O Moodle, um Sistema de Gerenciamento de Aprendizagem de código aberto, tornou-se cada vez mais popular no ano passado, quando a pandemia forçou bloqueios rígidos e a maioria das atividades educacionais mudou de escolas, faculdades e universidades para plataformas online. Com isso, foi colocada uma pressão sobre as equipes de TI para garantir que essas plataformas online sejam capazes de acomodar uma carga muito maior do que costumavam experimentar. Questões foram levantadas - como uma plataforma Moodle pode ser dimensionada para lidar com o aumento da carga? Por um lado, dimensionar o aplicativo em si não é uma tarefa difícil de realizar, mas o banco de dados, por outro lado, é um animal diferente. Bancos de dados, como todos os serviços com estado, são notoriamente difíceis de escalar horizontalmente. Nesta postagem do blog, gostaríamos de discutir alguns desafios que você enfrentará ao dimensionar um banco de dados Moodle.
Scaling Moodle database - The Challenge
A principal fonte de problemas é o patrimônio - o Moodle, assim como muitos bancos de dados, vem de um único banco de dados e, como tal, vem com algumas expectativas relacionadas a esse ambiente. O típico é que você pode executar uma transação após a outra e a segunda transação sempre verá o resultado da primeira. Este não é necessariamente o caso na maioria dos ambientes de banco de dados distribuídos. A replicação assíncrona não faz promessas. Qualquer transação pode se perder no processo. É suficiente que o mestre falhe antes que os dados da transação sejam transferidos para os escravos. A replicação semisíncrona traz a promessa de segurança de dados, mas não promete mais nada. Os escravos ainda podem estar atrasados e, embora os dados sejam armazenados em armazenamento persistente como um log de retransmissão e, eventualmente, sejam aplicados ao conjunto de dados, isso ainda não significa que já tenham sido aplicados. Você pode consultar seus escravos e não ver os dados que acabou de gravar no mestre.
Mesmo clusters como Galera, por padrão, não vêm com a replicação verdadeiramente síncrona - a lacuna é significativamente reduzida em comparação com os sistemas de replicação, mas ainda está lá e o SELECT imediato executado após uma gravação anterior pode não ver o dados que você acabou de armazenar no banco de dados porque seu SELECT foi roteado para um nó Galera diferente da sua gravação anterior.
Existem várias soluções alternativas que você pode usar para dimensionar o banco de dados MySQL do Moodle. Para começar, se você usar a configuração de replicação, poderá usar o recurso “leituras seguras” do Moodle. Cobrimos isso em um de nossos blogs anteriores. Isso levará à situação em que o Moodle decidirá quais gravações serão distribuídas pelos escravos e quais atingirão o mestre.
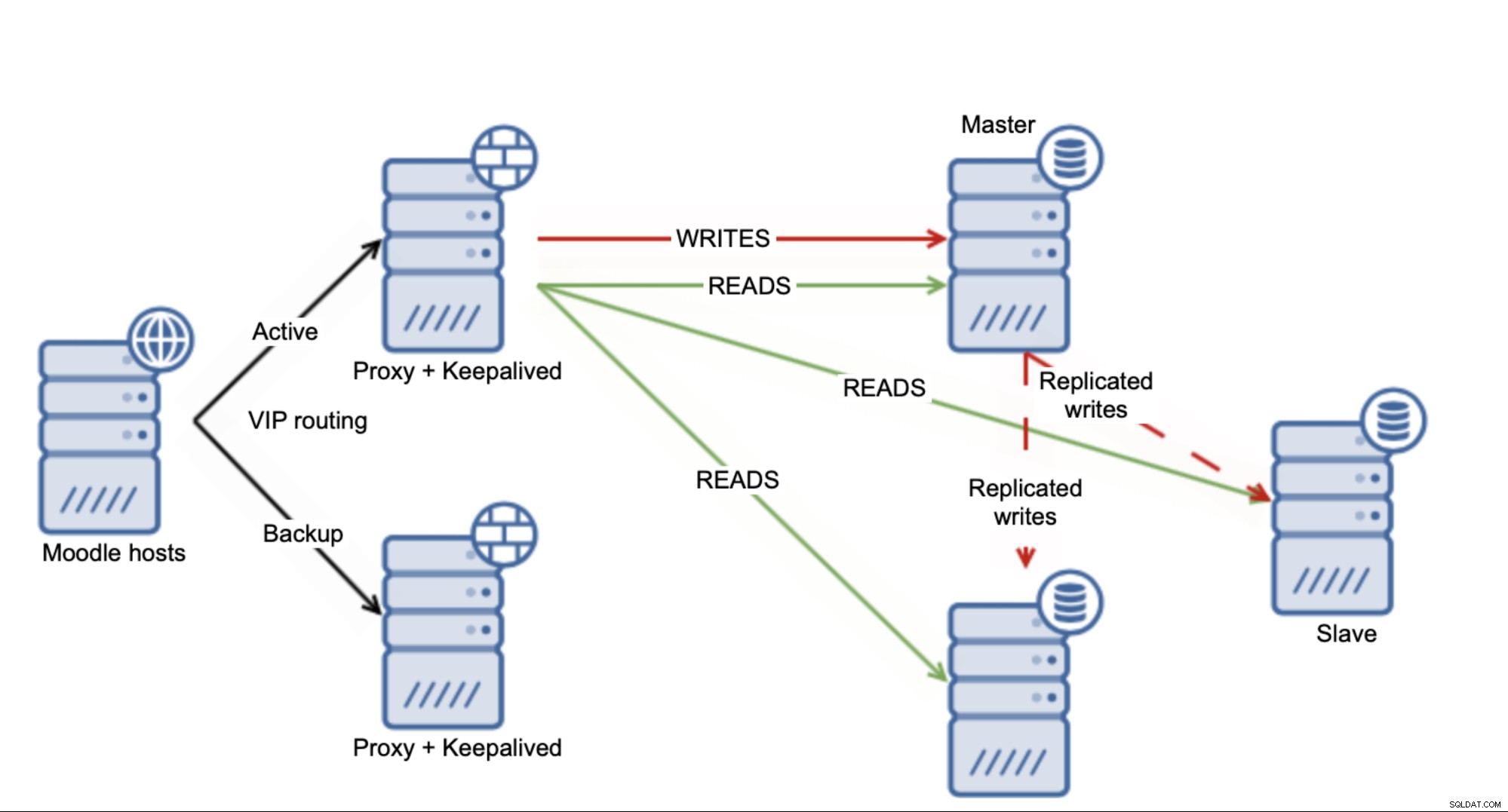
Por um lado é bom - você está seguro para usar vários escravos anexados para o mestre, permitindo que você descarregue o mestre pelo menos até certo ponto. Por outro lado, está longe de ser o ideal, pois é apenas um subconjunto de SELECTs que você poderá enviar para os escravos. Claro, tudo depende do caso exato, mas você pode esperar que o mestre continue sendo um gargalo em relação à carga.
Uma abordagem alternativa pode ser usar o Galera Cluster e distribuir a carga uniformemente por todos os nós.
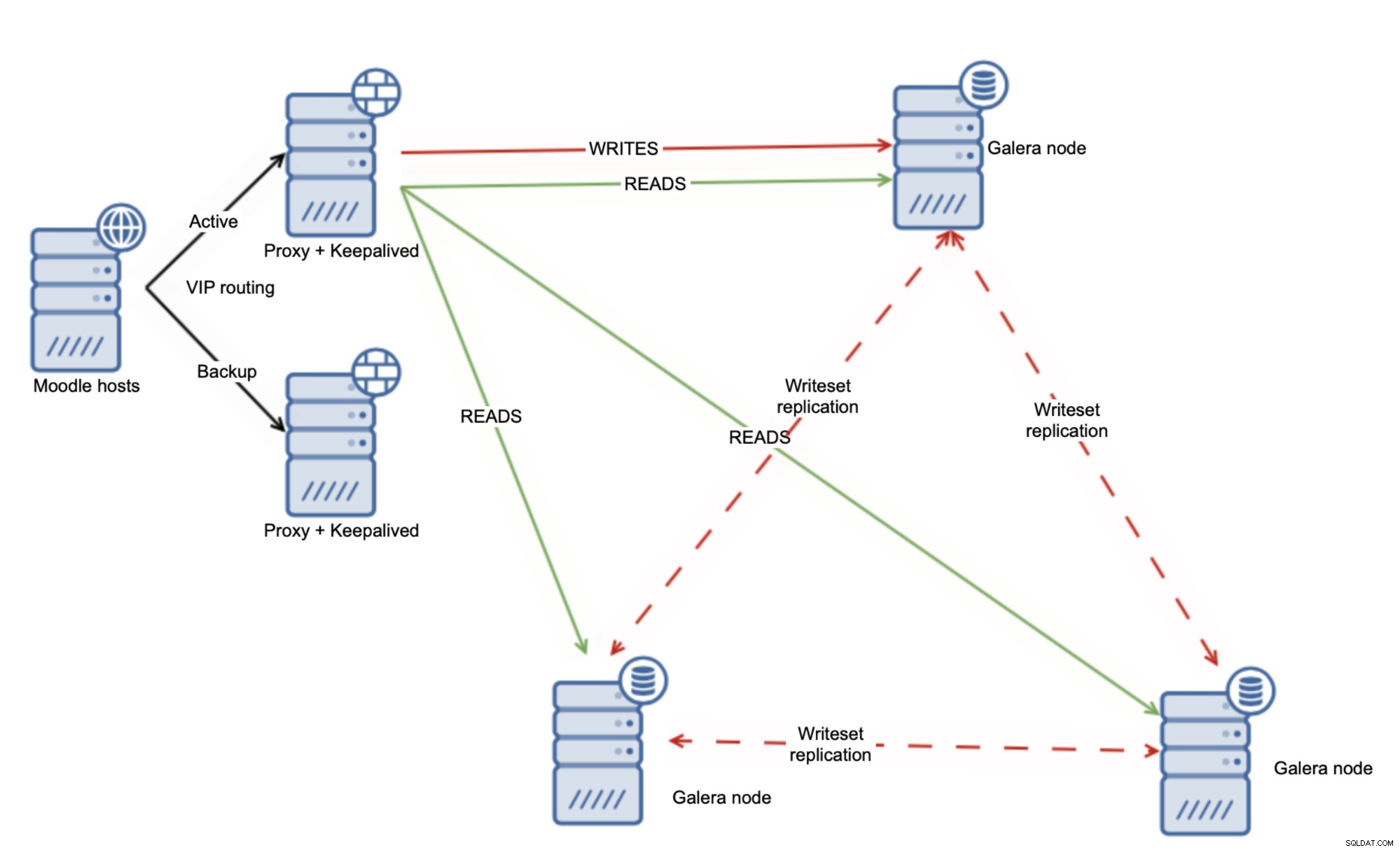
Por si só, isso não é suficiente para lidar com todas as leituras posteriores -write, mas felizmente você pode usar a variável wsrep-sync-wait, que pode ser usada para garantir que as verificações de causalidade estejam em vigor e que o cluster se comporte como um cluster síncrono real. Usar esta configuração permitirá que você leia com segurança de todos os seus nós Galera.
É claro que aplicar verificações de causalidade afetará o desempenho do Galera, mas ainda faz sentido, pois você pode se beneficiar da leitura de vários nós do Galera ao mesmo tempo. A partir desse ponto, o dimensionamento de leituras com o Galera Cluster é bastante fácil - basta adicionar mais nós Galera ao cluster. O Load Balancer deve ser reconfigurado para pegá-los e usá-los como um destino adicional para as leituras, permitindo que você dimensione até mais de 10 nós de leitor.
Você deve ter em mente que adicionar nós adicionais, replicação ou Galera, não importa, adiciona alguma complexidade às operações no cluster. Você precisa garantir que seus nós sejam monitorados adequadamente, que os backups estejam funcionando, que a replicação esteja funcionando corretamente e que o próprio cluster esteja em um estado correto. Para ambientes de replicação, o failover deve ser tratado de uma forma ou de outra e, tanto para o Galera quanto para a replicação, você pode querer reconstruir os nós no cluster se detectar qualquer tipo de inconsistência de dados no cluster. Felizmente, o ClusterControl pode ajudá-lo significativamente a lidar com esses desafios.
Como o ClusterControl ajuda a gerenciar o cluster de banco de dados MySQL do Moodle
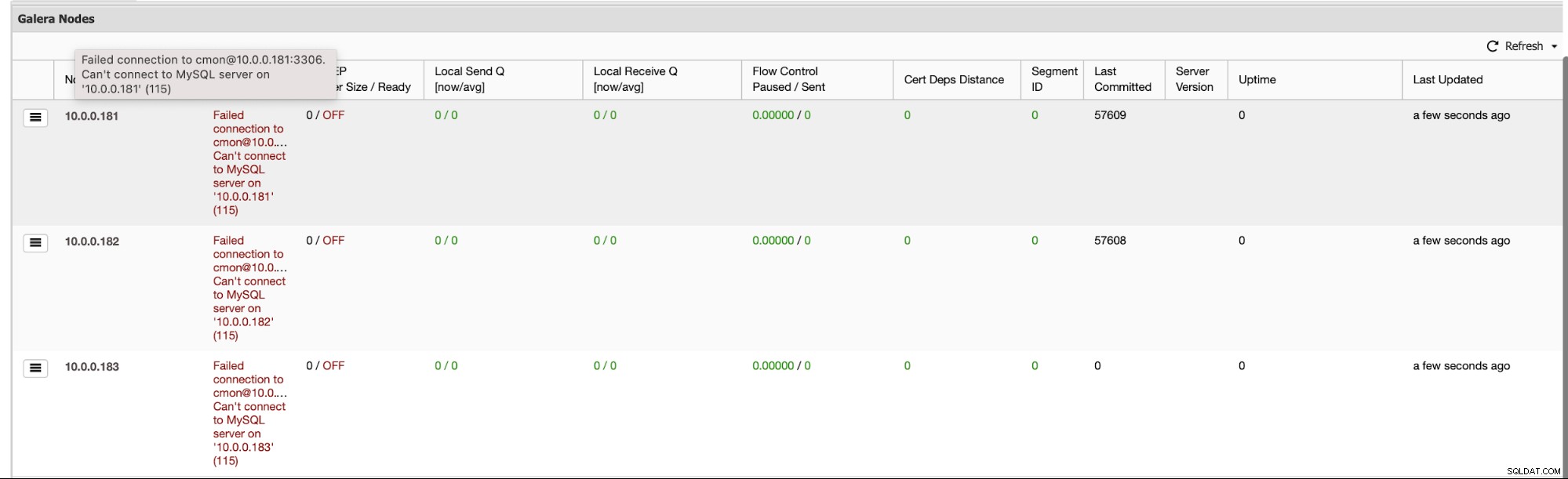
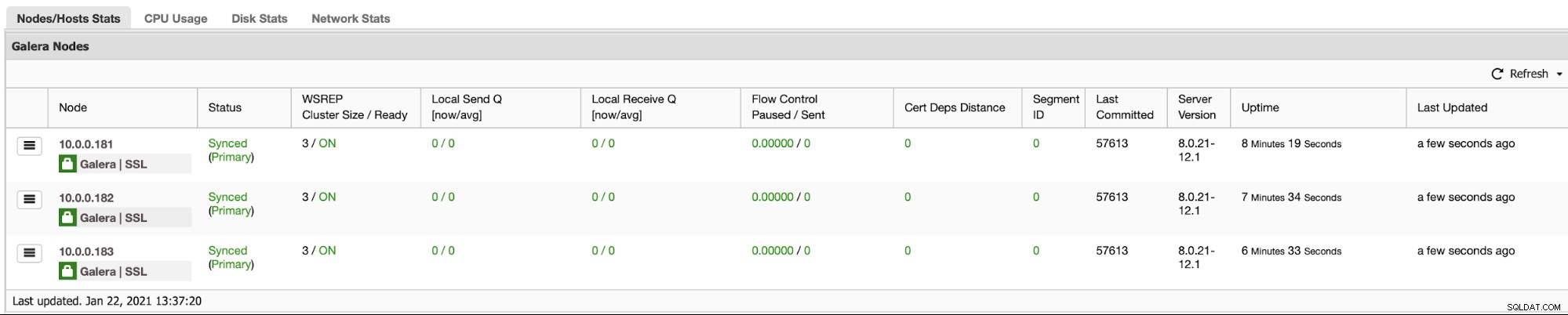
Em primeiro lugar, se todo o cluster entrar em colapso, o ClusterControl executará uma recuperação de cluster - desde que todos os nós estejam disponíveis, o ClusterControl iniciará o processo de recuperação de cluster:

Depois de algum tempo, todo o cluster deve estar novamente online.
ClusterControl vem com um conjunto de opções de gerenciamento:
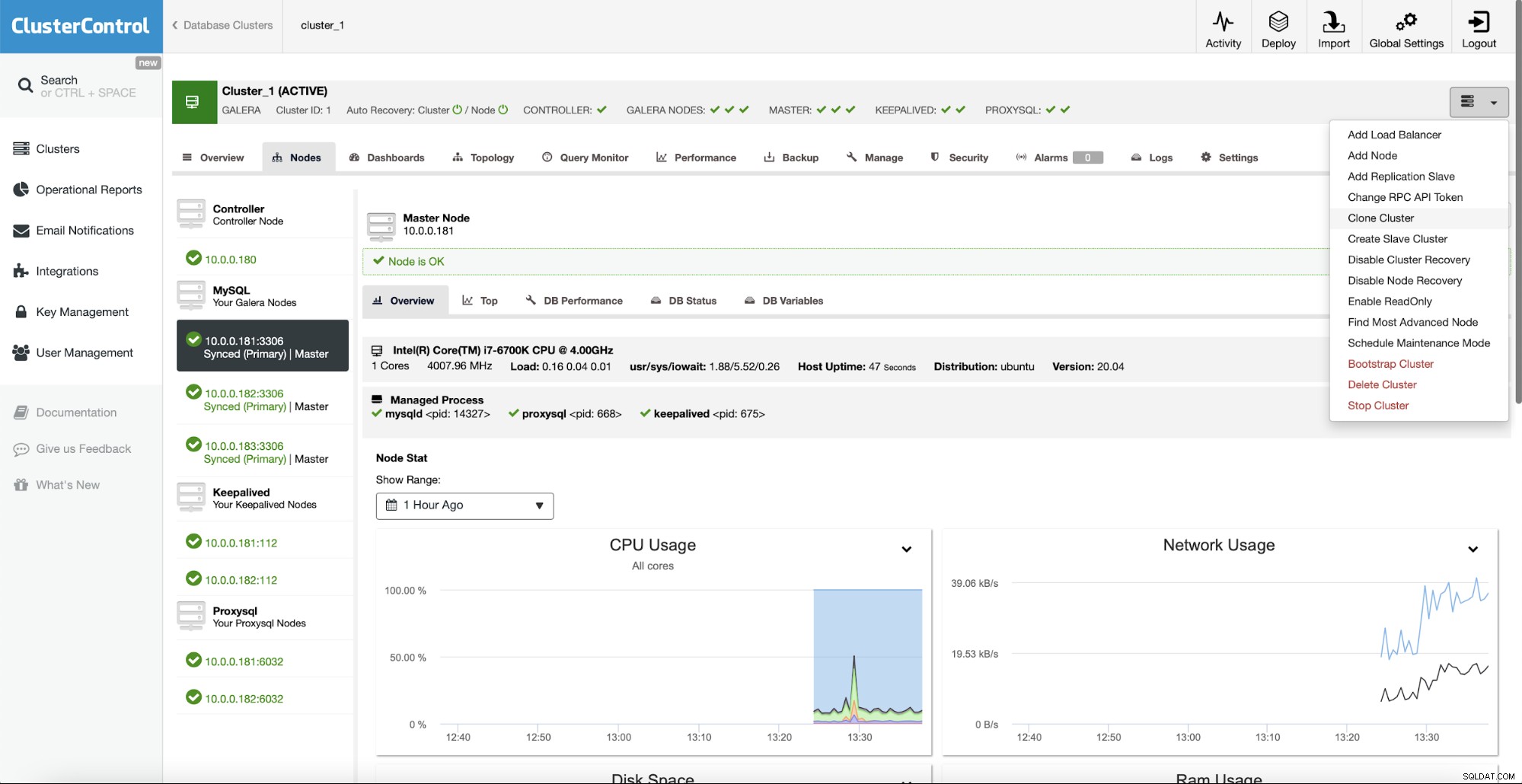
Você pode dimensionar o cluster adicionando nós ou escravos de replicação. Você pode até criar um cluster escravo inteiro que será replicado no cluster principal.
É possível configurar facilmente um agendamento de backup que será executado pelo ClusterControl. Você pode até configurar a verificação de backup automatizada.
Você provavelmente deseja monitorar seu cluster de banco de dados. ClusterControl permite que você faça exatamente isso:
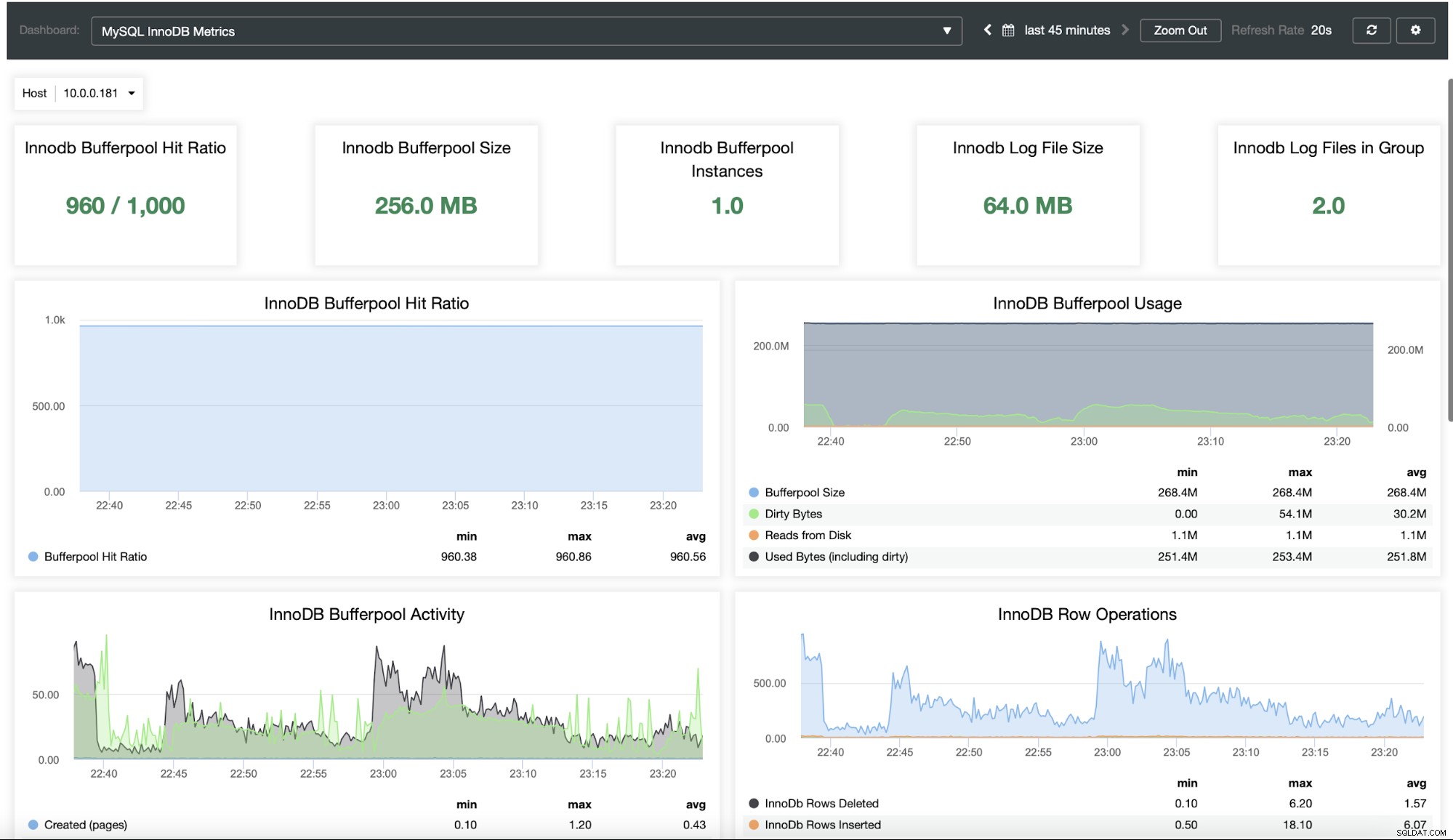
Como você pode ver, o ClusterControl é uma ótima plataforma que pode ser usada para reduzir a complexidade de dimensionar e gerenciar o banco de dados MySQL do Moodle. Gostaríamos muito de ouvir sobre sua experiência com o dimensionamento do Moodle e seu banco de dados em particular.