Algumas semanas atrás, escrevi sobre como fiquei surpreso com o desempenho de uma nova função nativa no SQL Server 2016,
STRING_SPLIT() :- Surpresas e suposições de desempenho :STRING_SPLIT()
Depois que o post foi publicado, recebi alguns comentários (públicos e privados) com essas sugestões (ou perguntas que transformei em sugestões):
- Especificar um tipo de dados de saída explícito para a abordagem JSON, para que esse método não sofra uma possível sobrecarga de desempenho devido ao fallback de
nvarchar(max). - Testando uma abordagem um pouco diferente, onde algo é realmente feito com os dados – ou seja,
SELECT INTO #temp. - Mostrando como as contagens de linhas estimadas se comparam aos métodos existentes, principalmente ao aninhar operações de divisão.
Eu respondi a algumas pessoas offline, mas achei que valeria a pena postar um acompanhamento aqui.
Ser mais justo com o JSON
A função JSON original ficou assim, sem especificação para o tipo de dados de saída:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Eu o renomeei e criei mais dois, com as seguintes definições:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Eu pensei que isso melhoraria drasticamente o desempenho, mas, infelizmente, esse não foi o caso. Fiz os testes novamente e os resultados foram os seguintes:
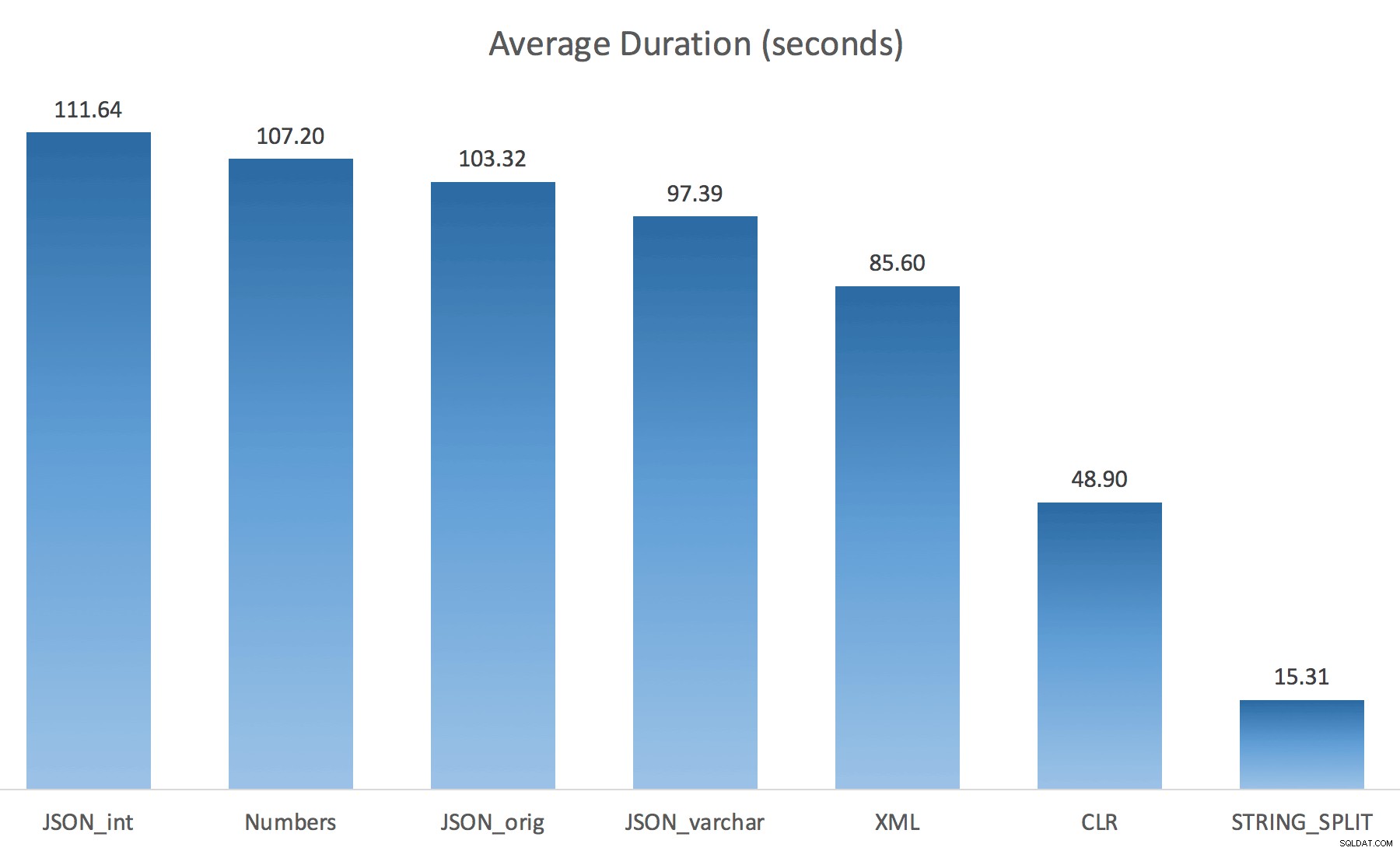
As esperas observadas durante uma instância aleatória do teste (filtradas para aquelas> 25):
| CLR | IO_COMPLETION | 1.595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6.294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6.110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Números | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1.917 |
| IO_COMPLETION | 1.616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Aguarda observada> 25 (observe que não há entrada para
STRING_SPLIT ) Ao mudar do padrão para
varchar(100) melhorou um pouco o desempenho, o ganho foi insignificante e mudou para int realmente piorou. Adicione a isso que você provavelmente precisa adicionar STRING_ESCAPE() para a string de entrada em alguns cenários, caso eles tenham caracteres que atrapalharão a análise de JSON. Minha conclusão ainda é que essa é uma maneira legal de usar a nova funcionalidade JSON, mas principalmente uma novidade inadequada para escala razoável. Materializando a saída
Jonathan Magnan fez esta observação perspicaz no meu post anterior:
STRING_SPLIT é realmente muito rápido, mas também lento como o inferno ao trabalhar com tabela temporária (a menos que seja corrigido em uma compilação futura).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Será BEM mais lento que a solução SQL CLR (15x e mais!).
Então, eu mergulhei. Eu criei um código que chamaria cada uma das minhas funções e despejaria os resultados em uma tabela #temp, e cronometraria eles:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
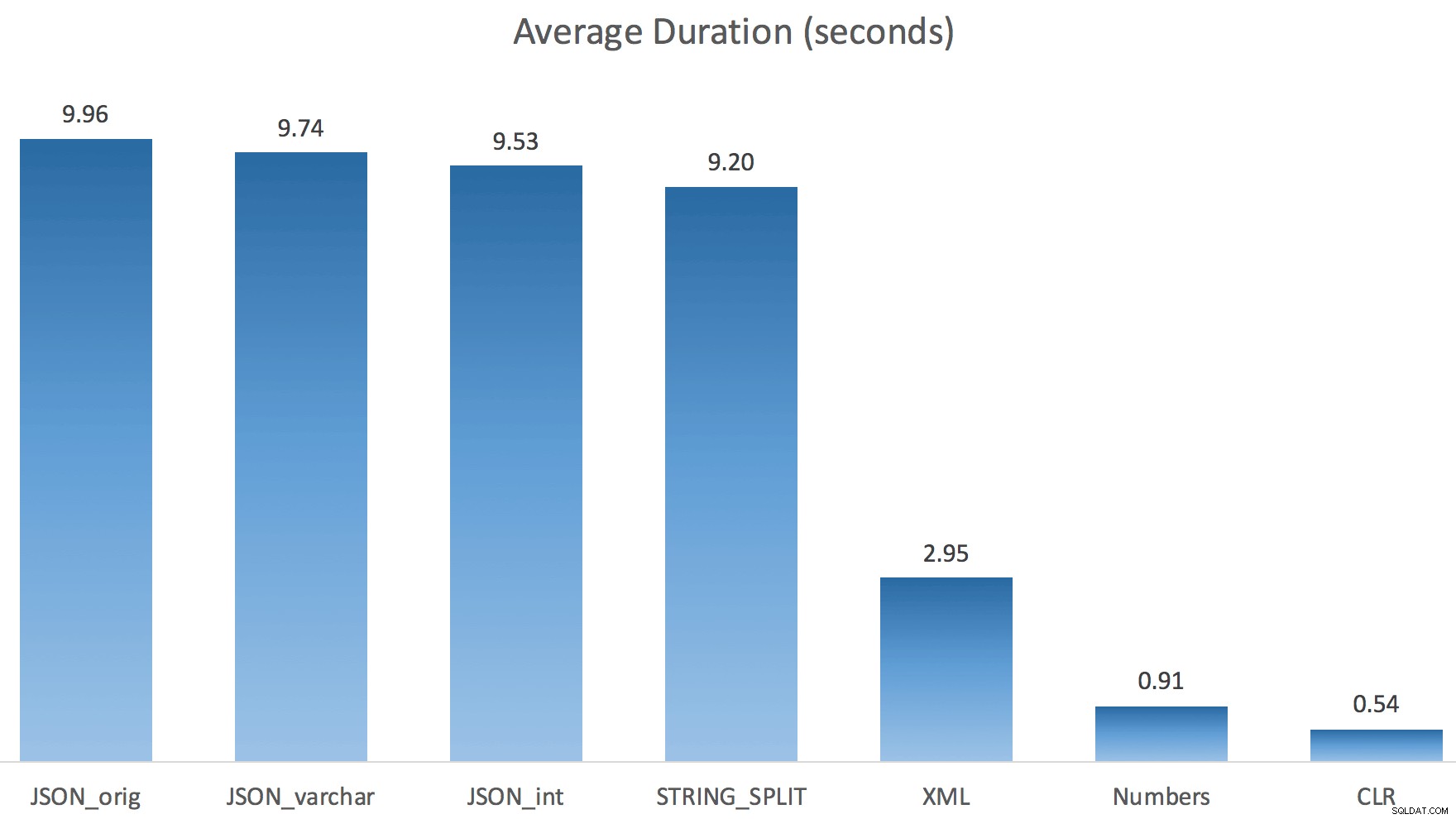
Eu apenas executei cada teste uma vez (em vez de fazer um loop 100 vezes), porque não queria sobrecarregar completamente a E/S no meu sistema. Ainda assim, após uma média de três execuções de teste, Jonathan estava absolutamente 100% certo. Aqui estão as durações de preenchimento de uma tabela #temp com aproximadamente 500.000 linhas usando cada método:
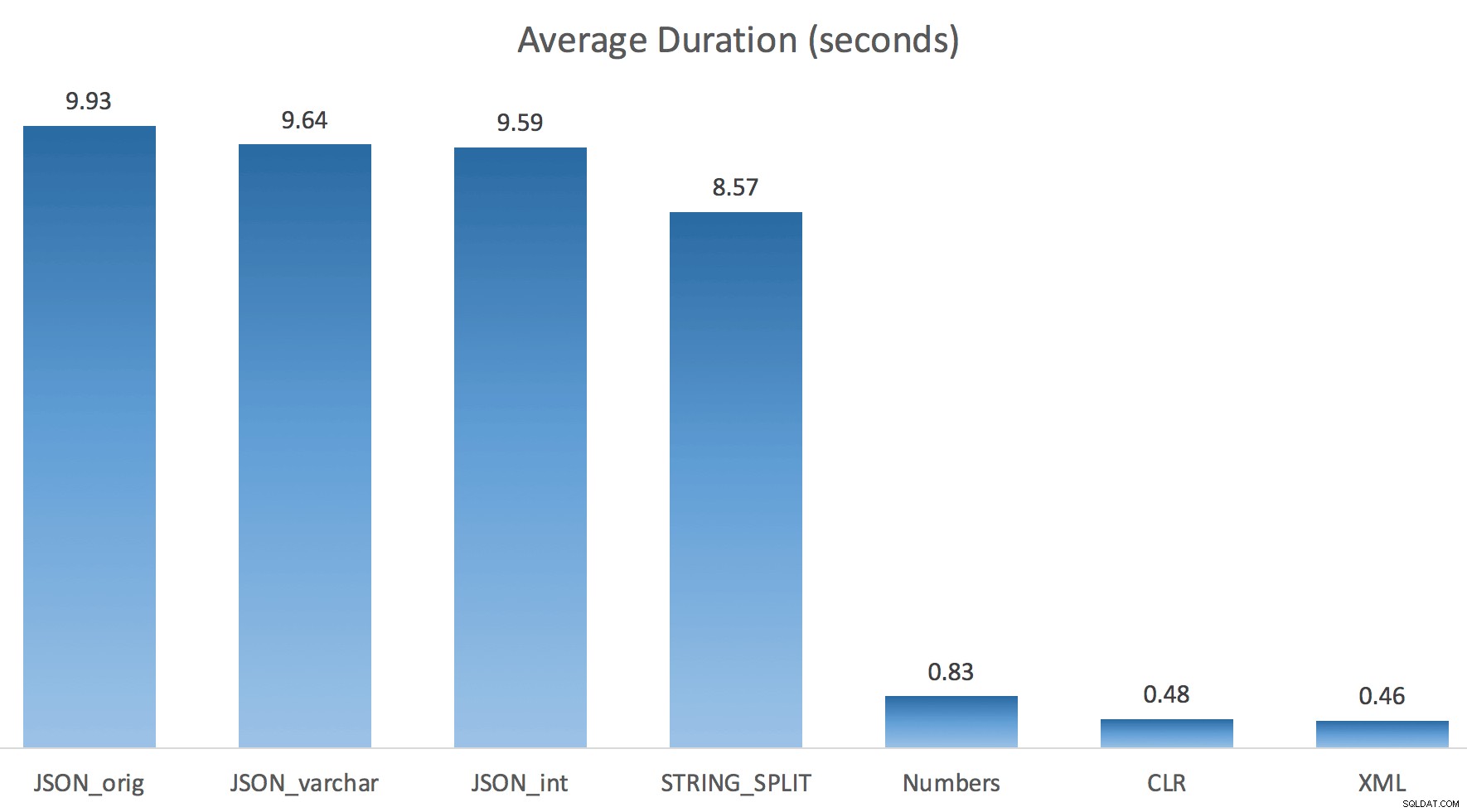
Aqui, o JSON e o
STRING_SPLIT os métodos levaram cerca de 10 segundos cada, enquanto as abordagens de tabela de números, CLR e XML levaram menos de um segundo. Perplexo, investiguei as esperas e, com certeza, os quatro métodos à esquerda incorreram em LATCH_EX significativo esperas (cerca de 25 segundos) não vistas nos outros três, e não houve outras esperas significativas para falar. E como as esperas de trava eram maiores que a duração total, isso me deu uma pista de que isso tinha a ver com paralelismo (esta máquina em particular tem 4 núcleos). Então gerei código de teste novamente, alterando apenas uma linha para ver o que aconteceria sem paralelismo:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Agora
STRING_SPLIT se saiu muito melhor (assim como os métodos JSON), mas ainda pelo menos o dobro do tempo gasto pelo CLR: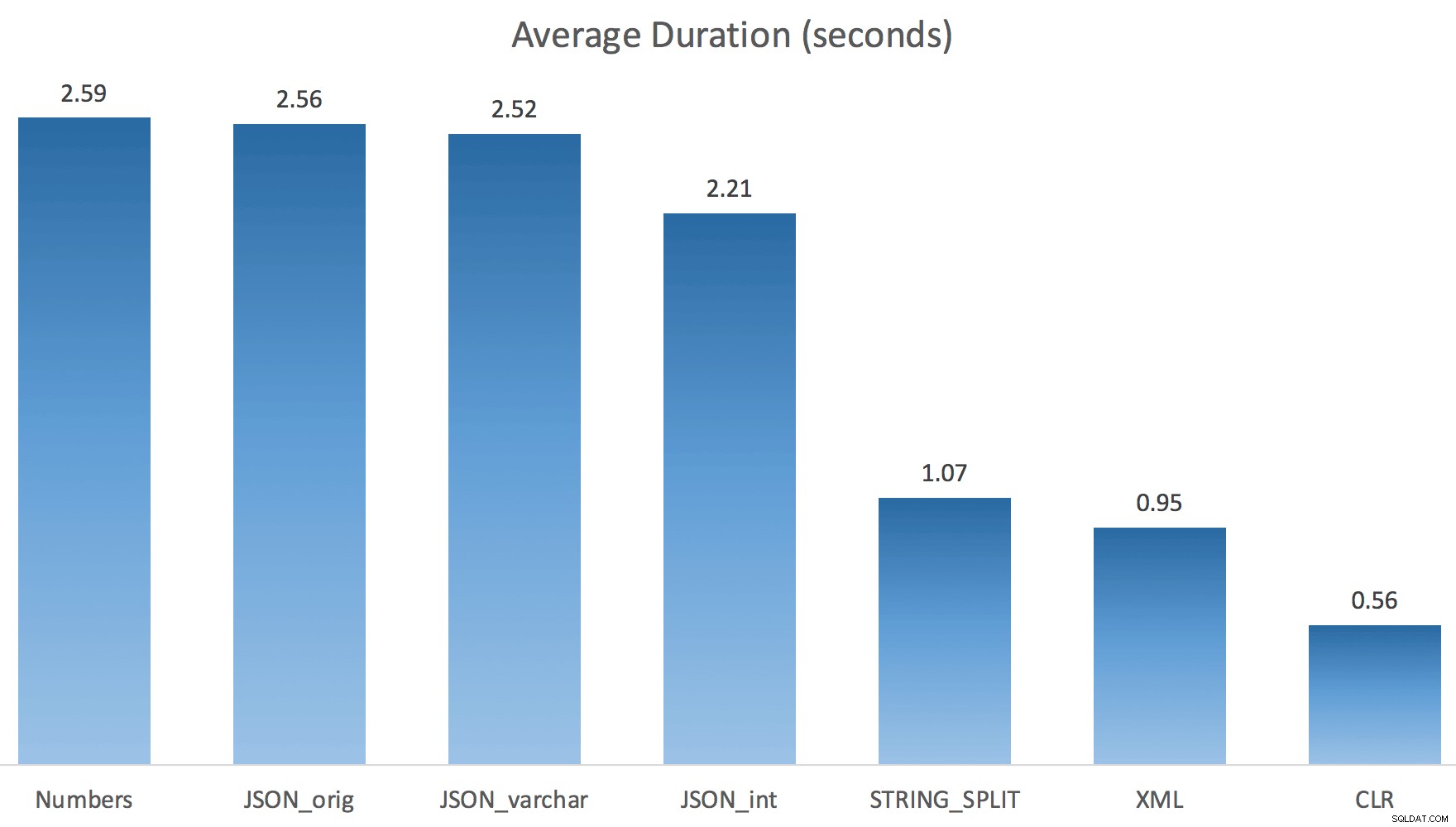
Portanto, pode haver um problema remanescente nesses novos métodos quando o paralelismo está envolvido. Não foi um problema de distribuição de encadeamentos (eu verifiquei isso), e o CLR realmente teve estimativas piores (100x reais versus apenas 5x para
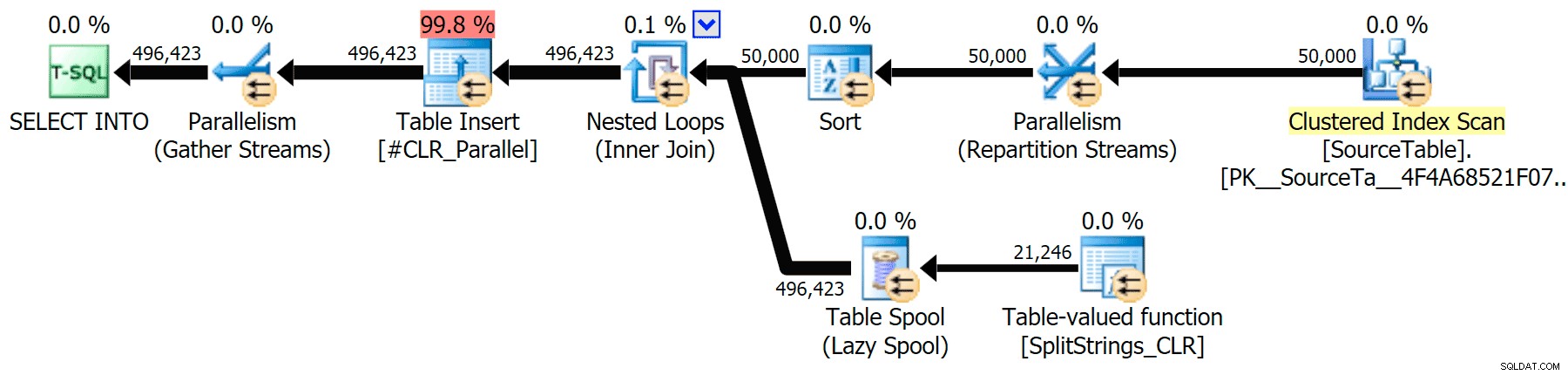
STRING_SPLIT ); apenas algum problema subjacente com travas de coordenação entre threads, suponho. Por enquanto, pode valer a pena usar MAXDOP 1 se você sabe que está gravando a saída em novas páginas. Incluí os planos gráficos comparando a abordagem CLR com a nativa, para execução paralela e serial (também carreguei um arquivo de Análise de Consulta que você pode abrir no SQL Sentry Plan Explorer para bisbilhotar por conta própria):
STRING_SPLIT
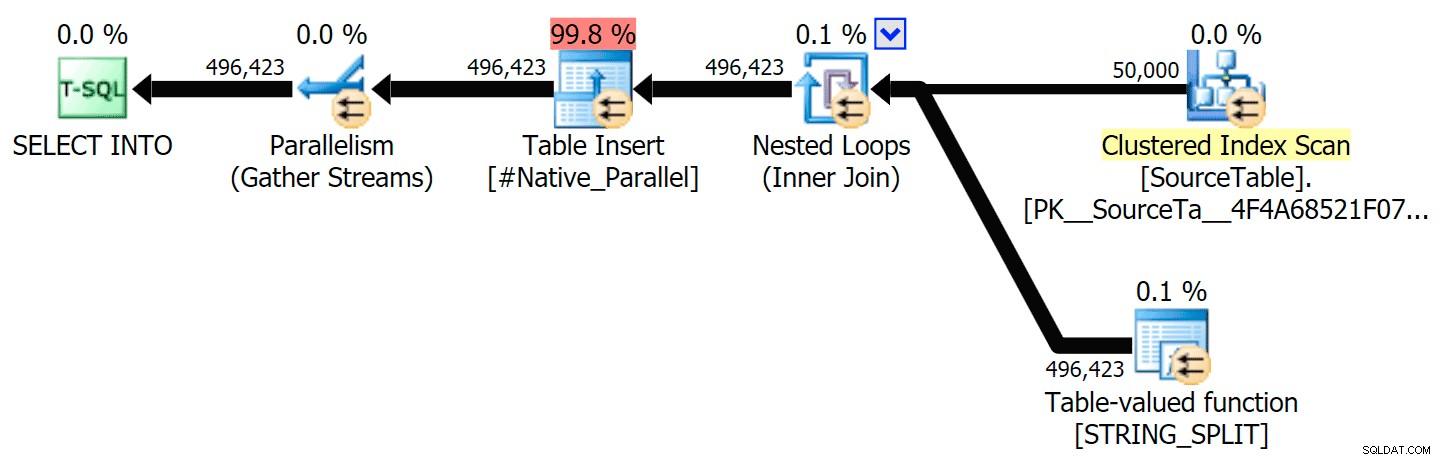
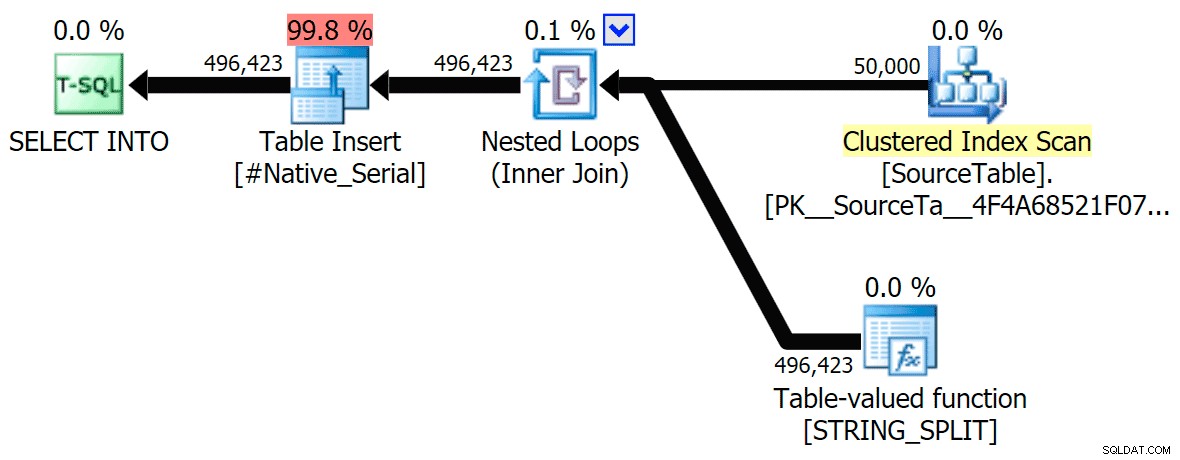
CLR
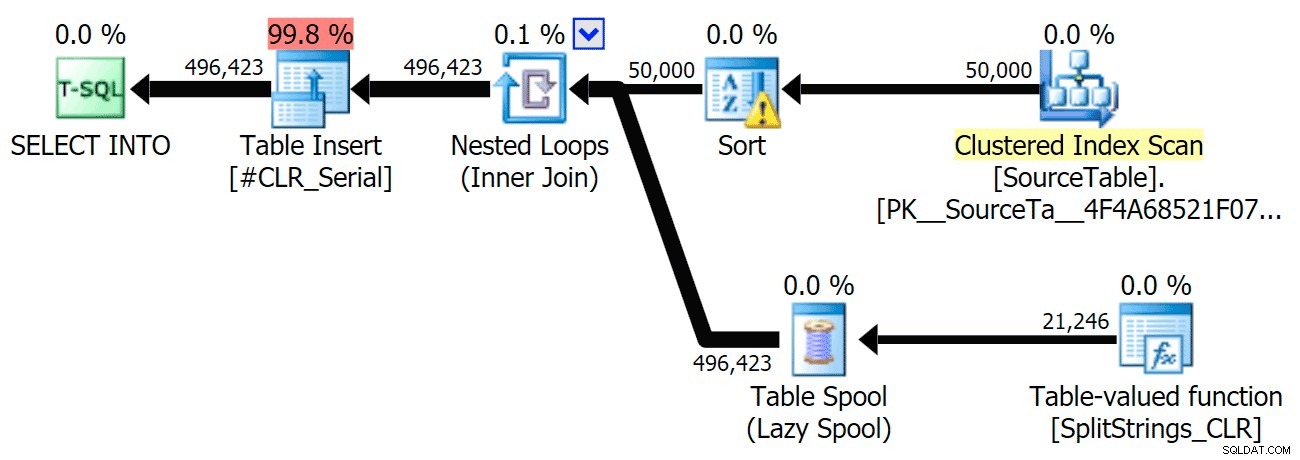
O aviso de classificação, FYI, não foi nada muito chocante e obviamente não teve muito efeito tangível na duração da consulta:

- StringSplit.queryanalysis.zip (25kb)
Bobinas para o verão
Quando olhei um pouco mais de perto para esses planos, notei que no plano CLR, há um carretel preguiçoso. Isso é introduzido para garantir que as duplicatas sejam processadas juntas (para economizar trabalho fazendo menos divisão real), mas esse carretel nem sempre é possível em todas as formas de plano e pode dar uma vantagem para aqueles que podem usá-lo ( por exemplo, o plano CLR), dependendo das estimativas. Para comparar sem spools, habilitei o sinalizador de rastreamento 8690 e executei os testes novamente. Primeiro, aqui está o plano CLR paralelo sem o carretel:
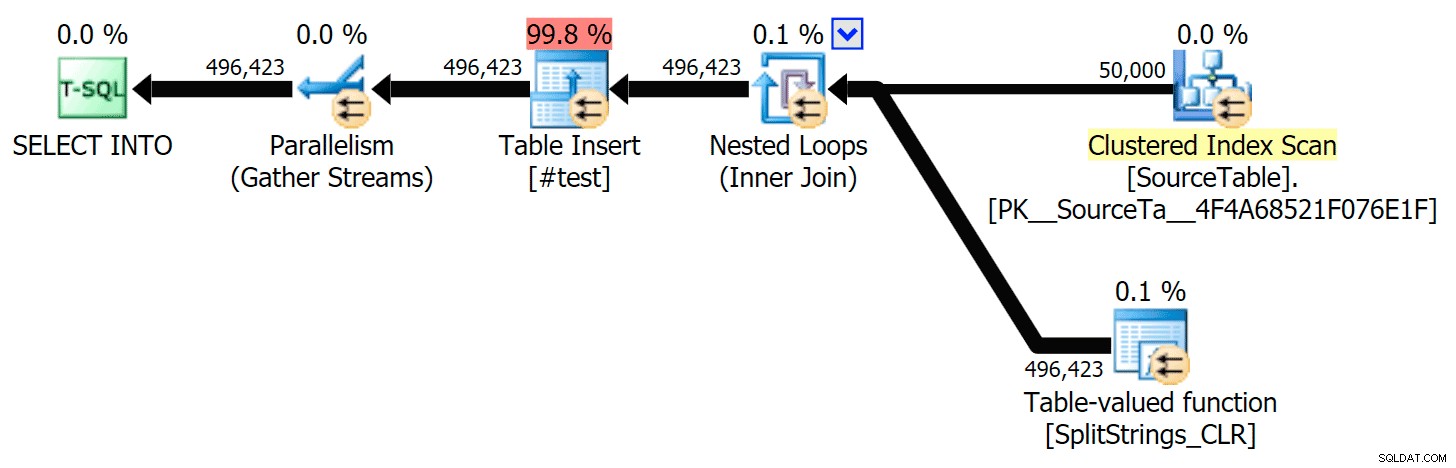
E aqui estavam as novas durações para todas as consultas paralelas com o TF 8690 ativado:
Agora, aqui está o plano CLR serial sem o carretel:
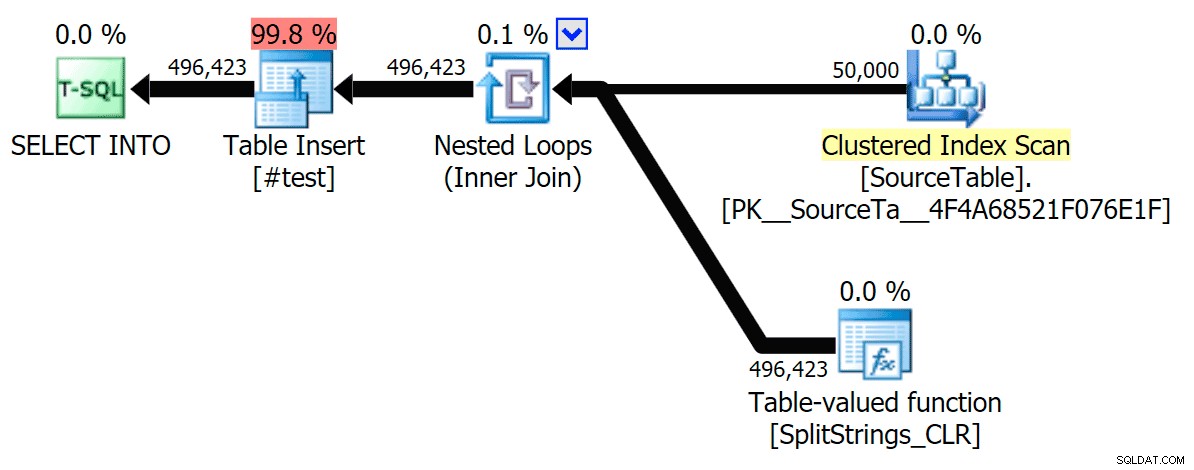
E aqui estavam os resultados de tempo para consultas usando TF 8690 e
MAXDOP 1 :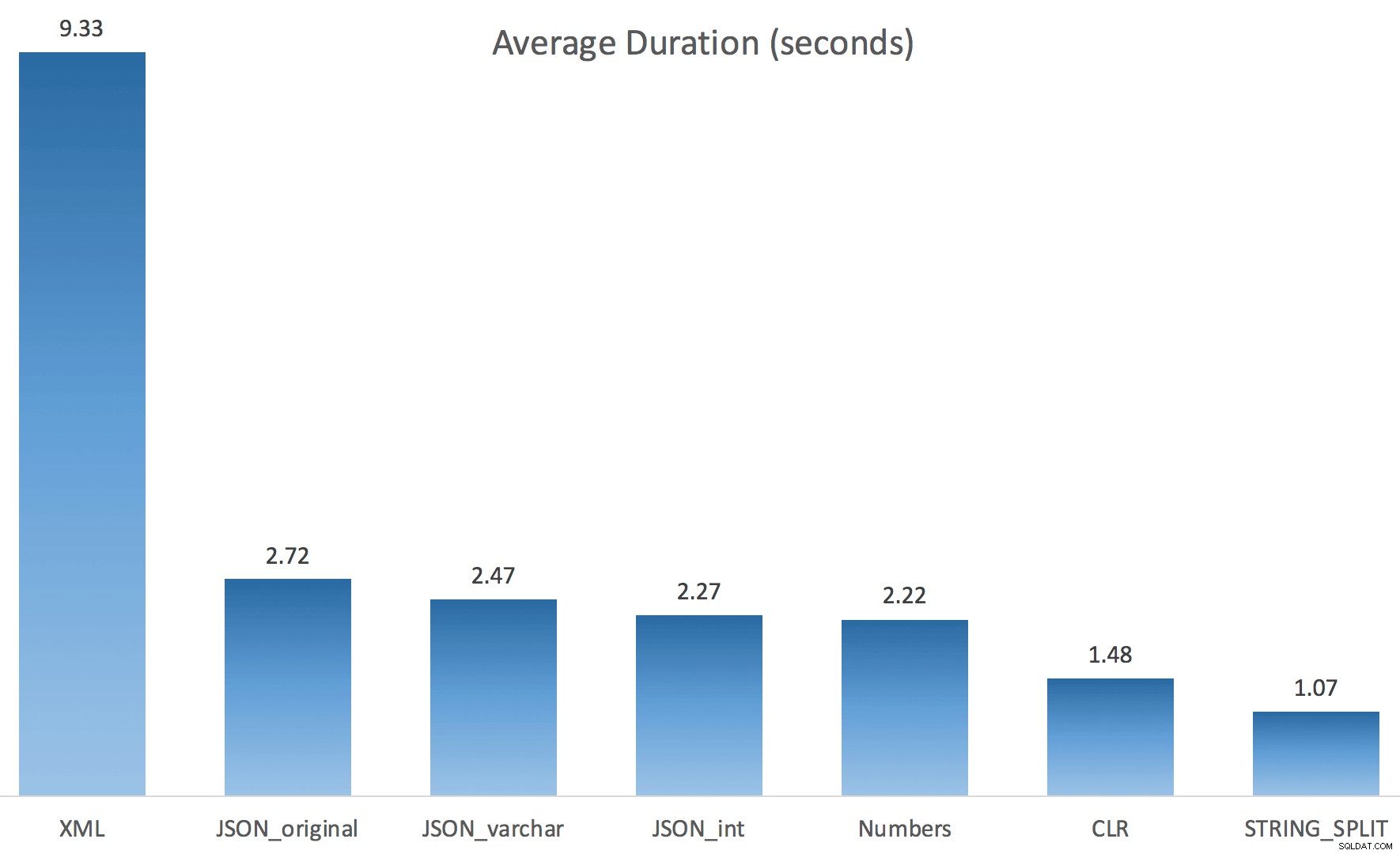
(Observe que, além do plano XML, a maioria dos outros não mudou, com ou sem o sinalizador de rastreamento.)
Comparação de contagens de linhas estimadas
Dan Holmes fez a seguinte pergunta:
Como ele estima o tamanho dos dados quando associado a outra função de divisão (ou múltipla)? O link abaixo é uma descrição de uma implementação de divisão baseada em CLR. O 2016 faz um trabalho 'melhor' com estimativas de dados? (infelizmente ainda não tenho a capacidade de instalar o RC).
https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Então, eu peguei o código do post de Dan, mudei para usar minhas funções e o executei através do Plan Explorer:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
O
SPLIT_STRING A abordagem certamente apresenta estimativas *melhores* do que CLR, mas ainda grosseiramente (neste caso, quando a string está vazia; isso pode não ser sempre o caso). A função tem um padrão embutido que estima que a string de entrada terá 50 elementos, então quando você os aninha você obtém 50 x 50 (2.500); se você os aninhar novamente, 50 x 2.500 (125.000); e, finalmente, 50 x 125.000 (6.250.000):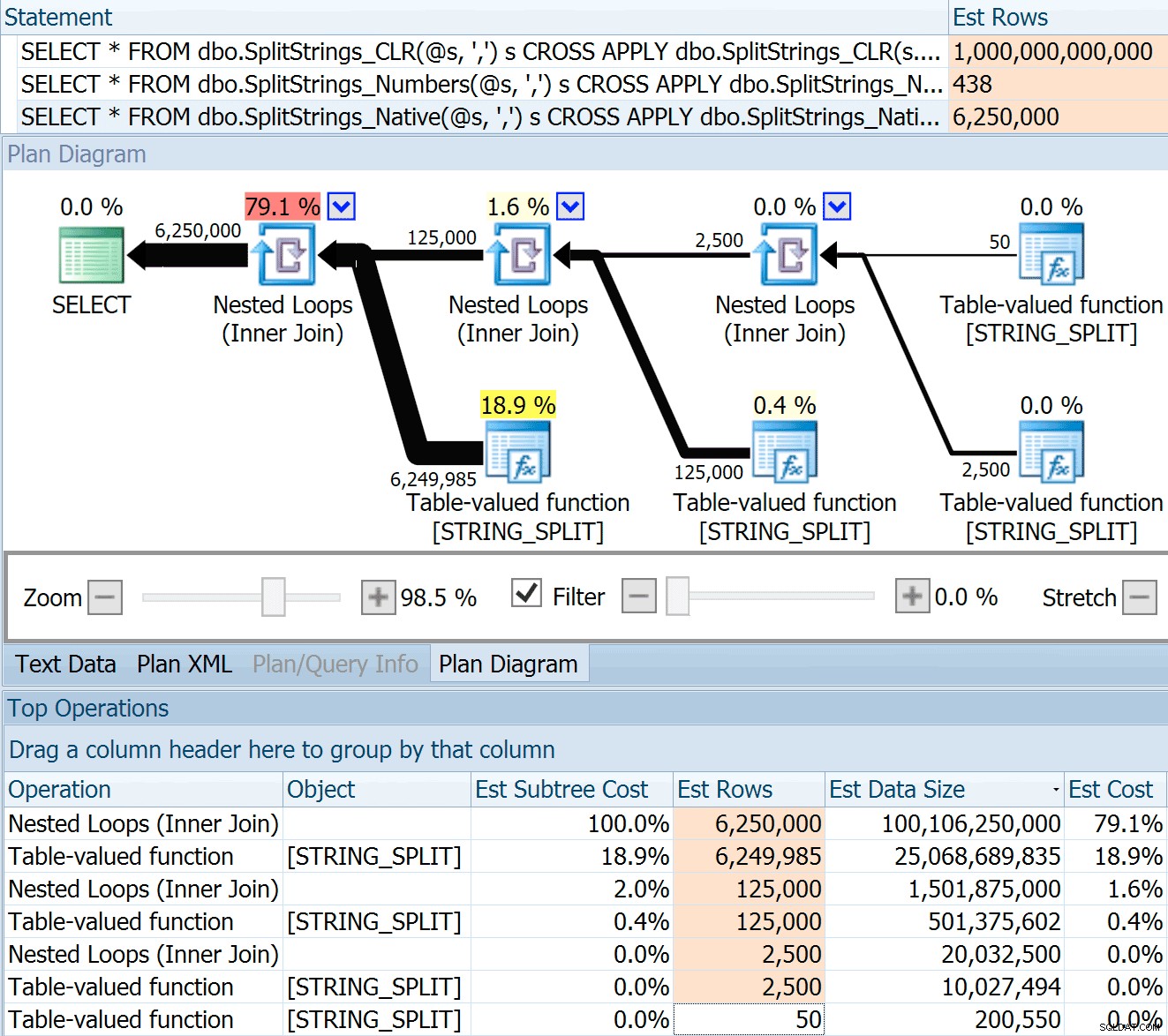
Observação:
OPENJSON() se comporta exatamente da mesma maneira que STRING_SPLIT – também assume que 50 linhas sairão de qualquer operação de divisão. Estou pensando que pode ser útil ter uma maneira de sugerir cardinalidade para funções como essa, além de sinalizar sinalizadores como 4137 (pré-2014), 9471 e 9472 (2014+) e, claro, 9481… Essa estimativa de 6,25 milhões de linhas não é ótima, mas é muito melhor do que a abordagem CLR sobre a qual Dan estava falando, que estima UM TRILHÃO DE LINHAS , e perdi a conta das vírgulas para determinar o tamanho dos dados – 16 petabytes? exabytes?
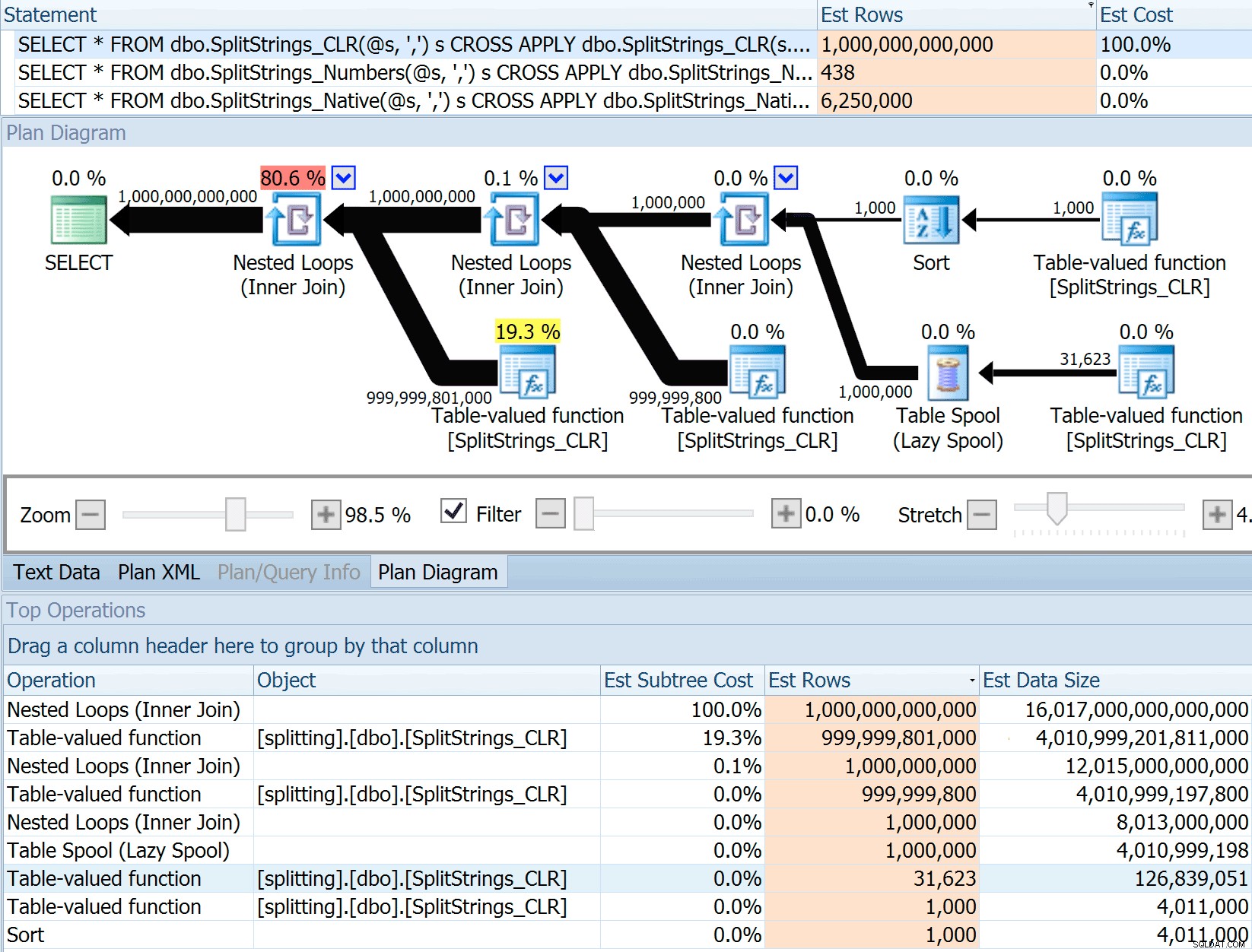
Algumas das outras abordagens obviamente se saem melhor em termos de estimativas. A tabela Numbers, por exemplo, estimou 438 linhas muito mais razoáveis (no SQL Server 2016 RC2). De onde vem esse número? Bem, existem 8.000 linhas na tabela e, se você se lembra, a função tem um predicado de igualdade e desigualdade:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Portanto, o SQL Server multiplica o número de linhas na tabela por 10% (como uma estimativa) para o filtro de igualdade e, em seguida, a raiz quadrada de 30% (novamente, um palpite) para o filtro de desigualdade. A raiz quadrada é devido ao recuo exponencial, que Paul White explica aqui. Isso nos dá:
8000 * 0,1 * SQRT(0,3) =438,178
A variação XML estimou um pouco mais de um bilhão de linhas (devido a um spool de tabela estimado para ser executado 5,8 milhões de vezes), mas seu plano era muito complexo para tentar ilustrar aqui. De qualquer forma, lembre-se de que as estimativas claramente não contam toda a história – só porque uma consulta tem estimativas mais precisas não significa que ela terá um desempenho melhor.
Havia algumas outras maneiras de ajustar um pouco as estimativas:a saber, forçando o antigo modelo de estimativa de cardinalidade (que afetava as variações da tabela XML e Numbers) e usando TFs 9471 e 9472 (que afetava apenas a variação da tabela Numbers, uma vez que ambos controlam a cardinalidade em torno de vários predicados). Aqui estão as maneiras de alterar um pouco as estimativas (ou MUITO , no caso de reverter para o antigo modelo CE):

O antigo modelo CE reduziu as estimativas XML em uma ordem de magnitude, mas para a tabela Numbers, explodiu completamente. Os sinalizadores de predicado alteraram as estimativas da tabela Numbers, mas essas alterações são muito menos interessantes.
Nenhum desses sinalizadores de rastreamento teve qualquer efeito nas estimativas para CLR, JSON ou
STRING_SPLIT variações. Conclusão
Então o que eu aprendi aqui? Um monte, na verdade:
- O paralelismo pode ajudar em alguns casos, mas quando não ajuda, realmente não ajuda. Os métodos JSON eram ~5x mais rápidos sem paralelismo e
STRING_SPLITfoi quase 10 vezes mais rápido. - O spool realmente ajudou a abordagem CLR a ter um desempenho melhor neste caso, mas o TF 8690 pode ser útil para experimentar em outros casos em que você está vendo spools e está tentando melhorar o desempenho. Tenho certeza de que há situações em que eliminar o carretel acabará sendo melhor no geral.
- Eliminar o spool realmente prejudicou a abordagem XML (mas apenas drasticamente quando foi forçado a ser de thread único).
- Muitas coisas estranhas podem acontecer com estimativas dependendo da abordagem, juntamente com as estatísticas usuais, distribuição e sinalizadores de rastreamento. Bem, acho que eu já sabia disso, mas definitivamente há alguns exemplos bons e tangíveis aqui.
Obrigado às pessoas que fizeram perguntas ou me estimularam a incluir mais informações. E como você deve ter adivinhado pelo título, abordo ainda outra pergunta em um segundo acompanhamento, esta sobre TVPs:
- STRING_SPLIT() no SQL Server 2016:acompanhamento nº 2