Na Parte 1 desta série, importamos com sucesso a estrutura do banco de dados SuiteCRM para nossa ferramenta de modelagem de banco de dados online. Foi quando vimos que o modelo contém 201 tabelas sem relacionamentos entre elas. Temos um monte de mesas que pareciam realmente bagunçadas. Neste artigo, mostrarei como você pode organizar um modelo tão grande.
Logo após importar para o Vertabelo, o modelo de banco de dados do SuiteCRM tem a seguinte aparência:
O modelo funciona – mas não de forma eficiente. Precisaremos modificá-lo para torná-lo realmente útil. Como queremos analisar o banco de dados SuiteCRM depois ações são executadas em sua GUI, precisamos entender as definições de tabela e os relacionamentos entre as tabelas. Vamos começar agrupando as tabelas em áreas de assunto e estabelecendo os relacionamentos mais importantes.
A Vertabelo oferece três ferramentas principais para ajudá-lo a organizar diagramas grandes:
- Áreas de assunto
- Tabelas e atalhos de visualização
- Atalhos de referência
Vou descrevê-los mais adiante neste artigo, mas você também pode saber mais assistindo a este vídeo.
Etapa 1. Desative a geração automática de chaves estrangeiras
Em primeiro lugar, desabilitaremos a geração automática de chaves estrangeiras. Por padrão, o Vertabelo gera atributos de chave estrangeira quando extraímos relações de uma tabela primária para uma tabela referenciada. Isso geralmente é uma coisa boa, mas não aqui. Já temos atributos que representam chaves estrangeiras. O que nos falta são relacionamentos “reais” entre tabelas. Para desativar essa opção, clique em "Minha conta" no menu superior e encontre as "Preferências pessoais" seção.
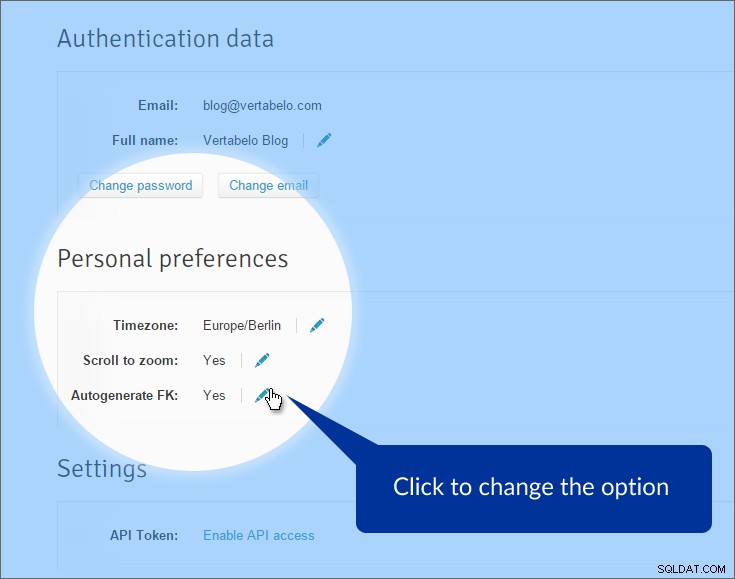
A opção está desativada. Agora, quando desenhamos uma linha de referência entre as tabelas, a linha é criada – mas teremos que especificar quais atributos são usados, tanto no lado primário quanto no externo.
Etapa 2. Agrupar Tabelas Prefixadas com Áreas de Assunto
Em seguida, vamos agrupar algumas tabelas. Faremos isso usando a área de assunto ferramenta que permite associar tabelas com base em critérios selecionados. No nosso caso, estamos tentando identificar tabelas relacionadas ou parte do mesmo processo. Isso resultará em grupos como "Chamadas", "Reunião" e "Campanhas".
Podemos criar uma área de assunto clicando em "Adicionar nova área" ícone na caixa de ferramentas:
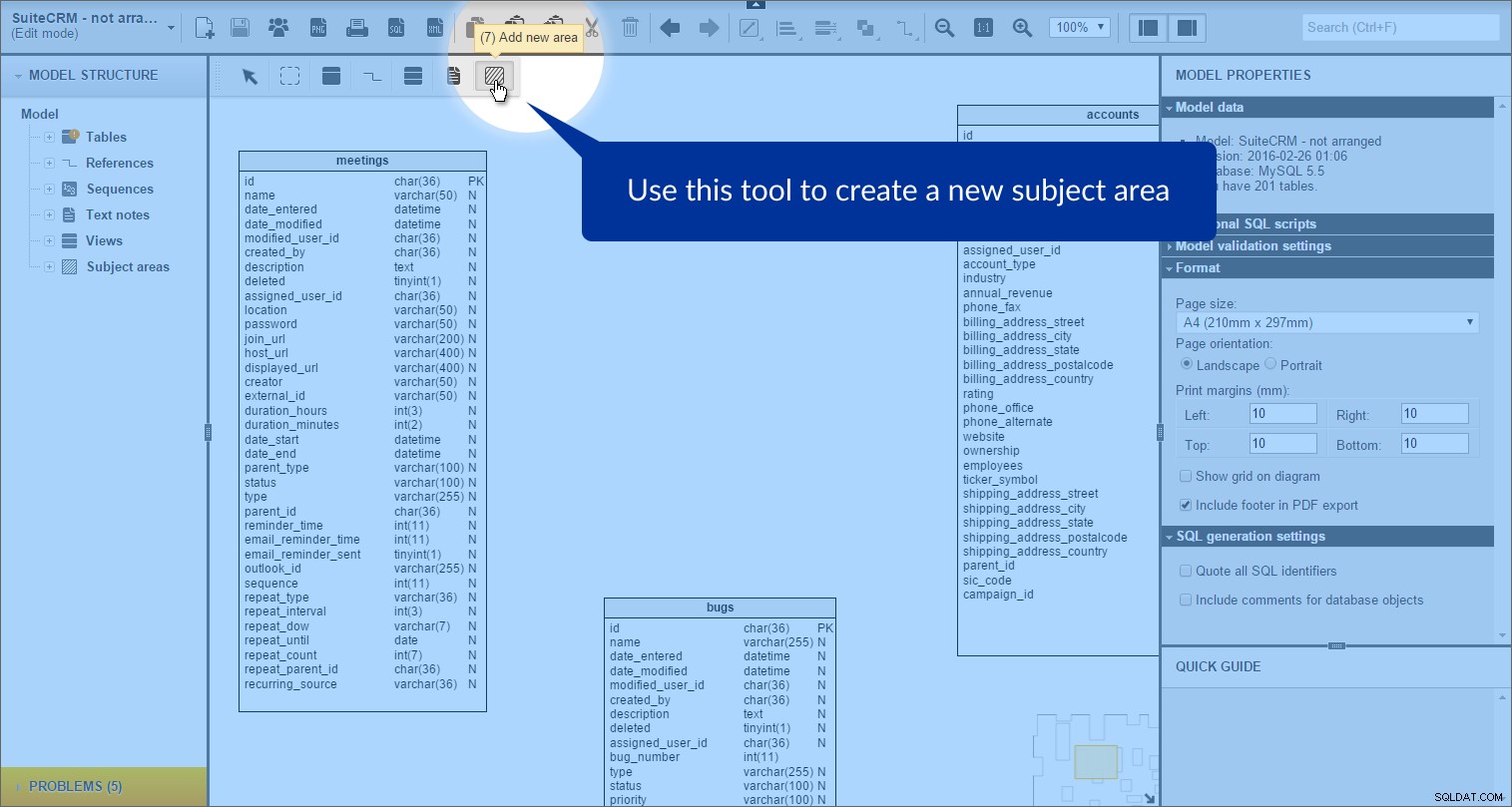
e, em seguida, desenhando um retângulo em nosso modelo:
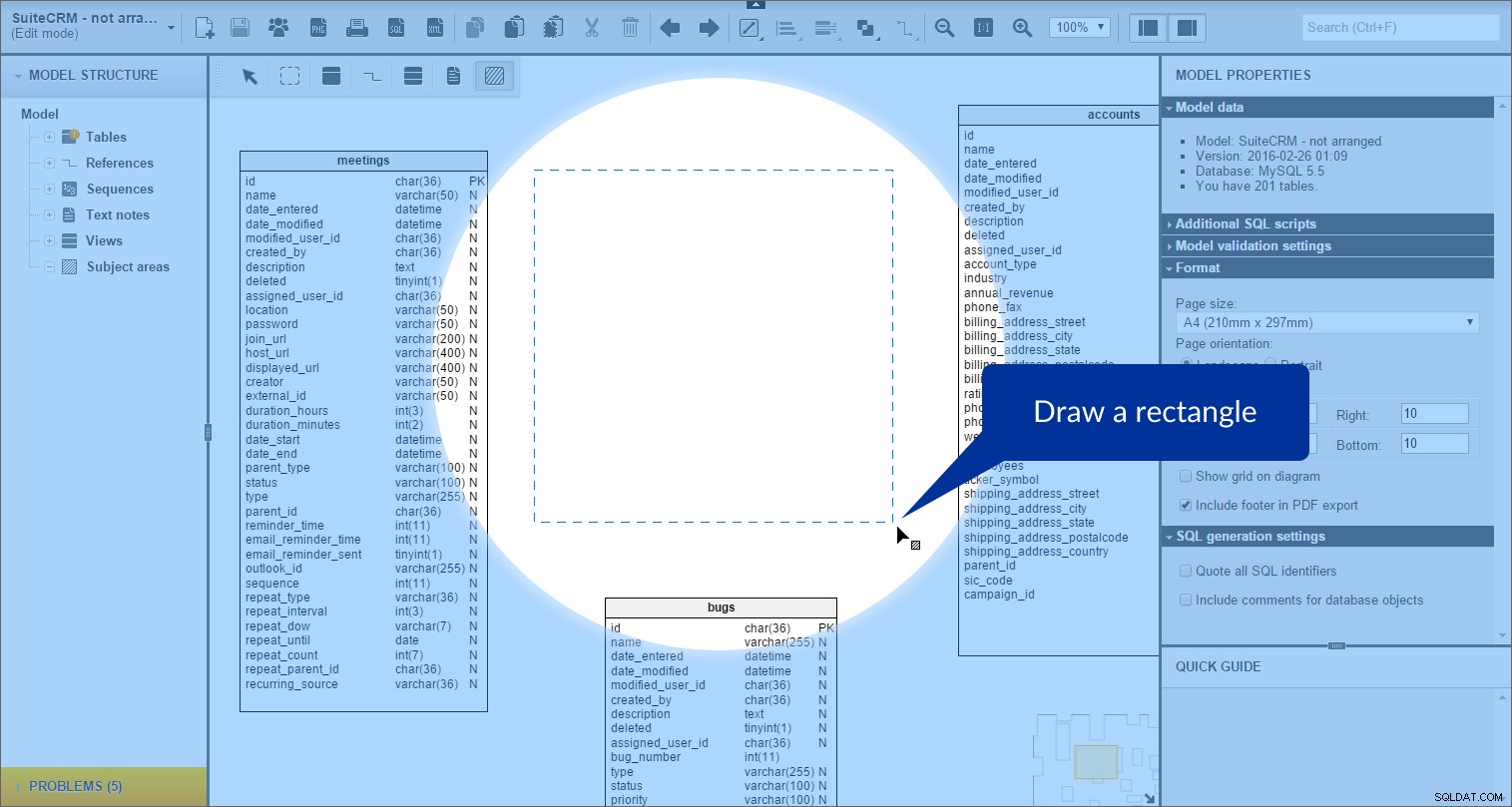
A área de assunto é criada. Podemos vê-lo na “Estrutura do modelo” painel à esquerda:
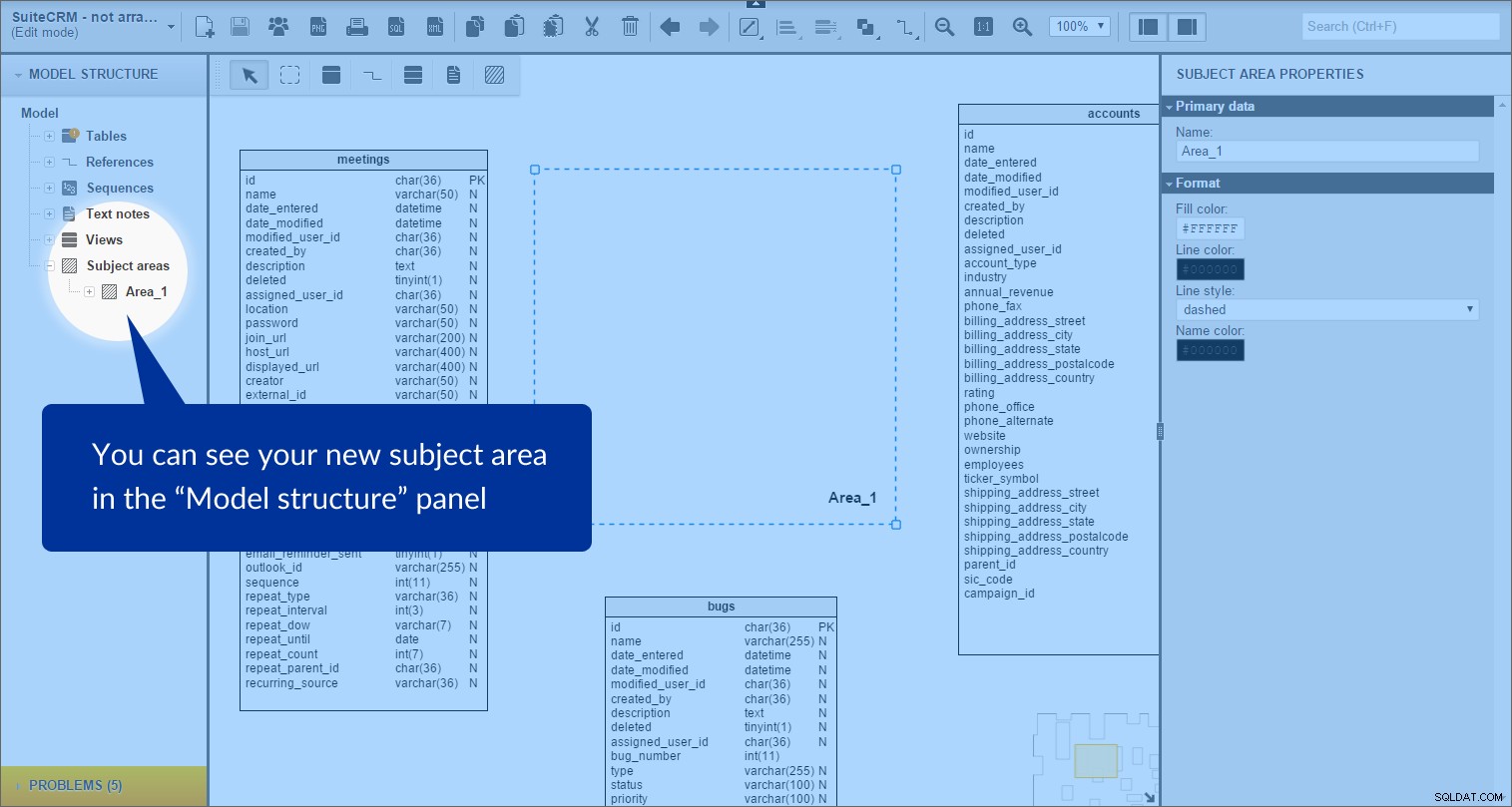
Cada área de assunto contém uma lista de todos os objetos que estão dentro de suas bordas; neste caso, são tabelas e tipos de referência.
No SuiteCRM, existem muitas tabelas que compartilham um prefixo comum. Então, comecei a agrupar as tabelas prefixadas. Dê uma olhada nas tabelas “acl” como exemplo. No painel “Model structure”, encontrei todas as tabelas cujos nomes começam com “acl_“:
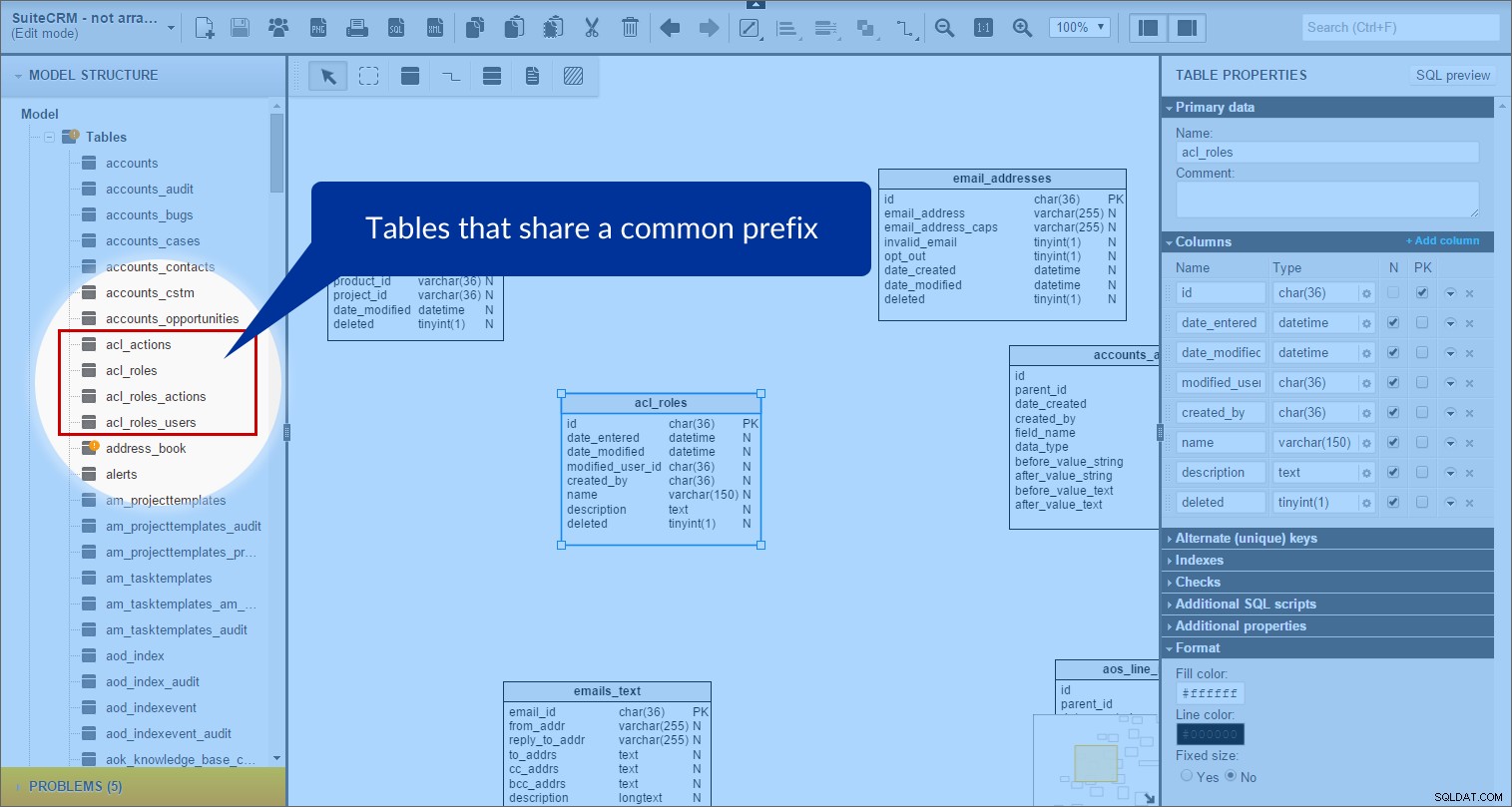
Em seguida, criei a área de assunto “acl” no modelo e arrastei todas as tabelas apropriadas para ela. (Para melhor visibilidade, defino a cor de fundo para roxo.)
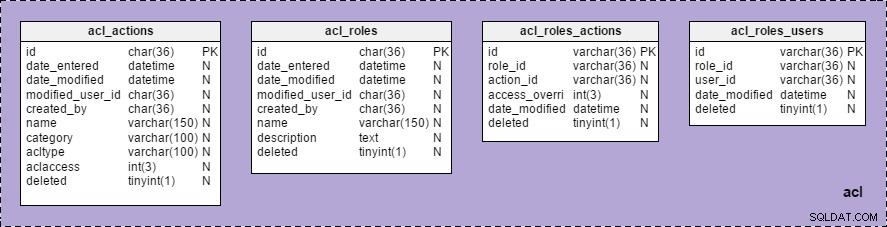
Agora, podemos ver o grupo “acl”, com uma lista de todas as tabelas pertencentes a ele, em “Áreas de assunto” na “Estrutura do modelo” :
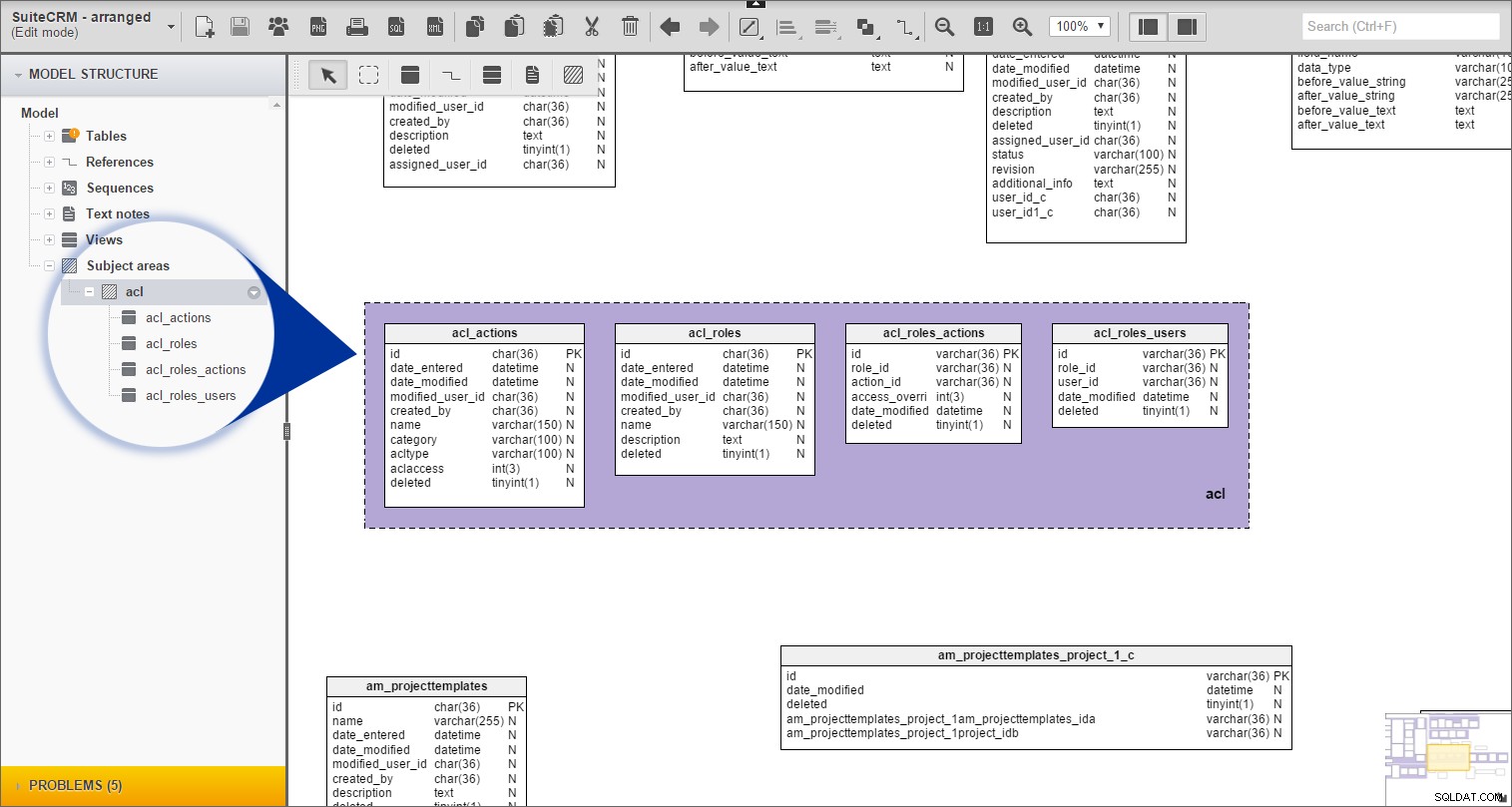
Repeti o mesmo procedimento para todas as tabelas prefixadas restantes.
Etapa 3:organize as tabelas restantes.
Mesma Tabela Duas Vezes no Diagrama? Atalhos de tabela!
Existem cerca de 80 tabelas prefixadas. Depois de agrupá-los, fiquei com cerca de 120 mesas 'selvagens'. Eles são significativos:eles armazenam informações sobre usuários, clientes, chamadas, reuniões e outras coisas do CRM. Isso é muita informação para permanecer em geral, então vamos organizar essas tabelas.
O recurso que achei mais útil para organizar essas tabelas é chamado de atalhos de tabela . Às vezes, você deseja usar a mesma tabela mais de uma vez em um modelo. (Por quê? Para achatar o modelo e evitar sobreposições.) Podemos fazer isso facilmente usando o “Copiar” e “Colar como atalho” botões.
Basta selecionar a tabela para a qual deseja criar um atalho e clicar em "Copiar" na barra de ferramentas superior (ou pressione Ctrl + C ):
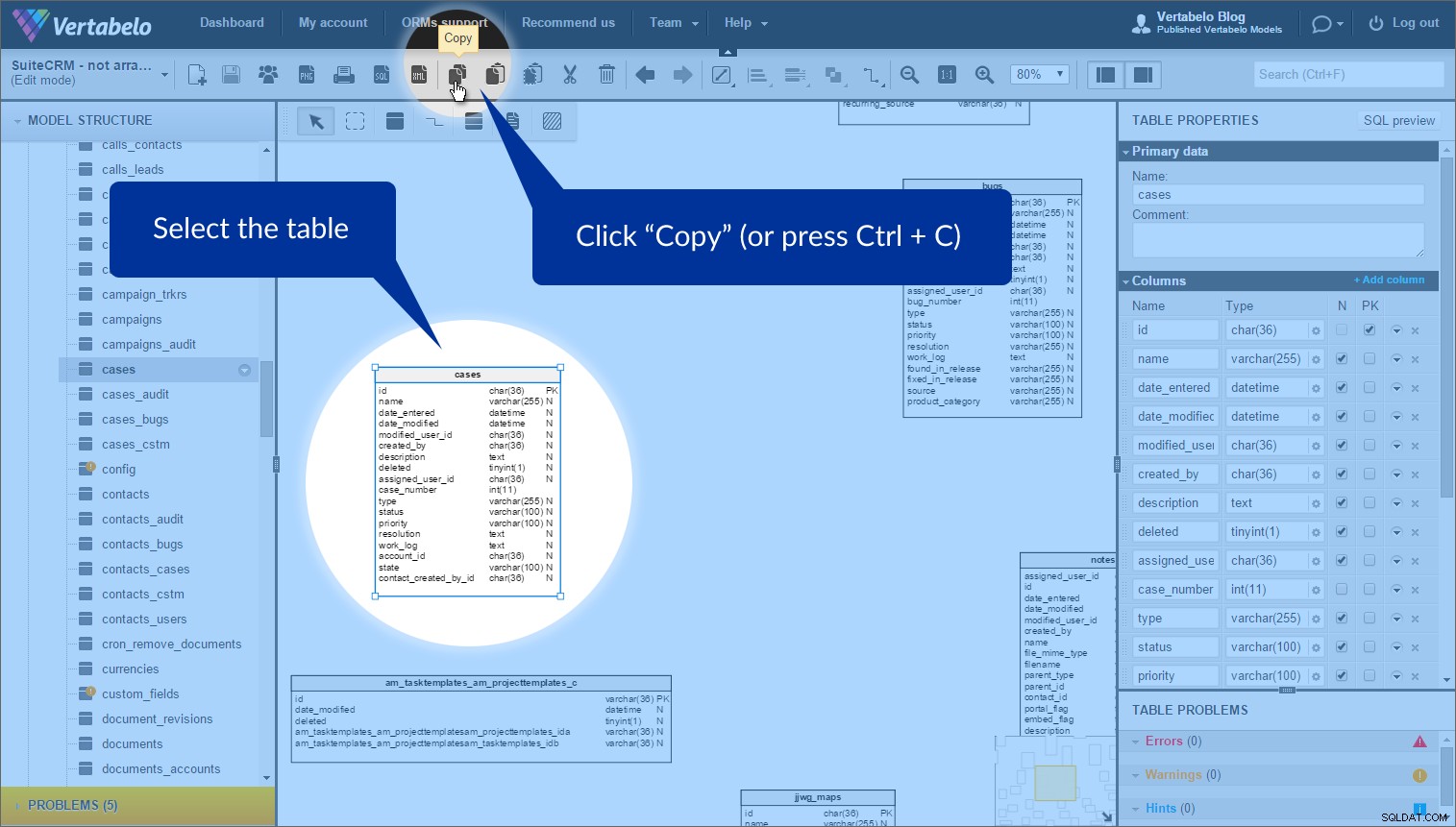
Para criar um atalho, clique em "Colar como atalho" (ou pressione Ctrl + K ). Depois disso, uma nova tabela com um contorno pontilhado aparecerá:
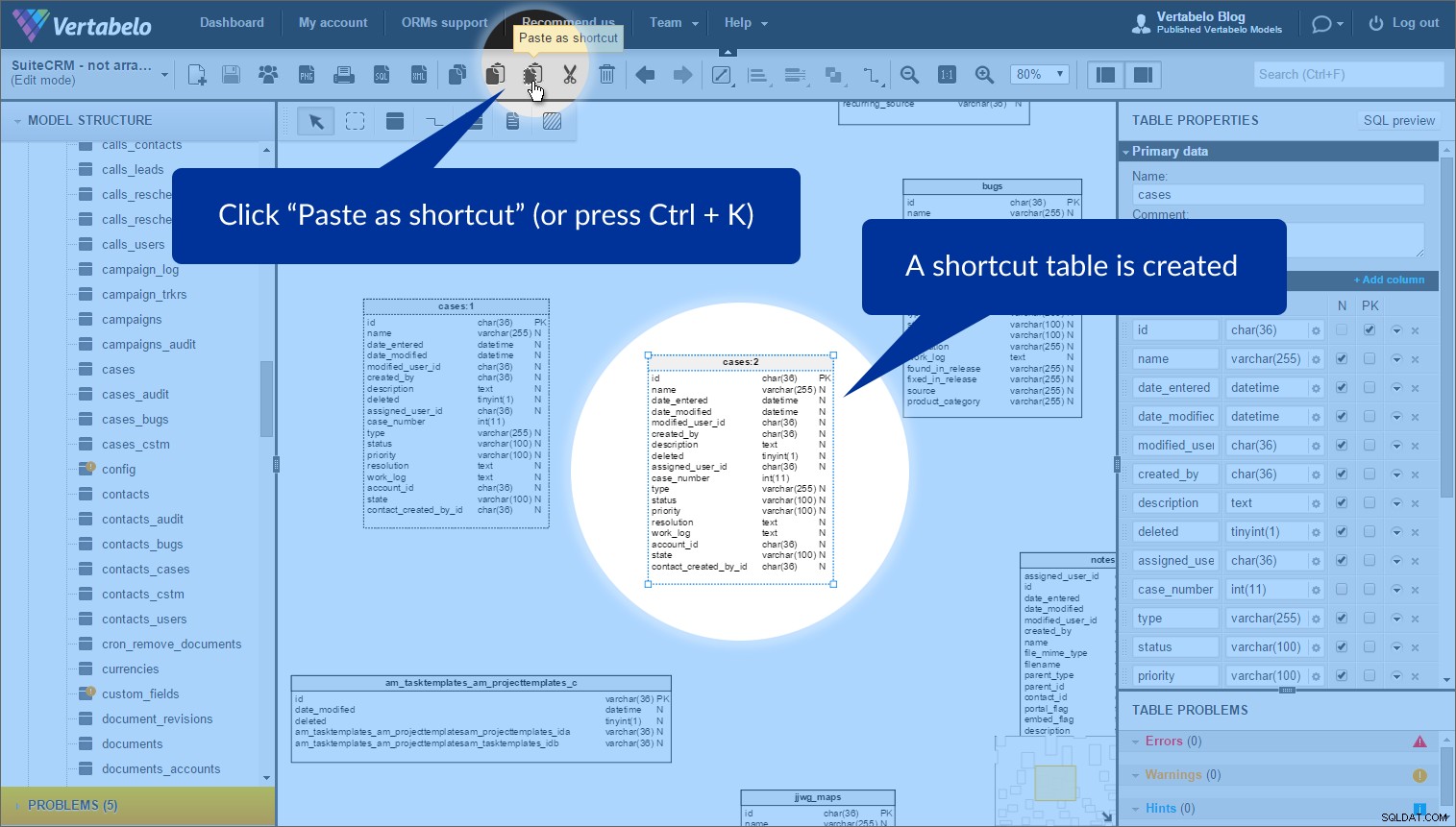
Isso não uma cópia da tabela, mas outra instância da tabela original. Podemos colocá-lo em qualquer lugar em nosso modelo. Usei instâncias da mesma tabela em diferentes áreas de assunto para evitar sobreposição de referências. Vale a pena mencionar que cada instância de tabela tem um nome de área de assunto atribuído (ao lado de seu nome) enquanto está dentro dessa área de assunto.
Um bom exemplo de como isso funciona são os users tabela. Ele pode ser encontrado em “Usuário e Contas”, “Funções”, “Documentos” e outras áreas temáticas. Veremos isso mais adiante no modelo.
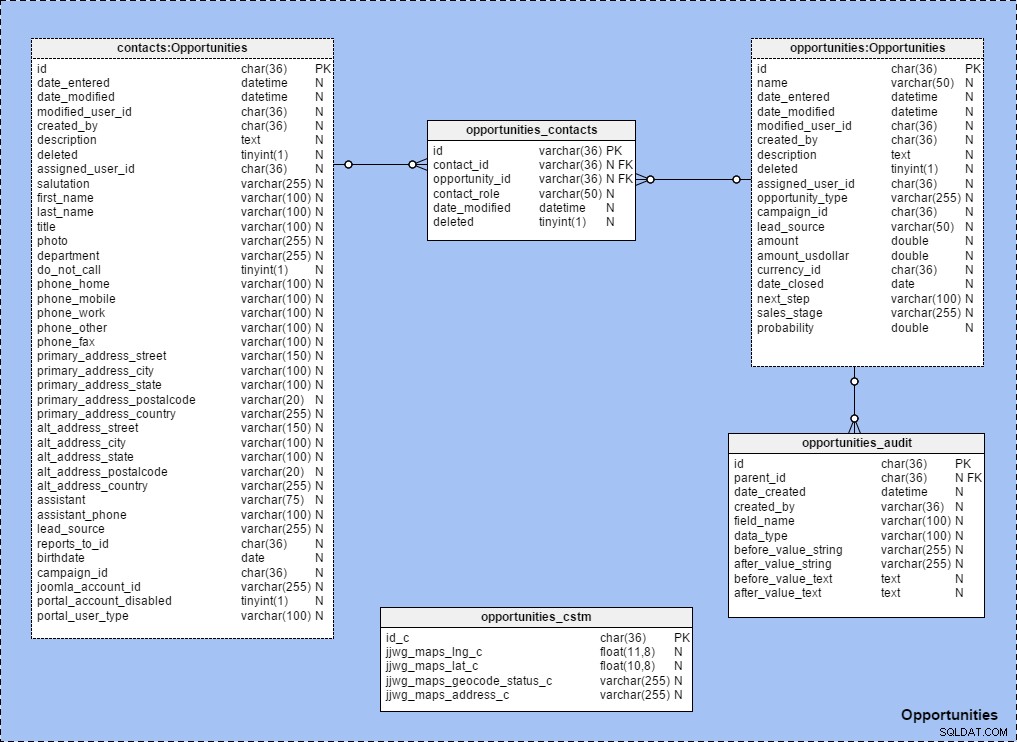
Eu uso atalhos de tabela extensivamente ao criar áreas de assunto com relacionamentos estabelecidos entre tabelas. Para ver como isso funciona, veja a área de assunto “Oportunidades” mapeada abaixo. Observe que todas as tabelas dentro dessa área de assunto são nomeadas seguindo esta regra:{table name} :{subject area name} .
Quando expandimos o {subject area name} no painel “Estrutura do modelo”, podemos ver claramente que ele contém tabelas e referências:
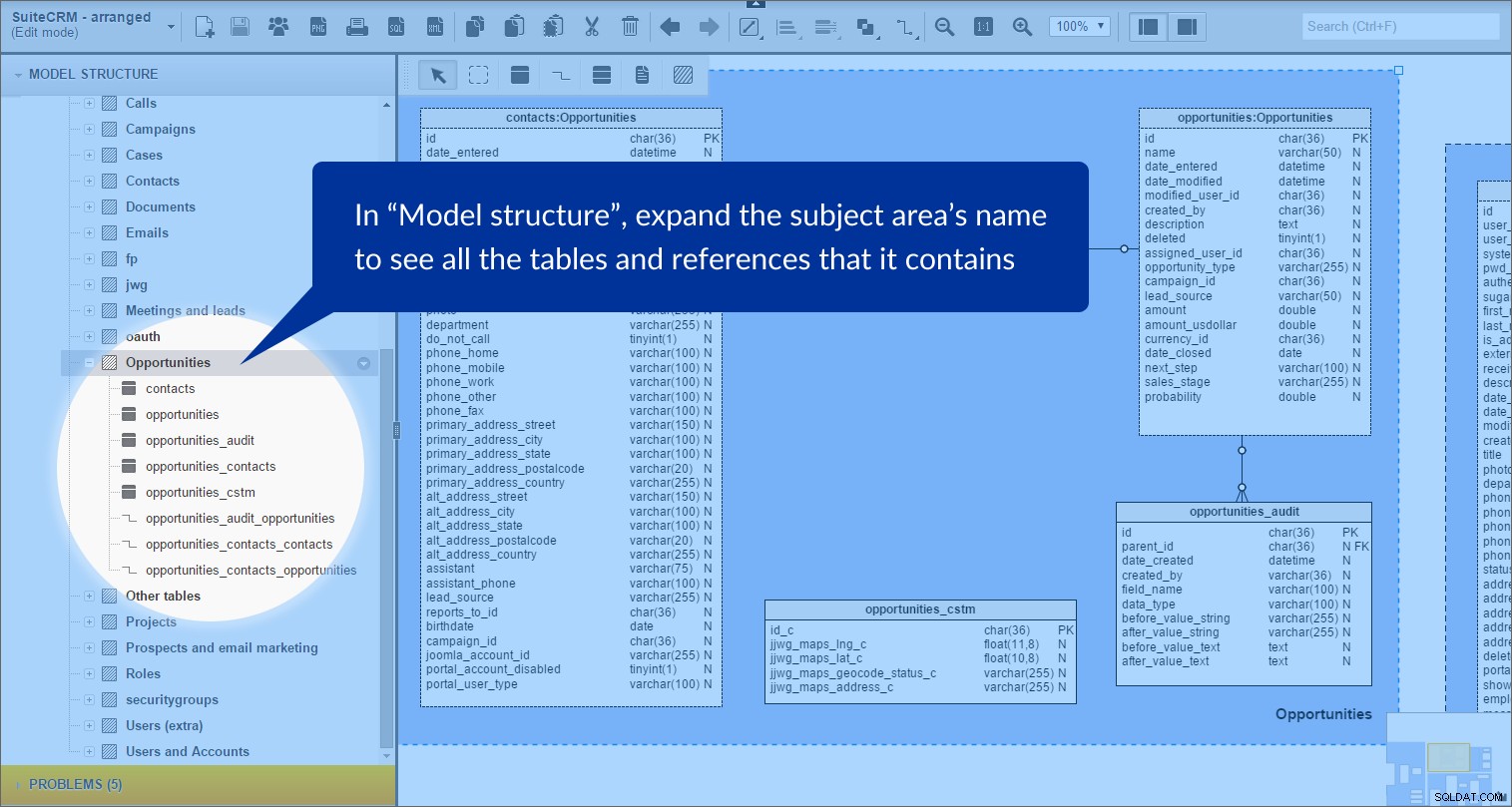
Fiz isso para as seguintes áreas de assunto:“Chamadas”, “Casos”, “Campanha”, “Contatos”, “Documentos”, “Reunião e leads”, “oauth”, “Projetos”, “Prospects e e-mail marketing”, “Funções” e “Usuários e contas”. Todas essas áreas compartilham um fundo azul claro.
As demais tabelas são agrupadas com base em seu nome e significado presumido:“E-mails”, “Usuários (extra)” e “Outras tabelas”. Esses grupos têm sua cor de fundo definida como vermelho claro.
Quando você clica duas vezes no nome de uma tabela na árvore de navegação, a visualização amplia essa tabela no modelo e a seleciona. Quando você aumenta o zoom rolando a roda do mouse, a visualização será ampliada na direção do ponteiro do mouse.
O modelo organizado
Usei as opções descritas anteriormente para nivelar o modelo o máximo possível enquanto agrupava as tabelas logicamente. O resultado são 26 áreas temáticas, algumas das quais contêm apenas tabelas, enquanto outras possuem tabelas e relações. Vamos fazer uma rápida revisão de cada categoria:
Áreas de assunto que contêm tabelas e relações:
“Chamadas”, “Campanhas”, “Casos”, “Contatos”, “Documentos”, “Reuniões e leads”, “Oportunidades”, “Projetos”, “Perspectivas e e-mail marketing”, “Funções”, “Usuários e contas”
Todas as relações são definidas como não obrigatórias. Isso mantém as informações de que essas tabelas estão relacionadas e por meio de qual(is) atributo(s).
Áreas de assunto que contêm apenas tabelas:
“acl”, “am”, “aod”, “aok”, “aop”, “aor”, “aos”, “aow”, “Emails”, “fp”, “jwg”, “oauth”, “security_groups” ”, “Usuários extras”
Isso não significa que aqui não existam relações; eles simplesmente não estão sendo enfatizados.
A área de assunto “Outras tabelas” é para tabelas que realmente não se encaixam em um grupo específico.
Como é o modelo?
O modelo reorganizado fica assim:
Obviamente, uma convenção de nomenclatura foi usada. Aqui está uma visão geral das diretrizes que seguimos:
- Os nomes das tabelas são principalmente no plural:
users,contracts,folders,roles,tasks. Alguns nomes de tabelas são singulares, comoproject. - A chave primária na maioria das tabelas é chamada simplesmente de
ide é um tipo char(36). - Quando ocorre uma relação um-para-muitos, a chave estrangeira geralmente é denominada
parent_id. (Exemplo:contacts_audit.parent_idé uma referência acontacts.id.) - Em relações muitos-para-muitos, “
parent_id” não pode ser usado como nome para várias colunas. Em vez disso, é usado um nome de tabela singular com o sufixo “_id”. (Exemplo:contacts_bugs.bug_idé referência abug.id.) - Há situações em que a mesma coluna é usada como chave estrangeira para várias tabelas. (Exemplo:
calls.parent_idé referenciado à coluna id em cada uma das seguintes tabelas:accounts,bugs,cases,contacts,leads,tasks,opportunities and prospects. Eu não verifiquei os valores no banco de dados, mas meu palpite é que não há os mesmos valores de chave nessas tabelas. Como todos são do tipo char(36), provavelmente alguma combinação de nome de tabela e incremento automático é usada. Veremos isso nos próximos artigos.) - Usamos os mesmos nomes para colunas que têm o mesmo significado em tabelas diferentes. (Exemplo:
modified_user_id,created_byeassigned_user_idpode ser encontrado em muitas tabelas no modelo. Todos eles são referenciados ausers.id.)
O que vem a seguir?
Nos próximos artigos, usaremos a GUI do SuiteCRM e ficaremos de olho nas mudanças que isso causa no banco de dados. Com essas informações, tentaremos fazer alterações no modelo, reorganizar as áreas temáticas e estabelecer conexões onde for necessário. Além disso, procuraremos outras regras específicas do SuiteCRM, como a forma como as chaves primárias são geradas.
Manipular diagramas de banco de dados grandes nunca é uma tarefa fácil. Assim como construir uma boa base para uma casa, dedicar mais tempo aos fundamentos agora trará vantagens mais tarde. Se quisermos analisar modelos como o que está por trás do SuiteCRM, analisar antes de organizar a estrutura do modelo e definir os relacionamentos das tabelas é fazê-lo no estilo Sísifo.



