A necessidade de obter alta disponibilidade de banco de dados é uma tarefa bastante comum e, muitas vezes, obrigatória. Se sua empresa tiver um orçamento limitado, manter um escravo de replicação (ou mais de um) que esteja sendo executado no mesmo provedor de nuvem (apenas esperando se for necessário algum dia) pode ser caro. Dependendo do tipo de aplicação, existem alguns casos em que um escravo de replicação é necessário para melhorar o RTO (Recovery Time Objective).
Existe outra opção, no entanto, se sua empresa puder aceitar um pequeno atraso para colocar seus sistemas online novamente.
Cold Standby, é um método de redundância onde você tem um nó em espera (como backup) para o primário. Este nó é usado apenas durante uma falha principal. No restante do tempo, o nó cold standby é desligado e usado apenas para carregar um backup quando necessário.
Para usar esse método, é necessário ter uma política de backup predefinida (com redundância) de acordo com um RPO (objetivo de ponto de recuperação) aceitável para a empresa. Pode ser que perder 12 horas de dados seja aceitável para o negócio ou perder apenas uma hora possa ser um grande problema. Cada empresa e aplicativo deve determinar seu próprio padrão.
Neste blog, você aprenderá como criar uma política de backup e como restaurá-la em um Cold Standby Server usando o ClusterControl e sua integração com a Amazon AWS.
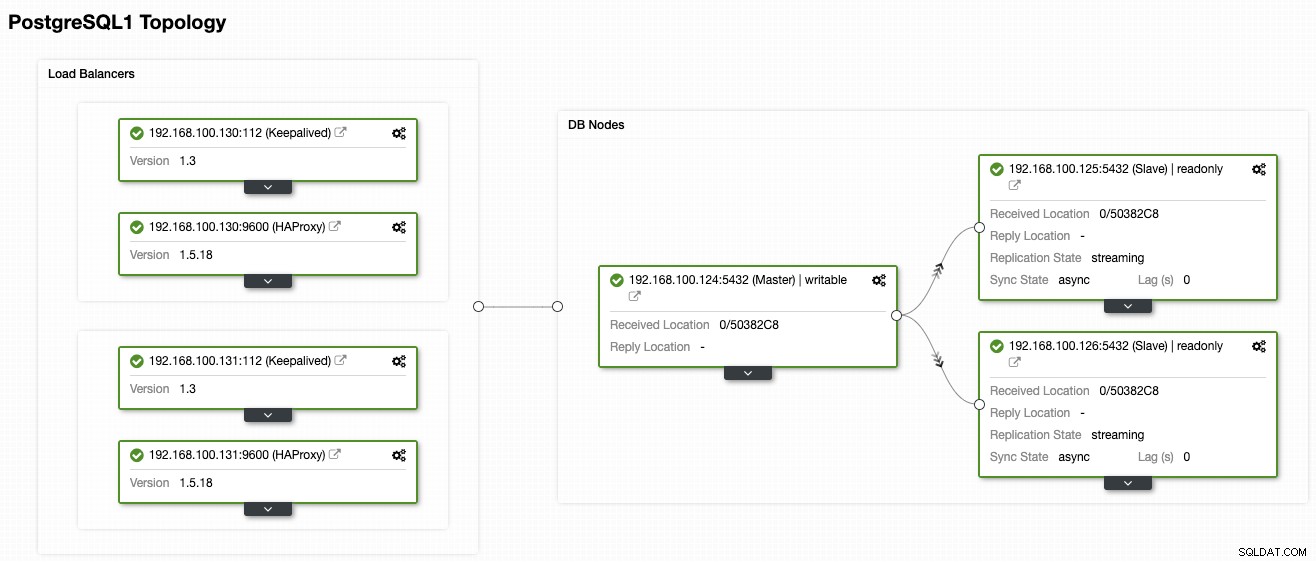
Para este blog, vamos supor que você já tenha uma conta da AWS e o ClusterControl instalado. Enquanto vamos usar a AWS como provedor de nuvem neste exemplo, você pode usar um diferente. Usaremos a seguinte topologia PostgreSQL implantada usando ClusterControl:
- 1 Nó Primário PostgreSQL
- 2 nós de espera ativa do PostgreSQL
- 2 balanceadores de carga (HAProxy + Keepalived)
Criando uma política de backup aceitável
A melhor prática para criar esse tipo de política é armazenar os arquivos de backup em três locais diferentes, um armazenado localmente no servidor de banco de dados (para recuperação mais rápida), outro em um servidor de backup centralizado e o último na nuvem.
Você pode melhorar isso também usando backups completos, incrementais e diferenciais. Com o ClusterControl você pode realizar todas as melhores práticas acima, todas no mesmo sistema, com uma interface amigável e fácil de usar. Vamos começar criando a integração da AWS no ClusterControl.
Configurando a integração ClusterControl AWS
Vá para ClusterControl -> Integrações -> Provedores de Nuvem -> Adicionar Credenciais de Nuvem.
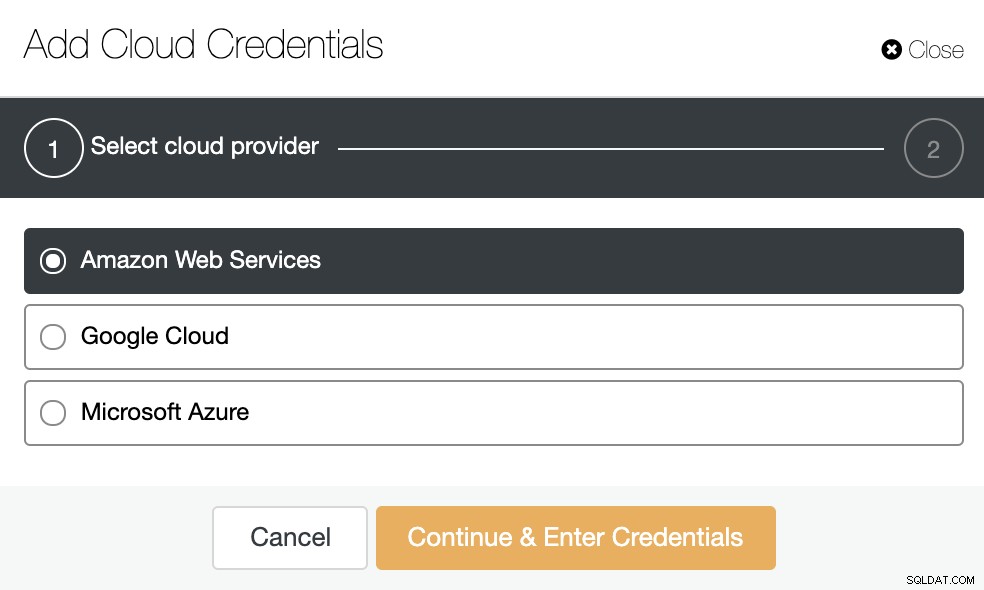
Escolha um provedor de nuvem. Apoiamos AWS, Google Cloud ou Azure. Nesse caso, escolha AWS e continue.
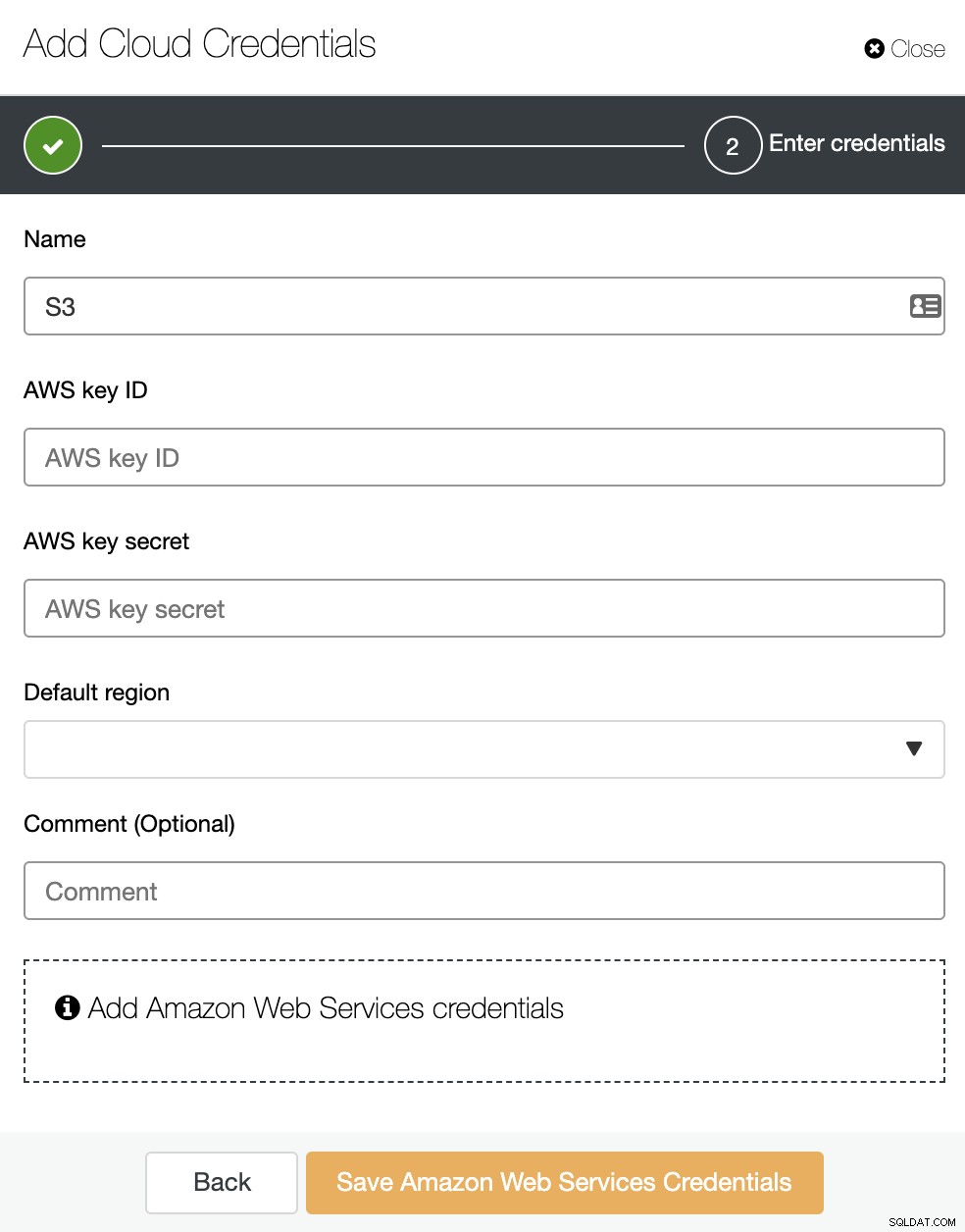
Aqui você precisa adicionar um nome, uma região padrão e uma AWS ID da chave e segredo da chave. Para obter ou criar esses últimos, você deve acessar a seção IAM (Identity and Access Management) no console de gerenciamento da AWS. Para obter mais informações, você pode consultar nossa documentação ou a documentação da AWS.
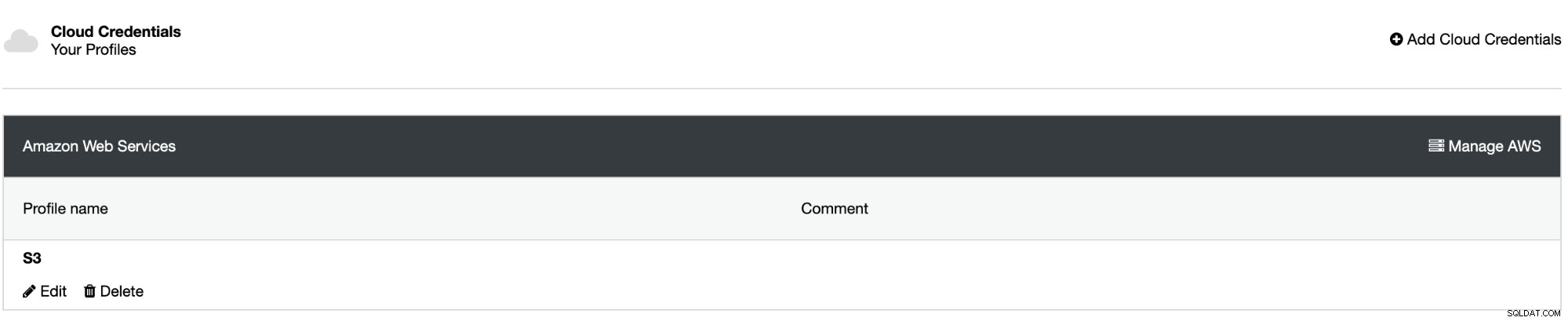
Agora que você criou a integração, vamos agendar o primeiro backup usando ClusterControl.
Agendando um backup com ClusterControl
Vá para ClusterControl -> Selecione o PostgreSQL Cluster -> Backup -> Criar Backup.
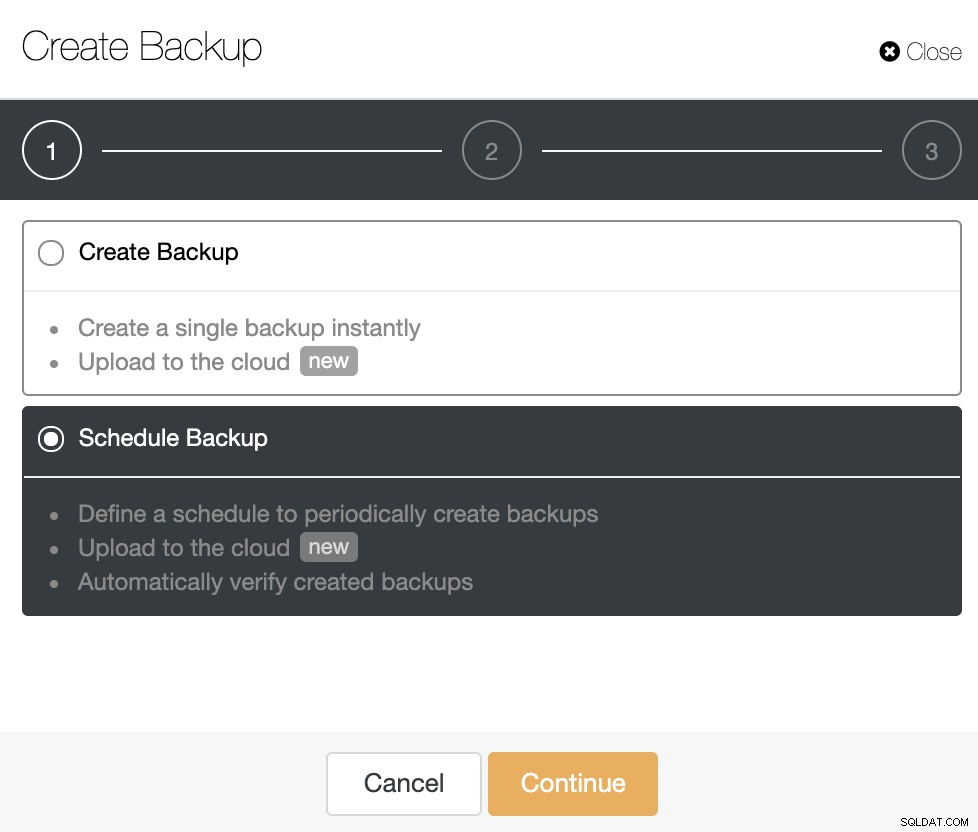
Você pode escolher se deseja criar um único backup instantaneamente ou agendar um novo backup. Então, vamos escolher a segunda opção e continuar.
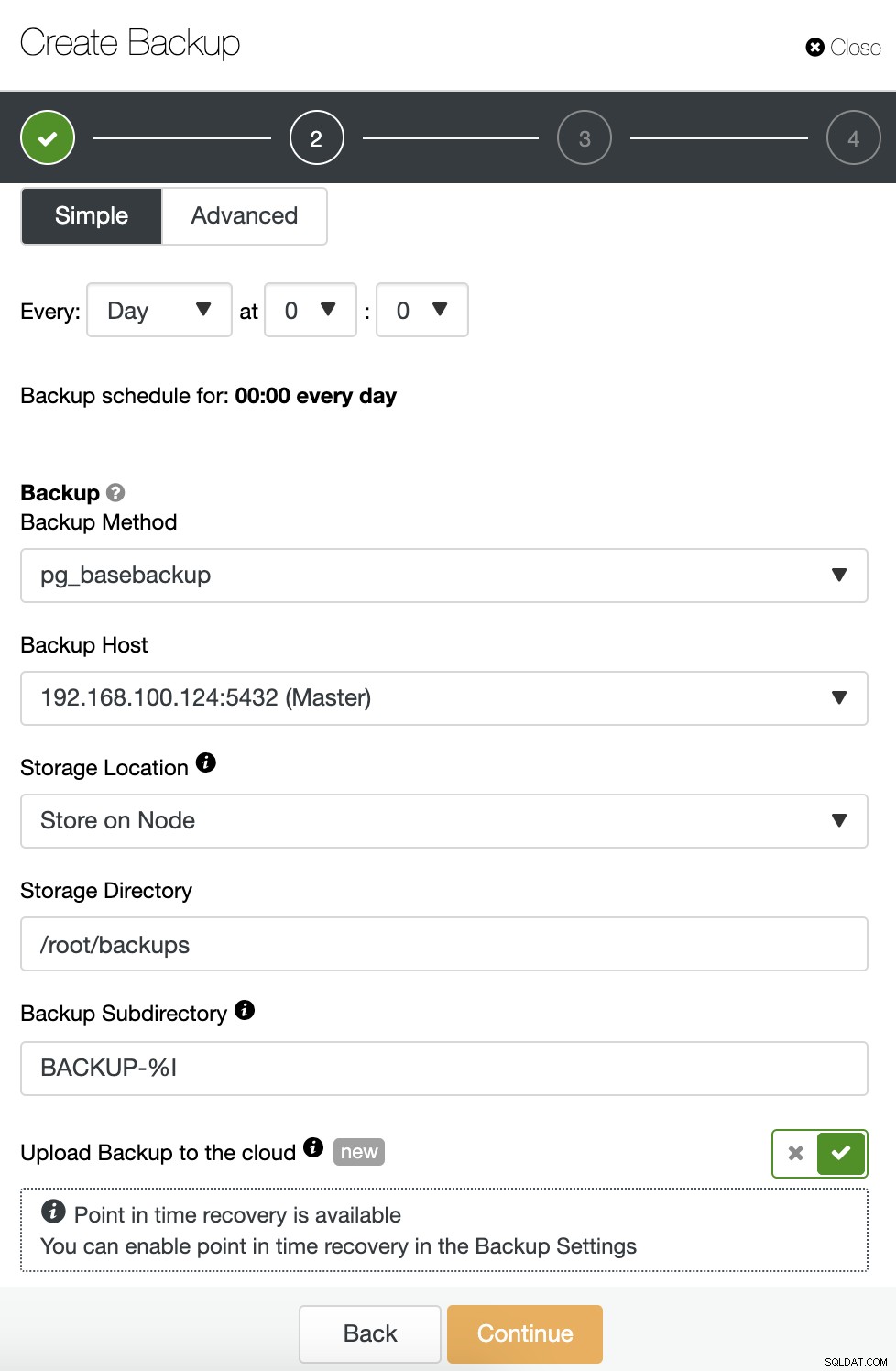
Ao agendar um backup, primeiro você precisa especificar o agendamento /frequência. Em seguida, você deve escolher um método de backup (pg_dumpall, pg_basebackup, pgBackRest), o servidor do qual o backup será feito e onde deseja armazenar o backup. Você também pode enviar nosso backup para a nuvem (AWS, Google ou Azure) ativando o botão correspondente.
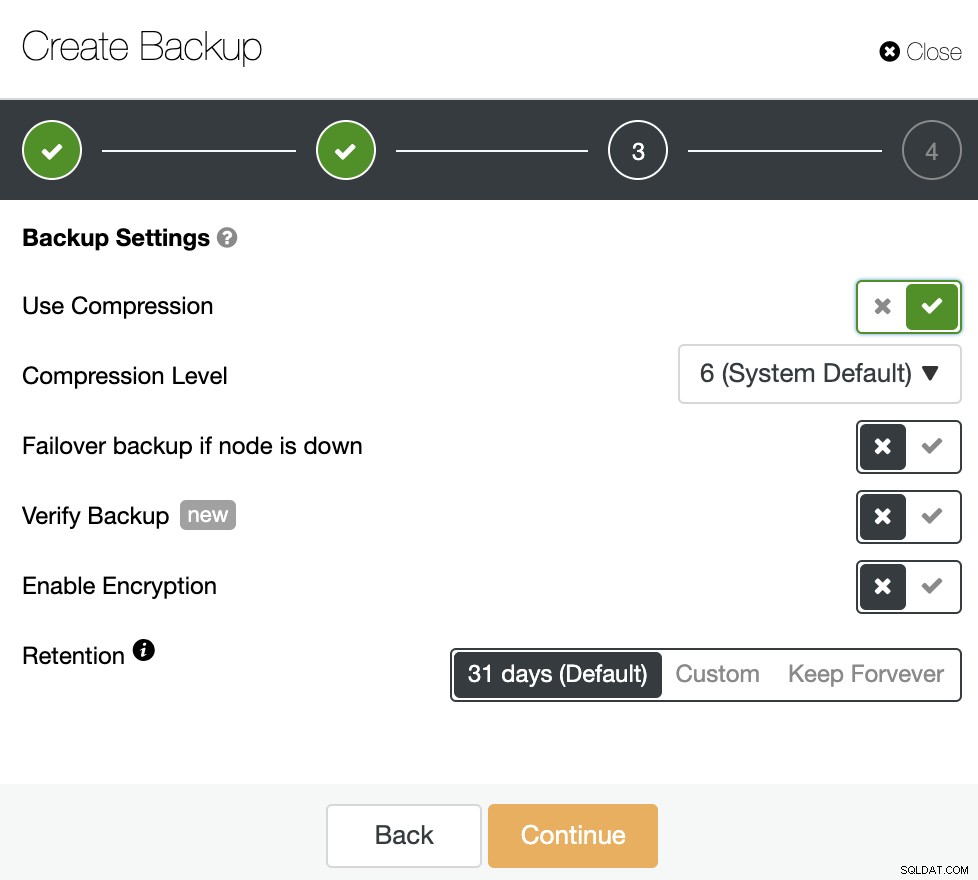
Em seguida, especifique o uso da compactação, o nível de compactação, a criptografia e o período de retenção para seu backup. Há outro recurso chamado “Verificar backup” que você verá mais detalhadamente em breve nesta postagem do blog.
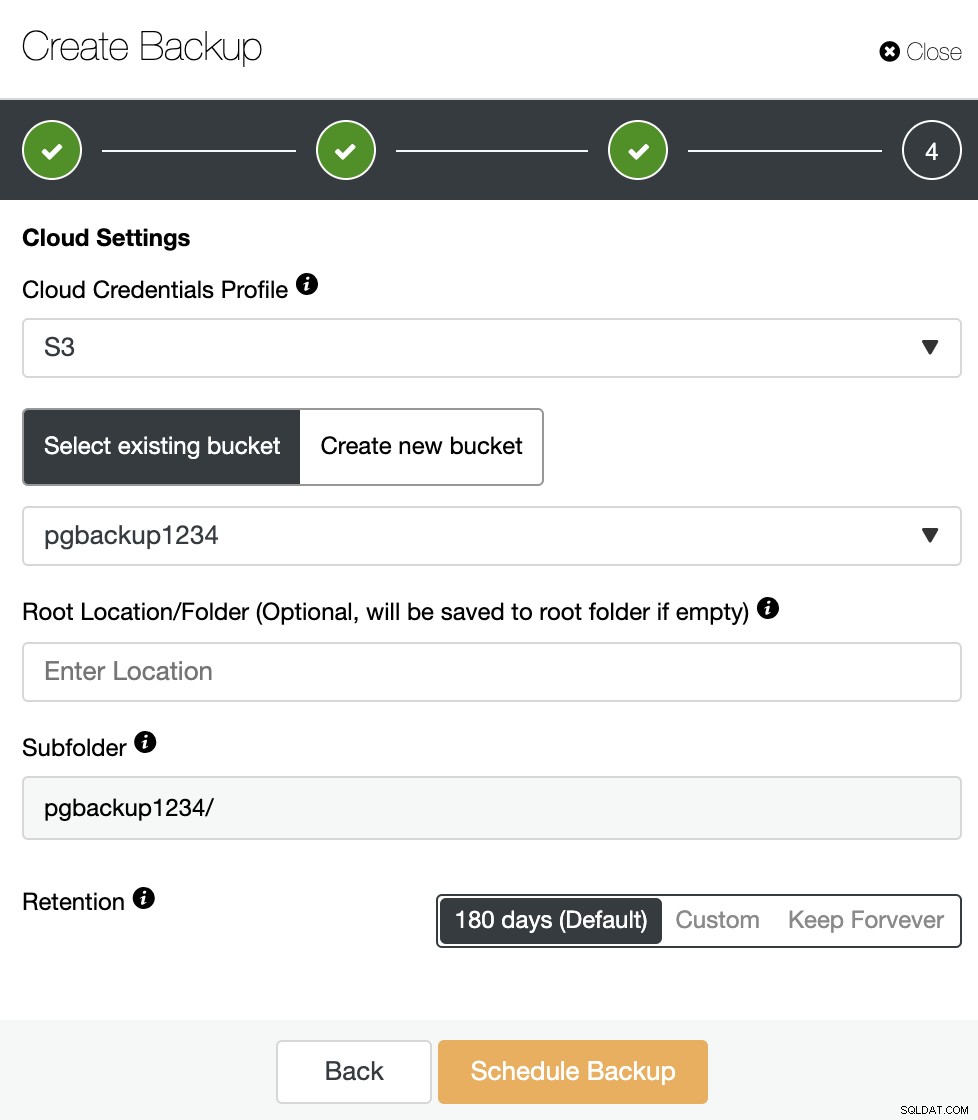
Se a opção “Upload Backup to the cloud” estiver habilitada, você ' Veremos esta etapa onde você deve selecionar as credenciais da nuvem e criar ou selecionar um bucket do S3 onde armazenar o backup. Você também deve especificar o período de retenção.
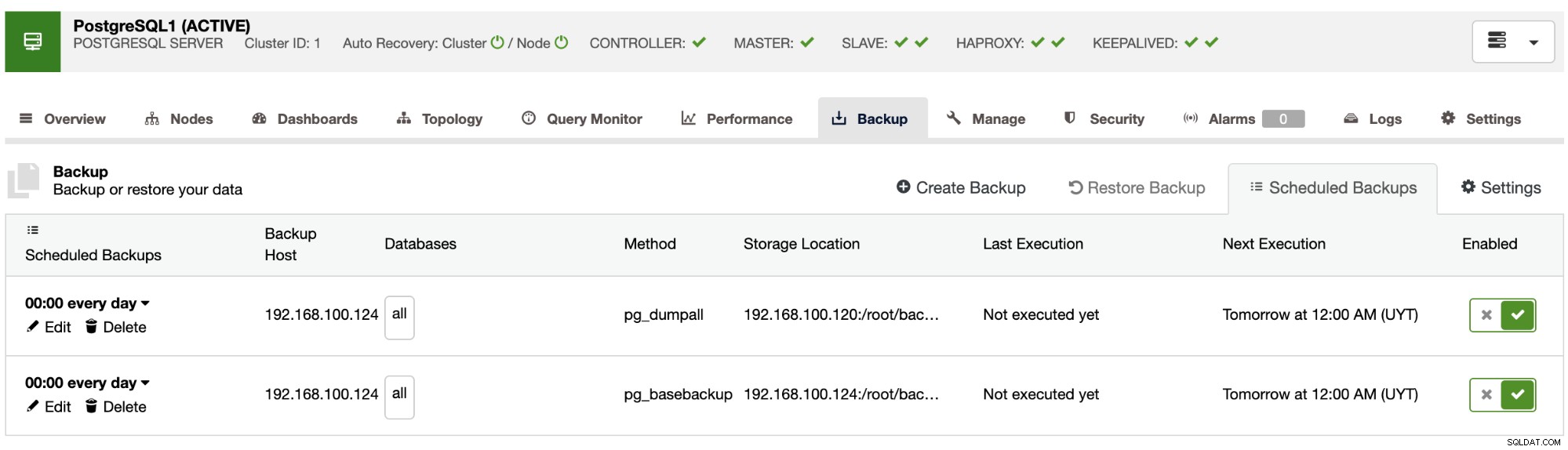
Agora você terá o backup agendado na seção ClusterControl Schedule Backups. Para cobrir as práticas recomendadas mencionadas anteriormente, você pode agendar um backup para armazená-lo em um servidor externo (servidor ClusterControl) e na nuvem e, em seguida, agendar outro backup para armazená-lo localmente no nó do banco de dados para uma recuperação mais rápida.
Restaurando um backup no Amazon EC2
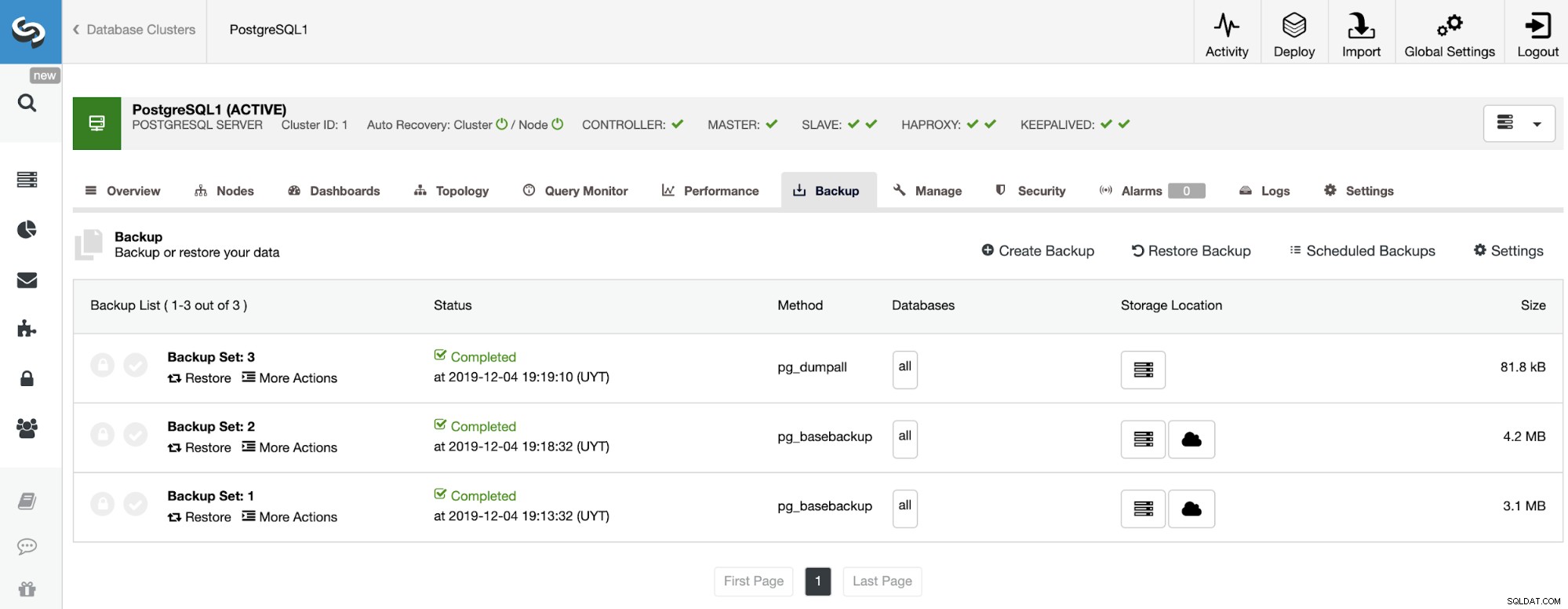
Quando o backup estiver concluído, você poderá restaurá-lo usando ClusterControl na seção Backup.
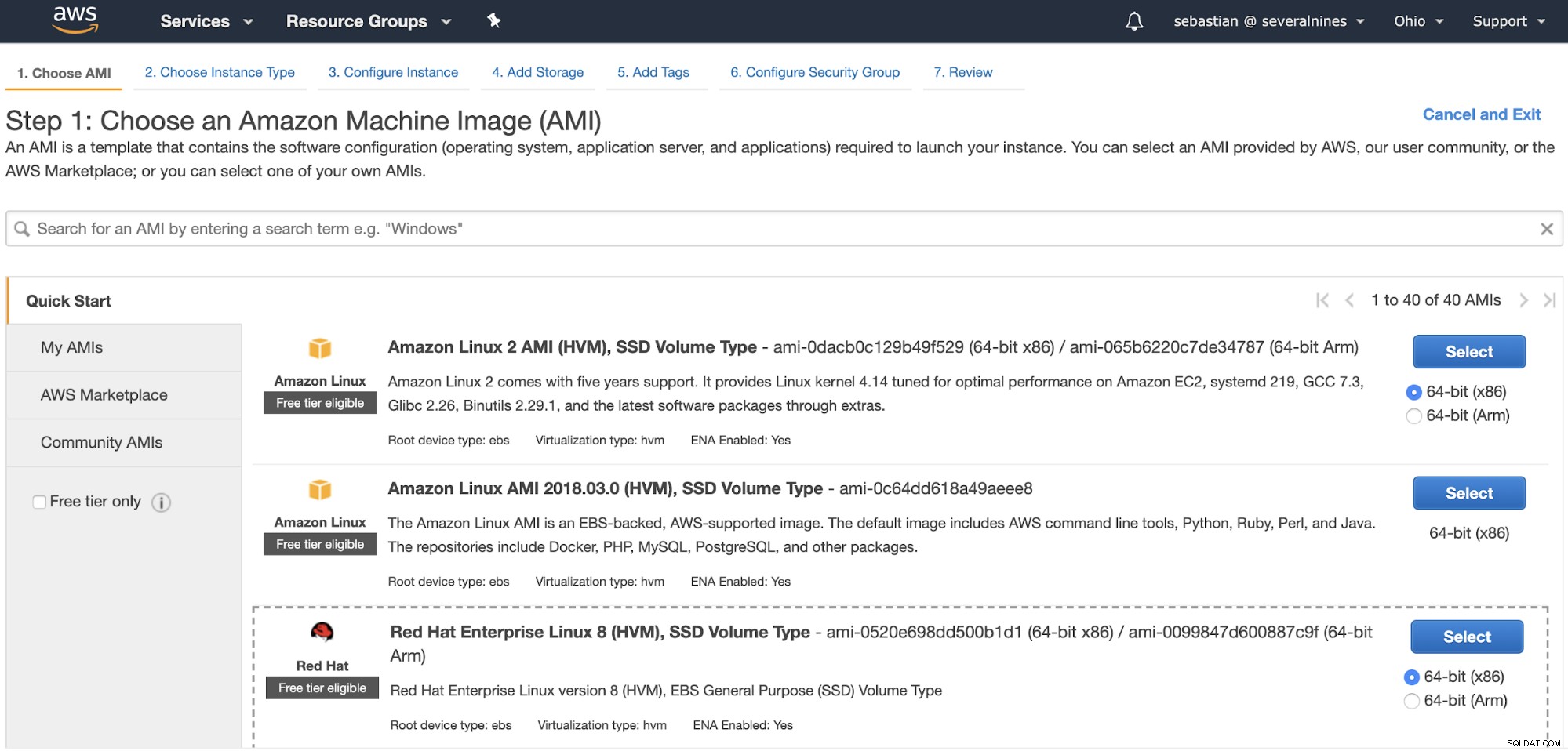
Criando a instância do Amazon EC2
Primeiro de tudo, para restaurá-lo, você precisará de um lugar para fazer isso, então vamos criar uma instância básica do Amazon EC2. Vá para “Iniciar instância” no console de gerenciamento da AWS na seção EC2 e configure sua instância.
Quando sua instância for criada, você precisará copiar o SSH público chave do servidor ClusterControl.
Restaurando o backup usando o ClusterControl
Agora que você tem a nova instância do EC2, vamos usá-la para restaurar o backup lá. Para isso, no seu ClusterControl vá para a seção de backup (ClusterControl -> Select Cluster -> Backup), e lá você pode selecionar "Restaurar Backup", ou diretamente "Restaurar" no backup que deseja restaurar.
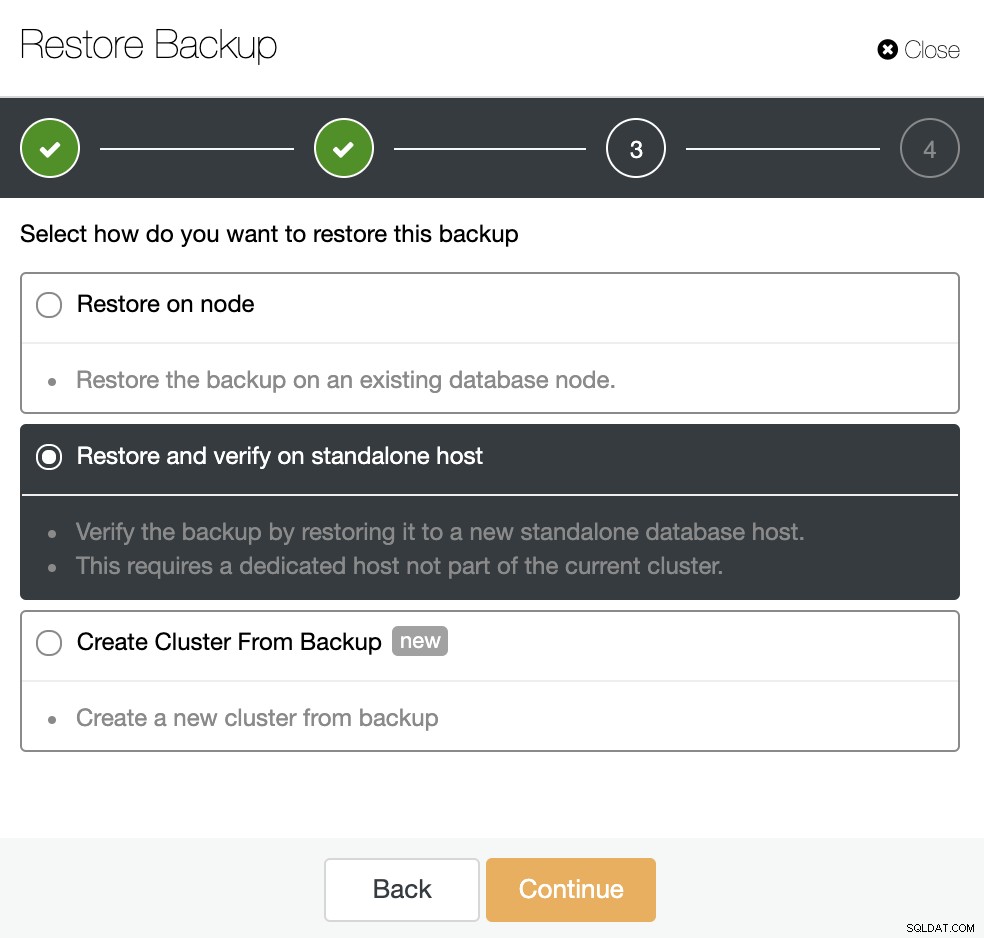
Você tem três opções para restaurar o backup. Você pode restaurar o backup em um nó de banco de dados existente, restaurar e verificar o backup em um host autônomo ou criar um novo cluster a partir do backup. Como você deseja criar um nó cold standby, vamos usar a segunda opção “Restore and Verify on standalone host”.
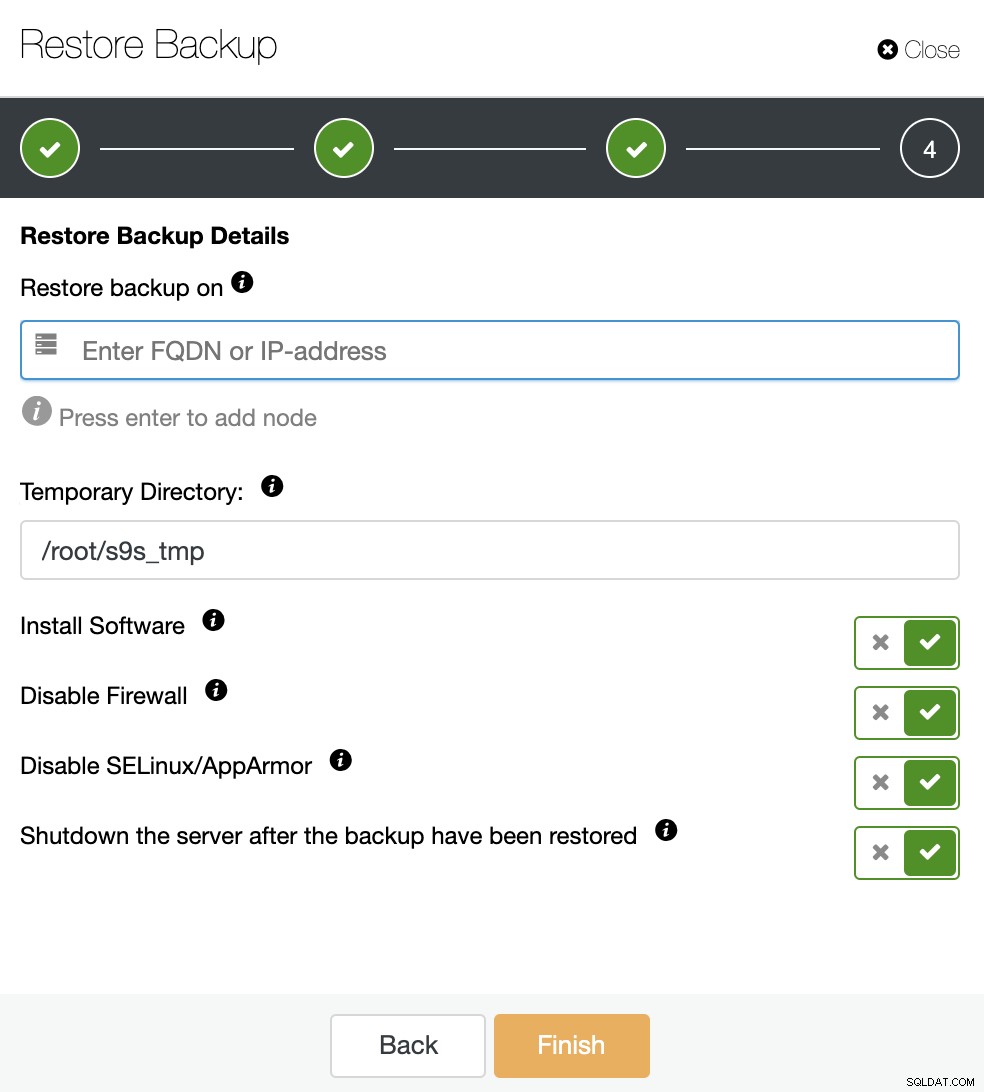
Você precisará de um host dedicado (ou VM) que não faça parte do cluster para restaurar o backup, então vamos usar a instância do EC2 criada para este trabalho. O ClusterControl instalará o software e restaurará o backup neste host.
Se a opção “Desligar o servidor após a restauração do backup” estiver habilitada, o ClusterControl interromperá o nó do banco de dados após terminar o trabalho de restauração, e é exatamente isso que precisamos para essa criação em espera fria.
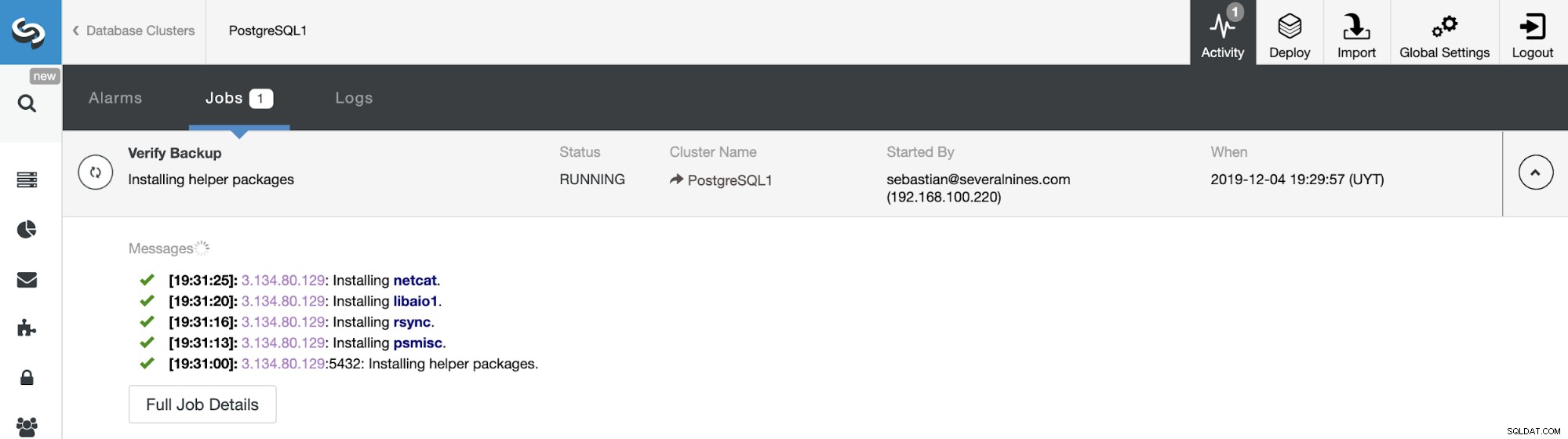
Você pode monitorar o progresso do backup na seção ClusterControl Activity.
Usando o recurso de backup de verificação do ClusterControl
Um backup não é um backup se não for restaurável. Portanto, você deve certificar-se de que o backup está funcionando e restaurá-lo no nó de espera fria com frequência.
Esse recurso de backup ClusterControl Verify Backup é uma maneira de automatizar a manutenção de um nó de espera a frio restaurando um backup recente para mantê-lo o mais atualizado possível, evitando a tarefa de backup de restauração manual. Vamos ver como isso funciona.
Como a tarefa “Restaurar e verificar no host autônomo”, ela exigirá um host dedicado (ou VM) que não faz parte do cluster para restaurar o backup, então vamos usar a mesma instância do EC2 aqui.
O recurso de verificação automática de backup está disponível para os backups agendados. Então, vá para ClusterControl -> Select the PostgreSQL Cluster -> Backup -> Create Backup e repita os passos que você viu anteriormente para agendar um novo backup.
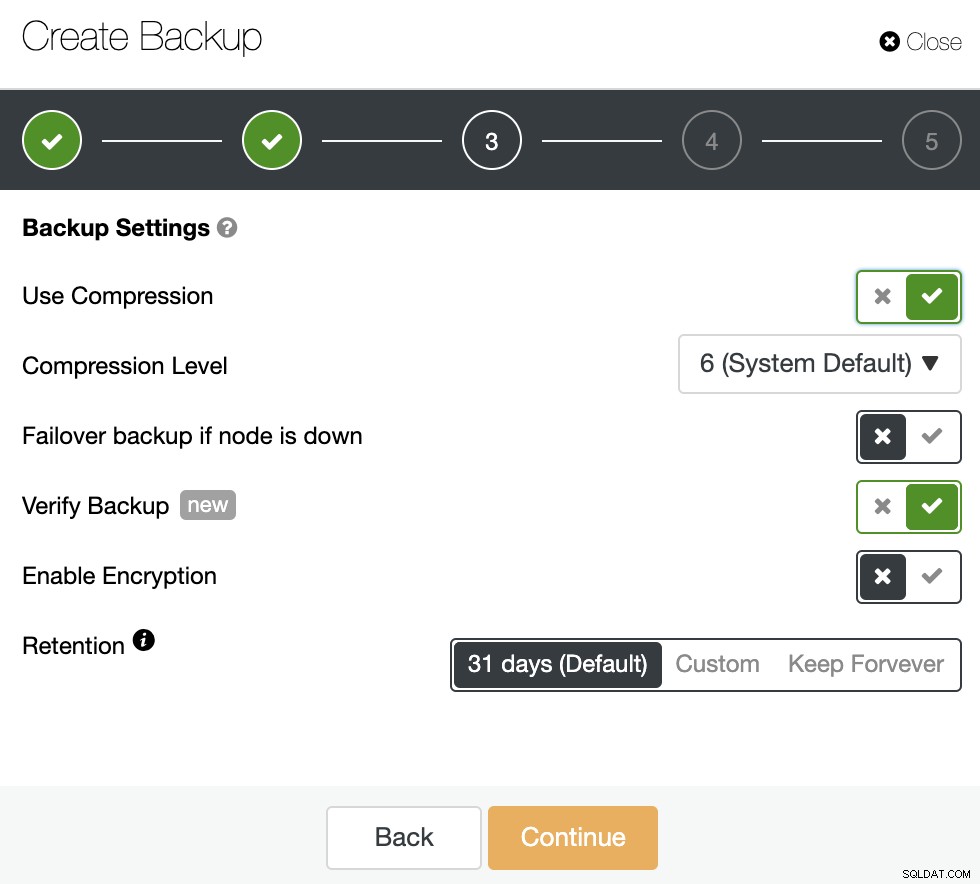
Na segunda etapa, você terá o recurso “Verify Backup” disponível para habilitá-lo.
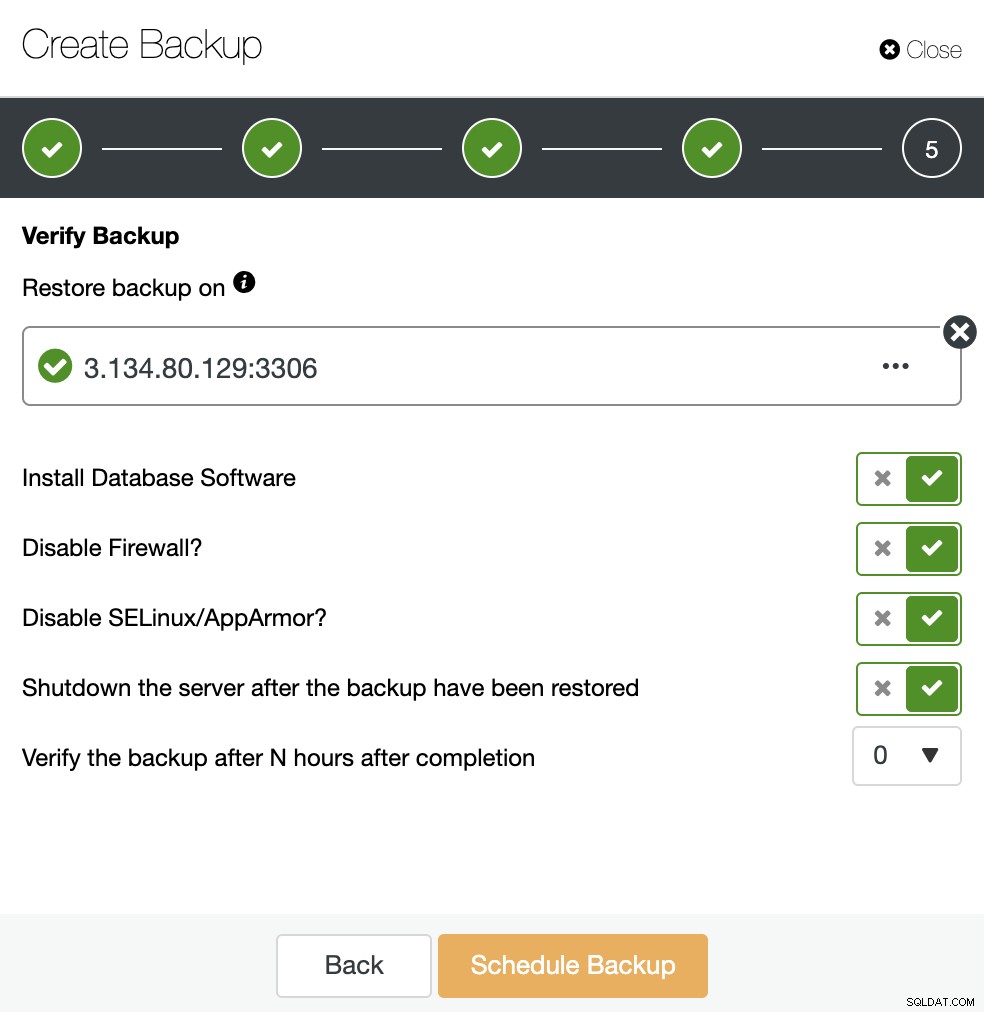
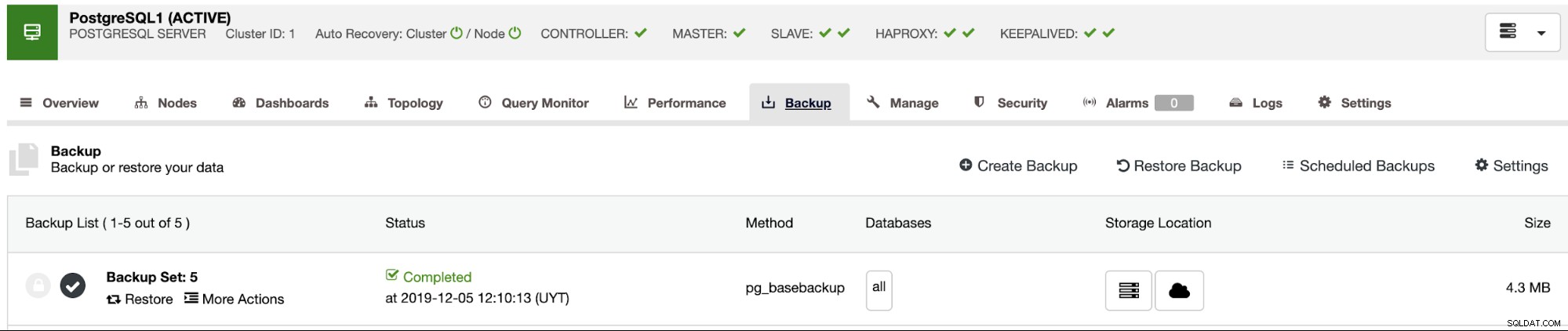
Usando as opções acima, o ClusterControl instalará o software e restaurará o backup em O hospedeiro. Após restaurá-lo, se tudo correu bem, você verá o ícone de verificação na seção Backup do ClusterControl.
Conclusão
Se você tiver um orçamento limitado, mas precisar de alta disponibilidade, poderá usar um nó do PostgreSQL de espera fria que pode ser válido ou não, dependendo do RTO e RPO da empresa. Neste blog, mostramos como agendar um backup (de acordo com sua política de negócios) e como restaurá-lo manualmente. Também mostramos como restaurar o backup automaticamente em um Cold Standby Server usando ClusterControl, Amazon S3 e Amazon EC2.