produto da equipe de marketing. É comum que os profissionais de marketing enviem várias notificações a um usuário e enviem outras notificações periodicamente. Esta coluna armazena a data em que a última notificação foi enviada.is_call_briefing_done– Se o cliente recebeu um telefonema informando sobre um produto.last_call_date–A data da última chamada telefônica. Pode haver várias chamadas (chamadas de acompanhamento) feitas para os clientes.
Melhoria nº 4:gerenciamento do formulário de pré-inscrição
Pergunta a ser respondida: Como um recrutador pode obter um formulário de consentimento personalizado preenchido por todos os possíveis candidatos a emprego?
Muitas vezes, os candidatos a emprego respondem a perguntas específicas quando se candidatam a um cargo. Isso geralmente inclui coisas como o consentimento para uma verificação de antecedentes criminais. No entanto, existem vários outros tipos de consentimentos que podem ser necessários. Por exemplo, um emprego em marketing pode exigir muitas viagens; empregos na terceirização de processos de negócios (BPO) podem exigir que os funcionários trabalhem em turnos noturnos (ou seja, tarde da noite). Estes são abordados em formulários de pré-candidatura.
É sempre melhor obter o consentimento quando o pedido de emprego é enviado. Dessa forma, os candidatos que não estiverem dispostos a atender a esses requisitos não se candidatarão ao trabalho.
Antes de pular para o modelo de dados, deixe-me destacar alguns fatos básicos sobre formulários de consentimento:
- Uma vaga de emprego pode ter mais de um formulário de consentimento.
- Cada formulário de consentimento tem várias perguntas associadas a várias seções.
- Uma pergunta pode ser definida como obrigatória ou opcional, dependendo de como a pergunta é marcada no formulário. Uma pergunta pode ser opcional em um formulário e obrigatória em outro.
- Cada pergunta pode ser respondida como (1) sim, (2) não ou (3) não aplicável.
- Todas as respostas serão gravadas.
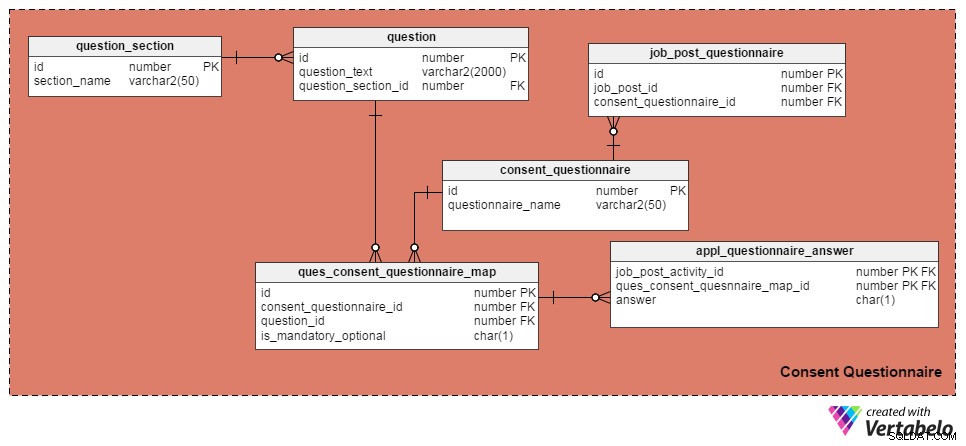
Usei as quatro tabelas a seguir para gerenciar perguntas e formulários de consentimento. A primeira, a question mesa, contém uma lista de perguntas. Ele tem esses atributos:
id– A chave primária da tabela, que fornece um número de identificação exclusivo para cada pergunta.question_text– Armazena o texto da pergunta real.question_section_id– A seção onde a pergunta aparece. (Por exemplo, "Você trabalhou no desenvolvimento de software por pelo menos cinco anos?" aparecerá na seção "Experiência de trabalho".) Esta é uma coluna de chave estrangeira que é referenciada naquestion_sectiontabela.
A
question_section tabela armazena informações da seção. É uma forma de agrupar questões relacionadas ao mesmo tema. Além do id atributo, que é a chave primária da tabela, o único atributo é section_name , Que é auto-explicativo. O
consent_questionnaire table contém nomes de formulários de consentimento. Seus dois atributos também são autoexplicativos. O
ques_consent_questionnaire_map tabela é o núcleo desta área de assunto. Todas as outras tabelas desta área temática estão direta ou indiretamente ligadas a ela. Seu objetivo é manter uma lista de perguntas marcadas nos formulários de consentimento. As colunas desta tabela são:id– A chave primária desta tabela.consent_questionnaire_id– O número de identificação do formulário de consentimento.question_id– O número de identificação da pergunta.is_mandatory_optional– Significa se a pergunta é obrigatória ou opcional para um determinado formulário de consentimento. Uma pergunta pode fazer parte de vários formulários de consentimento, mas pode ser obrigatória em alguns e opcional em outros. Essa é a única razão por trás de manter esta coluna aqui em vez de tê-la naquestiontabela.
Nas próximas tabelas, discutiremos formulários de consentimento de marcação para postagens de emprego individuais e registraremos as respostas dos candidatos. Vamos começar com o
job_post_questionnaire tabela, que armazena informações sobre quais formulários de consentimento fazem parte de um anúncio de emprego. Pode haver um ou mais formulários de consentimento marcados com um anúncio de emprego. As colunas desta tabela são:id– A chave primária da tabela.job_post_id– Indica em qual postagem de trabalho o formulário de consentimento está marcado.consent_questionnaire_id– O formulário de consentimento marcado para uma publicação de emprego.
Em seguida, o
appl_questionnaire_answer A tabela registra as respostas individuais de cada pergunta do formulário de consentimento, conforme preenchidas pelos candidatos. As colunas desta tabela são:job_post_activity_id– Uma coluna de chave estrangeira referenciada nojob_post_activitytabela. Ele armazena informações sobre o candidato que respondeu à pergunta.quest_consent_quesnnaire_map_id– Outra coluna de chave estrangeira referida noquest_consent_questionnaire_maptabela. Ele armazena qual pergunta de qual formulário de consentimento está sendo respondido.answer– A resposta real do candidato a emprego. Eu a mantive como uma coluna CHAR(1) porque todas as perguntas em nosso modelo podem ser respondidas como 'Sim' (resposta ='S'), 'Não' (resposta ='N') ou 'Não aplicável' (resposta ='X').
O novo e aprimorado modelo de dados do portal de empregos on-line
Você pode ver o modelo de dados concluído abaixo.
O que você adicionaria?
Você consegue pensar em outros recursos para adicionar ao nosso portal de empregos online? Por favor, compartilhe suas opiniões na seção de comentários.



