Nos blogs anteriores, meus colegas e eu mostramos como você pode monitorar o desempenho, gerenciar e implantar clusters, executar backups e até habilitar o failover automático para TimescaleDB.
Neste blog, mostraremos como dimensionar sua única instância do TimescaleDB para cluster de vários nós em apenas algumas etapas simples.
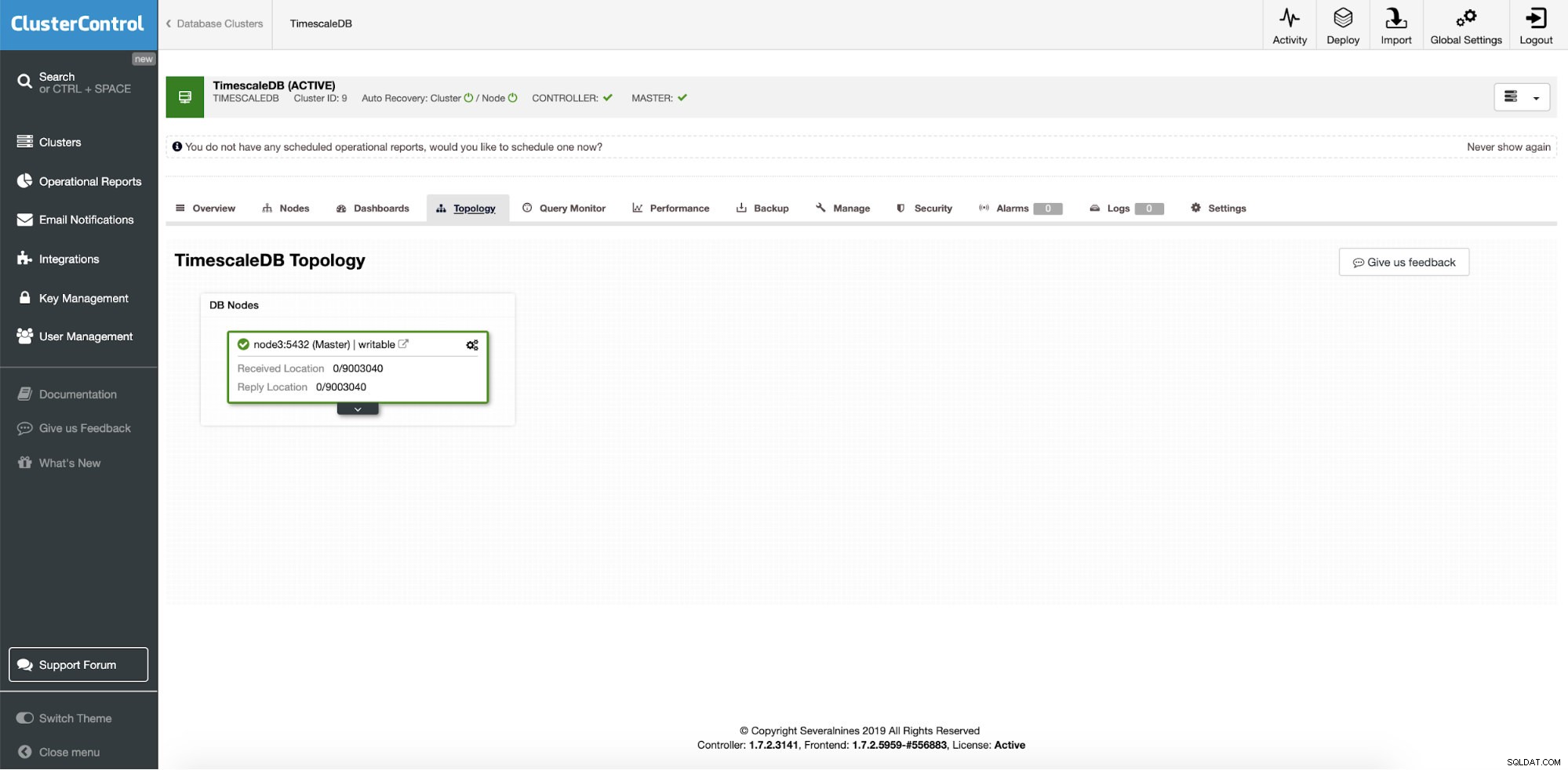
Começaremos com uma configuração comum, uma instância de nó único em execução no CentosOS. O nó está em funcionamento e já está sendo monitorado e gerenciado pelo ClusterControl.
Se você quiser aprender a implantar ou importar sua instância do TimescaleDB, confira o blog escrito por meu colega Sebastian Insausti, “Como implantar facilmente o TimescaleDB”.
A configuração fica da seguinte forma...
 ClusterControl:instância única TimescaleDB
ClusterControl:instância única TimescaleDB Portanto, é uma instância de produção única e queremos convertê-la em cluster sem tempo de inatividade. Nosso principal objetivo é dimensionar as operações de leitura de aplicativos para outras máquinas com a opção de usá-las como servidores de preparação de alta disponibilidade ao gravar falhas no servidor.
Mais nós também devem reduzir o tempo de inatividade de manutenção do aplicativo. Como o patch aplicado no modo de reinicialização contínua - um nó corrigido no momento enquanto outros nós estão servindo conexões de banco de dados.
O último requisito é criar um único endereço para nosso novo cluster para que nossos novos nós fiquem visíveis para o aplicativo em um só lugar.

Podemos resumir nosso plano de ação em duas etapas principais:
- Adicionar uma réplica de leitura
- Instale e configure o Haproxy
Adicionar uma réplica de leitura
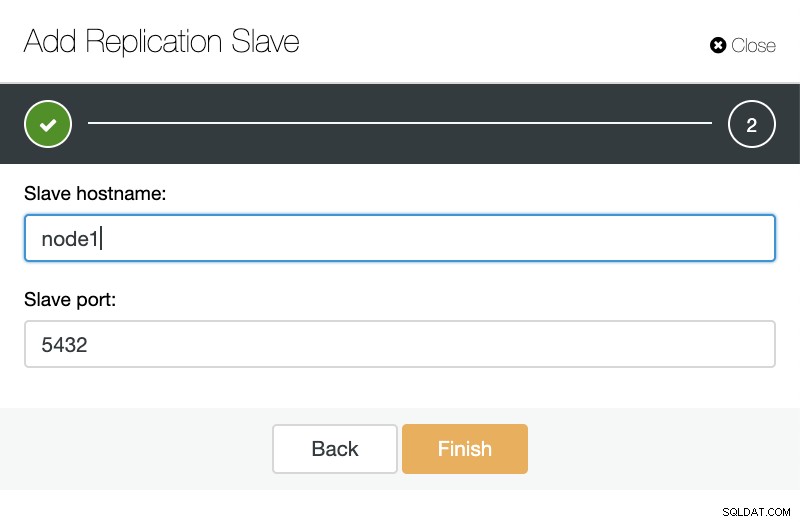
Se formos para ações de cluster e selecionarmos “Add Replication Slave”, podemos criar uma nova réplica do zero ou adicionar um banco de dados TimescaleDB existente como uma réplica.
 ClusterControl:Adicionar escravo de replicação
ClusterControl:Adicionar escravo de replicação 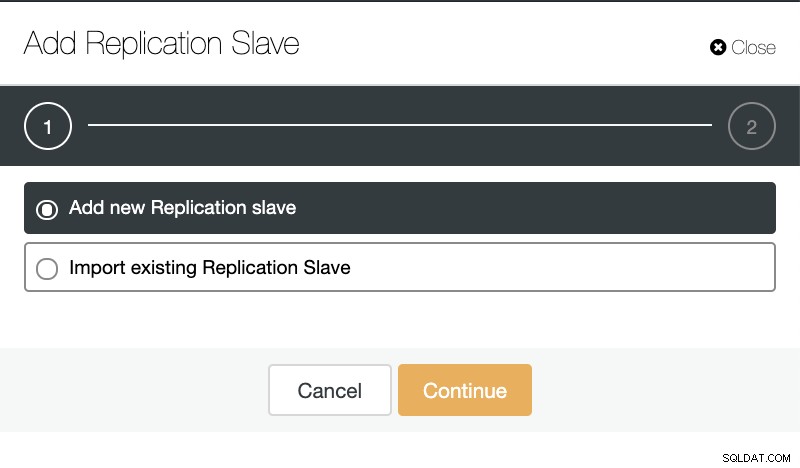 ClusterControl:Adicionar novo escravo de replicação, importar escravo de replicação existente
ClusterControl:Adicionar novo escravo de replicação, importar escravo de replicação existente Como você pode ver na imagem abaixo, só precisamos escolher nosso servidor Master, inserir o endereço IP do nosso novo servidor slave e a porta do banco de dados.
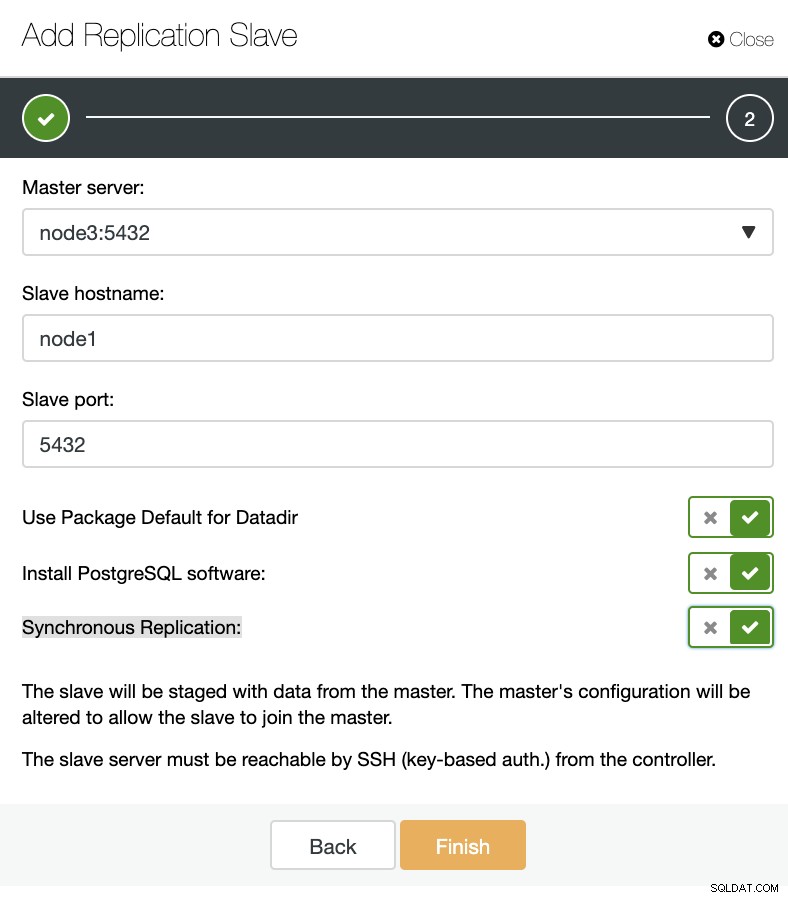 ClusterControl:Adicionar escravo de replicação
ClusterControl:Adicionar escravo de replicação Então podemos escolher se queremos que o ClusterControl instale o software para nós e se o escravo de replicação deve ser síncrono ou assíncrono. Ao importar o servidor escravo existente, você pode usar a opção de importação da seguinte forma:
 ClusterControl:Importar escravo de replicação para TimescaleDB
ClusterControl:Importar escravo de replicação para TimescaleDB De ambas as formas, podemos adicionar quantas réplicas quisermos. No nosso caso de exemplo, adicionaremos dois nós. CusterControl criará um trabalho interno e cuidará de todas as etapas necessárias, uma de cada vez.
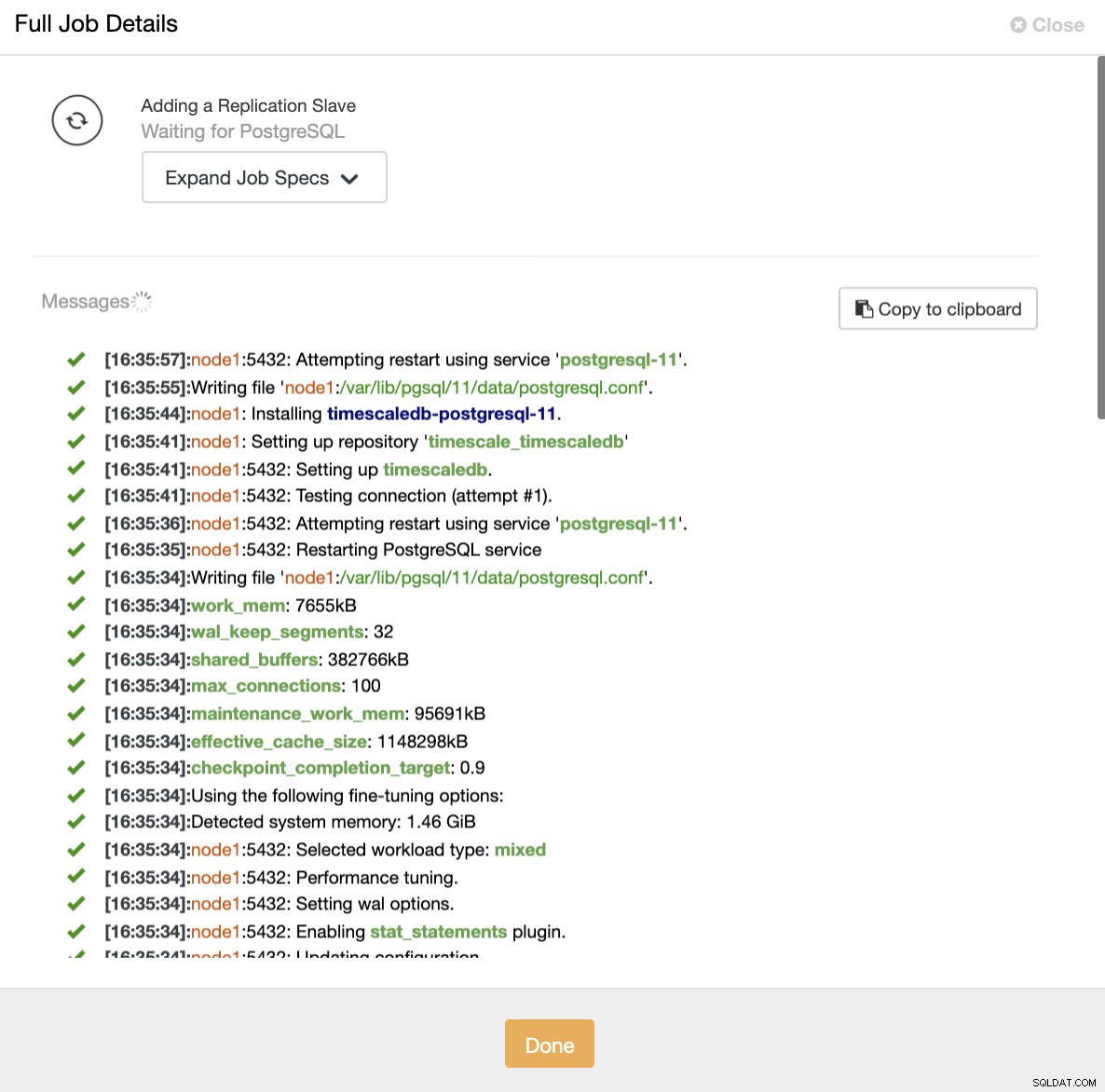 ClusterControl:adicionar réplica de leitura
ClusterControl:adicionar réplica de leitura Adicionando um balanceador de carga ao TimescaleDB
Nesse ponto, nossos dados são distribuídos em vários nós ou data centers se você optar por adicionar nós escravos de replicação em um local diferente. O cluster é dimensionado com dois nós de réplica de leitura adicionais.
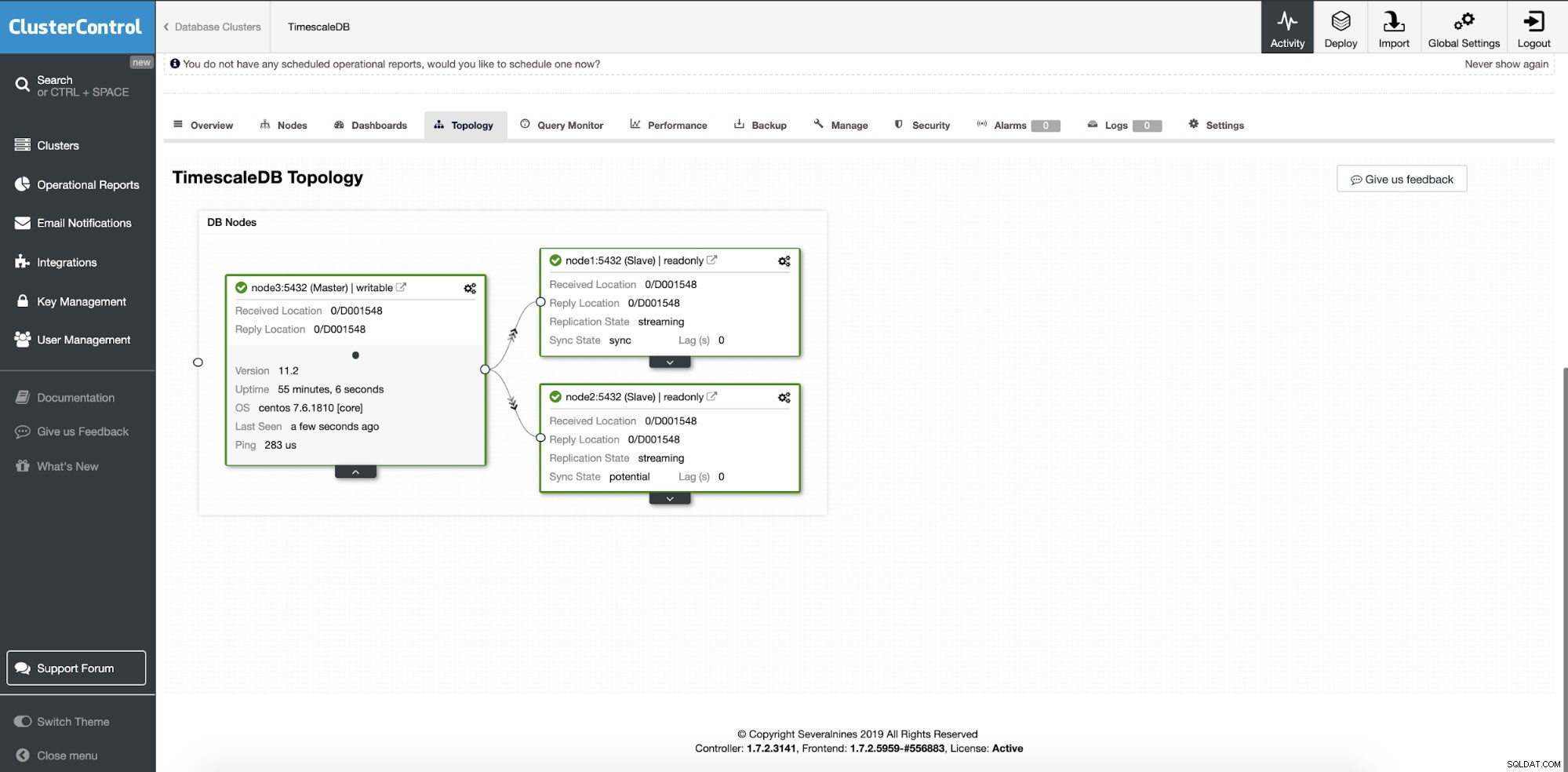 ClusterControl:dois nós adicionados
ClusterControl:dois nós adicionados A questão é como o aplicativo sabe qual nó de banco de dados acessar? Usaremos o HAProxy e diferentes portas para operações de gravação e leitura.
No cluster TimescaleDB, no menu de contexto, escolha adicionar o balanceador de carga.

Agora precisamos fornecer a localização do servidor onde o Haproxy deve ser instalado, qual política queremos usar para conexões de banco de dados e quais nós fazem parte da configuração do Haproxy.
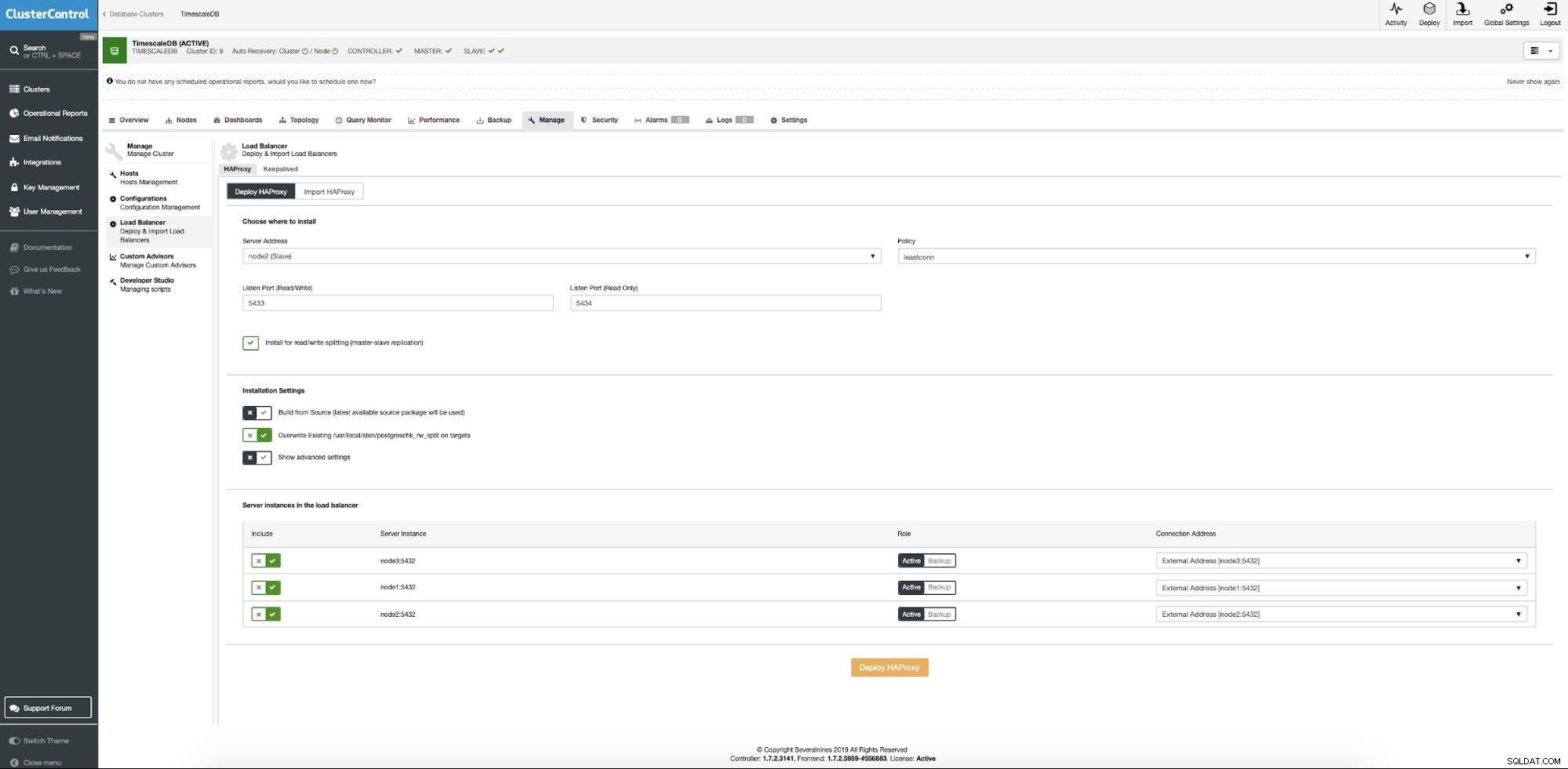
Quando tudo estiver definido, pressione o botão de implantação. Após alguns minutos, devemos preparar nossa configuração de cluster. O ClusterControl cuidará de todos os pré-requisitos e configurações para implantar o balanceador de carga.
Após uma implantação bem-sucedida, podemos ver a topologia do nosso novo cluster; com balanceamento de carga e nós de leitura adicionais. Com mais nós integrados, o ClusterControl habilita automaticamente a recuperação automática. Dessa forma, quando o nó mestre ficar inativo, a operação de failover iniciará sozinha.
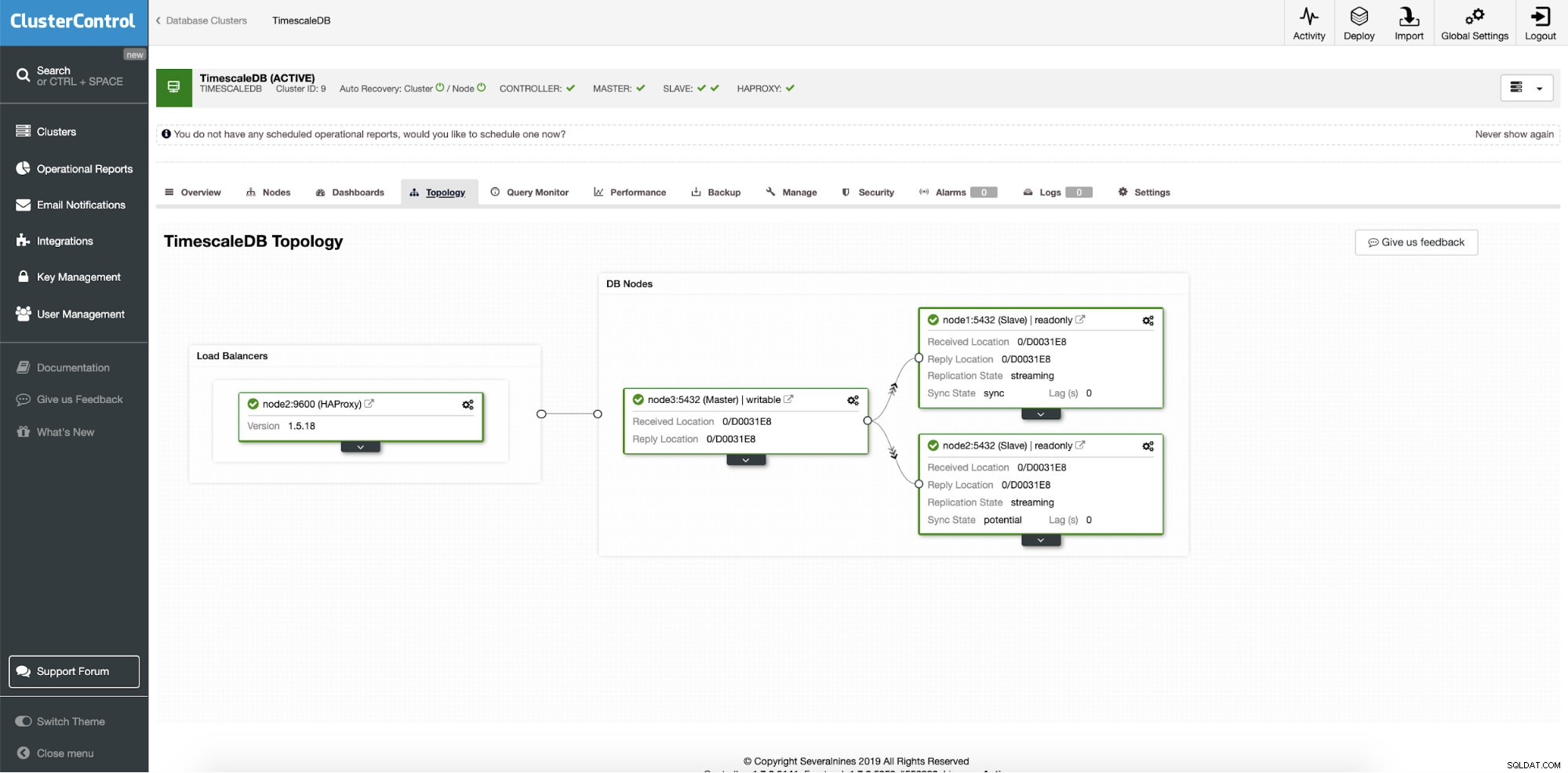 ClusterControl:topologia final
ClusterControl:topologia final Conclusão
TimescaleDB é um banco de dados de código aberto inventado para tornar o SQL escalável para dados de séries temporais. Ter uma maneira automatizada de estender seu cluster é a chave para obter desempenho e eficiência. Como vimos acima, agora você pode dimensionar o TimescaleDB usando o ClusterControl com facilidade.