Em janeiro de 2015, meu bom amigo e colega MVP do SQL Server Rob Farley escreveu sobre uma nova solução para o problema de encontrar a mediana nas versões do SQL Server anteriores a 2012. Além de ser uma leitura interessante por si só, acaba sendo um ótimo exemplo a ser usado para demonstrar algumas análises avançadas do plano de execução e para destacar alguns comportamentos sutis do otimizador de consultas e do mecanismo de execução.
Media Única
Embora o artigo de Rob tenha como alvo específico um cálculo de mediana agrupada, vou começar aplicando seu método a um grande problema de cálculo de mediana única, porque ele destaca as questões importantes com mais clareza. Os dados de amostra mais uma vez virão do artigo original de Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Aplicando a técnica de Rob Farley a este problema dá o seguinte código:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
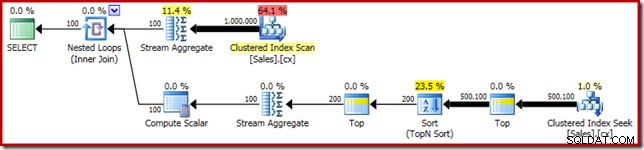
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Como de costume, comentei a contagem do número de linhas na tabela e a substituí por uma constante para evitar uma fonte de variação de desempenho. O plano de execução para a consulta importante é o seguinte:

Esta consulta é executada por 5800 ms na minha máquina de teste.
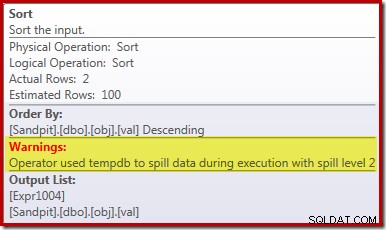
O derramamento de classificação
A principal causa desse desempenho ruim deve ficar clara ao observar o plano de execução acima:O aviso no operador Sort mostra que uma concessão de memória de espaço de trabalho insuficiente causou um derramamento de nível 2 (várias passagens) no tempdb disco:
Nas versões do SQL Server anteriores a 2012, você precisaria monitorar separadamente os eventos de derramamento de classificação para ver isso. De qualquer forma, a reserva insuficiente de memória de ordenação é causada por um erro de estimativa de cardinalidade, como mostra o plano de pré-execução (estimado):

A estimativa de cardinalidade de 100 linhas na entrada Sort é uma estimativa (descontroladamente imprecisa) do otimizador, devido à expressão da variável local no operador Top anterior:

Observe que esse erro de estimativa de cardinalidade não é um problema de meta de linha. A aplicação do sinalizador de rastreamento 4138 removerá o efeito de meta de linha abaixo do primeiro Top, mas a estimativa pós-Top ainda será uma estimativa de 100 linhas (portanto, a reserva de memória para o Sort ainda será muito pequena):

Indicando o valor da variável local
Existem várias maneiras de resolver esse problema de estimativa de cardinalidade. Uma opção é usar uma dica para fornecer ao otimizador informações sobre o valor mantido na variável:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O uso da dica melhora o desempenho para 3250 ms de 5800 ms. O plano de pós-execução mostra que a classificação não é mais derramada:

Existem algumas desvantagens para isso embora. Primeiro, este novo plano de execução requer 388 MB concessão de memória – memória que poderia ser usada pelo servidor para armazenar planos, índices e dados em cache:
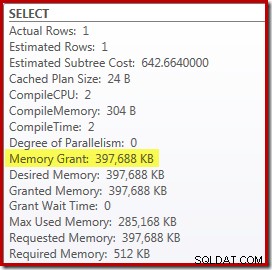
Segundo, pode ser difícil escolher um bom número para a dica que funcionará bem para todas as execuções futuras, sem reservar memória desnecessariamente.
Observe também que tivemos que sugerir um valor para a variável que é 10% maior que o valor real da variável para eliminar completamente o derramamento. Isso não é incomum, porque o algoritmo de ordenação geral é bem mais complexo do que uma ordenação simples no local. Reservar memória igual ao tamanho do conjunto a ser classificado nem sempre (ou mesmo geralmente) será suficiente para evitar um derramamento em tempo de execução.
Incorporando e recompilando
Outra opção é aproveitar a Otimização de Incorporação de Parâmetros habilitada adicionando uma dica de recompilação em nível de consulta no SQL Server 2008 SP1 CU5 ou posterior. Essa ação permitirá que o otimizador veja o valor de tempo de execução da variável e otimize de acordo:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Isso melhora o tempo de execução para 3150ms – 100ms melhor do que usar o
OPTIMIZE FOR dica. A razão para esta pequena melhoria adicional pode ser discernida a partir do novo plano pós-execução:
A expressão
(2 – @Count % 2) – como visto anteriormente no segundo operador Top – agora pode ser dobrado para um único valor conhecido. Uma reescrita de pós-otimização pode então combinar o Top com o Sort, resultando em um único Top N Sort. Essa reescrita não era possível anteriormente porque recolher Top + Sort em uma Top N Sort só funciona com um valor Top literal constante (não variáveis ou parâmetros). Substituir o Top e Sort por um Top N Sort tem um pequeno efeito benéfico no desempenho (100ms aqui), mas também elimina quase totalmente o requisito de memória, porque um Top N Sort só precisa acompanhar o N mais alto (ou mais baixo) linhas, em vez de todo o conjunto. Como resultado dessa mudança no algoritmo, o plano pós-execução dessa consulta mostra que o mínimo de 1 MB a memória foi reservada para o Top N Sort neste plano e apenas 16 KB foi usado em tempo de execução (lembre-se, o plano de classificação completa exigia 388 MB):
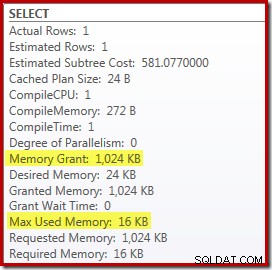
Evitando a recompilação
A desvantagem (óbvia) de usar a dica de consulta de recompilação é que ela requer uma compilação completa em cada execução. Nesse caso, a sobrecarga é bem pequena – cerca de 1 ms de tempo de CPU e 272 KB de memória. Mesmo assim, existe uma maneira de ajustar a consulta de forma que obtenhamos os benefícios de um Top N Sort sem usar nenhuma dica e sem recompilar.
A ideia vem do reconhecimento de que um máximo de duas linhas será necessário para o cálculo da mediana final. Pode ser uma linha ou duas em tempo de execução, mas nunca pode ser mais. Esse insight significa que podemos adicionar uma etapa intermediária logicamente redundante Top (2) à consulta da seguinte maneira:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O novo Top (com o literal constante muito importante) significa que o plano de execução final apresenta o operador Top N Sort desejado sem recompilar:

O desempenho deste plano de execução permanece inalterado em relação à versão com sugestão de recompilação em 3150ms e o requisito de memória é o mesmo. Observe que a falta de incorporação de parâmetros significa que as estimativas de cardinalidade abaixo da classificação são suposições de 100 linhas (embora isso não afete o desempenho aqui).
A principal conclusão neste estágio é que, se você deseja uma classificação Top N com pouca memória, é necessário usar um literal constante ou permitir que o otimizador veja um literal por meio da otimização de incorporação de parâmetros.
A computação escalar
Eliminando os 388 MB a concessão de memória (ao mesmo tempo em que melhora o desempenho de 100ms) certamente vale a pena, mas há uma vitória de desempenho muito maior disponível. O alvo improvável dessa melhoria final é o Compute Scalar logo acima do Clustered Index Scan.
Este Compute Scalar está relacionado à expressão
(0E + f.val) contido no AVG agregado na consulta. Caso isso pareça estranho para você, este é um truque de escrita de consulta bastante comum (como multiplicar por 1,0) para evitar aritmética inteira no cálculo da média, mas tem alguns efeitos colaterais muito importantes. Há uma sequência particular de eventos aqui que precisamos seguir passo a passo.
Primeiro, observe que
0E é um zero literal constante, com um float tipo de dados. Para adicionar isso à coluna inteira val, o processador de consultas deve converter a coluna de inteiro para flutuante (de acordo com as regras de precedência de tipo de dados). Um tipo semelhante de conversão seria necessário se tivéssemos escolhido multiplicar a coluna por 1,0 (um literal com um tipo de dados numérico implícito). O ponto importante é que este truque de rotina introduz uma expressão . Agora, o SQL Server geralmente tenta enviar expressões a árvore do plano tanto quanto possível durante a compilação e otimização. Isso é feito por vários motivos, inclusive para facilitar a correspondência de expressões com colunas computadas e para facilitar as simplificações usando informações de restrição. Essa política de push-down explica por que o Compute Scalar parece muito mais próximo do nível folha do plano do que a posição textual original da expressão na consulta sugeriria.
Um risco de executar esse push-down é que a expressão pode acabar sendo computada mais vezes do que o necessário. A maioria dos planos apresenta uma contagem de linhas reduzida à medida que avançamos na árvore de planos, devido ao efeito de junções, agregação e filtros. Empurrar expressões para baixo na árvore, portanto, corre o risco de avaliar essas expressões mais vezes (ou seja, em mais linhas) do que o necessário.
Para mitigar isso, o SQL Server 2005 introduziu uma otimização em que os Compute Scalars podem simplesmente definir uma expressão, com o trabalho de realmente avaliar a expressão diferido até que um operador posterior no plano exija o resultado. Quando essa otimização funciona como pretendido, o efeito é obter todos os benefícios de empurrar expressões para baixo na árvore, enquanto ainda avalia a expressão apenas quantas vezes forem realmente necessárias.
O que todas essas coisas de Compute Scalar significam
Em nosso exemplo em execução, o
0E + val expressão foi originalmente associada ao AVG agregado, então podemos esperar vê-lo no (ou um pouco depois) do Stream Aggregate. No entanto, esta expressão foi reduzida a árvore para se tornar um novo Compute Scalar logo após a varredura, com a expressão rotulada como [Expr1004]. Observando o plano de execução, podemos ver que [Expr1004] é referenciado pelo Stream Aggregate (extrato da guia Expressões do Plan Explorer mostrado abaixo):

Todas as coisas sendo iguais, a avaliação da expressão [Expr1004] seria adiada até que o agregado precise desses valores para a parte somatória do cálculo da média. Como a agregação só pode encontrar uma ou duas linhas, isso deve resultar em [Expr1004] sendo avaliado apenas uma ou duas vezes:
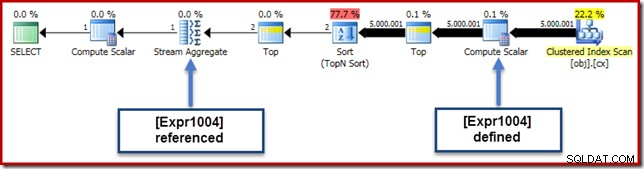
Infelizmente, não é bem assim que funciona aqui. O problema é o bloqueio do operador Sort:
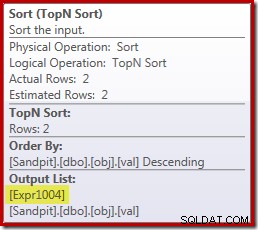
Isso força a avaliação de [Expr1004], então, em vez de ser avaliado apenas uma ou duas vezes no Stream Aggregate, o Sort significa que acabamos convertendo o
val coluna para um float e adicionando zero a ele 5.000.001 vezes! Uma solução alternativa
Idealmente, o SQL Server seria um pouco mais inteligente sobre tudo isso, mas não é assim que funciona hoje. Não há dica de consulta para evitar que as expressões sejam empurradas para baixo na árvore de plano e também não podemos forçar escalares de computação com um guia de plano. Há, inevitavelmente, um sinalizador de rastreamento não documentado, mas não é um sobre o qual eu possa falar com responsabilidade no contexto atual.
Então, para o bem ou para o mal, isso nos deixa com a tentativa de encontrar uma reescrita de consulta que impeça o SQL Server de separar a expressão da agregação e enviá-la para baixo além do Sort, sem alterar o resultado da consulta. Isso não é tão fácil quanto você imagina, mas a modificação (reconhecidamente um pouco estranha) abaixo consegue isso usando um
CASE expressão em uma função intrínseca não determinística:-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); O plano de execução para esta forma final da consulta é mostrado abaixo:

Observe que um Compute Scalar não aparece mais entre o Clustered Index Scan e o Top. O
0E + val A expressão agora é calculada no Stream Aggregate em no máximo duas linhas (em vez de cinco milhões!) e o desempenho aumenta em mais 32% de 3150ms a 2150ms como resultado. Isso ainda não se compara tão bem com o desempenho de menos de um segundo do
OFFSET e soluções de cálculo de mediana de cursor dinâmico, mas ainda representa uma melhoria muito significativa em relação aos 5800ms originais para este método em um grande conjunto de problemas de mediana única. O truque CASE não é garantido que funcione no futuro, é claro. A conclusão não é tanto sobre o uso de truques estranhos de expressão de caso, mas sobre as possíveis implicações de desempenho de Compute Scalars. Depois de saber sobre esse tipo de coisa, você pode pensar duas vezes antes de multiplicar por 1,0 ou adicionar float zero dentro de um cálculo de média.
Atualização: por favor, veja o primeiro comentário para uma boa solução de Robert Heinig que não requer nenhum truque não documentado. Algo a ter em mente quando você for tentado a multiplicar um inteiro por decimal (ou float) um em um agregado médio.
Media Agrupada
Para completar, e para vincular esta análise mais de perto ao artigo original de Rob, terminaremos aplicando as mesmas melhorias a um cálculo de mediana agrupado. Os tamanhos de conjuntos menores (por grupo) significam que os efeitos serão menores, é claro.
Os dados de amostra mediana agrupados (novamente como originalmente criados por Aaron Bertrand) compreendem dez mil linhas para cada uma das cem pessoas de vendas imaginárias:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); A aplicação direta da solução de Rob Farley fornece o código a seguir, que é executado em 560ms na minha máquina.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); O plano de execução tem semelhanças óbvias com a mediana única:
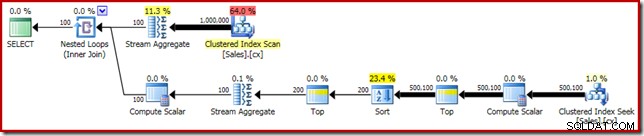
Nossa primeira melhoria é substituir o Sort por um Top N Sort, adicionando um Top (2) explícito. Isso melhora um pouco o tempo de execução de 560ms para 550ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); O plano de execução mostra o Top N Sort como esperado:
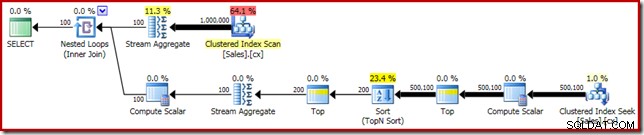
Por fim, implantamos a expressão CASE de aparência estranha para remover a expressão Compute Scalar enviada. Isso melhora ainda mais o desempenho para 450 ms (uma melhoria de 20% em relação ao original):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); O plano de execução finalizado é o seguinte: