Não existe um sistema, hardware ou topologia perfeitos para evitar todos os possíveis problemas que podem ocorrer em um ambiente de produção. Superar esses desafios requer um DRP (Plano de Recuperação de Desastres) eficaz, configurado de acordo com seus requisitos de aplicativo, infraestrutura e negócios. A chave para o sucesso nesses tipos de situações é sempre a rapidez com que podemos corrigir ou recuperar o problema.
Neste blog, veremos os cenários de falha mais comuns do PostgreSQL e mostraremos como você pode resolver ou lidar com os problemas. Também veremos como o ClusterControl pode nos ajudar a voltar a ficar online
A topologia comum do PostgreSQL
Para entender os cenários de falhas comuns, você deve primeiro começar com uma topologia comum do PostgreSQL. Pode ser qualquer aplicativo conectado a um Nó Primário PostgreSQL que tenha uma réplica conectada a ele.
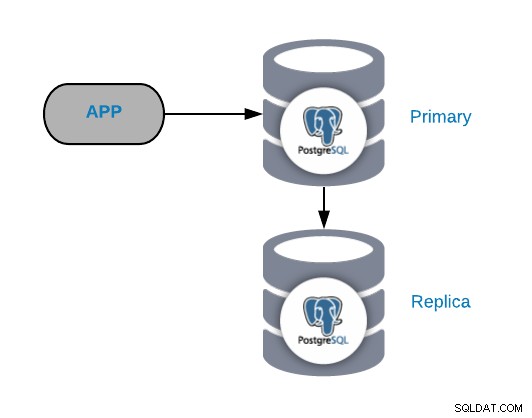
Você sempre pode melhorar ou expandir essa topologia adicionando mais nós ou balanceadores de carga , mas esta é a topologia básica com a qual começaremos a trabalhar.
Falha no nó principal do PostgreSQL
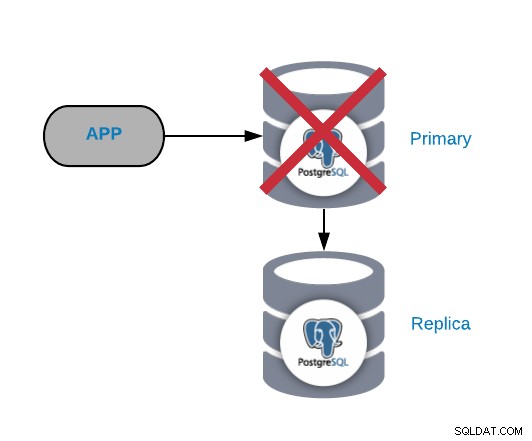
Esta é uma das falhas mais críticas, pois devemos corrigi-la o mais rápido possível se queremos manter nossos sistemas online. Para esse tipo de falha, é importante ter algum tipo de mecanismo de failover automático. Após a falha, você pode investigar o motivo dos problemas. Após o processo de failover, garantimos que o nó primário com falha ainda não pense que é o nó primário. Isso é para evitar inconsistência de dados ao gravar nele.
As causas mais comuns desse tipo de problema são uma falha do sistema operacional, falha de hardware ou falha de disco. Em qualquer caso, devemos verificar o banco de dados e os logs do sistema operacional para encontrar o motivo.
A solução mais rápida para este problema é realizar uma tarefa de failover para reduzir o tempo de inatividade. aplicativo para o novo nó primário. Para esta última tarefa, podemos implementar um balanceador de carga entre nosso aplicativo e os nós do banco de dados, para evitar qualquer alteração do lado do aplicativo em caso de falha. Também podemos configurar o load balancer para detectar a falha do nó e ao invés de enviar tráfego para ele, enviar o tráfego para o novo nó primário.
Após o processo de failover e verificar se o sistema está funcionando novamente, podemos analisar o problema e recomendamos manter sempre pelo menos um nó escravo funcionando, portanto, em caso de uma nova falha primária, podemos executar a tarefa de failover novamente.
Falha no nó de réplica PostgreSQL
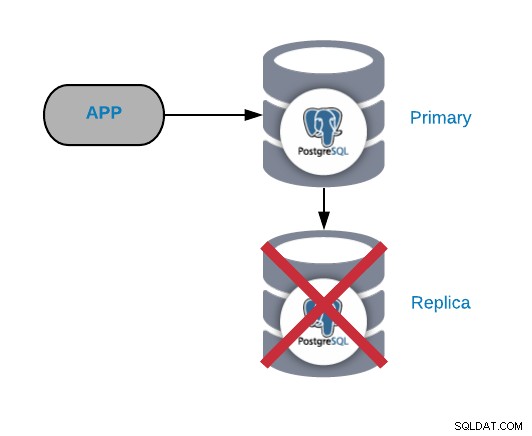
Isso normalmente não é um problema crítico (desde que você tenha mais de uma réplica e não a está usando para enviar o tráfego de produção de leitura). Se você estiver enfrentando problemas no nó primário e não tiver sua réplica atualizada, você terá um problema realmente crítico. Se você estiver usando nossa réplica para fins de relatórios ou big data, provavelmente desejará corrigi-la rapidamente de qualquer maneira.
As causas mais comuns desse tipo de problema são as mesmas que vimos para o nó primário, uma falha do sistema operacional, falha de hardware ou falha de disco. Você deve verificar o banco de dados e os logs do sistema operacional para encontrar o motivo.
Não é recomendável manter o sistema funcionando sem nenhuma réplica, pois, em caso de falha, você não tem uma maneira rápida de voltar a ficar online. Se você tiver apenas um escravo, deverá resolver o problema o mais rápido possível; a maneira mais rápida é criar uma nova réplica do zero. Para isso, você precisará fazer um backup consistente e restaurá-lo no nó escravo, depois configurar a replicação entre este nó escravo e o nó primário.
Se você deseja saber o motivo da falha, deve usar outro servidor para criar a nova réplica e, em seguida, examinar o antigo para descobri-lo. Ao concluir essa tarefa, você também pode reconfigurar a réplica antiga e manter ambas funcionando como uma opção de failover futuro.
Se você estiver usando a réplica para relatórios ou para fins de big data, deverá alterar o endereço IP para se conectar ao novo. Assim como no caso anterior, uma forma de evitar essa alteração é usar um balanceador de carga que saberá o status de cada servidor, permitindo adicionar/remover réplicas conforme desejar.
Falha na replicação do PostgreSQL
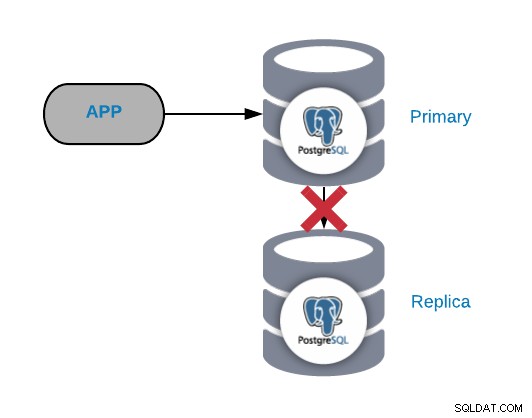
Em geral, esse tipo de problema é gerado devido a uma rede ou configuração questão. Está relacionado a uma perda de WAL (Write-Ahead Logging) no nó primário e a forma como o PostgreSQL gerencia a replicação.
Se você tem tráfego importante, está fazendo checkpoints com muita frequência ou está armazenando WALS por apenas alguns minutos; se você tiver um problema de rede, terá pouco tempo para resolvê-lo. Seus WALs seriam excluídos antes que você pudesse enviá-los e aplicá-los à réplica.
Se o WAL que a réplica precisa para continuar funcionando foi deletado você precisa reconstruí-lo, então para evitar essa tarefa, devemos verificar nossa configuração de banco de dados para aumentar os wal_keep_segments (quantidades de WALS para manter no pg_xlog) ou os parâmetros max_wal_senders (número máximo de processos do remetente WAL em execução simultânea).
Outra opção recomendada é configurar archive_mode e enviar os arquivos WAL para outro caminho com o parâmetro archive_command. Dessa forma, se o PostgreSQL atingir o limite e deletar o arquivo WAL, nós o teremos em outro caminho de qualquer maneira.
Corrupção de dados do PostgreSQL/inconsistência de dados/exclusão acidental

Este é um pesadelo para qualquer DBA e provavelmente o problema mais complexo a ser corrigido, dependendo da extensão do problema.
Quando seus dados são afetados por alguns desses problemas, a maneira mais comum de corrigi-los (e provavelmente a única) é restaurar um backup. É por isso que os backups são a forma básica de qualquer plano de recuperação de desastres e é recomendável que você tenha pelo menos três backups armazenados em locais físicos diferentes. A prática recomendada determina que os arquivos de backup devem ter um armazenado localmente no servidor de banco de dados (para uma recuperação mais rápida), outro em um servidor de backup centralizado e o último na nuvem.
Também podemos criar uma combinação de backups completos/incrementais/diferenciais compatíveis com PITR para reduzir nosso objetivo de ponto de recuperação.
Gerenciando falhas do PostgreSQL com ClusterControl
Agora que analisamos esses cenários comuns de falhas do PostgreSQL, vamos ver o que aconteceria se estivéssemos gerenciando seus bancos de dados PostgreSQL a partir de um sistema de gerenciamento de banco de dados centralizado. Um que é ótimo em termos de alcançar uma maneira rápida e fácil de corrigir o problema, o mais rápido possível, em caso de falha.
ClusterControl fornece automação para a maioria das tarefas do PostgreSQL descritas acima; tudo de forma centralizada e amigável. Com este sistema você poderá configurar facilmente coisas que, manualmente, levariam tempo e esforço. Analisaremos agora algumas de suas principais funcionalidades relacionadas aos cenários de falha do PostgreSQL.
Implantar/Importar um cluster PostgreSQL
Uma vez que entramos na interface ClusterControl, a primeira coisa a fazer é implantar um novo cluster ou importar um existente. Para realizar uma implantação, basta selecionar a opção Deploy Database Cluster e seguir as instruções que aparecem.
Escalando seu cluster PostgreSQL
Se você for para Cluster Actions e selecionar Add Replication Slave, poderá criar uma nova réplica do zero ou adicionar um banco de dados PostgreSQL existente como uma réplica. Desta forma, você pode ter sua nova réplica rodando em poucos minutos e podemos adicionar quantas réplicas quisermos; espalhando o tráfego de leitura entre eles usando um balanceador de carga (que também podemos implementar com o ClusterControl).
Failover automático do PostgreSQL
ClusterControl gerencia o failover em sua configuração de replicação. Ele detecta falhas no mestre e promove um escravo com os dados mais atuais como o novo mestre. Ele também faz failover automático do restante dos escravos para replicar a partir do novo mestre. Quanto às conexões do cliente, ele aproveita duas ferramentas para a tarefa:HAProxy e Keepalived.
HAProxy é um balanceador de carga que distribui o tráfego de uma origem para um ou mais destinos e pode definir regras e/ou protocolos específicos para a tarefa. Se algum dos destinos parar de responder, ele será marcado como off-line e o tráfego será enviado para um dos destinos disponíveis. Isso evita que o tráfego seja enviado para um destino inacessível e a perda dessas informações ao direcioná-lo para um destino válido.
Keepalived permite configurar um IP virtual dentro de um grupo ativo/passivo de servidores. Este IP virtual é atribuído a um servidor “Principal” ativo. Caso este servidor falhe, o IP é automaticamente migrado para o servidor “Secundário” que foi considerado passivo, permitindo que ele continue trabalhando com o mesmo IP de forma transparente para nossos sistemas.
Adicionando um balanceador de carga PostgreSQL
Se você for para Cluster Actions e selecionar Add Load Balancer (ou na visualização de cluster - vá para Manage -> Load Balancer), você pode adicionar load balancers à nossa topologia de banco de dados.
A configuração necessária para criar seu novo balanceador de carga é bastante simples. Você só precisa adicionar IP/Nome do host, porta, política e os nós que vamos usar. Você pode adicionar dois load balancers com Keepalived entre eles, o que nos permite ter um failover automático do nosso load balancer em caso de falha. O Keepalived usa um endereço IP virtual e o migra de um balanceador de carga para outro em caso de falha, para que nossa configuração possa continuar funcionando normalmente.
Backups do PostgreSQL
Já discutimos a importância de ter backups. ClusterControl fornece a funcionalidade para gerar um backup imediato ou agendar um.
Você pode escolher entre três métodos de backup diferentes, pgdump, pg_basebackup ou pgBackRest. Você também pode especificar onde armazenar os backups (no servidor de banco de dados, no servidor ClusterControl ou na nuvem), o nível de compactação, a criptografia necessária e o período de retenção.
Monitoramento e alerta do PostgreSQL
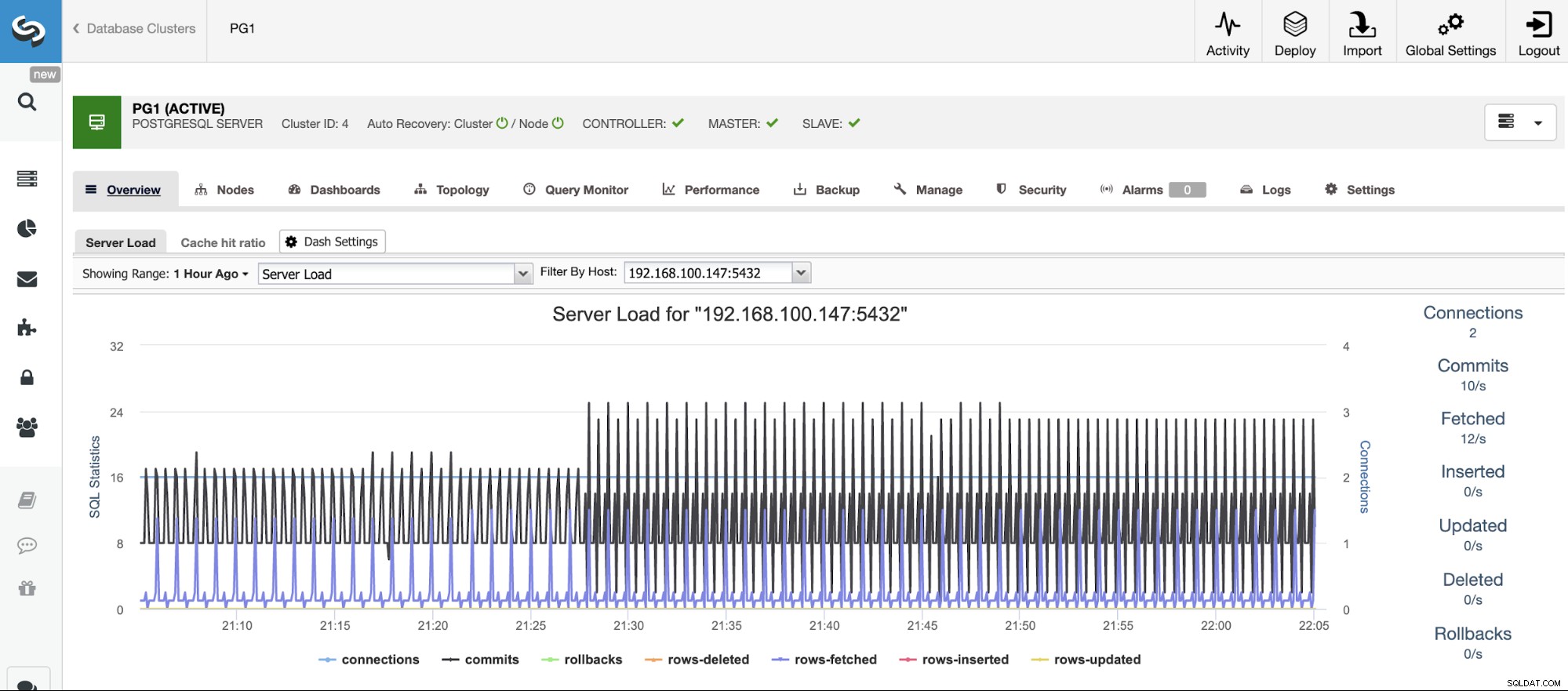
Antes de poder agir, você precisa saber o que está acontecendo, portanto, será necessário monitorar seu cluster de banco de dados. ClusterControl permite monitorar nossos servidores em tempo real. Existem gráficos com dados básicos como CPU, Rede, Disco, RAM, IOPS, além de métricas específicas do banco de dados coletadas das instâncias do PostgreSQL. As consultas de banco de dados também podem ser visualizadas no Monitor de Consultas.
Da mesma forma que você habilita o monitoramento do ClusterControl, você também pode configurar alertas que informam sobre eventos em seu cluster. Esses alertas são configuráveis e podem ser personalizados conforme necessário.
Conclusão
Todos eventualmente precisarão lidar com problemas e falhas do PostgreSQL. E como você não pode evitar o problema, você precisa consertá-lo o mais rápido possível e manter o sistema funcionando. Também vimos como o uso do ClusterControl pode ajudar com esses problemas; tudo a partir de uma plataforma única e fácil de usar.
Estes são os cenários de falha mais comuns para o PostgreSQL. Gostaríamos muito de ouvir sobre suas próprias experiências e como você a corrigiu.