A maneira mais rápida de calcular uma mediana usa o SQL Server 2012
OFFSET extensão para o ORDER BY cláusula. Executando um segundo próximo, a próxima solução mais rápida usa um cursor dinâmico (possivelmente aninhado) que funciona em todas as versões. Este artigo analisa um ROW_NUMBER comum anterior a 2012 solução para o problema de cálculo da mediana para ver por que ele tem um desempenho inferior e o que pode ser feito para torná-lo mais rápido. Teste de mediana única
Os dados de amostra para este teste consistem em uma única tabela de dez milhões de linhas (reproduzida do artigo original de Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); A solução OFFSET
Para definir o benchmark, aqui está a solução OFFSET do SQL Server 2012 (ou posterior) criada por Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); A consulta para contar as linhas na tabela é comentada e substituída por um valor codificado permanentemente para se concentrar no desempenho do código principal. Com um cache quente e uma coleção de planos de execução desativados, essa consulta é executada por 910 ms em média na minha máquina de teste. O plano de execução é mostrado abaixo:

Como observação lateral, é interessante que essa consulta moderadamente complexa se qualifique para um plano trivial:
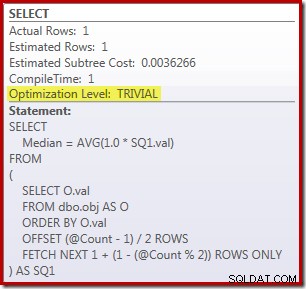
A solução ROW_NUMBER
Para sistemas que executam o SQL Server 2008 R2 ou anterior, a solução alternativa de melhor desempenho usa um cursor dinâmico, conforme mencionado anteriormente. Se você não puder (ou não quiser) considerar isso como uma opção, é natural pensar em emular o
OFFSET de 2012 plano de execução usando ROW_NUMBER . A ideia básica é numerar as linhas na ordem apropriada e filtrar apenas uma ou duas linhas necessárias para calcular a mediana. Existem várias maneiras de escrever isso no Transact SQL; uma versão compacta que captura todos os elementos-chave é a seguinte:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O plano de execução resultante é bastante semelhante ao
OFFSET versão:
Vale a pena olhar para cada uma das operadoras de planos para entendê-los completamente:
- O operador Segmento é redundante neste plano. Seria necessário se o
ROW_NUMBERfunção de classificação tinha umPARTITION BYcláusula, mas não. Mesmo assim, permanece no plano final. - O Projeto de sequência adiciona um número de linha calculado ao fluxo de linhas.
- O Compute Scalar define uma expressão associada à necessidade de converter implicitamente o
valcoluna para numérico para que possa ser multiplicado pelo literal constante1.0na consulta. Esse cálculo é adiado até ser necessário por um operador posterior (que é o Stream Aggregate). Essa otimização de tempo de execução significa que a conversão implícita é executada apenas para as duas linhas processadas pelo Stream Aggregate, não para as 5.000.001 linhas indicadas para o Compute Scalar. - O operador Top é introduzido pelo otimizador de consulta. Ele reconhece que, no máximo, apenas o primeiro
(@Count + 2) / 2as linhas são necessárias para a consulta. Poderíamos ter adicionado umTOP ... ORDER BYna subconsulta para tornar isso explícito, mas essa otimização torna isso bastante desnecessário. - O filtro implementa a condição em
WHEREcláusula, filtrando todas, exceto as duas linhas 'intermediárias' necessárias para calcular a mediana (o Top introduzido também é baseado nessa condição). - O Stream Aggregate calcula a
SUMeCOUNTdas duas linhas medianas. - O Compute Scalar final calcula a média da soma e da contagem.
Desempenho bruto
Comparado com o
OFFSET plano, podemos esperar que os operadores adicionais de Segmento, Projeto de Sequência e Filtro tenham algum efeito adverso no desempenho. Vale a pena reservar um momento para comparar a estimativa custos dos dois planos: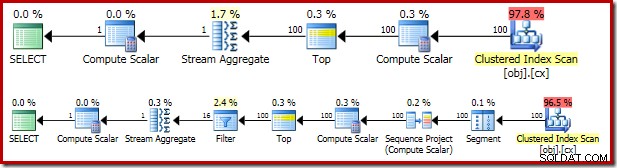
O
OFFSET plano tem um custo estimado de 0,0036266 unidades, enquanto o ROW_NUMBER o plano é estimado em 0,0036744 unidades. Estes são números muito pequenos, e há pouca diferença entre os dois. Portanto, talvez seja surpreendente que o
ROW_NUMBER a consulta realmente é executada por 4000 ms em média, em comparação com 910 ms média para o OFFSET solução. Parte desse aumento certamente pode ser explicado pela sobrecarga das operadoras de planos extras, mas um fator de quatro parece excessivo. Deve haver mais do que isso. Você provavelmente também notou que as estimativas de cardinalidade para ambos os planos estimados acima estão totalmente erradas. Isso se deve ao efeito dos operadores Top, que têm uma expressão que faz referência a uma variável como seus limites de contagem de linhas. O otimizador de consulta não pode ver o conteúdo das variáveis no momento da compilação, portanto, ele recorre à estimativa padrão de 100 linhas. Ambos os planos realmente encontram 5.000.001 linhas em tempo de execução.
Isso tudo é muito interessante, mas não explica diretamente por que o
ROW_NUMBER a consulta é mais de quatro vezes mais lenta que o OFFSET versão. Afinal, a estimativa de cardinalidade de 100 linhas está igualmente errada em ambos os casos. Melhorar o desempenho da solução ROW_NUMBER
No meu artigo anterior, vimos como o desempenho da mediana agrupada
OFFSET teste pode ser quase duplicado simplesmente adicionando um PAGLOCK dica. Essa dica substitui a decisão normal do mecanismo de armazenamento de adquirir e liberar bloqueios compartilhados na granularidade da linha (devido à baixa cardinalidade esperada). Como um lembrete adicional, o
PAGLOCK dica era desnecessária na única mediana OFFSET teste devido a uma otimização interna separada que pode ignorar bloqueios compartilhados no nível da linha, resultando em apenas um pequeno número de bloqueios compartilhados por intenção sendo realizados no nível da página. Podemos esperar o
ROW_NUMBER solução mediana única para se beneficiar da mesma otimização interna, mas isso não acontece. Monitorando a atividade de bloqueio enquanto o ROW_NUMBER consulta é executada, vemos mais de meio milhão de bloqueios compartilhados em nível de linha individual sendo levado e liberado. Esse é o problema das otimizações internas não documentadas:nunca podemos ter certeza de quando elas serão aplicadas ou não.
Então, agora que sabemos qual é o problema, podemos melhorar o desempenho do bloqueio da mesma forma que fizemos anteriormente:ou com um
PAGLOCK dica de granularidade de bloqueio ou aumentando a estimativa de cardinalidade usando o sinalizador de rastreamento documentado 4138. Desabilitar o "objetivo de linha" usando o sinalizador de rastreamento é a solução menos satisfatória por vários motivos. Primeiro, só é eficaz no SQL Server 2008 R2 ou posterior. Provavelmente preferiríamos o
OFFSET solução no SQL Server 2012, portanto, isso limita efetivamente a correção do sinalizador de rastreamento somente ao SQL Server 2008 R2. Em segundo lugar, a aplicação do sinalizador de rastreamento requer permissões em nível de administrador, a menos que seja aplicado por meio de um guia de plano. Uma terceira razão é que desabilitar metas de linha para toda a consulta pode ter outros efeitos indesejáveis, especialmente em planos mais complexos. Por outro lado, o
PAGLOCK A dica é eficaz, está disponível em todas as versões do SQL Server sem nenhuma permissão especial e não tem nenhum efeito colateral importante além da granularidade de bloqueio. Aplicando o
PAGLOCK dica para o ROW_NUMBER consulta aumenta drasticamente o desempenho:de 4000 ms para 1500 ms: DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Os 1500 ms o resultado ainda é significativamente mais lento do que os 910 ms para o
OFFSET solução, mas pelo menos está agora no mesmo patamar. O diferencial de desempenho restante se deve simplesmente ao trabalho extra no plano de execução:
No
OFFSET No plano, cinco milhões de linhas são processadas até o topo (com as expressões definidas no Compute Scalar adiadas conforme discutido anteriormente). No ROW_NUMBER plano, o mesmo número de linhas deve ser processado pelo segmento, projeto de sequência, superior e filtro.