Esta é a segunda parte de uma série sobre soluções para o desafio do gerador de séries numéricas. No mês passado, abordei soluções que geram as linhas dinamicamente usando um construtor de valor de tabela com linhas baseadas em constantes. Não havia operações de E/S envolvidas nessas soluções. Este mês, concentro-me em soluções que consultam uma tabela base física que você preenche previamente com linhas. Por isso, além de relatar o perfil de tempo das soluções como fiz no mês passado, também relatarei o perfil de I/O das novas soluções. Obrigado novamente a Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 e Ed Wagner por compartilhar suas ideias e comentários.
Solução mais rápida até agora
Primeiro, como um lembrete rápido, vamos revisar a solução mais rápida do artigo do mês passado, implementada como um TVF embutido chamado dbo.GetNumsAlanCharlieItzikBatch.
Farei meus testes no tempdb, habilitando as estatísticas de IO e TIME:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
A solução mais rápida do mês passado aplica uma junção com uma tabela fictícia que possui um índice columnstore para obter o processamento em lote. Aqui está o código para criar a tabela fictícia:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
E aqui está o código com a definição da função dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO No mês passado, usei o seguinte código para testar o desempenho da função com 100 milhões de linhas, depois de habilitar os resultados de Descartar após a execução no SSMS para suprimir o retorno das linhas de saída:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Aqui estão as estatísticas de tempo que obtive para esta execução:
Tempo de CPU =16.031 ms, tempo decorrido =17.172 ms.
Joe Obbish observou corretamente que esse teste pode estar faltando no reflexo de alguns cenários da vida real no sentido de que uma grande parte do tempo de execução é devido a esperas de E/S de rede assíncrona (tipo de espera ASYNC_NETWORK_IO). Você pode observar as esperas mais altas examinando a página de propriedades do nó raiz do plano de consulta real ou executar uma sessão de eventos estendidos com informações de espera. O fato de você habilitar Descartar resultados após a execução no SSMS não impede que o SQL Server envie as linhas de resultados para o SSMS; apenas impede que o SSMS os imprima. A questão é:qual é a probabilidade de você retornar grandes conjuntos de resultados para o cliente em cenários da vida real, mesmo quando você usa a função para produzir uma série de números grandes? Talvez mais frequentemente você grave os resultados da consulta em uma tabela ou use o resultado da função como parte de uma consulta que eventualmente produz um pequeno conjunto de resultados. Você precisa descobrir isso. Você pode escrever o conjunto de resultados em uma tabela temporária usando a instrução SELECT INTO, ou pode usar o truque de Alan Burstein com uma instrução SELECT de atribuição, que atribui o valor da coluna de resultado a uma variável.
Veja como você alteraria o último teste para usar a opção de atribuição de variável:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Aqui estão as estatísticas de tempo que obtive para este teste:
Tempo de CPU =8641 ms, tempo decorrido =8645 ms.
Desta vez, as informações de espera não têm esperas de E/S de rede assíncronas e você pode ver a queda significativa no tempo de execução.
Teste a função novamente, desta vez adicionando ordenação:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Eu obtive as seguintes estatísticas de desempenho para esta execução:
Tempo de CPU =9360 ms, tempo decorrido =9551 ms.
Lembre-se de que não há necessidade de um operador Sort no plano para esta consulta, pois a coluna n é baseada em uma expressão que preserva a ordem em relação à coluna rownum. Isso se deve ao truque de dobragem constante de Charli, que cobri no mês passado. Os planos para ambas as consultas — a sem pedido e a com pedido são os mesmos, portanto, o desempenho tende a ser semelhante.
A Figura 1 resume os números de desempenho que obtive para as soluções do mês passado, só que desta vez usando atribuição de variáveis nos testes em vez de descartar resultados após a execução.
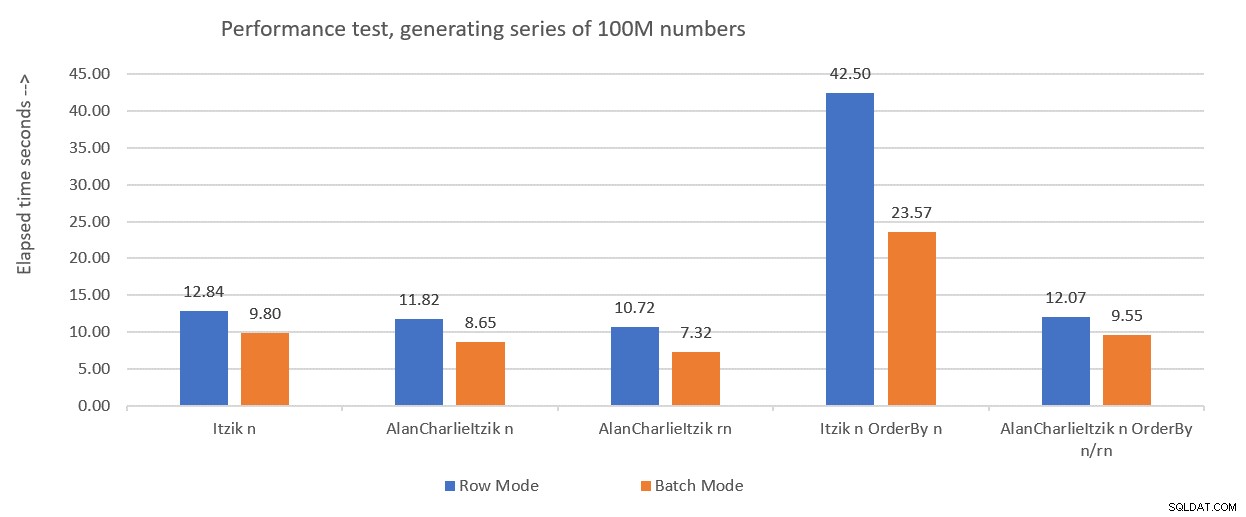 Figura 1:Resumo de desempenho até agora com atribuição de variável
Figura 1:Resumo de desempenho até agora com atribuição de variável Usarei a técnica de atribuição de variáveis para testar o restante das soluções que apresentarei neste artigo. Certifique-se de ajustar seus testes para refletir melhor sua situação da vida real, usando atribuição de variáveis, SELECT INTO, Descartar resultados após a execução ou qualquer outra técnica.
Dica para forçar planos seriais sem MAXDOP 1
Antes de apresentar novas soluções, gostaria apenas de dar uma pequena dica. Lembre-se de que algumas das soluções têm melhor desempenho ao usar um plano serial. A maneira óbvia de forçar isso é com uma dica de consulta MAXDOP 1. E esse é o caminho certo a seguir se às vezes você deseja habilitar o paralelismo e às vezes não. No entanto, e se você sempre quiser forçar um plano serial ao usar a função, embora seja um cenário menos provável?
Há um truque para conseguir isso. O uso de uma UDF escalar não-inlineável na consulta é um inibidor de paralelismo. Um dos inibidores de inlining UDF escalares está invocando uma função intrínseca que é dependente do tempo, como SYSDATETIME. Então aqui está um exemplo para uma UDF escalar não-inlineável:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Outra opção é definir uma UDF com apenas alguma constante como valor retornado e usar a opção INLINE =OFF em seu cabeçalho. Mas essa opção está disponível apenas a partir do SQL Server 2019, que introduziu o inlining UDF escalar. Com a função sugerida acima, você pode criá-la como está com versões mais antigas do SQL Server.
Em seguida, altere a definição da função dbo.GetNumsAlanCharlieItzikBatch para ter uma chamada fictícia para dbo.MySYSDATETIME (defina uma coluna com base nela, mas não faça referência à coluna na consulta retornada), assim:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Agora você pode executar novamente o teste de desempenho sem especificar MAXDOP 1 e ainda obter um plano serial:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
É importante ressaltar que qualquer consulta usando esta função agora obterá um plano serial. Se houver alguma chance de que a função seja usada em consultas que se beneficiarão de planos paralelos, melhor não usar esse truque e, quando precisar de um plano serial, basta usar MAXDOP 1.
Solução de Joe Obbish
A solução de Joe é bastante criativa. Aqui está sua própria descrição da solução:
“Optei por criar um índice columnstore clusterizado (CCI) com 134.217.728 linhas de números inteiros sequenciais. A função referencia a tabela até 32 vezes para obter todas as linhas necessárias para o conjunto de resultados. Eu escolhi um CCI porque os dados serão compactados bem (menos de 3 bytes por linha), você obtém o modo de lote "de graça" e a experiência anterior sugere que a leitura de números sequenciais de um CCI será mais rápida do que gerá-los por meio de outro método. ”
Conforme mencionado anteriormente, Joe também observou que meu teste de desempenho original foi significativamente distorcido devido às esperas de E/S de rede assíncrona geradas pela transmissão das linhas para o SSMS. Então todos os testes que eu vou fazer aqui vão usar a ideia do Alan com a atribuição de variáveis. Certifique-se de ajustar seus testes com base no que reflete mais de perto sua situação da vida real.
Aqui está o código que Joe usou para criar a tabela dbo.GetNumsObbishTable e preenchê-la com 134.217.728 linhas:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Este código levou 1:04 minutos para ser concluído na minha máquina.
Você pode verificar o uso de espaço desta tabela executando o seguinte código:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Eu tenho cerca de 350 MB de espaço usado. Em comparação com as outras soluções que apresentarei neste artigo, esta usa muito mais espaço.
Na arquitetura columnstore do SQL Server, um grupo de linhas é limitado a 2^20 =1.048.576 linhas. Você pode verificar quantos grupos de linhas foram criados para esta tabela usando o seguinte código:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Eu tenho 128 grupos de linhas.
Aqui está o código com a definição da função dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
As 32 consultas individuais geram os subintervalos de 134.217.728 inteiros separados que, quando unificados, produzem o intervalo ininterrupto completo de 1 a 4.294.967.296. O que é realmente inteligente nessa solução são os predicados do filtro WHERE que as consultas individuais usam. Lembre-se de que quando o SQL Server processa um TVF embutido, ele primeiro aplica a incorporação de parâmetros, substituindo os parâmetros pelas constantes de entrada. O SQL Server pode otimizar as consultas que produzem subintervalos que não fazem interseção com o intervalo de entrada. Por exemplo, quando você solicita o intervalo de entrada de 1 a 100.000.000, apenas a primeira consulta é relevante e todo o resto é otimizado. O plano, nesse caso, envolverá uma referência a apenas uma instância da tabela. Isso é muito brilhante!
Vamos testar o desempenho da função com o intervalo de 1 a 100.000.000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
O plano para esta consulta é mostrado na Figura 2.
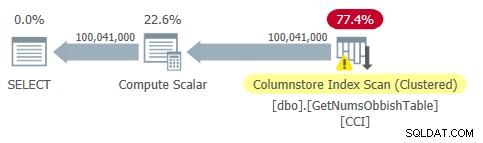 Figura 2:plano para dbo.GetNumsObbish, 100 milhões de linhas, não ordenadas
Figura 2:plano para dbo.GetNumsObbish, 100 milhões de linhas, não ordenadas Observe que, de fato, apenas uma referência ao CCI da tabela é necessária neste plano.
Recebi as seguintes estatísticas de tempo para esta execução:
Tempo de CPU =4969 ms, tempo decorrido =4982 ms.
Isso é bastante impressionante e muito mais rápido do que qualquer outra coisa que eu testei.
Aqui estão as estatísticas de E/S que obtive para esta execução:
Tabela 'GetNumsObbishTable'. Contagem de varredura 1, leitura lógica 0, leitura física 0, servidor de página lê 0, leitura antecipada lê 0, leitura antecipada do servidor de página lê 0, leitura lógica lob 32928 , leituras físicas de lob 0, servidor de página lob lê 0, leitura antecipada de lob lê 0, leitura antecipada de servidor de página lob lê 0.
Tabela 'GetNumsObbishTable'. O segmento lê 96 , segmento ignorado 32.
O perfil de E/S desta solução é uma de suas desvantagens em relação às demais, incorrendo em mais de 30 mil leituras lógicas de lob para esta execução.
Para ver que, ao cruzar vários subintervalos de 134.217.728 inteiros, o plano envolverá várias referências à tabela, consulte a função com o intervalo de 1 a 400.000.000, por exemplo:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
O plano para esta execução é mostrado na Figura 3.
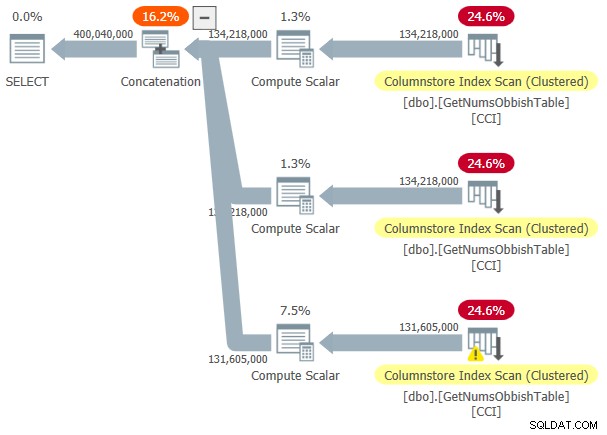 Figura 3:plano para dbo.GetNumsObbish, 400 milhões de linhas, não ordenadas
Figura 3:plano para dbo.GetNumsObbish, 400 milhões de linhas, não ordenadas O intervalo solicitado cruzou três subintervalos de 134.217.728 inteiros, portanto, o plano mostra três referências ao CCI da tabela.
Aqui estão as estatísticas de tempo que obtive para esta execução:
Tempo de CPU =20610 ms, tempo decorrido =20628 ms.
E aqui estão suas estatísticas de E/S:
Tabela 'GetNumsObbishTable'. Contagem de varredura 3, leituras lógicas 0, leituras físicas 0, leituras do servidor de páginas 0, leituras antecipadas 0, leituras antecipadas do servidor de páginas 0, leituras lógicas lob 131026 , leituras físicas de lob 0, servidor de página lob lê 0, leitura antecipada de lob lê 0, leitura antecipada de servidor de página lob lê 0.
Tabela 'GetNumsObbishTable'. Segmento lê 382 , segmento ignorado 2.
Desta vez, a execução da consulta resultou em mais de 130 mil leituras lógicas de lob.
Se você puder suportar os custos de E/S e não precisar processar a série numérica de forma ordenada, esta é uma ótima solução. No entanto, se você precisar processar a série em ordem, essa solução resultará em um operador Sort no plano. Aqui está um teste solicitando o resultado solicitado:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
O plano para esta execução é mostrado na Figura 4.
 Figura 4:plano para dbo.GetNumsObbish, 100 milhões de linhas, ordenadas
Figura 4:plano para dbo.GetNumsObbish, 100 milhões de linhas, ordenadas Aqui estão as estatísticas de tempo que obtive para esta execução:
Tempo de CPU =44.516 ms, tempo decorrido =34.836 ms.
Como você pode ver, o desempenho diminuiu significativamente com o tempo de execução aumentando em uma ordem de magnitude devido à classificação explícita.
Aqui estão as estatísticas de E/S que obtive para esta execução:
Tabela 'GetNumsObbishTable'. Contagem de varredura 4, leituras lógicas 0, leituras físicas 0, servidor de página lê 0, leitura antecipada lê 0, leitura antecipada do servidor de página lê 0, leitura lógica lob 32928 , leituras físicas de lob 0, servidor de página lob lê 0, leitura antecipada de lob lê 0, leitura antecipada de servidor de página lob lê 0.
Tabela 'GetNumsObbishTable'. O segmento lê 96 , segmento ignorado 32.
Tabela 'Mesa de trabalho'. Contagem de varredura 0, leitura lógica 0, leitura física 0, servidor de página lê 0, leitura antecipada lê 0, leitura antecipada do servidor de página lê 0, leitura lógica lob 0, leitura física lob 0, servidor de página lob lê 0, leitura lob A frente lê 0, a leitura antecipada do servidor de página lob lê 0.
Observe que uma Worktable apareceu na saída de STATISTICS IO. Isso ocorre porque uma classificação pode potencialmente vazar para o tempdb, caso em que usaria uma tabela de trabalho. Esta execução não foi derramada, portanto, os números são todos zeros nesta entrada.
Solução de John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 postou uma solução que é simplesmente linda em sua simplicidade. Além disso, inclui ideias e sugestões de outras soluções de Dave, Joe, Alan, Charlie e eu.
Assim como na solução de Joe, John decidiu usar um CCI para obter um alto nível de compactação e processamento em lote “gratuito”. Apenas John decidiu preencher a tabela com 4B linhas com algum marcador NULL fictício em uma coluna de bits e fazer com que a função ROW_NUMBER gerasse os números. Como os valores armazenados são todos iguais, com a compactação de valores repetidos, você precisa de muito menos espaço, resultando em significativamente menos E/S em comparação com a solução de Joe. A compactação Columnstore lida muito bem com valores repetidos, pois pode representar cada seção consecutiva dentro do segmento de coluna de um grupo de linhas apenas uma vez, juntamente com a contagem de ocorrências repetidas consecutivamente. Como todas as linhas têm o mesmo valor (o marcador NULL), teoricamente você precisa apenas de uma ocorrência por grupo de linhas. Com 4B linhas, você deve terminar com 4.096 grupos de linhas. Cada um deve ter um único segmento de colunas, com muito pouco uso de espaço.
Aqui está o código para criar e preencher a tabela, implementado como um CCI com compactação de arquivamento:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO A principal desvantagem dessa solução é o tempo que leva para preencher essa tabela. Este código levou 12:32 minutos para ser concluído na minha máquina ao permitir o paralelismo e 15:17 minutos ao forçar um plano serial.
Observe que você pode trabalhar na otimização da carga de dados. Por exemplo, John testou uma solução que carregou as linhas usando 32 conexões simultâneas com OSTRESS.EXE, cada uma executando 128 rodadas de inserções de 2^20 linhas (tamanho máximo do grupo de linhas). Essa solução reduziu o tempo de carregamento de John para um terço. Aqui está o código que John usou:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"WITH L0 AS (SELECT CAST(NULL AS BIT) AS b FROM (VALUES(1),(1),(1),(1)) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)), L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B), L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B), nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"
Ainda assim, o tempo de carregamento é em minutos. A boa notícia é que você precisa realizar esse carregamento de dados apenas uma vez.
A grande novidade é a pequena quantidade de espaço necessária para a mesa. Use o seguinte código para verificar o uso do espaço:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Eu tenho 1,64 MB. Isso é incrível considerando o fato de que a tabela tem 4B linhas!
Use o código a seguir para verificar quantos grupos de linhas foram criados:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Como esperado, o número de grupos de linhas é 4.096.
A definição da função dbo.GetNumsJohn2DaveObbishAlanCharlieItzik se torna bem simples:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Como você pode ver, uma consulta simples na tabela usa a função ROW_NUMBER para calcular os números de linha base (coluna rownum) e, em seguida, a consulta externa usa as mesmas expressões que em dbo.GetNumsAlanCharlieItzikBatch para calcular rn, op e n. Também aqui, rn e n preservam a ordem em relação a rownum.
Vamos testar o desempenho da função:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Eu tenho o plano mostrado na Figura 5 para esta execução.
 Figura 5:Plano para dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figura 5:Plano para dbo.GetNumsJohn2DaveObbishAlanCharlieItzik Aqui estão as estatísticas de tempo que obtive para este teste:
Tempo de CPU =7593 ms, tempo decorrido =7590 ms.
Como você pode ver, o tempo de execução não é tão rápido quanto com a solução de Joe, mas ainda é mais rápido do que todas as outras soluções que testei.
Aqui estão as estatísticas de E/S que obtive para este teste:
Tabela 'NullBits4B'. Contagem de varredura 1, leitura lógica 0, leitura física 0, servidor de página lê 0, leitura antecipada lê 0, leitura antecipada do servidor de página lê 0, leitura lógica lob 194 , leituras físicas de lob 0, servidor de página lob lê 0, leitura antecipada de lob lê 0, leitura antecipada de servidor de página lob lê 0.
Tabela 'NullBits4B'. O segmento lê 96 , segmento ignorado 0
Observe que os requisitos de E/S são significativamente menores do que com a solução de Joe.
A outra grande vantagem dessa solução é que, quando você precisa processar a série numérica solicitada, não paga nada a mais. Isso porque não resultará em uma operação de classificação explícita no plano, independentemente de você ordenar o resultado por rn ou n.
Aqui está um teste para demonstrar isso:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Você obtém o mesmo plano mostrado anteriormente na Figura 5.
Aqui estão as estatísticas de tempo que obtive para este teste;
Tempo de CPU =7578 ms, tempo decorrido =7582 ms.
E aqui estão as estatísticas de E/S:
Tabela 'NullBits4B'. Contagem de varredura 1, leitura lógica 0, leitura física 0, servidor de página lê 0, leitura antecipada lê 0, leitura antecipada do servidor de página lê 0, leitura lógica lob 194 , leituras físicas de lob 0, servidor de página lob lê 0, leitura antecipada de lob lê 0, leitura antecipada de servidor de página lob lê 0.
Tabela 'NullBits4B'. O segmento lê 96 , segmento ignorado 0.
Eles são basicamente os mesmos que no teste sem a ordenação.
Solução 2 por John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
A solução de John é rápida e simples. Isso é fantástico. A única desvantagem é o tempo de carregamento. Às vezes, isso não será um problema, pois o carregamento acontece apenas uma vez. Mas se for um problema, você pode preencher a tabela com 102.400 linhas em vez de 4B linhas e usar uma junção cruzada entre duas instâncias da tabela e um filtro TOP para gerar o máximo desejado de 4B linhas. Observe que para obter 4B linhas bastaria preencher a tabela com 65.536 linhas e então aplicar uma junção cruzada; no entanto, para que os dados sejam compactados imediatamente—em vez de serem carregados em um armazenamento delta baseado em rowstore—você precisa carregar a tabela com um mínimo de 102.400 linhas.
Aqui está o código para criar e preencher a tabela:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO O tempo de carregamento é insignificante - 43 ms na minha máquina.
Verifique o tamanho da tabela no disco:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Eu tenho 56 KB de espaço necessário para os dados.
Verifique o número de rowgroups, seu estado (compactado ou aberto) e seu tamanho:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Obtive a seguinte saída:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Apenas um grupo de linhas é necessário aqui; é compactado e o tamanho é insignificante de 293 bytes.
Se você preencher a tabela com uma linha a menos (102.399), obterá um armazenamento delta aberto não compactado baseado em rowstore. Nesse caso, sp_spaceused relata o tamanho dos dados no disco de mais de 1 MB e sys.column_store_row_groups relata as seguintes informações:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Portanto, certifique-se de preencher a tabela com 102.400 linhas!
Aqui está a definição da função dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Vamos testar o desempenho da função:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Eu tenho o plano mostrado na Figura 6 para esta execução.
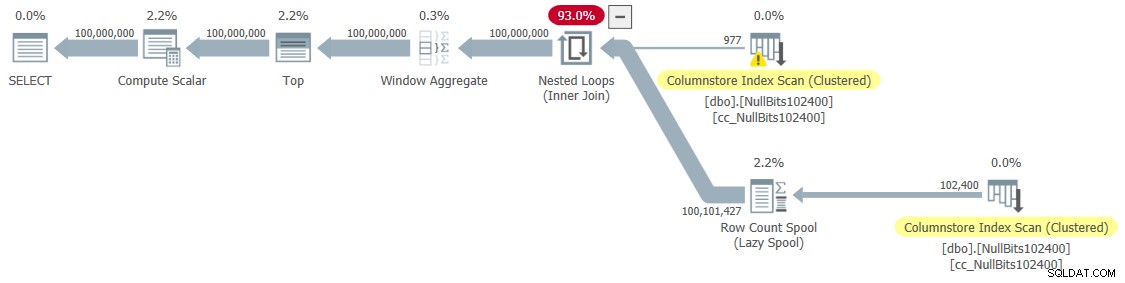 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.
As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.
And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
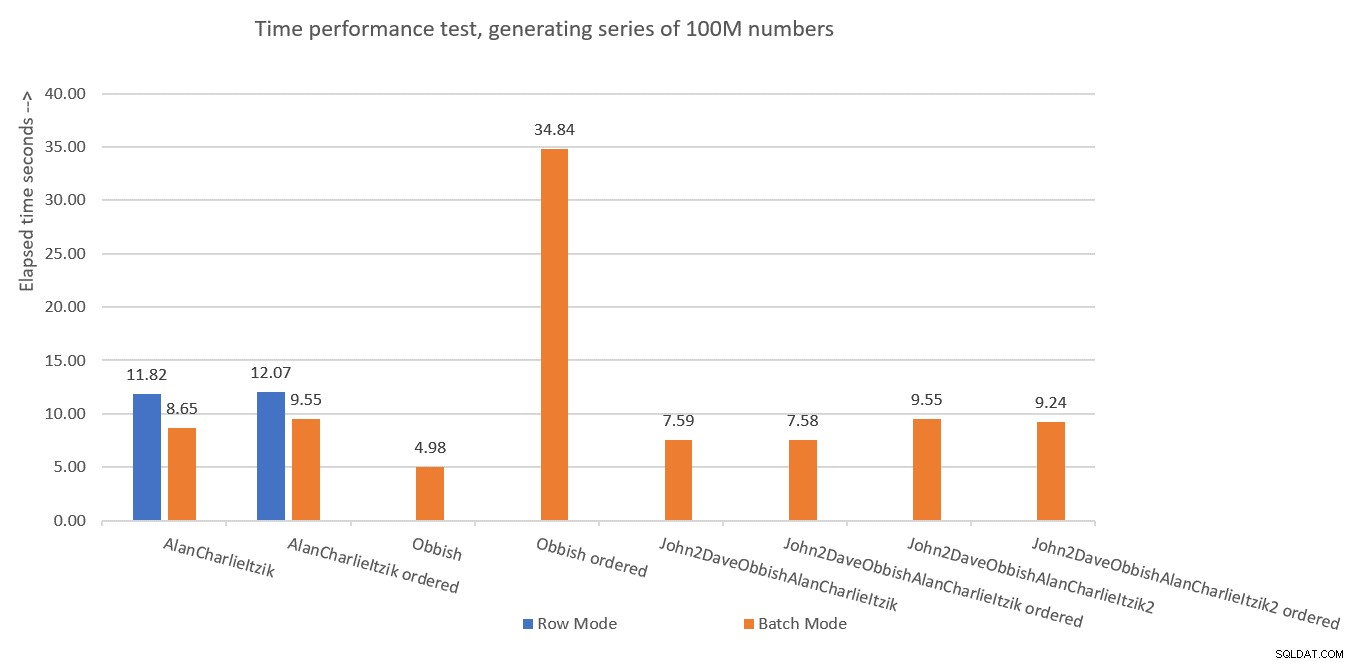 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions Figure 8 has a summary of the I/O statistics.
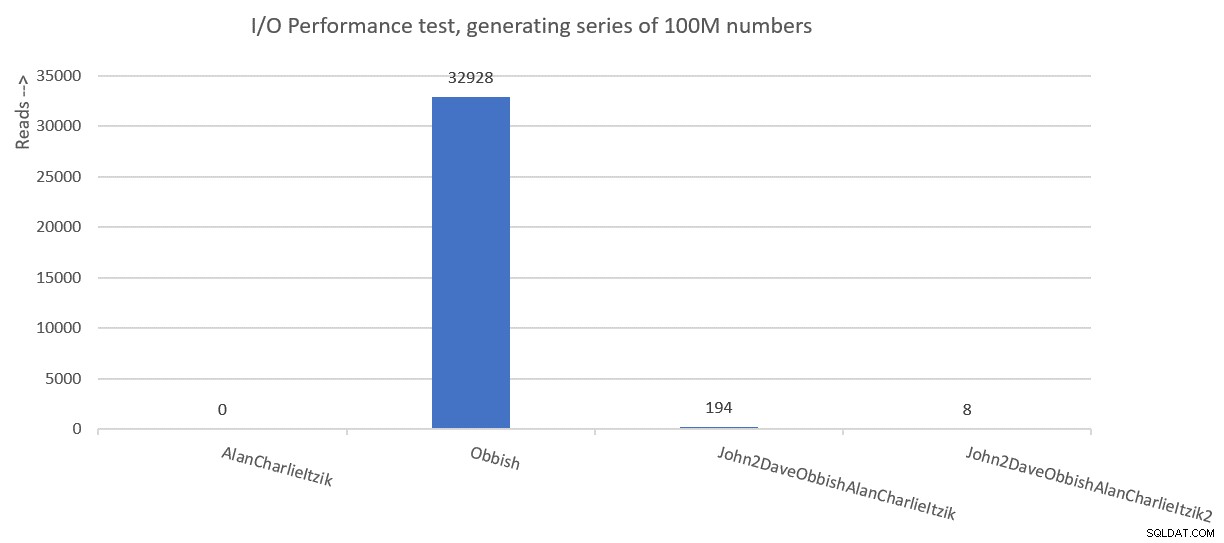 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. No próximo mês, continuarei explorando soluções adicionais.