O Sysbench é uma ótima ferramenta para gerar dados de teste e realizar benchmarks MySQL OLTP. Normalmente, seria feito um ciclo de preparação-execução-limpeza ao executar o benchmark usando o Sysbench. Por padrão, a tabela gerada pelo Sysbench é uma tabela base padrão sem partição. Esse comportamento pode ser estendido, é claro, mas você precisa saber como escrevê-lo no script LUA.
Nesta postagem de blog, mostraremos como gerar dados de teste para uma tabela particionada no MySQL usando o Sysbench. Isso pode ser usado como um playground para mergulharmos ainda mais na causa-efeito do particionamento de tabelas, distribuição de dados e roteamento de consultas.
Particionamento de tabela de servidor único
Particionamento de servidor único significa simplesmente que todas as partições da tabela residem no mesmo servidor/instância MySQL. Ao criar a estrutura da tabela, definiremos todas as partições de uma vez. Esse tipo de particionamento é bom se você tiver dados que perdem sua utilidade com o tempo e podem ser facilmente removidos de uma tabela particionada descartando a partição (ou partições) contendo apenas esses dados.
Crie o esquema Sysbench:
mysql> CREATE SCHEMA sbtest;Crie o usuário do banco de dados sysbench:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO 'sbtest'@'%';No Sysbench, pode-se usar o comando --prepare para preparar o servidor MySQL com estruturas de esquema e gerar linhas de dados. Temos que pular esta parte e definir a estrutura da tabela manualmente.
Crie uma tabela particionada. Neste exemplo, vamos criar apenas uma tabela chamada sbtest1 e ela será particionada por uma coluna chamada "k", que é basicamente um inteiro variado entre 0 e 1.000.000 (com base na opção --table-size que estamos vai usar na operação somente de inserção mais tarde):
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999),
PARTITION p2 VALUES LESS THAN MAXVALUE
);Teremos 2 partições - A primeira partição é chamada p1 e armazenará dados onde o valor na coluna "k" for menor que 499.999 e a segunda partição, p2, armazenará os valores restantes . Também criamos uma chave primária que contém as duas colunas importantes - "id" é para identificador de linha e "k" é a chave de partição. No particionamento, uma chave primária deve incluir todas as colunas na função de particionamento da tabela (onde usamos "k" na função de partição de intervalo).
Verifique se as partições estão lá:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 0 |
| sbtest | sbtest1 | p2 | 0 |
+--------------+------------+----------------+------------+Podemos então iniciar uma operação somente de inserção do Sysbench como abaixo:
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.131 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runObserve as partições da tabela crescerem conforme o Sysbench é executado:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 1021 |
| sbtest | sbtest1 | p2 | 1644 |
+--------------+------------+----------------+------------+Se contarmos o número total de linhas usando a função COUNT, ele corresponderá ao número total de linhas informadas pelas partições:
mysql> SELECT COUNT(id) FROM sbtest1;
+-----------+
| count(id) |
+-----------+
| 2665 |
+-----------+É isso. Temos um particionamento de tabela de servidor único pronto com o qual podemos brincar.
Particionamento de tabela multiservidor
No particionamento multi-servidor, usaremos vários servidores MySQL para armazenar fisicamente um subconjunto de dados de uma tabela específica (sbtest1), conforme mostrado no diagrama a seguir:
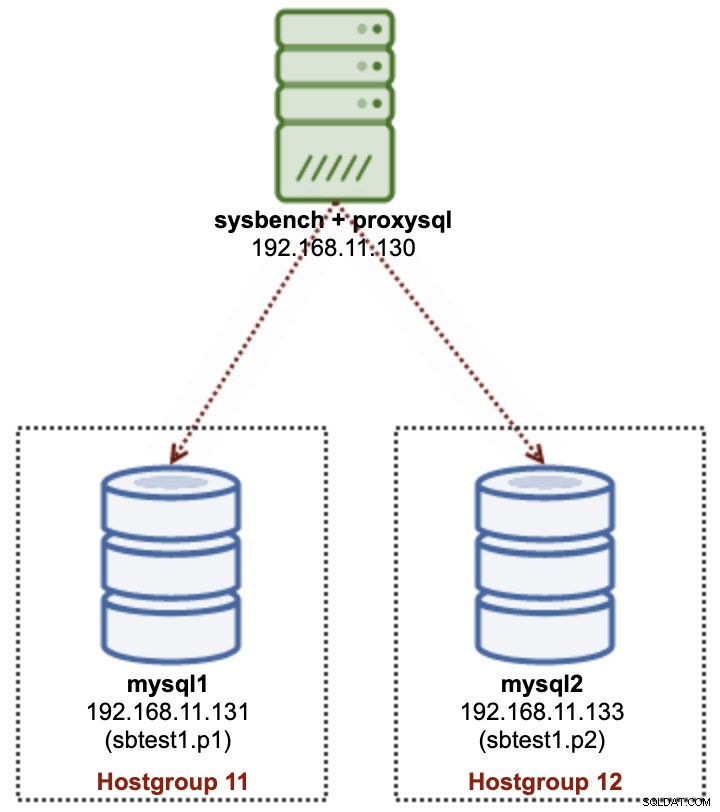
Vamos implantar 2 nós MySQL independentes - mysql1 e mysql2. A tabela sbtest1 será particionada nesses dois nós e chamaremos essa combinação de partição + host de shard. O Sysbench está sendo executado remotamente no terceiro servidor, imitando a camada do aplicativo. Como o Sysbench não reconhece partições, precisamos ter um driver ou roteador de banco de dados para rotear as consultas de banco de dados para o fragmento correto. Usaremos o ProxySQL para atingir esse objetivo.
Vamos criar outro novo banco de dados chamado sbtest3 para esta finalidade:
mysql> CREATE SCHEMA sbtest3;
mysql> USE sbtest3;Conceda os privilégios corretos ao usuário do banco de dados sbtest:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest3.* TO 'sbtest'@'%';No mysql1, crie a primeira partição da tabela:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999)
);Ao contrário do particionamento autônomo, definimos apenas a condição para a partição p1 na tabela para armazenar todas as linhas com valores de coluna "k" variando de 0 a 499.999.
No mysql2, crie outra tabela particionada:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p2 VALUES LESS THAN MAXVALUE
);No segundo servidor, ele deve conter os dados da segunda partição armazenando o restante dos valores antecipados da coluna "k".
Nossa estrutura de tabela agora está pronta para ser preenchida com dados de teste.
Antes de podermos executar a operação somente de inserção do Sysbench, precisamos instalar um servidor ProxySQL como o roteador de consulta e atuar como o gateway para nossos fragmentos MySQL. O sharding de vários servidores requer que as conexões de banco de dados provenientes dos aplicativos sejam roteadas para o shard correto. Caso contrário, você verá o seguinte erro:
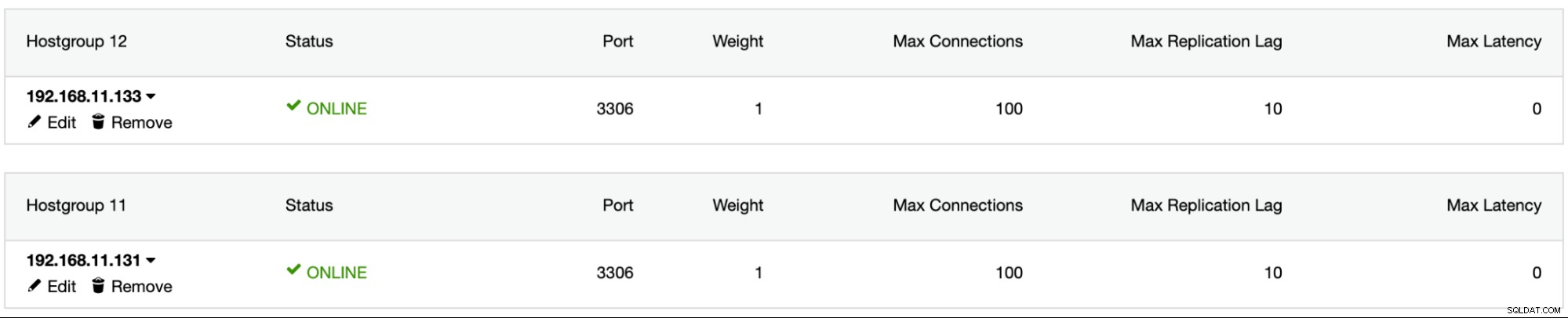
1526 (Table has no partition for value 503599)Instale o ProxySQL usando o ClusterControl, adicione o usuário do banco de dados sbtest no ProxySQL, adicione os dois servidores MySQL no ProxySQL e configure mysql1 como hostgroup 11 e mysql2 como hostgroup 12:
Em seguida, precisamos trabalhar em como a consulta deve ser roteada. Uma amostra da consulta INSERT que será executada pelo Sysbench terá a seguinte aparência:
INSERT INTO sbtest1 (id, k, c, pad)
VALUES (0, 503502, '88816935247-23939908973-66486617366-05744537902-39238746973-63226063145-55370375476-52424898049-93208870738-99260097520', '36669559817-75903498871-26800752374-15613997245-76119597989')Então vamos usar a seguinte expressão regular para filtrar a consulta INSERT para "k" => 500000, para atender a condição de particionamento:
^INSERT INTO sbtest1 \(id, k, c, pad\) VALUES \([0-9]\d*, ([5-9]{1,}[0-9]{5}|[1-9]{1,}[0-9]{6,}).*A expressão acima simplesmente tenta filtrar o seguinte:
-
[0-9]\d* - Estamos esperando um inteiro de incremento automático aqui, portanto, correspondemos a qualquer inteiro.
-
[5-9]{1,}[0-9]{5} - O valor corresponde a qualquer número inteiro de 5 como o primeiro dígito e 0-9 nos últimos 5 dígitos, para corresponder ao valor do intervalo de 500.000 a 999.999.
-
[1-9]{1,}[0-9]{6,} - O valor corresponde a qualquer número inteiro de 1 a 9 como o primeiro dígito e de 0 a 9 nos últimos 6 dígitos ou maiores, para corresponder ao valor de 1.000.000 e maior.
Criaremos duas regras de consulta semelhantes. A primeira regra de consulta é a negação da expressão regular acima. Damos a esta regra o ID 51 e o hostgroup de destino deve ser o hostgroup 11 para corresponder à coluna "k" <500.000 e encaminhar as consultas para a primeira partição. Deve ficar assim:
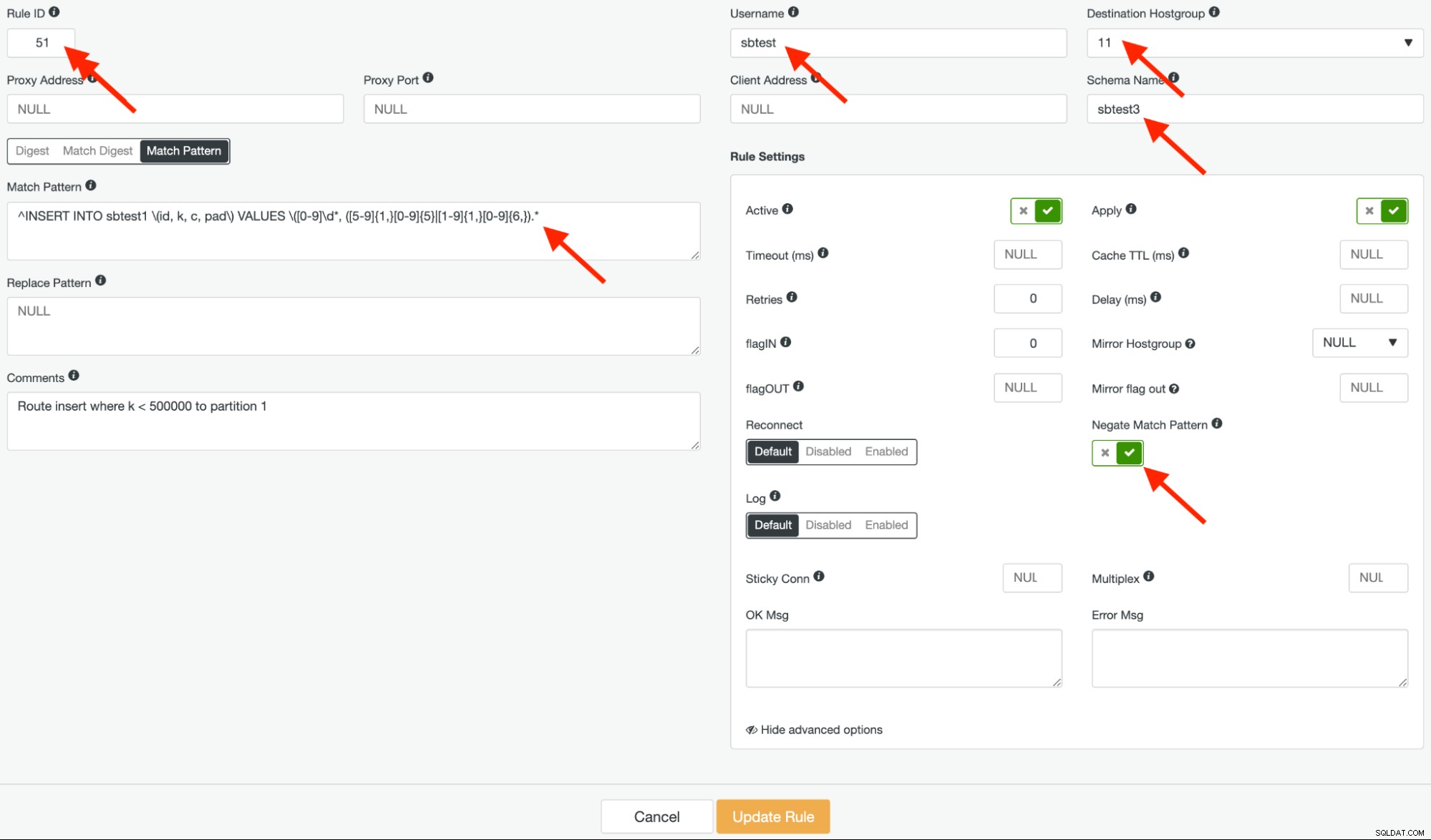
Preste atenção ao "Negate Match Pattern" na captura de tela acima. Essa opção é fundamental para o roteamento adequado dessa regra de consulta.
Em seguida, crie outra regra de consulta com ID de regra 52, usando a mesma expressão regular e o hostgroup de destino deve ser 12, mas desta vez, deixe "Negate Match Pattern" como false, conforme mostrado abaixo:
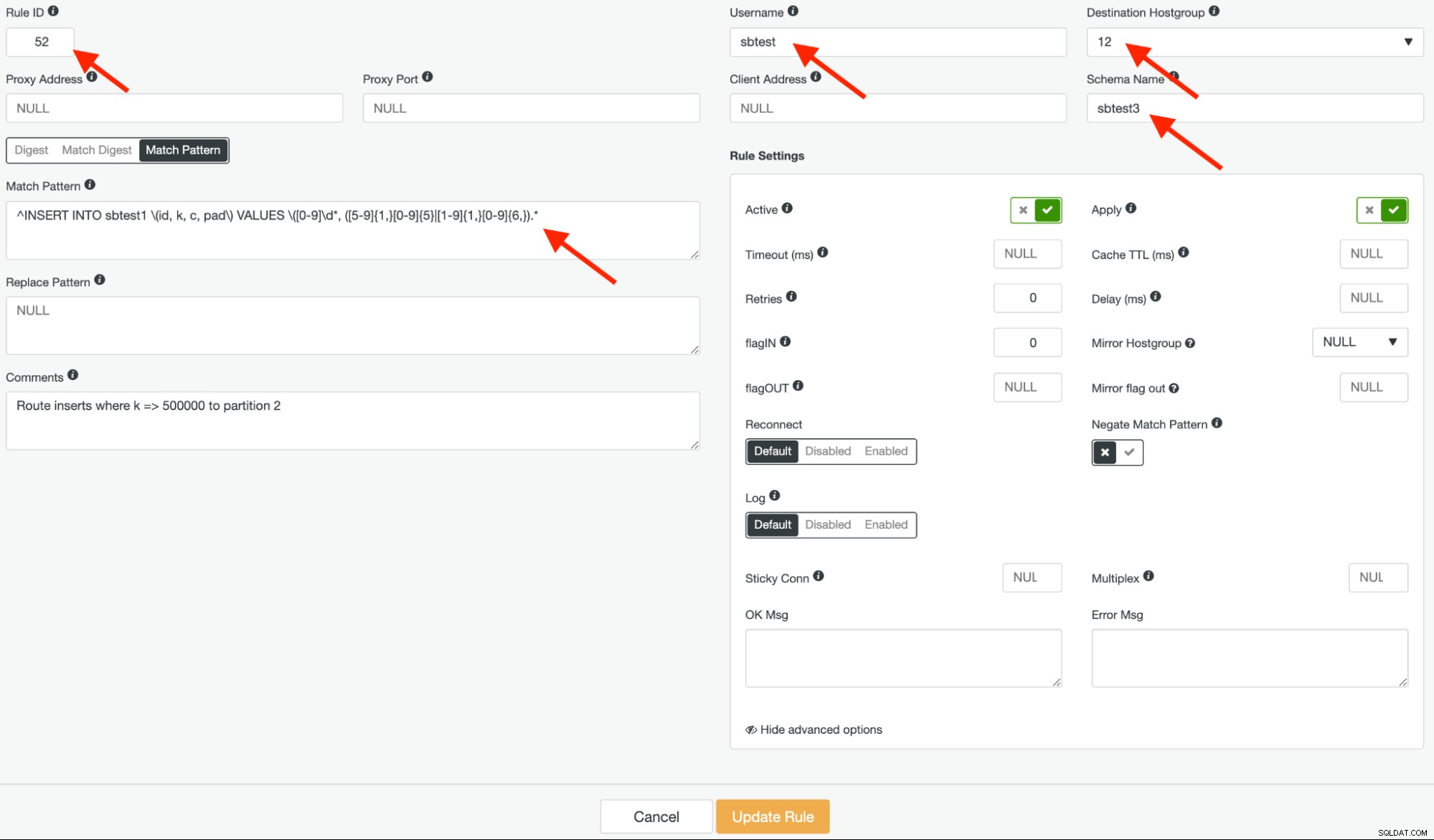
Podemos então iniciar uma operação somente de inserção usando o Sysbench para gerar dados de teste . As informações relacionadas ao acesso do MySQL devem ser o host ProxySQL (192.168.11.130 na porta 6033):
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.130 \
--mysql-port=6033 \
--mysql-user=sbtest \
--mysql-db=sbtest3 \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
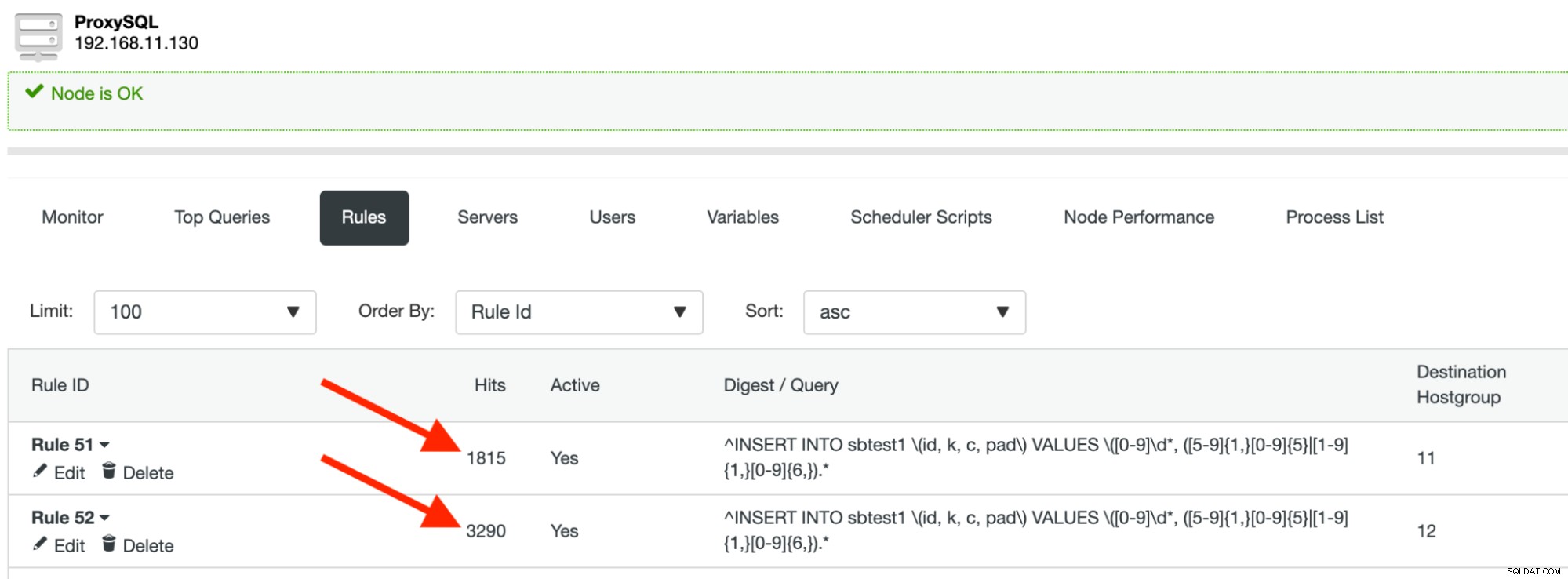
runSe você não vir nenhum erro, significa que o ProxySQL roteou nossas consultas para o fragmento/partição correto. Você deve ver que as ocorrências da regra de consulta estão aumentando enquanto o processo do Sysbench está em execução:
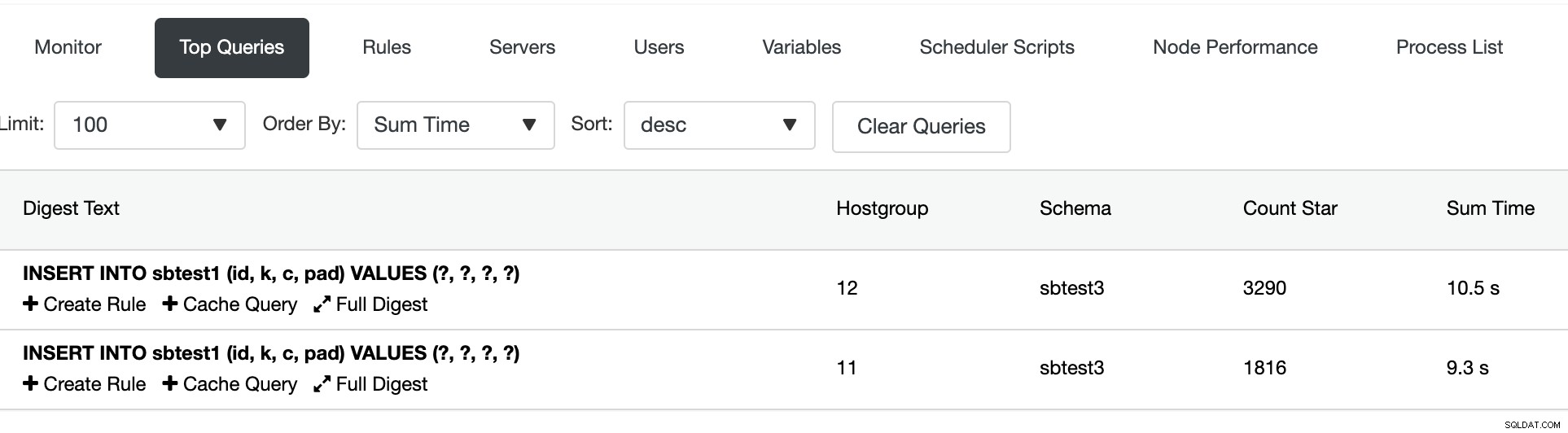
Na seção Principais consultas, podemos ver o resumo do roteamento da consulta:
Para verificar novamente, faça login no mysql1 para procurar a primeira partição e verifique o valor mínimo e máximo da coluna 'k' na tabela sbtest1:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 232185 | 499998 |
+--------+--------+Parece ótimo. O valor máximo da coluna "k" não ultrapassa o limite de 499.999. Vamos verificar o número de linhas que ele armazena para esta partição:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p1 | 1815 |
+--------------+------------+----------------+------------+Agora vamos verificar o outro servidor MySQL (mysql2):
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500003 | 794952 |
+--------+--------+Vamos verificar o número de linhas que ele armazena para esta partição:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p2 | 3247 |
+--------------+------------+----------------+------------+Excelente! Temos uma configuração de teste do MySQL fragmentado com particionamento de dados adequado usando o Sysbench para brincarmos. Bom benchmarking!