Vendor lock-in é um conceito bem conhecido para tecnologias de banco de dados. Com o aumento do uso da nuvem, esse aprisionamento também se expandiu para incluir provedores de nuvem. Podemos definir o aprisionamento do fornecedor como um aprisionamento proprietário que torna um cliente dependente de um fornecedor para seus produtos ou serviços. Às vezes, esse aprisionamento não significa que você não pode alterar o fornecedor/fornecedor, mas pode ser uma tarefa cara ou demorada.
PostgreSQL, uma tecnologia de banco de dados de código aberto, não tem o problema de aprisionamento do fornecedor em si, mas se você estiver executando seus sistemas na nuvem, é provável que você precise lidar com esse assunto em algum momento.
Neste blog, compartilharemos algumas dicas sobre como evitar o bloqueio do PostgreSQL na nuvem e também veremos como o ClusterControl pode ajudar a evitá-lo.
Dica 1:verifique as limitações ou restrições do provedor de nuvem
Os provedores de nuvem geralmente oferecem uma maneira simples e amigável (ou até mesmo uma ferramenta) de migrar seus dados para a nuvem. O problema é que, quando você deseja deixá-los, pode ser difícil encontrar uma maneira fácil de migrar os dados para outro provedor ou para uma configuração local. Essa tarefa geralmente tem um custo alto (muitas vezes baseado na quantidade de tráfego).
Para evitar esse problema, você deve sempre primeiro verificar a documentação do provedor de nuvem e as limitações para conhecer as restrições que podem ser inevitáveis ao sair.
Dica 2:Planeje antecipadamente uma saída de provedor de nuvem
A melhor recomendação que podemos dar a você é não esperar até o último minuto para saber como sair do seu provedor de nuvem. Você deve planejar com bastante antecedência para saber a melhor, mais rápida e menos cara maneira de sair.,
Como esse plano provavelmente depende de seus requisitos de negócios específicos, o plano será diferente dependendo de você poder agendar janelas de manutenção e se a empresa aceitar quaisquer períodos de inatividade. Planejando com antecedência, você definitivamente evitará uma dor de cabeça no final do dia.
Dica 3:evite usar produtos exclusivos de provedor de nuvem
O produto de um provedor de nuvem quase sempre funcionará melhor do que um produto de código aberto. Isso se deve ao fato de ter sido projetado e testado para rodar na infraestrutura do provedor de nuvem. O desempenho será muitas vezes consideravelmente melhor do que o segundo.
Se você precisar migrar seus bancos de dados para outro provedor, terá o problema de bloqueio de tecnologia, pois o produto do provedor de nuvem está disponível apenas no ambiente atual do provedor de nuvem. Isso significa que você não poderá migrar facilmente. Você provavelmente pode encontrar uma maneira de fazer isso gerando um arquivo de despejo (ou outro método de backup), mas provavelmente terá um longo período de inatividade (dependendo da quantidade de dados e tecnologias que deseja usar).
Se você estiver usando Amazon RDS ou Aurora, Banco de Dados SQL do Azure ou Google Cloud SQL (para se concentrar nos provedores de nuvem mais usados atualmente), considere verificar as alternativas para migrá-lo para um código aberto base de dados. Com isso, não estamos dizendo que você deve migrá-lo, mas definitivamente deve ter a opção de fazê-lo, se necessário.
Dica nº 4:armazene seus backups em outro provedor de nuvem
Uma boa prática para diminuir o tempo de inatividade, seja no caso de migração ou para recuperação de desastres, é não apenas armazenar backups no mesmo local (para uma recuperação mais rápida), mas também armazenar backups em um provedor de nuvem diferente ou até mesmo local.
Seguindo esta prática quando você precisar restaurar ou migrar seus dados, você só precisa copiar os dados mais recentes após o backup ter sido feito. A quantidade de tráfego e o tempo serão consideravelmente menores do que copiar todos os dados sem compactação durante a migração ou evento de falha.
Dica 5:use um modelo multinuvem ou híbrido
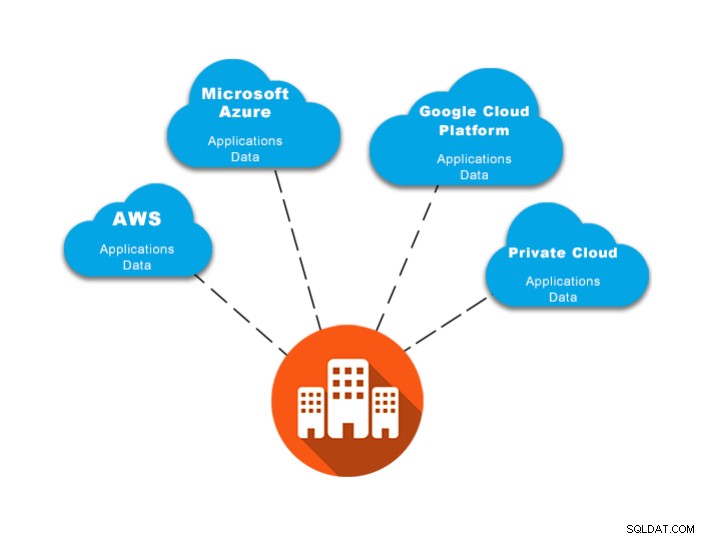
Esta é provavelmente a melhor opção se você quiser evitar o bloqueio da nuvem . Armazenar os dados em dois ou mais lugares em tempo real (ou o mais próximo possível do tempo real) permite migrar de forma rápida e com o menor tempo de inatividade possível. Se você tiver um cluster PostgreSQL em um provedor de nuvem e tiver um nó standby do PostgreSQL em outro, caso precise alterar seu provedor, basta promover o nó standby e enviar o tráfego para esse novo nó PostgreSQL primário.
Um conceito semelhante é aplicado ao modelo híbrido. Você pode manter seu cluster de produção na nuvem e, em seguida, criar um cluster em espera ou um nó de banco de dados no local, que gera uma topologia híbrida (nuvem/no local) e, em caso de falha ou necessidade de migração, você pode promover o nó de espera sem nenhum bloqueio de nuvem, pois você está usando seu próprio ambiente.
Nesse caso, tenha em mente que provavelmente o provedor de nuvem cobrará pelo tráfego de saída, portanto, sob tráfego intenso, manter esse método funcionando pode gerar um custo excessivo para a empresa.
Como o ClusterControl pode ajudar a evitar o bloqueio do PostgreSQL
Para evitar o bloqueio do PostgreSQL, você também pode usar o ClusterControl para implantar (ou importar), gerenciar e monitorar seus clusters de banco de dados. Dessa forma, você não dependerá de uma tecnologia ou provedor específico para manter seus sistemas funcionando.
ClusterControl tem uma interface de usuário amigável e fácil de usar, então você não precisa usar um console de gerenciamento de provedor de nuvem para gerenciar seus bancos de dados, você só precisa fazer login e você terá um visão geral de todos os clusters de banco de dados no mesmo sistema.
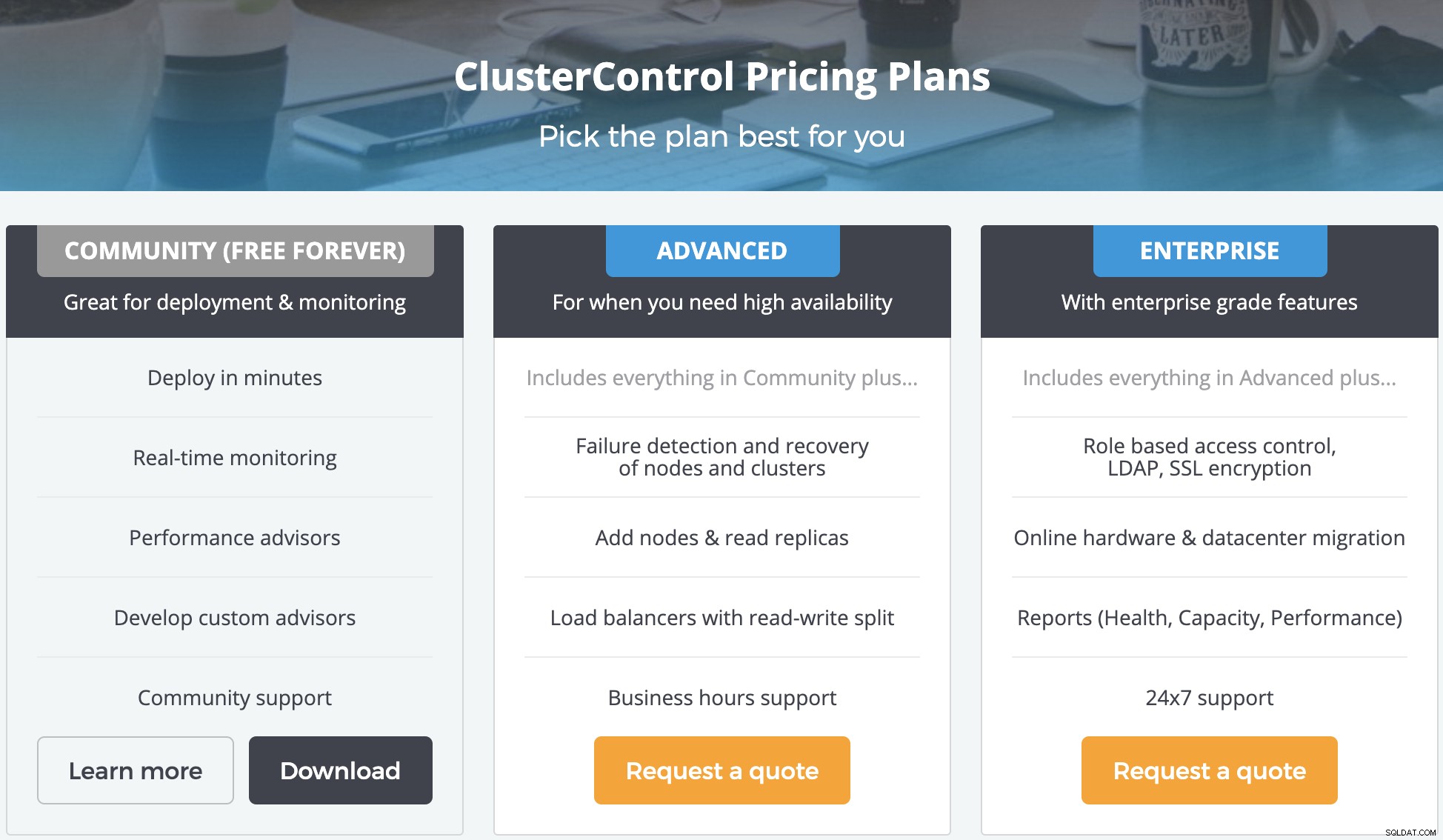
Tem três versões diferentes (incluindo uma versão gratuita da comunidade). Você ainda pode usar o ClusterControl (sem alguns recursos pagos) mesmo que sua licença tenha expirado e isso não afetará o desempenho do seu banco de dados.
Você pode implantar diferentes mecanismos de banco de dados de código aberto do mesmo sistema e apenas Acesso SSH e um usuário privilegiado é necessário para usá-lo.
O ClusterControl também pode ajudar a gerenciar seu sistema de backup. A partir daqui, você pode agendar um novo backup usando diferentes métodos de backup (dependendo do mecanismo de banco de dados), compactar, criptografar, verificar seus backups restaurando-os em um nó diferente. Você também pode armazená-lo em vários locais diferentes ao mesmo tempo (incluindo a nuvem).
A implementação multinuvem ou híbrida é facilmente realizável com ClusterControl usando o Replicação cluster a cluster ou o recurso Add Replication Slave. Você só precisa seguir um assistente simples para implantar um novo nó de banco de dados ou cluster em um local diferente.
Conclusão
Como os dados são provavelmente o ativo mais importante para a empresa, provavelmente você desejará manter os dados o mais controlados possível. Ter um bloqueio na nuvem não ajuda nisso. Se você estiver em um cenário de bloqueio na nuvem, isso significa que você não pode gerenciar seus dados como deseja, e isso pode ser um problema.
No entanto, o bloqueio da nuvem nem sempre é um problema. É possível que você esteja executando todo o seu sistema (bancos de dados, aplicativos, etc.) no mesmo provedor de nuvem usando os produtos do provedor (Amazon RDS ou Aurora, Banco de Dados SQL do Azure ou Google Cloud SQL) e não esteja procurando por migrando qualquer coisa, em vez disso, é possível que você esteja aproveitando todos os benefícios do provedor de nuvem. Evitar o bloqueio da nuvem nem sempre é uma obrigação, pois depende de cada caso.
Esperamos que você tenha gostado do nosso blog compartilhando as maneiras mais comuns de evitar um bloqueio na nuvem do PostgreSQL e como o ClusterControl pode ajudar.