Os bancos de dados de séries temporais, como o nome sugere, são projetados para armazenar dados que mudam com o tempo. Isso pode ser qualquer tipo de dado que foi coletado ao longo do tempo. Podem ser métricas coletadas de alguns sistemas e, na verdade, todos os sistemas de tendências são exemplos de dados de séries temporais.
Temos diferentes tipos de bancos de dados de séries temporais, quais devemos usar?
Neste blog, veremos quais são as principais diferenças entre duas das principais opções, TimescaleDB e InfluxDB.
InfluxDB
O InfluxDB foi criado por InfluxData. É um banco de dados de série temporal NoSQL personalizado, de código aberto, escrito em Go. O armazenamento de dados fornece uma linguagem semelhante a SQL para consultar os dados, chamada InfluxQL, que facilita a integração dos desenvolvedores em seus aplicativos. Ele também possui uma nova linguagem de consulta personalizada chamada Flux, essa linguagem pode facilitar algumas tarefas, mas sempre há uma curva de aprendizado ao adotar uma linguagem de consulta personalizada.
Este é um exemplo de consulta Flux:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()Neste banco de dados, cada medição tem um timestamp e um conjunto associado de tags e um conjunto de campos. O campo representa os valores reais de leitura da medição, enquanto a tag representa os metadados para descrever as medições. Os tipos de dados de campo são limitados a floats, ints, strings e booleanos e não podem ser alterados sem reescrever os dados. Os valores das tags são indexados. Eles são representados como strings e não podem ser atualizados.
O InfluxDB é bastante fácil de começar, pois você não precisa se preocupar em criar esquemas ou índices. No entanto, é bastante rígido e limitado, sem capacidade de criar índices adicionais, índices em campos contínuos, atualizar metadados após o fato, impor validação de dados etc.
Não é sem esquema. Há um esquema subjacente que é criado automaticamente a partir dos dados de entrada.
O InfluxDB precisa implementar do zero várias ferramentas para tolerância a falhas, como replicação, alta disponibilidade e backup/restauração, e é responsável por sua confiabilidade em disco. Estamos limitados a usar essas ferramentas e muitos desses recursos, como HA, estão disponíveis apenas na versão corporativa.
A ferramenta de backup InfluxDB pode executar um backup completo ou incremental e pode ser usada para recuperação pontual.
O InfluxDB também oferece compactação em disco significativamente melhor do que PostgreSQL e TimescaleDB.
TimescaleDB
TimescaleDB é um banco de dados de séries temporais de código aberto otimizado para ingestão rápida e consultas complexas que suportam SQL completo. É baseado no PostgreSQL e oferece o melhor dos mundos NoSQL e Relacional para dados de séries temporais.
Este é um exemplo de consulta do TimescaleDB:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, como uma extensão do PostgreSQL, é um banco de dados relacional. Isso permite ter uma curva de aprendizado curta para novos usuários e herdar ferramentas como pg_dump ou pg_backup para backup e ferramentas de alta disponibilidade, o que é uma vantagem em relação a outros bancos de dados de séries temporais. Ele também oferece suporte à replicação de streaming como o principal método de replicação, que pode ser usado em uma configuração de alta disponibilidade. Em termos de failover e backups, você pode automatizar esse processo usando um sistema externo como o ClusterControl.
No TimescaleDB, cada medição de série temporal é registrada em sua própria linha, com um campo de tempo seguido por qualquer número de outros campos, que podem ser floats, ints, strings, booleans, arrays, JSON blobs, geospatial dimension, date/time/ carimbos de data/hora, moedas, dados binários e muito mais.
Você pode criar índices em qualquer campo (índices padrão) ou vários campos (índices compostos), ou em expressões como funções, ou até mesmo limitar um índice a um subconjunto de linhas (índice parcial). Qualquer um desses campos pode ser usado como chave estrangeira para tabelas secundárias, que podem armazenar metadados adicionais.
Dessa forma, você precisa escolher um esquema e decidir quais índices serão necessários para o seu sistema.
Desempenho
Se falarmos de desempenho, podemos conferir o ótimo blog de comparação do TimescaleDB. Lá você tem uma comparação detalhada de desempenho entre os dois bancos de dados com gráficos e métricas. Vamos ver algumas das informações mais importantes deste blog.
Inserções
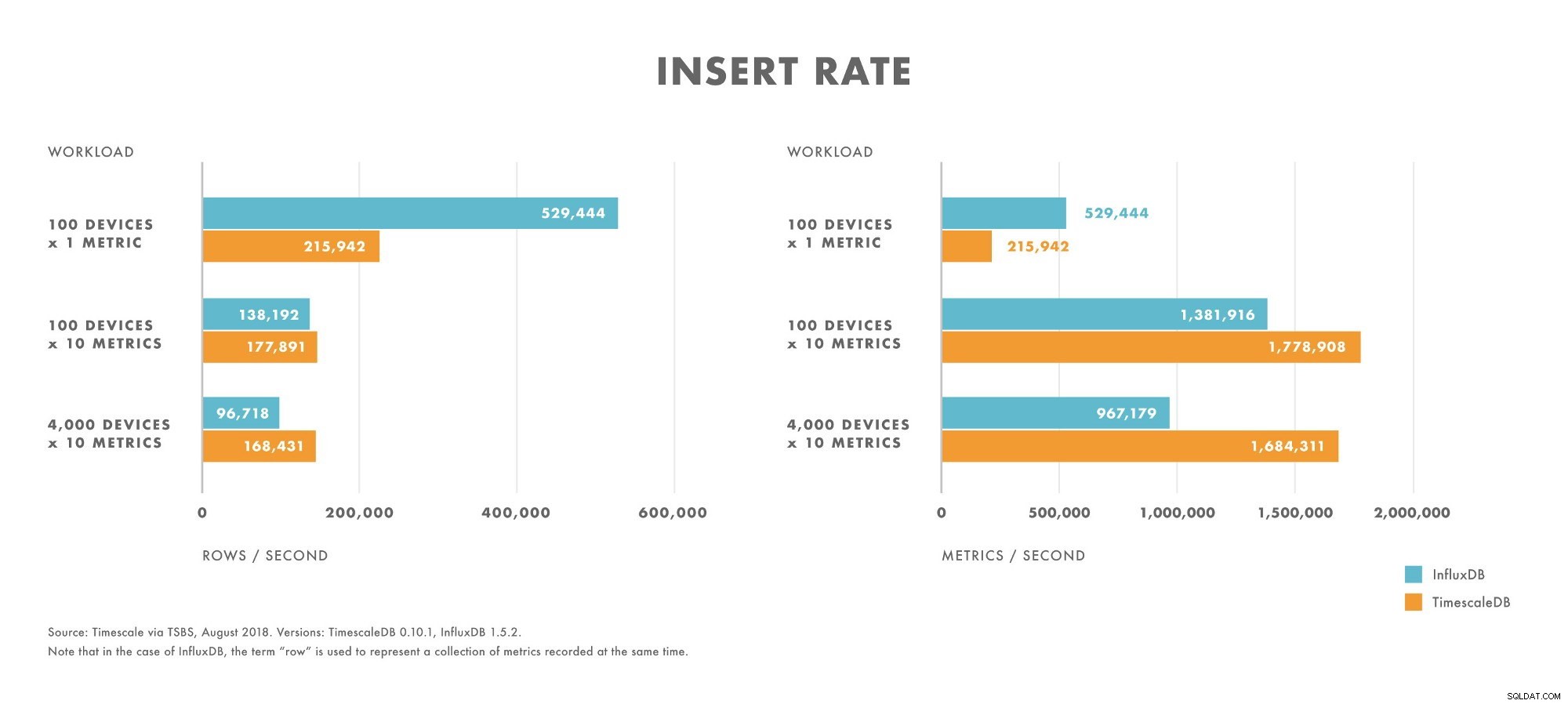
- Para cargas de trabalho com cardinalidade muito baixa (por exemplo, 100 dispositivos), o InfluxDB supera o TimescaleDB.
- À medida que a cardinalidade aumenta, o desempenho de inserção do InfluxDB diminui mais rapidamente do que no TimescaleDB.
- Para cargas de trabalho com cardinalidade moderada a alta (por exemplo, 100 dispositivos enviando 10 métricas), o TimescaleDB supera o InfluxDB.

Latência de leitura
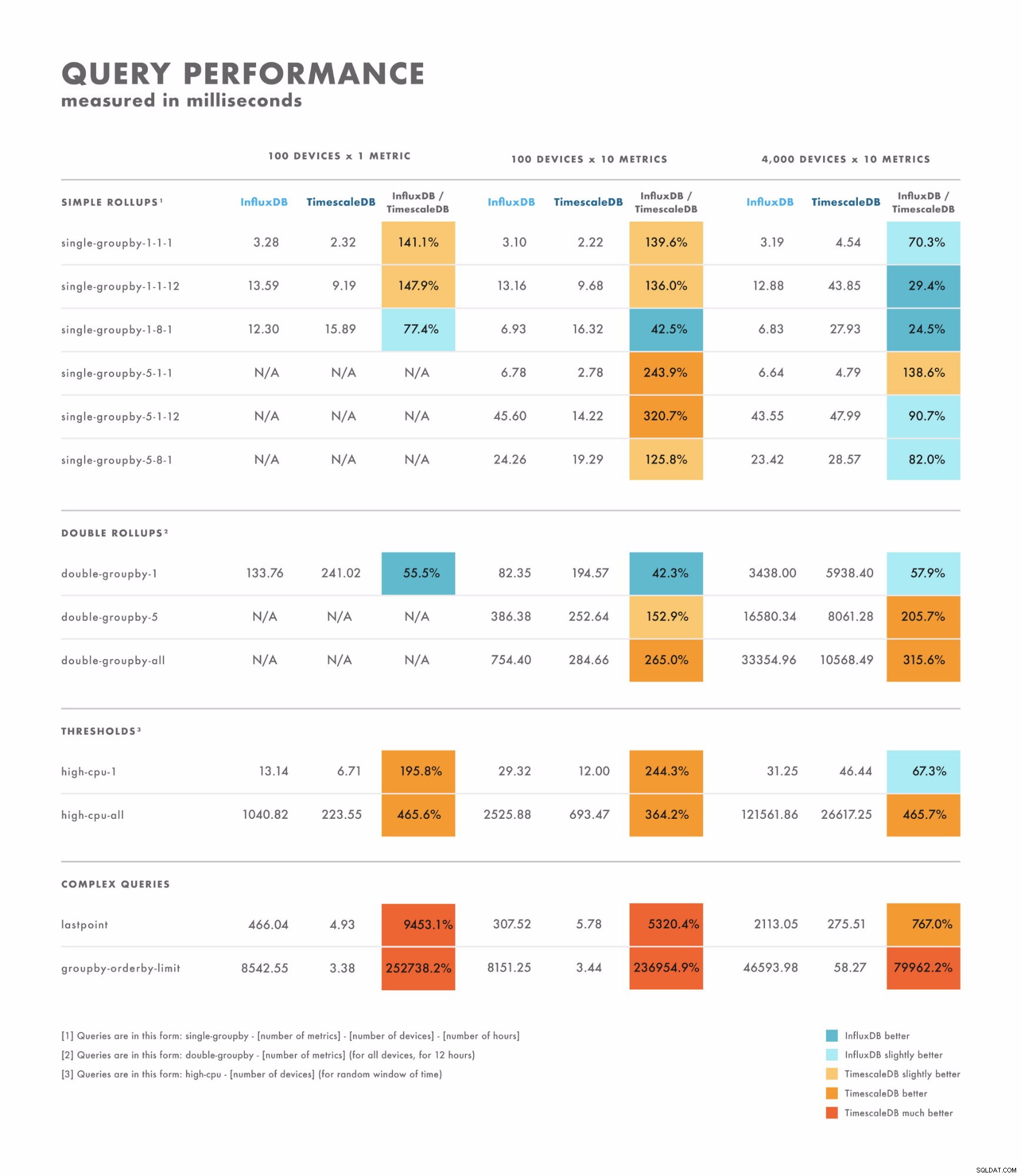
- Para consultas simples, os resultados variam bastante:há alguns em que um banco de dados é claramente melhor que o outro, enquanto outros dependem da cardinalidade do seu conjunto de dados. A diferença aqui geralmente está no intervalo de milissegundos de um dígito a dois dígitos.
- Para consultas complexas, o TimescaleDB supera amplamente o InfluxDB e oferece suporte a uma variedade maior de tipos de consulta. A diferença aqui geralmente está no intervalo de segundos a dezenas de segundos.
- Com isso em mente, a melhor maneira de testar adequadamente é comparar usando as consultas que você planeja executar.
Problemas de estabilidade
- O InfluxDB tem problemas de estabilidade e desempenho em cardinalidades altas (mais de 100 mil).
Conclusão
Se seus dados se encaixam no modelo de dados do InfluxDB e você não espera mudar no futuro, considere usar o InfluxDB, pois esse modelo é mais fácil de começar e, como a maioria dos bancos de dados que usam uma abordagem orientada a colunas, oferece melhor compactação em disco do que PostgreSQL e TimescaleDB.
No entanto, o modelo relacional é mais versátil e oferece mais funcionalidade, flexibilidade e controle que o modelo InfluxDB. Isso é especialmente importante à medida que seu aplicativo evolui. E ao planejar seu sistema, você deve considerar suas necessidades atuais e futuras.
Neste blog, pudemos ver uma pequena comparação entre o TimescaleDB e o InfluxDB, e poderíamos dizer que o TimescaleDB como uma extensão do PostgreSQL, parece bastante maduro e rico em recursos, pois herda muito do PostgreSQL. Mas você pode tomar sua própria decisão com base nos prós e contras mencionados anteriormente neste blog e certifique-se de comparar sua própria carga de trabalho. Boa sorte neste novo mundo de banco de dados de séries temporais!