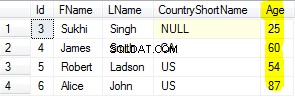
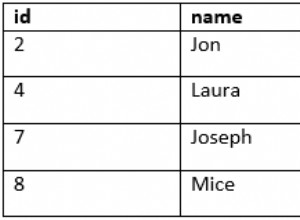
A resposta depende de muitos fatores, como versão, codificação e localidade do Postgres -
LC_COLLATE em particular. A expressão nua
lower(description) LIKE '%abc%' normalmente é um pouco mais rápido que description ILIKE '%abc%' , e qualquer um é um pouco mais rápido que a expressão regular equivalente:description ~* 'abc' . Isso é importante para varreduras sequenciais em que a expressão deve ser avaliada para cada linha testada. Mas para tabelas grandes como você demonstra em sua resposta, certamente usaria um índice. Para padrões arbitrários (não apenas ancorados à esquerda), sugiro um índice de trigramas usando o módulo adicional
pg_trgm . Então falamos sobre milissegundos em vez de segundos e a diferença entre as expressões acima é anulada. Índices GIN e GiST (usando o
gin_trgm_ops ou gist_trgm_ops classes de operadores) suportam LIKE (~~ ), ILIKE (~~* ), ~ , ~* (e mais algumas variantes) iguais. Com um índice GIN trigrama na description (normalmente maior que GiST, mas mais rápido para leituras), sua consulta usaria description ILIKE 'case_insensitive_pattern' . Relacionado:
- Variações de desempenho de consulta PostgreSQL LIKE
- Strings UTF-8 semelhantes para campo de preenchimento automático
Noções básicas para correspondência de padrões no Postgres:
- Correspondência de padrões com LIKE, SIMILAR TO ou expressões regulares no PostgreSQL
Ao trabalhar com o referido índice trigrama é normalmente mais prático para trabalhar:
description ILIKE '%abc%'
Ou com o operador regexp que não diferencia maiúsculas de minúsculas (sem
% curingas):description ~* 'abc'
Um índice em
(description) não suporta consultas em lower(description) Como:lower(description) LIKE '%abc%'
E vice versa.
Com predicados em
lower(description) exclusivamente , o índice de expressão é a opção um pouco melhor. Em todos os outros casos, um índice em
(description) é preferível, pois suporta ambos predicados que diferenciam maiúsculas de minúsculas e não diferenciam maiúsculas de minúsculas.