Chaves primárias e estrangeiras são características fundamentais de bancos de dados relacionais, conforme notado originalmente no artigo de E.F. Codd, “A Relational Model of Data for Large Shared Data Banks”, publicado em 1970. A citação frequentemente repetida é:“The key, the whole key, e nada além da chave, então me ajude Codd."
Plano de fundo:Chaves primárias
Uma chave primária é uma restrição no SQL Server, que atua para identificar exclusivamente cada linha em uma tabela. A chave pode ser definida como uma única coluna não NULL ou uma combinação de colunas não NULL que gera um valor exclusivo e é usada para impor a integridade da entidade para uma tabela. Uma tabela pode ter apenas uma chave primária e, quando uma restrição de chave primária é definida para uma tabela, um índice exclusivo é criado. Esse índice será um índice clusterizado por padrão, a menos que especificado como um índice não clusterizado quando a restrição de chave primária for definida.
Considere o
Sales.SalesOrderHeader tabela no AdventureWorks2012 base de dados. Esta tabela contém informações básicas sobre um pedido de venda, incluindo data do pedido e ID do cliente, e cada venda é identificada exclusivamente por um SalesOrderID , que é a chave primária da tabela. Sempre que uma nova linha é adicionada à tabela, a restrição de chave primária (chamada PK_SalesOrderHeader_SalesOrderID ) é verificado para garantir que nenhuma linha já exista com o mesmo valor para SalesOrderID . Chaves estrangeiras
Separadas das chaves primárias, mas muito relacionadas, estão as chaves estrangeiras. Uma chave estrangeira é uma coluna ou combinação de colunas que é igual à chave primária, mas em uma tabela diferente. As chaves estrangeiras são usadas para definir um relacionamento e impor a integridade entre duas tabelas.
Para continuar usando o exemplo acima, o
SalesOrderID coluna existe como uma chave estrangeira no Sales.SalesOrderDetail tabela, onde são armazenadas informações adicionais sobre a venda, como ID do produto e preço. Quando uma nova venda é adicionada ao SalesOrderHeader tabela, não é necessário adicionar uma linha para essa venda ao SalesOrderDetail tabela No entanto, ao adicionar uma linha ao SalesOrderDetail tabela, uma linha correspondente para o SalesOrderID deve existem no SalesOrderHeader tabela. Por outro lado, ao excluir dados, uma linha para um
SalesOrderID específico pode ser excluído a qualquer momento do SalesOrderDetail tabela, mas para que uma linha seja excluída do SalesOrderHeader tabela, linhas associadas de SalesOrderDetail terá de ser eliminado primeiro. Ao contrário das restrições de chave primária, quando uma restrição de chave estrangeira é definida para uma tabela, um índice não é criado por padrão pelo SQL Server. No entanto, não é incomum que desenvolvedores e administradores de banco de dados os adicionem manualmente. A chave estrangeira pode fazer parte de uma chave primária composta para a tabela, caso em que existiria um índice clusterizado com a chave estrangeira como parte da chave de clustering. Como alternativa, as consultas podem exigir um índice que inclua a chave estrangeira e uma ou mais colunas adicionais na tabela, portanto, um índice não clusterizado seria criado para dar suporte a essas consultas. Além disso, os índices em chaves estrangeiras podem fornecer benefícios de desempenho para junções de tabelas envolvendo a chave primária e a chave estrangeira e podem afetar o desempenho quando o valor da chave primária é atualizado ou se a linha é excluída.
No
AdventureWorks2012 banco de dados, há uma tabela, SalesOrderDetail , com SalesOrderID como chave estrangeira. Para o SalesOrderDetail tabela, SalesOrderID e SalesOrderDetailID combinam para formar a chave primária, suportada por um índice clusterizado. Se o SalesOrderDetail tabela não tinha um índice no SalesOrderID coluna, então quando uma linha é excluída de SalesOrderHeader , o SQL Server teria que verificar se nenhuma linha para o mesmo SalesOrderID valor existe. Sem nenhum índice que contenha o SalesOrderID coluna, o SQL Server precisaria realizar uma verificação completa da tabela de SalesOrderDetail . Como você pode imaginar, quanto maior a tabela referenciada, mais tempo demorará a exclusão. Um exemplo
Podemos ver isso no exemplo a seguir, que usa cópias das tabelas mencionadas do
AdventureWorks2012 banco de dados que foi expandido usando um script que pode ser encontrado aqui. O script foi desenvolvido por Jonathan Kehayias (blog | @SQLPoolBoy) e cria um SalesOrderHeaderEnlarged tabela com 1.258.600 linhas e um SalesOrderDetailEnglarged tabela com 4.852.680 linhas. Depois que o script foi executado, a restrição de chave estrangeira foi adicionada usando as instruções abaixo. Observe que a restrição é criada com o ON DELETE CASCADE opção. Com esta opção, quando uma atualização ou exclusão é emitida no SalesOrderHeaderEnlarged table, linhas na(s) tabela(s) correspondente(s) – neste caso apenas SalesOrderDetailEnglarged – são atualizados ou excluídos. Além disso, o índice clusterizado padrão para
SalesOrderDetailEnglarged foi descartado e recriado para ter apenas SalesOrderDetailID como a chave primária, pois representa um design típico. USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO Com a restrição de chave estrangeira e sem índice de suporte, uma única exclusão foi emitida no
SalesOrderHeaderEnlarged tabela, que resultou na remoção de uma linha de SalesOrderHeaderEnlarged e 72 linhas de SalesOrderDetailEnglarged :SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
As estatísticas de IO e informações de tempo mostraram o seguinte:
SQL Server analisa e compila o tempo:
Tempo de CPU =8 ms, tempo decorrido =8 ms.
Tabela 'SalesOrderDetailEnlarged'. Contagem de varredura 1, leituras lógicas 50647, leituras físicas 8, leituras antecipadas 50667, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Worktable'. Contagem de varredura 2, leituras lógicas 7, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'SalesOrderHeaderEnlarged'. Contagem de varredura 0, leituras lógicas 15, leituras físicas 14, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tempos de execução do SQL Server:
Tempo de CPU =1.045 ms, tempo decorrido =1.898 ms.
Usando o SQL Sentry Plan Explorer, o plano de execução mostra uma verificação de índice clusterizado em relação a
SalesOrderDetailEnglarged pois não há índice em SalesOrderID :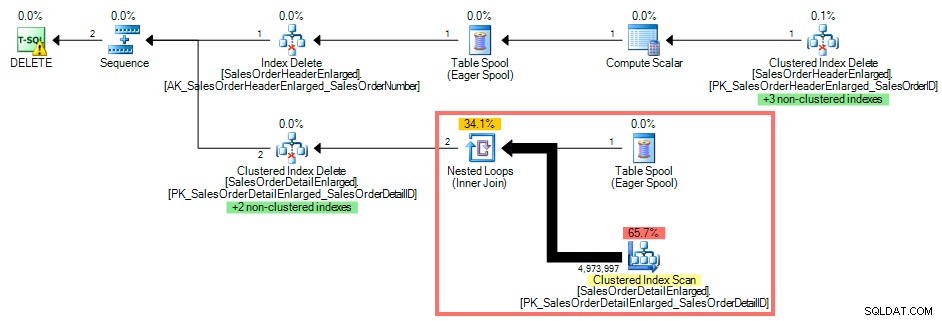
Plano de consulta sem índice na chave estrangeira
O índice não clusterizado para dar suporte a
SalesOrderDetailEnglarged foi então criado usando a seguinte declaração:USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Outra exclusão foi executada para um
SalesOrderID que afetou uma linha em SalesOrderHeaderEnlarged e 72 linhas em SalesOrderDetailEnglarged :SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
As estatísticas de IO e informações de tempo mostraram uma melhoria dramática:
SQL Server analisa e compila o tempo:
Tempo de CPU =0 ms, tempo decorrido =7 ms.
Tabela 'SalesOrderDetailEnlarged'. Contagem de varredura 1, leituras lógicas 48, leituras físicas 13, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'Worktable'. Contagem de varredura 2, leituras lógicas 7, leituras físicas 0, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tabela 'SalesOrderHeaderEnlarged'. Contagem de varredura 0, leituras lógicas 15, leituras físicas 15, leituras antecipadas 0, leituras lógicas lob 0, leituras físicas lob 0, leituras antecipadas lob 0.
Tempos de execução do SQL Server:
Tempo de CPU =0 ms, tempo decorrido =27 ms.
E o plano de consulta mostrou uma busca de índice do índice não clusterizado em
SalesOrderID , como esperado: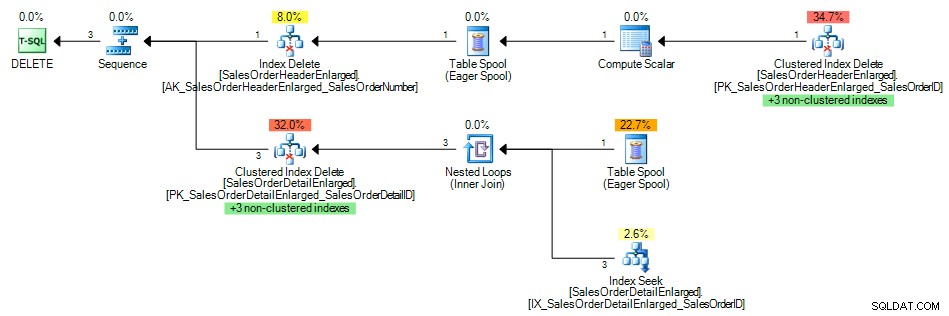
Plano de consulta com índice na chave estrangeira
O tempo de execução da consulta caiu de 1.898 ms para 27 ms – uma redução de 98,58% e leituras para o
SalesOrderDetailEnglarged tabela diminuiu de 50647 para 48 – uma melhoria de 99,9%. Porcentagens à parte, considere apenas a E/S gerada pela exclusão. O SalesOrderDetailEnglarged table tem apenas 500 MB neste exemplo, e para um sistema com 256 GB de memória disponível, uma tabela que ocupa 500 MB no cache do buffer não parece uma situação terrível. Mas uma tabela de 5 milhões de linhas é relativamente pequena; a maioria dos grandes sistemas OLTP tem tabelas com centenas de milhões de linhas. Além disso, não é incomum que existam várias referências de chave estrangeira para uma chave primária, onde uma exclusão da chave primária requer exclusões de várias tabelas relacionadas. Nesse caso, é possível ver durações estendidas para exclusões, o que não é apenas um problema de desempenho, mas também um problema de bloqueio, dependendo do nível de isolamento. Conclusão
Geralmente é recomendado criar um índice que conduza na(s) coluna(s) de chave estrangeira, para dar suporte não apenas a junções entre as chaves primária e estrangeira, mas também atualizações e exclusões. Observe que essa é uma recomendação geral, pois há cenários de casos extremos em que o índice adicional na chave estrangeira não foi usado devido ao tamanho extremamente pequeno da tabela, e as atualizações de índice adicionais afetaram negativamente o desempenho. Como acontece com qualquer modificação de esquema, as adições de índice devem ser testadas e monitoradas após a implementação. É importante garantir que os índices adicionais produzam os efeitos desejados e não afetem negativamente o desempenho da solução. Também vale a pena observar quanto espaço adicional é exigido pelos índices para as chaves estrangeiras. Isso é essencial a ser considerado antes de criar os índices e, se eles fornecerem um benefício, deve ser considerado para o planejamento de capacidade daqui para frente.