O Grupo de Disponibilidade Always ON do SQL Server é uma solução destinada a obter alta disponibilidade e recuperação de desastres para bancos de dados SQL Server. Podemos configurar essa funcionalidade entre as instalações do SQL Server baseadas em Windows, instalações do SQL Server baseadas em Linux e até mesmo entre instalações do SQL Server baseadas em Linux e Windows juntas.
Os Grupos de Disponibilidade são totalmente integrados às tecnologias de cluster em uma forma de failover automático e proteção de dados, replicando dados para suas respectivas réplicas secundárias. No entanto, nem sempre é obrigatório ter um gerenciador de recursos de cluster para configurar grupos de disponibilidade.
Para configurar grupos de disponibilidade do SQL Server, precisamos do WSFC – Cluster de failover do Windows Server tecnologia para Windows instalações baseadas em SQL Server e PACEMAKER para Linux instalações baseadas em SQL Server.
PACEMAKER é um gerenciador de recursos de cluster de código aberto que podemos usar para gerenciar recursos e garantir a disponibilidade do sistema, caso ocorra alguma falha nos sistemas Linux.
WSFC é um produto da Microsoft desenvolvido para oferecer suporte a requisitos de cluster baseados em Windows.
Quando você observa os Grupos de Disponibilidade configurados no SQL Server para ambos os tipos de SO, parece semelhante no SQL Server Management Studio.
No entanto, este artigo explica os grupos de disponibilidade entre o SQL Server baseado em Linux Ubuntu instalações usando o PACEMAKER tecnologia de cluster, portanto, considerarei apenas essa configuração.
Configuração do tipo de cluster
Como afirmei acima, temos três variantes para configurar Grupos de Disponibilidade para SQL Server, dependendo do SO:
- entre instalações do SQL Server baseadas em Windows;
- entre instalações do SQL Server baseadas em Linux;
- entre o tipo misto de instalações do SQL Server baseadas em Windows e Linux.
A Microsoft introduziu o Cluster_type definição de configuração para identificar e configurar uma tecnologia de cluster apropriada para grupos de disponibilidade. É um item de configuração que define que tipo de tecnologia de cluster usamos para Grupos de Disponibilidade, não importa em qual SO a instância do SQL Server seja baseada.
Você pode buscar e validar a configuração existente do tipo de cluster usando SQL Server dynamic management view (DMV) sys.availability_groups . Há duas colunas chamadas cluster_type e cluster_type_desc . Podemos ler essas colunas para definir a configuração do tipo de cluster da configuração do Grupo de Disponibilidade.
Esta definição de configuração tem 3 valores para atender aos requisitos de tecnologia de cluster para cada variante:
WSFC .Você deve usar a opção WSFC (cluster de failover do Windows Server) se tiver instalações do SQL Server baseadas no Windows. Não há suporte para instalações do SQL Server baseadas em Linux.
EXTERNO . Se você estiver configurando Grupos de Disponibilidade entre instalações do SQL Server baseadas em Linux, deverá usar o gerenciador de cluster PACEMAKER e escolher a opção EXTERNAL grupo tipo . O modo de failover também deve ser EXTERNAL (no WSFC será Automático).
NENHUM . Se você não quiser usar nenhuma tecnologia de cluster para seus grupos de disponibilidade, selecione NENHUM . Essa opção é aplicável se você deseja configurar grupos de disponibilidade entre instâncias do SQL Server baseadas em Linux e Windows. Mesmo se você tiver configurado o clustering para seu sistema, depois de definir o valor do tipo de cluster como NENHUM, os Grupos de Disponibilidade não usarão a tecnologia de cluster. O modo de failover para o tipo de cluster NONE é sempre Manual .
Uma nova configuração:secundários sincronizados necessários para confirmação
A partir do SQL Server 2017, a Microsoft introduziu uma nova configuração chamada required_synchronized_secondaries_to_commit . Ele habilita a opção de failover automático se você tiver configurado o tipo de cluster como EXTERNAL para a configuração de cluster do PACEMAKER.
O valor dessa configuração é definido por padrão quando você configura o agente de recursos do SQL Server mssql-server-ha e crie a configuração do cluster.
Além disso, você pode modificar manualmente o valor para seus requisitos executando o comando abaixo:
--Run below commands to change value for setting required_synchronized_secondaries_to_commit
--AGResourceName is the name of the resource configured for the Availability group
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
Nota:Podemos alterar a configuração acima apenas via Pacemaker no Linux. É impossível modificá-lo usando a instrução T-SQL para implantações baseadas em Linux. No entanto, para implantações baseadas no Windows, podemos alterar essa configuração por uma instrução T-SQL.
Abaixo estão os valores possíveis para required_synchronized_secondaries_to_commit
0 – Isso significa que as réplicas secundárias não precisam ser sincronizadas com a respectiva réplica primária. Assim, ele não suporta o failover automático. Você precisa iniciar o failover manualmente se a réplica primária ficar inativa. Importante:há uma chance de perda de dados quando você escolhe este valor para configuração.
1 – Isso significa que pelo menos uma réplica secundária deve estar no estado sincronizado para obter o failover automático.
2 – Isso significa que ambas as réplicas secundárias devem ser sincronizadas com a réplica primária. O failover automático é suportado.
Réplicas para participar de um grupo de disponibilidade
O número de réplicas que podem participar de um Grupo de Disponibilidade depende da edição do SQL Server instalada.
- O SQL Server Padrão edição suporta apenas réplica de dois nós para um grupo de disponibilidade junto com a réplica adicional somente de configuração.
- O SQL Server Empresa edição suporta até nove réplicas – uma réplica primária e oito secundárias.
Como o SQL Server Standard Edition suporta apenas duas réplicas (uma réplica primária e uma réplica secundária), a Microsoft introduziu um novo conceito chamado réplica somente de configuração no SQL Server 2017 CU1 para obter failover automático para SQL Servers executados em sistemas Linux.
Existem duas opções de design possíveis:
- Três réplicas síncronas. Essa configuração pode ser implantada apenas com a edição SQL Server Enterprise. Haverá 3 cópias de seus bancos de dados de disponibilidade. Essa arquitetura permite todas as 3 funcionalidades em escala de leitura, alta disponibilidade e proteção de dados.
- Duas réplicas síncronas e uma réplica somente de configuração. Você também pode configurar esse design com a ajuda da edição SQL Server Standard, executando duas réplicas síncronas na edição SQL Server Standard e a 3 réplicas na edição SQL Server Express que atua como a réplica somente de configuração. É um design econômico que oferece suporte a alta disponibilidade com failover automático e proteção de banco de dados.
Réplica de dois nós
As configurações de réplica de dois nós para Grupos de Disponibilidade é uma opção de implantação muito popular para garantir a alta disponibilidade dos bancos de dados do SQL Server. Alcançamos o failover automático com a ajuda da tecnologia Windows Server Failover Cluster e uma testemunha de compartilhamento de arquivos em implantações do SQL Server baseadas em Windows.
O compartilhamento de arquivos geralmente é usado em um nó adicional no WSFC para fornecer configuração de quorum para configurações de réplica de dois nós. O WSFC sincroniza todos os metadados de configuração para ambas as réplicas e no terceiro nó ou testemunha de compartilhamento de arquivos para um failover suave. Toda a arbitragem de failover para o grupo de disponibilidade do SQL Server baseado em Windows acontece na camada WSFC.
Se quisermos obter o failover automático para implantações do SQL Server Availability Group baseadas em Linux, a configuração acima não funcionará. Isso ocorre porque o WSFC só pode ser usado para instalações do SQL Server baseadas em Windows.
Para resolver essa limitação e habilitar o failover automático para implantações de duas réplicas baseadas em Linux, a Microsoft introduziu um novo conceito.
Réplica somente de configuração
Uma réplica somente de configuração é uma opção em que instalamos uma instância adicional do SQL Server no terceiro nó. Esse nó funcionará como um servidor testemunha para a configuração de réplica de dois nós para dar suporte ao failover automático. Podemos criar uma réplica somente de configuração por grupo de disponibilidade .
Para instâncias do SQL Server baseadas em Linux em que usamos o tipo de cluster como EXTERNAL para PACEMAKER, a arbitragem de failover não funciona na camada de cluster como o WSFC. Toda a arbitragem de failover acontece na camada do SQL Server porque todos os metadados de configuração do grupo de disponibilidade são armazenados nos bancos de dados mestre de cada réplica.
A Microsoft introduziu o conceito de réplica somente de configuração para lidar com quorum para grupos de disponibilidade do SQL Server baseados em Linux. Esse conceito não hospeda nenhum banco de dados de usuário para participar de um grupo de disponibilidade. Ele armazena todas as informações de configuração do Grupo de Disponibilidade no banco de dados mestre para garantir que toda a arbitragem de failover ocorra sem problemas.
Você pode usar qualquer edição do SQL Server para a réplica somente de configuração. Até mesmo a edição do SQL Server Express será adequada para economizar o custo da licença para a terceira réplica. Lembre-se de que a réplica somente de configuração não hospedará nenhum banco de dados no grupo de disponibilidade. Assim, você terá apenas duas cópias de bancos de dados em um grupo de disponibilidade.
Por padrão, required_synchronized_secondaries_to_commit está definido como 0 quando usamos a réplica somente de configuração. Podemos modificar manualmente esse valor para 1, se necessário.
Dê uma olhada no diagrama de design da réplica síncrona de dois nós e uma réplica somente de configuração para obter failover automático e proteção de dados.
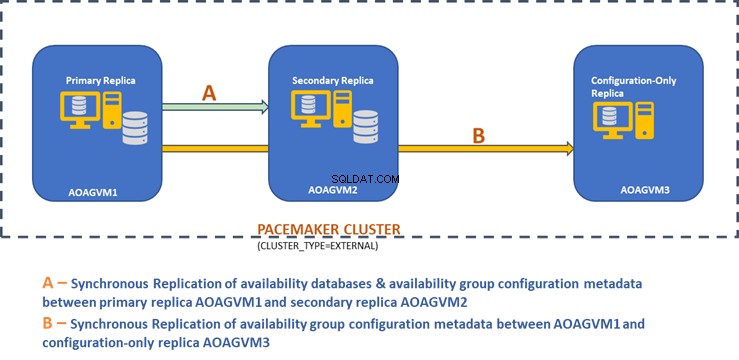
Podemos ver que existem 3 VMs chamadas AOAGVM1, AOAGVM2 e AOAGVM3. Todos eles são executados pelo sistema Ubuntu Linux e o SQL Server está configurado nos três sistemas Linux. Os bancos de dados de disponibilidade são hospedados em AOAGVM1 e AOAGVM2.
AOAGVM1 está agindo como uma réplica primária, enquanto AOAGVM2 é uma réplica secundária. AOAGVM3 serve como a réplica somente de configuração, que é a edição SQL Server Express. Nenhum banco de dados de usuário está hospedado nesta terceira réplica.
O cluster Pacemaker foi configurado entre todos os três nós para dar suporte à tecnologia de cluster para configuração de grupo de disponibilidade baseada em Linux.
Para configurar ou implementar o design acima, precisamos executar as seguintes etapas:
- Instale o SQL Server em três sistemas Ubuntu (a edição SQL Server Express será adequada para réplicas somente de configuração).
- Configure grupos de disponibilidade entre três nós.
- Configure o cluster PACEMAKER entre três nós.
- Adicione ou integre o grupo de disponibilidade como um recurso no grupo de clusters.
Dê uma olhada no artigo relacionado para concluir a etapa 1 (instalar instâncias do SQL Server em três nós).
Fique atento ao meu próximo artigo, onde explicarei o processo passo a passo para implementar o design acima. Nosso objetivo será obter failover automático e proteção de dados usando a réplica síncrona de 2 nós e uma réplica somente de configuração.
Ficaremos felizes em ouvir seus pensamentos e dicas práticas sobre este assunto. Sinta-se à vontade para compartilhá-los na seção de comentários.