Na semana passada, apresentei minha sessão T-SQL :Bad Habits and Best Practices durante a conferência GroupBy. Um replay em vídeo e outros materiais estão disponíveis aqui:
- T-SQL:maus hábitos e práticas recomendadas
Um dos itens que sempre menciono nessa sessão é que geralmente prefiro GROUP BY ao invés de DISTINCT ao eliminar duplicatas. Embora DISTINCT explique melhor a intenção e GROUP BY seja necessário apenas quando as agregações estiverem presentes, elas são intercambiáveis em muitos casos.
Vamos começar com algo simples usando o Wide World Importers. Essas duas consultas produzem o mesmo resultado:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
E, de fato, derivam seus resultados usando exatamente o mesmo plano de execução:

Mesmos operadores, mesmo número de leituras, diferenças insignificantes em CPU e duração total (eles se revezam "ganhando").
Então, por que eu recomendaria usar a sintaxe GROUP BY mais elaborada e menos intuitiva em vez de DISTINCT? Bem, neste caso simples, é uma moeda ao ar. No entanto, em casos mais complexos, DISTINCT pode acabar fazendo mais trabalho. Essencialmente, DISTINCT coleta todas as linhas, incluindo quaisquer expressões que precisem ser avaliadas e, em seguida, descarta as duplicatas. GROUP BY pode (novamente, em alguns casos) filtrar as linhas duplicadas antes realizar qualquer um desses trabalhos.
Vamos falar sobre agregação de strings, por exemplo. Enquanto no SQL Server v.Next você será capaz de usar STRING_AGG (veja os posts aqui e aqui), o resto de nós tem que continuar com FOR XML PATH (e antes de você me contar sobre como CTEs recursivos são incríveis para isso, por favor leia este post também). Podemos ter uma consulta como esta, que tenta retornar todos os pedidos da tabela Sales.OrderLines, juntamente com descrições de itens como uma lista delimitada por barra vertical:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Esta é uma consulta típica para resolver esse tipo de problema, com o seguinte plano de execução (o aviso em todos os planos é apenas para a conversão implícita que sai do filtro XPath):
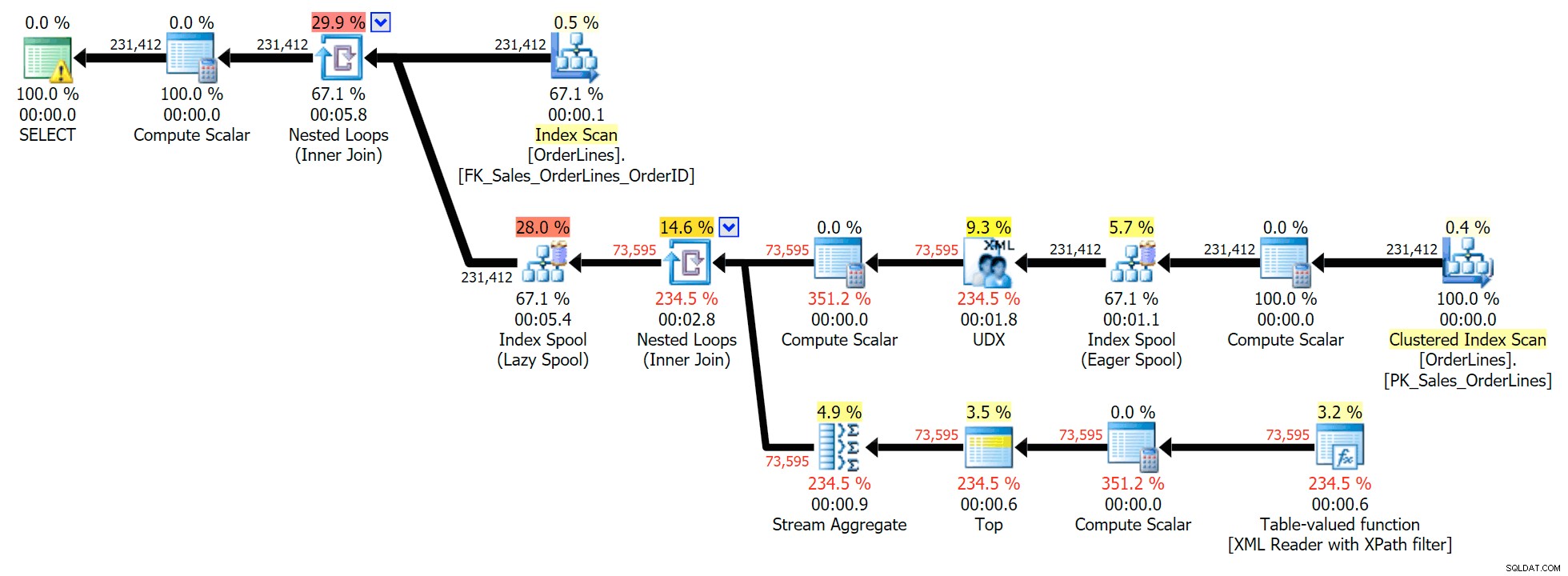
No entanto, há um problema que você pode notar no número de linhas de saída. Você certamente pode identificá-lo ao digitalizar casualmente a saída:

Para cada pedido, vemos a lista delimitada por barra vertical, mas vemos uma linha para cada item em cada ordem. A reação automática é lançar um DISTINCT na lista de colunas:
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Isso elimina as duplicatas (e altera as propriedades de ordenação nas verificações, para que os resultados não apareçam necessariamente em uma ordem previsível) e produz o seguinte plano de execução:
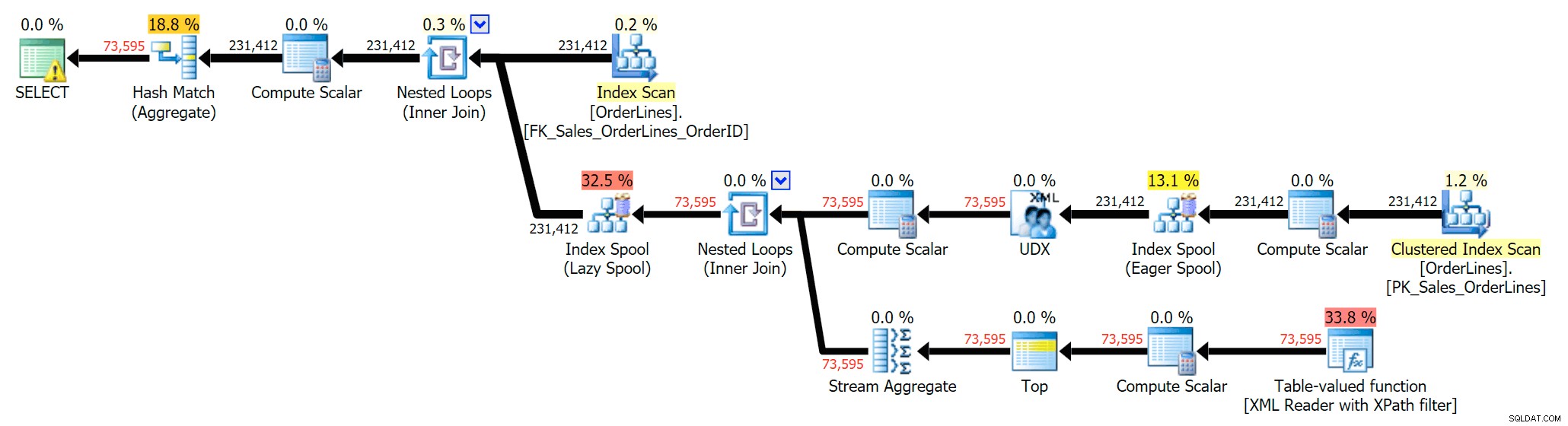
Outra maneira de fazer isso é adicionar um GROUP BY para OrderID (já que a subconsulta não precisa explicitamente para ser referenciado novamente no GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Isso produz os mesmos resultados (embora o pedido tenha retornado) e um plano ligeiramente diferente:
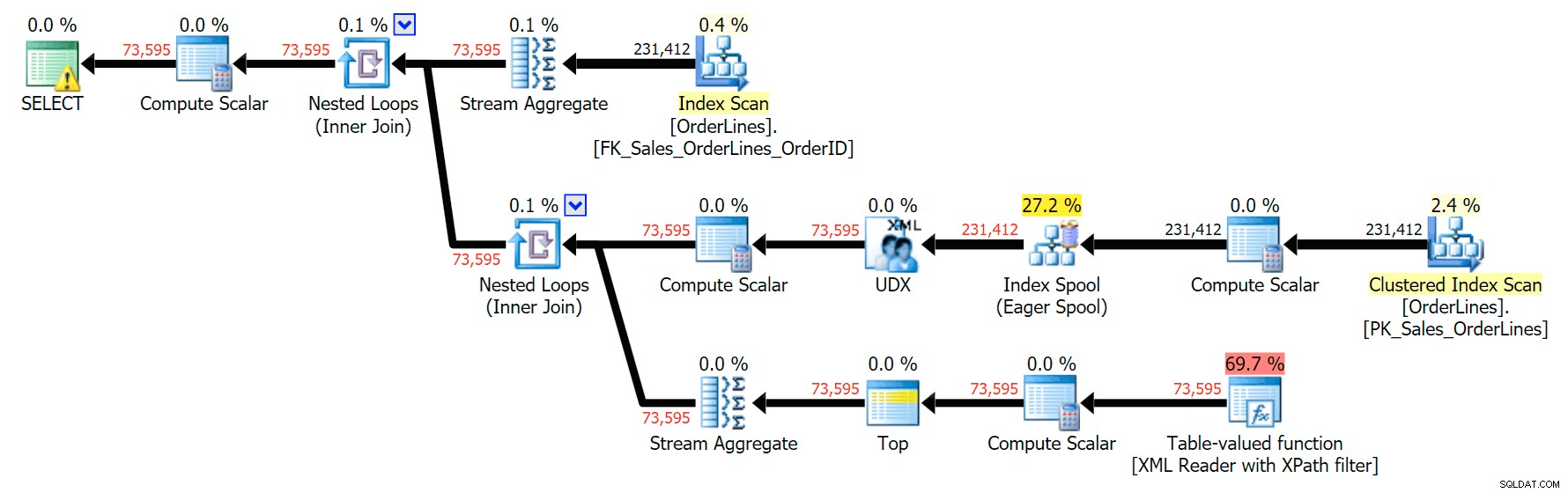
As métricas de desempenho, no entanto, são interessantes de comparar.

A variação DISTINCT levou 4X mais tempo, usou 4X a CPU e quase 6X as leituras quando comparada à variação GROUP BY. (Lembre-se, essas consultas retornam exatamente os mesmos resultados.)
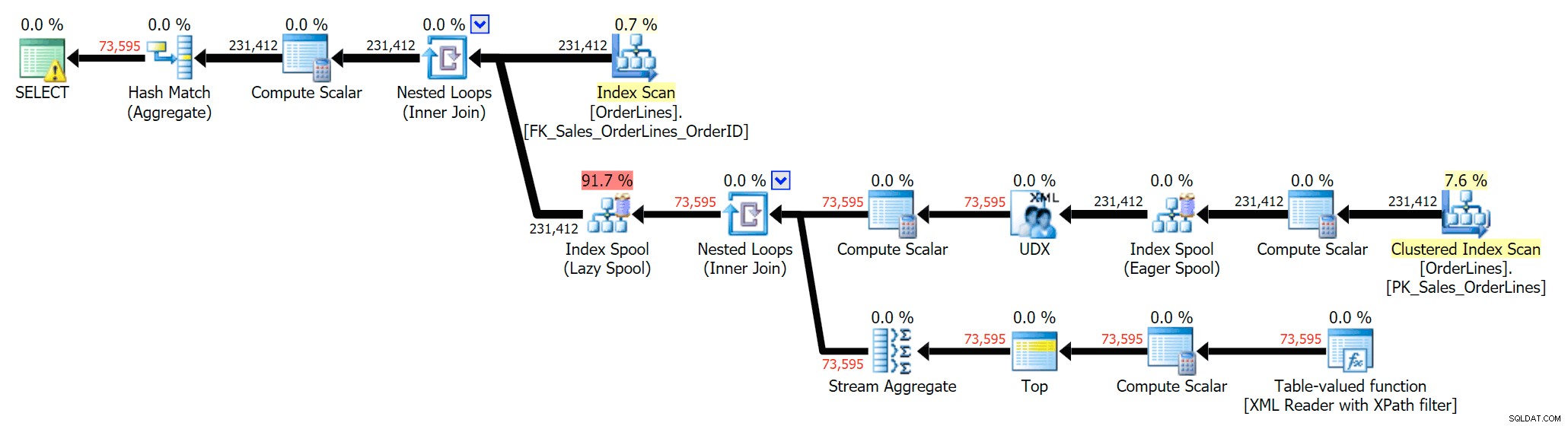
Também podemos comparar os planos de execução quando alteramos os custos de CPU + E/S combinados para apenas E/S, recurso exclusivo do Plan Explorer. Também mostramos os valores recalculados (que são baseados no valor real custos observados durante a execução da consulta, um recurso também encontrado apenas no Plan Explorer). Aqui está o plano DISTINTO:
E aqui está o plano GROUP BY:
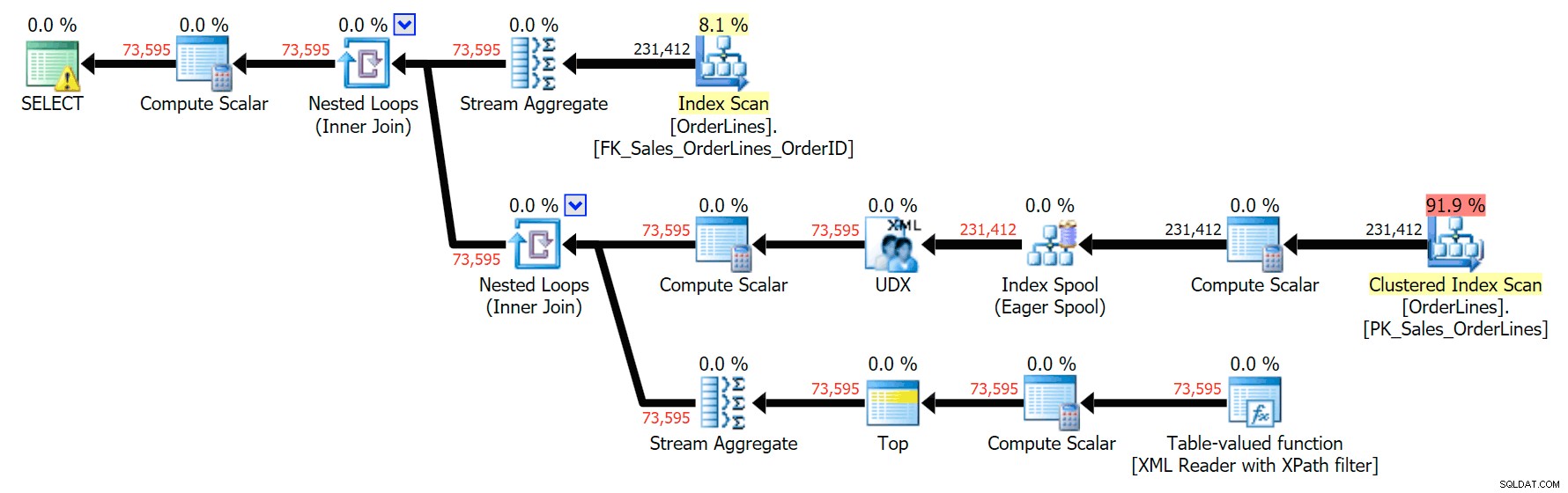
Você pode ver que, no plano GROUP BY, quase todo o custo de E/S está nas varreduras (aqui está a dica de ferramenta para a varredura de CI, mostrando um custo de E/S de ~3,4 "query bucks"). No entanto, no plano DISTINCT, a maior parte do custo de E/S está no carretel de índice (e aqui está a dica de ferramenta; o custo de E/S aqui é ~ 41,4 "query bucks"). Observe que a CPU também é muito maior com o carretel de índice. Falaremos sobre "query bucks" outra hora, mas o ponto é que o spool de índice é mais de 10 vezes mais caro que a varredura - mas a varredura ainda é a mesma 3,4 em ambos os planos. Essa é uma das razões pelas quais sempre me incomoda quando as pessoas dizem que precisam "consertar" a operadora do plano com o maior custo. Algum operador do plano sempre ser o mais caro; isso não significa que precisa ser consertado.
@AaronBertrand essas consultas não são realmente logicamente equivalentes — DISTINCT é em ambas as colunas, enquanto seu GROUP BY está apenas em uma
— Adam Machanic (@AdamMachanic) 20 de janeiro de 2017
Embora Adam Machanic esteja correto quando diz que essas consultas são semanticamente diferentes, o resultado é o mesmo – obtemos o mesmo número de linhas, contendo exatamente os mesmos resultados, e fizemos isso com muito menos leituras e CPU.
Portanto, embora DISTINCT e GROUP BY sejam idênticos em muitos cenários, aqui está um caso em que a abordagem GROUP BY definitivamente leva a um melhor desempenho (ao custo de uma intenção declarativa menos clara na própria consulta). Eu estaria interessado em saber se você acha que existem cenários em que DISTINCT é melhor que GROUP BY, pelo menos em termos de desempenho, que é muito menos subjetivo que estilo ou se uma declaração precisa ser autodocumentada.
Esta postagem se encaixa na minha série "surpresas e suposições" porque muitas coisas que consideramos verdades com base em observações limitadas ou casos de uso específicos podem ser testadas quando usadas em outros cenários. Só temos que nos lembrar de reservar um tempo para fazer isso como parte da otimização de consultas SQL…
Referências
- Concatenação Agrupada no SQL Server
- Concatenação Agrupada:como pedir e remover duplicatas
- Quatro casos de uso práticos para concatenação agrupada
- SQL Server v.Next:desempenho de STRING_AGG()
- SQL Server v.Next :STRING_AGG Performance, Parte 2