Atualmente, a replicação é fornecida em um ambiente de alta disponibilidade e tolerante a falhas para praticamente qualquer tecnologia de banco de dados que você esteja usando. É um tema que temos visto uma e outra vez, mas que nunca envelhece.
Se você estiver usando o TimescaleDB, o tipo mais comum de replicação é a replicação de streaming, mas como isso funciona?
Neste blog, revisaremos alguns conceitos relacionados à replicação e focaremos na replicação de streaming para TimescaleDB, que é uma funcionalidade herdada do mecanismo PostgreSQL subjacente. Em seguida, veremos como o ClusterControl pode nos ajudar a configurá-lo.
Portanto, a replicação de streaming é baseada no envio dos registros WAL e na aplicação deles ao servidor em espera. Então, primeiro, vamos ver o que é WAL.
WAL
Write Ahead Log (WAL) é um método padrão para garantir a integridade dos dados, ele é ativado automaticamente por padrão.
Os WALs são os logs REDO no TimescaleDB. Mas, o que são os logs REDO?
Os logs REDO contêm todas as alterações que foram feitas no banco de dados e são usados para replicação, recuperação, backup online e recuperação pontual (PITR). Quaisquer alterações que não tenham sido aplicadas às páginas de dados podem ser refeitas a partir dos logs REDO.
O uso do WAL resulta em um número significativamente reduzido de gravações em disco, porque apenas o arquivo de log precisa ser liberado para o disco para garantir que uma transação seja confirmada, em vez de todos os arquivos de dados alterados pela transação.
Um registro WAL especificará, pouco a pouco, as alterações feitas nos dados. Cada registro WAL será anexado a um arquivo WAL. A posição de inserção é um Log Sequence Number (LSN) que é um deslocamento de byte nos logs, aumentando a cada novo registro.
Os WALs são armazenados no diretório pg_wal, no diretório de dados. Esses arquivos têm um tamanho padrão de 16 MB (o tamanho pode ser alterado alterando a opção de configuração --with-wal-segsize ao construir o servidor). Eles têm um nome incremental exclusivo, no seguinte formato:"00000001 00000000 00000000".
O número de arquivos WAL contidos em pg_wal dependerá do valor atribuído aos parâmetros min_wal_size e max_wal_size no arquivo de configuração postgresql.conf.
Um parâmetro que precisamos configurar ao configurar todas as nossas instalações do TimescaleDB é o wal_level. Ele determina quanta informação é gravada no WAL. O valor padrão é mínimo, que grava apenas as informações necessárias para se recuperar de uma falha ou desligamento imediato. Arquivo adiciona o registro necessário para o arquivamento do WAL; hot_standby adiciona ainda informações necessárias para executar consultas somente leitura em um servidor em espera; e, finalmente, o lógico adiciona as informações necessárias para suportar a decodificação lógica. Este parâmetro requer uma reinicialização, portanto, pode ser difícil alterá-lo nos bancos de dados de produção em execução se nos esquecermos disso.
Replicação de streaming
A replicação de streaming é baseada no método de envio de logs. Os registros WAL são movidos diretamente de um servidor de banco de dados para outro para serem aplicados. Podemos dizer que é um PITR contínuo.
Essa transferência é realizada de duas maneiras diferentes, transferindo os registros WAL um arquivo (segmento WAL) de cada vez (transporte de log baseado em arquivo) e transferindo registros WAL (um arquivo WAL é composto de registros WAL) em tempo real (record based log shipping), entre um servidor mestre e um ou vários servidores escravos, sem esperar o preenchimento do arquivo WAL.
Na prática, um processo chamado receptor WAL, executado no servidor escravo, se conectará ao servidor mestre usando uma conexão TCP/IP. No servidor mestre existe outro processo, denominado WAL remetente, e é responsável por enviar os registros WAL ao servidor escravo à medida que eles acontecem.
A replicação de streaming pode ser representada da seguinte forma:
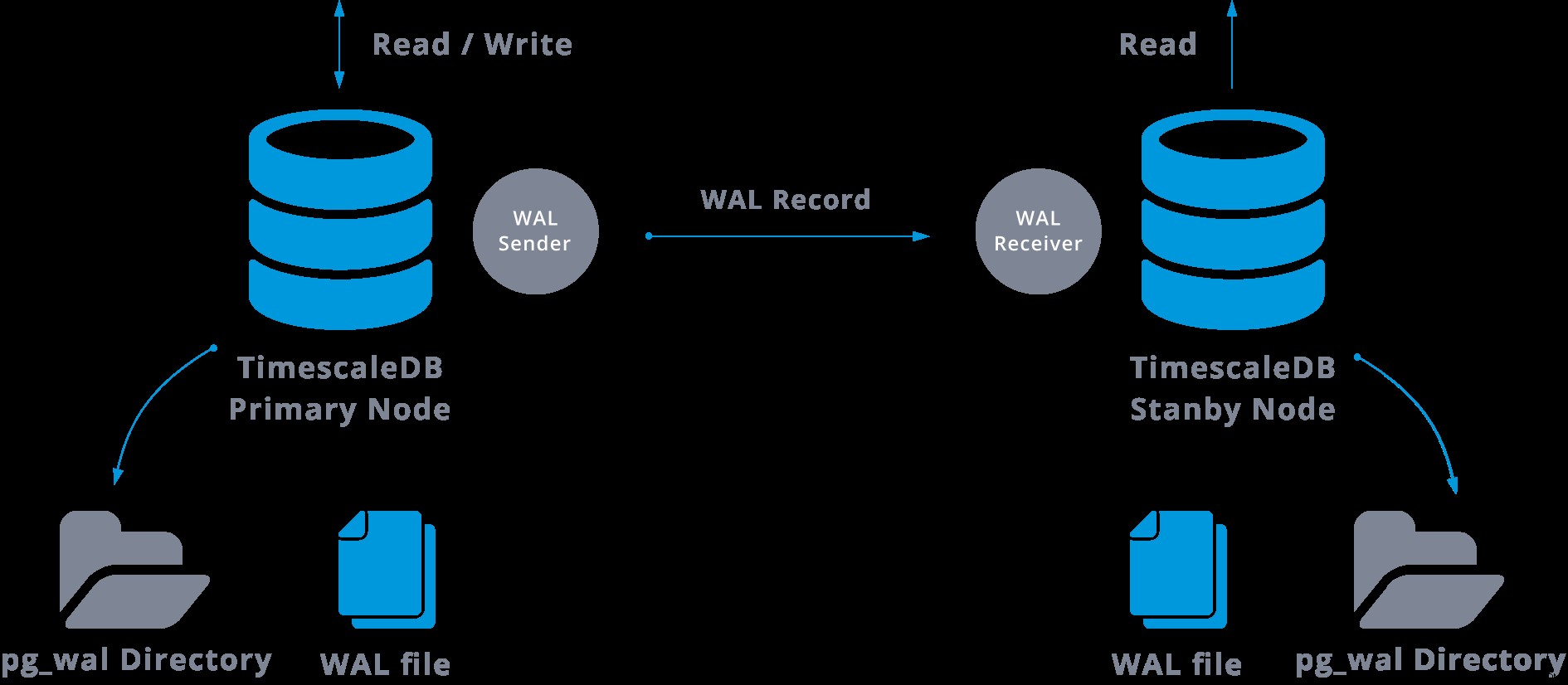
Olhando para o diagrama acima podemos pensar, o que acontece quando a comunicação entre o remetente WAL e o receptor WAL falha?
Ao configurar a replicação de streaming, temos a opção de habilitar o arquivamento WAL.
Esta etapa na verdade não é obrigatória, mas é extremamente importante para uma configuração de replicação robusta, pois é necessário evitar que o servidor principal recicle arquivos WAL antigos que ainda não foram aplicados ao escravo. Se isso ocorrer, precisaremos recriar a réplica do zero.
Ao configurar a replicação com arquivamento contínuo, partimos de um backup e, para chegar ao estado sincronizado com o mestre, precisamos aplicar todas as alterações hospedadas no WAL que ocorreram após o backup. Durante esse processo, o modo de espera restaurará primeiro todo o WAL disponível no local do arquivo (feito chamando restore_command). O restore_command falhará quando chegarmos ao último registro WAL arquivado, então, depois disso, o standby irá procurar no diretório pg_wal para ver se a mudança existe lá (isso é feito para evitar perda de dados quando os servidores master travam e alguns alterações que já foram movidas para a réplica e aplicadas ainda não foram arquivadas).
Se isso falhar e o registro solicitado não existir lá, ele começará a se comunicar com o mestre por meio da replicação de streaming.
Sempre que a replicação de streaming falhar, ela voltará à etapa 1 e restaurará os registros do arquivo novamente. Esse loop de recuperação do arquivo, pg_wal, e via replicação de streaming continua até que o servidor seja interrompido ou o failover seja acionado por um arquivo de gatilho.
Este será um diagrama de tal configuração:
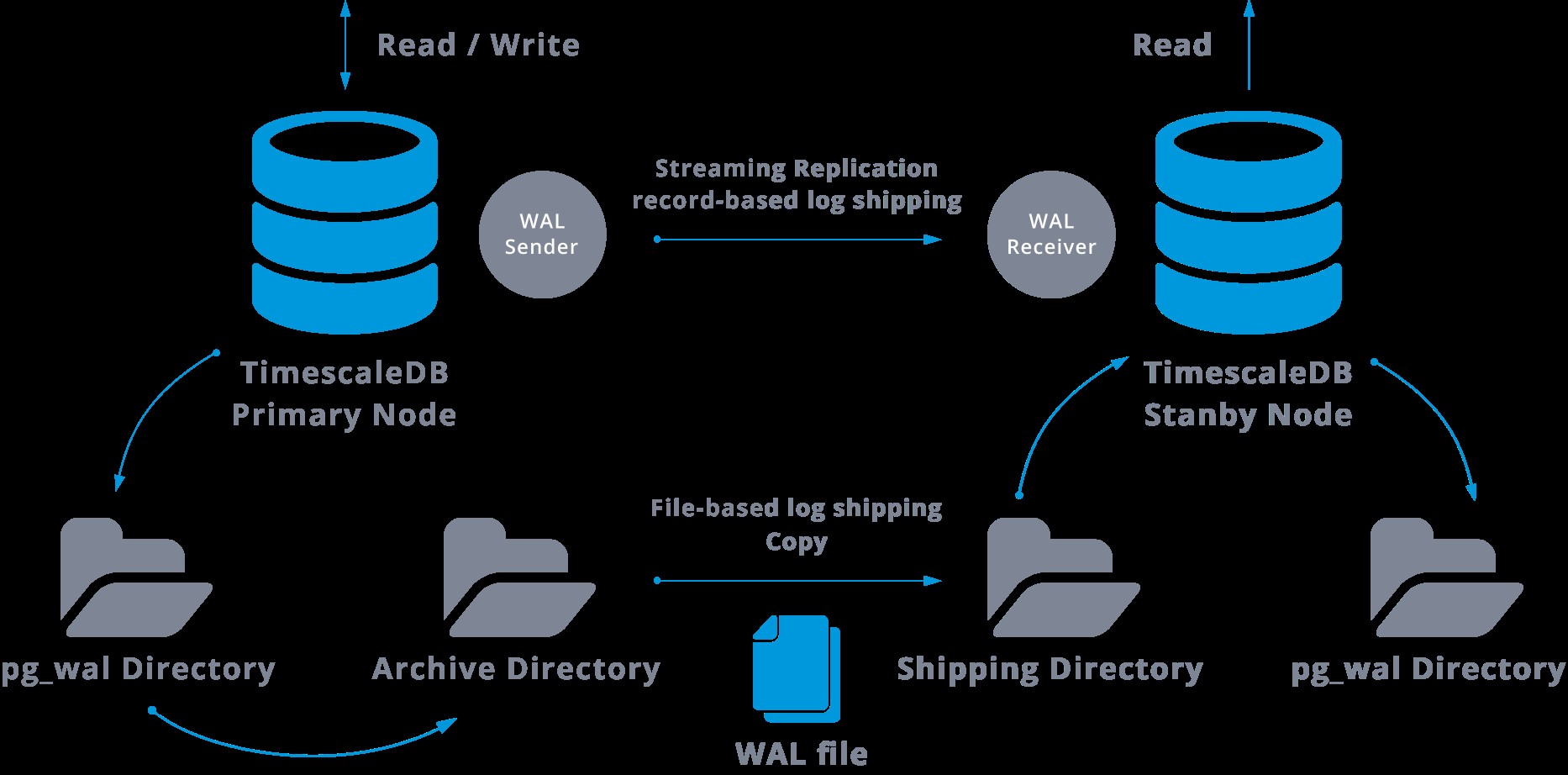
A replicação de streaming é assíncrona por padrão, então em algum momento podemos ter algumas transações que podem ser confirmadas no mestre e ainda não replicadas no servidor em espera. Isso implica em alguma perda potencial de dados.
No entanto, esse atraso entre a confirmação e o impacto das alterações na réplica deve ser muito pequeno (alguns milissegundos), supondo, é claro, que o servidor de réplica seja poderoso o suficiente para acompanhar a carga.
Para os casos em que mesmo o risco de uma pequena perda de dados não é tolerável, podemos usar o recurso de replicação síncrona.
Na replicação síncrona, cada confirmação de uma transação de gravação aguardará até que seja recebida a confirmação de que a confirmação foi gravada no log de gravação antecipada no disco do servidor primário e de espera.
Esse método minimiza a possibilidade de perda de dados, pois para isso precisaremos que o mestre e o standby falhem ao mesmo tempo.
A desvantagem óbvia dessa configuração é que o tempo de resposta para cada transação de gravação aumenta, pois precisamos esperar até que todas as partes tenham respondido. Portanto, o tempo para um commit é, no mínimo, a viagem de ida e volta entre o mestre e a réplica. As transações somente leitura não serão afetadas por isso.
Para configurar a replicação síncrona, precisamos que cada um dos servidores em espera especifique um application_name no primary_conninfo do arquivo recovery.conf:primary_conninfo ='...aplication_name=slaveX' .
Também precisamos especificar a lista dos servidores em espera que farão parte da replicação síncrona:synchronous_standby_name ='slaveX,slaveY'.
Podemos configurar um ou vários servidores síncronos, e esse parâmetro também especifica qual método (FIRST e ANY) escolher os standbys síncronos dentre os listados.
Para implantar o TimescaleDB com configurações de replicação de streaming (síncrona ou assíncrona), podemos usar o ClusterControl, como podemos ver aqui.
Depois de configurarmos nossa replicação e ela estiver funcionando, precisaremos ter alguns recursos adicionais para monitoramento e gerenciamento de backup. ClusterControl nos permite monitorar e gerenciar backups/retenção de nosso cluster TimescaleDB do mesmo local sem nenhuma ferramenta externa.
Como configurar a replicação de streaming no TimescaleDB
Configurar a replicação de streaming é uma tarefa que exige que algumas etapas sejam seguidas minuciosamente. Se você quiser configurá-lo manualmente, você pode seguir nosso blog sobre este tópico.
No entanto, você pode implantar ou importar seu TimescaleDB atual no ClusterControl e, em seguida, configurar a replicação de streaming com apenas alguns cliques. Vamos ver como podemos fazer isso.
Para esta tarefa, vamos supor que você tenha seu cluster TimescaleDB gerenciado pelo ClusterControl. Vá para ClusterControl -> Select Cluster -> Cluster Actions -> Add Replication Slave.
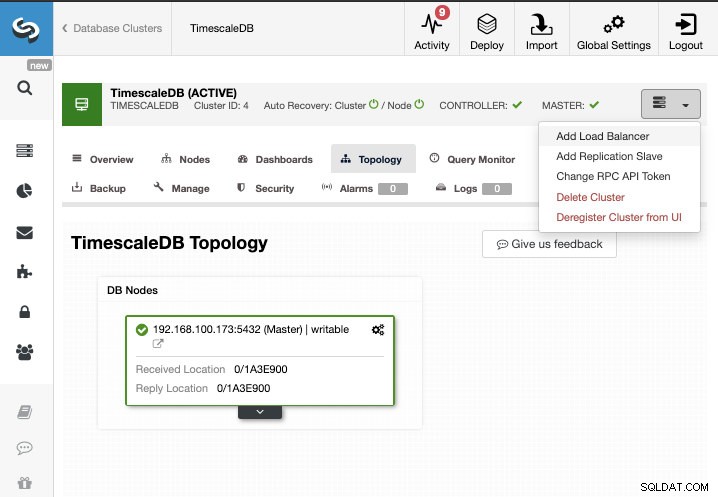
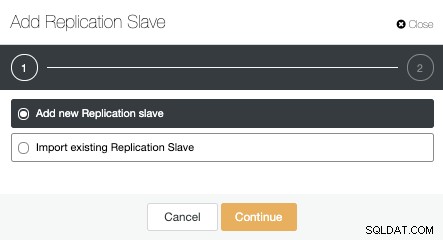
Podemos criar um novo slave de replicação (standby) ou podemos importar um existente. Neste caso, vamos criar um novo.
Agora, devemos selecionar o nó Master, adicionar o endereço IP ou nome do host para o novo servidor em espera e a porta do banco de dados. Também podemos especificar se queremos que o ClusterControl instale o software e se queremos configurar a replicação de streaming síncrona ou assíncrona.
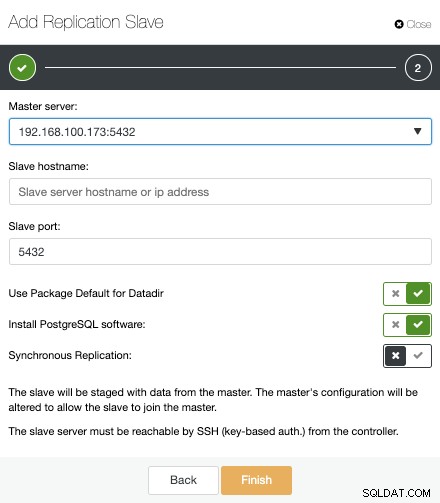
Isso é tudo. Só precisamos esperar até que o ClusterControl termine o trabalho. Podemos monitorar o status na seção Atividade.
Após a conclusão do trabalho, devemos ter a replicação de streaming configurada e podemos verificar a nova topologia na seção ClusterControl Topology View.
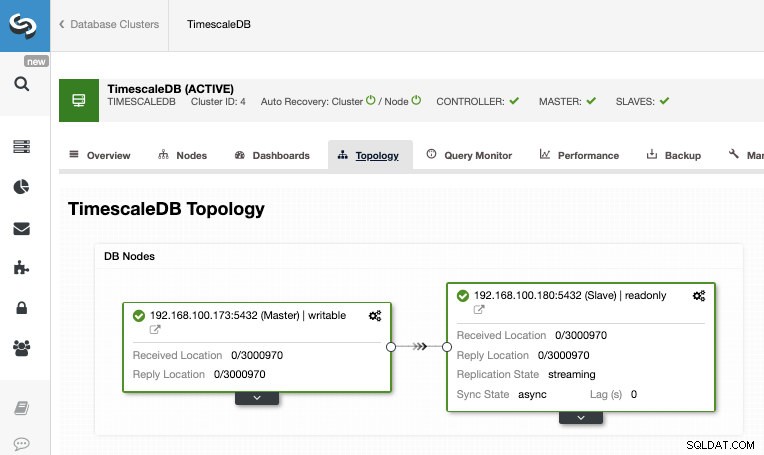
Ao usar o ClusterControl, você também pode executar várias tarefas de gerenciamento em seu TimescaleDB, como backup, monitor e alerta, failover automático, adicionar nós, adicionar balanceadores de carga e muito mais.
Failover
Como pudemos ver, o TimescaleDB usa um fluxo de registros WAL (write-ahead log) para manter os bancos de dados em espera sincronizados. Se o servidor principal falhar, o standby contém quase todos os dados do servidor principal e pode ser rapidamente transformado no novo servidor de banco de dados mestre. Isso pode ser síncrono ou assíncrono e só pode ser feito para todo o servidor de banco de dados.
Para garantir efetivamente a alta disponibilidade, não basta ter uma arquitetura master-standby. Também precisamos habilitar alguma forma automática de failover, portanto, se algo falhar, podemos ter o menor atraso possível na retomada da funcionalidade normal.
O TimescaleDB não inclui um mecanismo de failover automático para identificar falhas no banco de dados mestre e notificar o escravo para se apropriar, o que exigirá um pouco de trabalho do lado do DBA. Você também terá apenas um servidor funcionando, então a recriação da arquitetura master-standby precisa ser feita, então voltamos à mesma situação normal que tínhamos antes do problema.
O ClusterControl inclui um recurso de failover automático para TimescaleDB para melhorar o tempo médio de reparo (MTTR) em seu ambiente de alta disponibilidade. Em caso de falha, o ClusterControl irá promover o slave mais avançado a master, e irá reconfigurar o(s) slave(s) restante(s) para se conectarem ao novo master. O HAProxy também pode ser implementado automaticamente para oferecer um único endpoint de banco de dados aos aplicativos, para que eles não sejam afetados por uma alteração do servidor mestre.
Limitações
Recursos relacionados ClusterControl for TimescaleDB Como implantar facilmente o TimescaleDB PostgreSQL Streaming Replication - um mergulho profundoTemos algumas limitações bem conhecidas ao usar a replicação de streaming:
- Não podemos replicar em uma versão ou arquitetura diferente
- Não podemos alterar nada no servidor em espera
- Não temos muita granularidade sobre o que podemos replicar
Então, para superar essas limitações, temos o recurso de replicação lógica. Para saber mais sobre esse tipo de replicação, você pode conferir o blog a seguir.
Conclusão
Uma topologia master-standby tem muitos usos diferentes, como análise, backup, alta disponibilidade, failover. De qualquer forma, é preciso entender como funciona a replicação de streaming no TimescaleDB. Também é útil ter um sistema para gerenciar todo o cluster e dar a possibilidade de criar essa topologia de maneira fácil. Neste blog, vimos como fazer isso usando o ClusterControl e revisamos alguns conceitos básicos sobre a replicação de streaming.