Em referência ao seu comentário:
@MarcB o banco de dados é normalizado, a string CSV vem da interface do usuário."Obtenha-me dados para as seguintes pessoas:101.202.303"
Esta resposta tem um foco estreito apenas nos números separados por uma vírgula. Porque, como se vê, você nem estava falando sobre
FIND_IN_SET afinal. Sim, você pode alcançar o que deseja. Você cria uma instrução preparada que aceita uma string como um parâmetro como nesta Recente Resposta meu. Nessa resposta, veja o segundo bloco que mostra o
CREATE PROCEDURE e seu segundo parâmetro que aceita uma string como (1,2,3) . Voltarei a este ponto em um momento. Não que você precise ver @spraff, mas outros podem. A missão é obter o
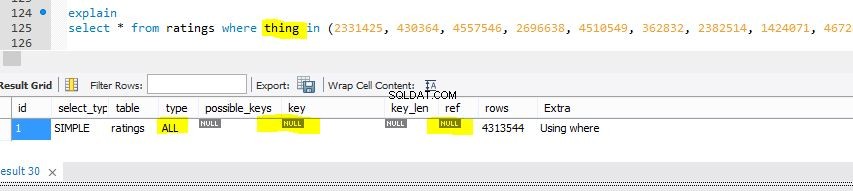
type !=ALL e possible_keys e chaves de Explique para não mostrar null, como você mostrou no seu segundo bloco. Para uma leitura geral sobre o tópico, consulte o artigo Entendendo EXPLAIN a saída
e a página do manual do MySQL intitulada EXPLAIN Informações extras
. Agora, de volta ao
(1,2,3) referência acima. Sabemos pelo seu comentário e pela segunda saída do Explain em sua pergunta que ela atende às seguintes condições desejadas:- type =range (e em particular não ALL) . Consulte os documentos acima sobre isso.
- chave não é nula
Estas são precisamente as condições que você tem em sua segunda saída do Explain e a saída que pode ser vista com a seguinte consulta:
explain
select * from ratings where id in (2331425, 430364, 4557546, 2696638, 4510549, 362832, 2382514, 1424071, 4672814, 291859, 1540849, 2128670, 1320803, 218006, 1827619, 3784075, 4037520, 4135373, ... use your imagination ..., ..., 4369522, 3312835);
onde eu tenho 999 valores nesse
in lista de cláusulas. Essa é uma amostra esta resposta
meu no Apêndice D que gera uma seqüência aleatória de csv, cercada por parênteses de abertura e fechamento. E observe a seguinte saída Explain para esse elemento 999 na cláusula abaixo:

Objetivo alcançado. Você consegue isso com um proc armazenado semelhante ao que mencionei anteriormente neste link usando uma
DECLARAÇÃO PREPARADA
(e essas coisas usam concat() seguido por um EXECUTE ). O índice é usado, um Tablescan (significando ruim) não é experimentado. Outras leituras são O tipo de junção do intervalo , qualquer referência que você encontrar no Cost-Based Optimizer (CBO) do MySQL, esta answer do vladr embora datado, de olho no
ANALISAR TABELA
parte, em particular após mudanças significativas de dados. Observe que ANALYZE pode levar um tempo significativo para ser executado em conjuntos de dados muito grandes. Às vezes muitas horas. Ataques de injeção de SQL:
O uso de strings passadas para Stored Procedures é um vetor de ataque para ataques de SQL Injection. Devem ser tomadas precauções para evitá-los ao usar dados fornecidos pelo usuário. Se sua rotina for aplicada contra seus próprios ids gerados pelo seu sistema, você estará seguro. Observe, no entanto, que os ataques de SQL Injection de 2º nível ocorrem quando os dados foram colocados em prática por rotinas que não sanitizaram esses dados em uma inserção ou atualização anterior. Ataques feitos antes por meio de dados e usados depois (uma espécie de bomba-relógio).
Portanto, esta resposta está Concluída em geral.
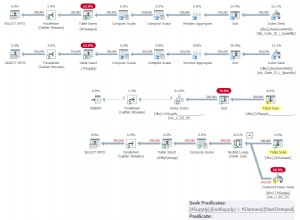
Abaixo está uma visualização da mesma tabela com uma pequena modificação para mostrar o que um temido Tablescan ficaria como na consulta anterior (mas contra uma coluna não indexada chamada
coisa ). Dê uma olhada em nossa definição de tabela atual:
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
select min(id), max(id),count(*) as theCount from ratings;
+---------+---------+----------+
| min(id) | max(id) | theCount |
+---------+---------+----------+
| 1 | 5046213 | 4718592 |
+---------+---------+----------+
Observe que a coluna
coisa era uma coluna int anulável antes. update ratings set thing=id where id<1000000;
update ratings set thing=id where id>=1000000 and id<2000000;
update ratings set thing=id where id>=2000000 and id<3000000;
update ratings set thing=id where id>=3000000 and id<4000000;
update ratings set thing=id where id>=4000000 and id<5100000;
select count(*) from ratings where thing!=id;
-- 0 rows
ALTER TABLE ratings MODIFY COLUMN thing int not null;
-- current table definition (after above ALTER):
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
E então o Explique que é um Tablescan (contra a coluna
coisa ):