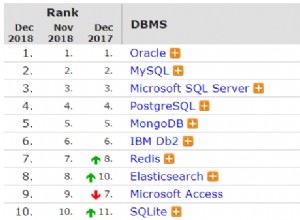
Se você tem seguido a Microsoft ultimamente, não será surpresa que o fornecedor de um produto de banco de dados concorrente, o SQL Server, também tenha entrado na onda do PostgreSQL. Desde o lançamento de 60.000 patentes para a OIN até o patrocínio Platinum na PGCon, a Microsoft como uma das organizações de apoio corporativo do PostgreSQL. Aproveitou todas as oportunidades para mostrar que não apenas você pode executar o PostgreSQL na Microsoft, mas também o inverso:a Microsoft, por meio de sua oferta de nuvem, pode executar o PostgreSQL para você. A afirmação ficou ainda mais clara com a aquisição da Citus Data e o lançamento de seu principal produto na Nuvem Azure sob o nome de Hyperscale. É seguro dizer que a adoção do PostgreSQL está crescendo e agora há ainda mais boas razões para escolhê-lo.
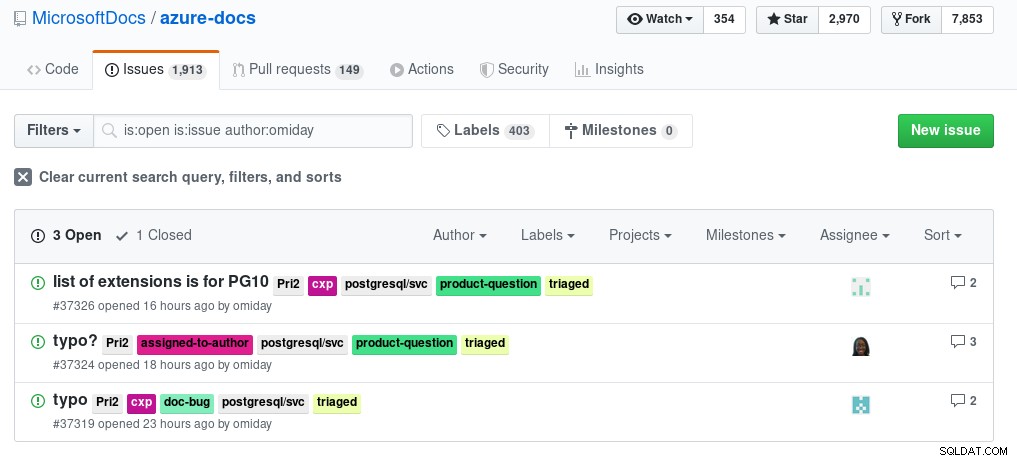
Minha jornada pela nuvem do Azure começou bem na página de destino onde encontro os concorrentes:Servidor Único e uma versão de visualização (em outras palavras, sem SLA fornecido) de Hyperscale (Citus). Este blog se concentrará no primeiro. Durante essa jornada, tive a oportunidade de praticar o que é o código aberto - retribuir à comunidade - neste caso, fornecendo feedback à documentação que, para crédito da Microsoft, eles facilitam muito ao enviar o feedback diretamente no Github:
Compatibilidade do PostgreSQL com o Azure
Versão
De acordo com a documentação do produto, o Single Server tem como alvo as versões do PostgreSQL na faixa principal n-2:
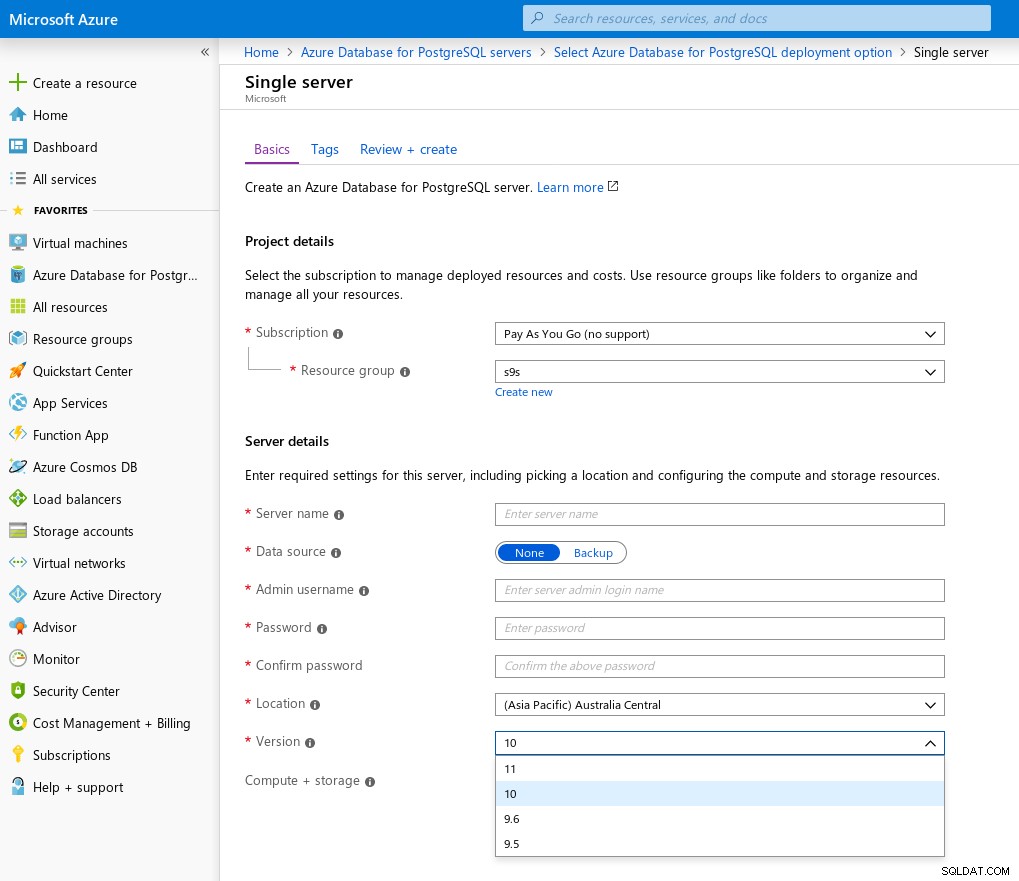
Como uma solução criada para desempenho, um servidor único é recomendado para conjuntos de dados de 100 GB e maior. Os servidores forneceram desempenho previsível — as instâncias de banco de dados vêm com um número predefinido de vCores e IOPS (com base no tamanho do armazenamento provisionado).
Extensões
Há um número razoável de Extensões Suportadas com algumas delas sendo instaladas imediatamente:
example@sqldat.com:5432 postgres> select name, default_version, installed_version from pg_available_extensions where name !~ '^postgis' order by name;
name | default_version | installed_version
------------------------------+-----------------+-------------------
address_standardizer | 2.4.3 |
address_standardizer_data_us | 2.4.3 |
btree_gin | 1.2 |
btree_gist | 1.5 |
chkpass | 1.0 |
citext | 1.4 |
cube | 1.2 |
dblink | 1.2 |
dict_int | 1.0 |
earthdistance | 1.1 |
fuzzystrmatch | 1.1 |
hstore | 1.4 |
hypopg | 1.1.1 |
intarray | 1.2 |
isn | 1.1 |
ltree | 1.1 |
orafce | 3.7 |
pg_buffercache | 1.3 | 1.3
pg_partman | 2.6.3 |
pg_prewarm | 1.1 |
pg_qs | 1.1 |
pg_stat_statements | 1.6 | 1.6
pg_trgm | 1.3 |
pg_wait_sampling | 1.1 |
pgcrypto | 1.3 |
pgrouting | 2.5.2 |
pgrowlocks | 1.2 |
pgstattuple | 1.5 |
plpgsql | 1.0 | 1.0
plv8 | 2.1.0 |
postgres_fdw | 1.0 |
tablefunc | 1.0 |
timescaledb | 1.1.1 |
unaccent | 1.1 |
uuid-ossp | 1.1 |
(35 rows)Monitoramento do PostgreSQL no Azure
O monitoramento do servidor depende de um conjunto de métricas que podem ser agrupadas de forma organizada para criar um painel personalizado:
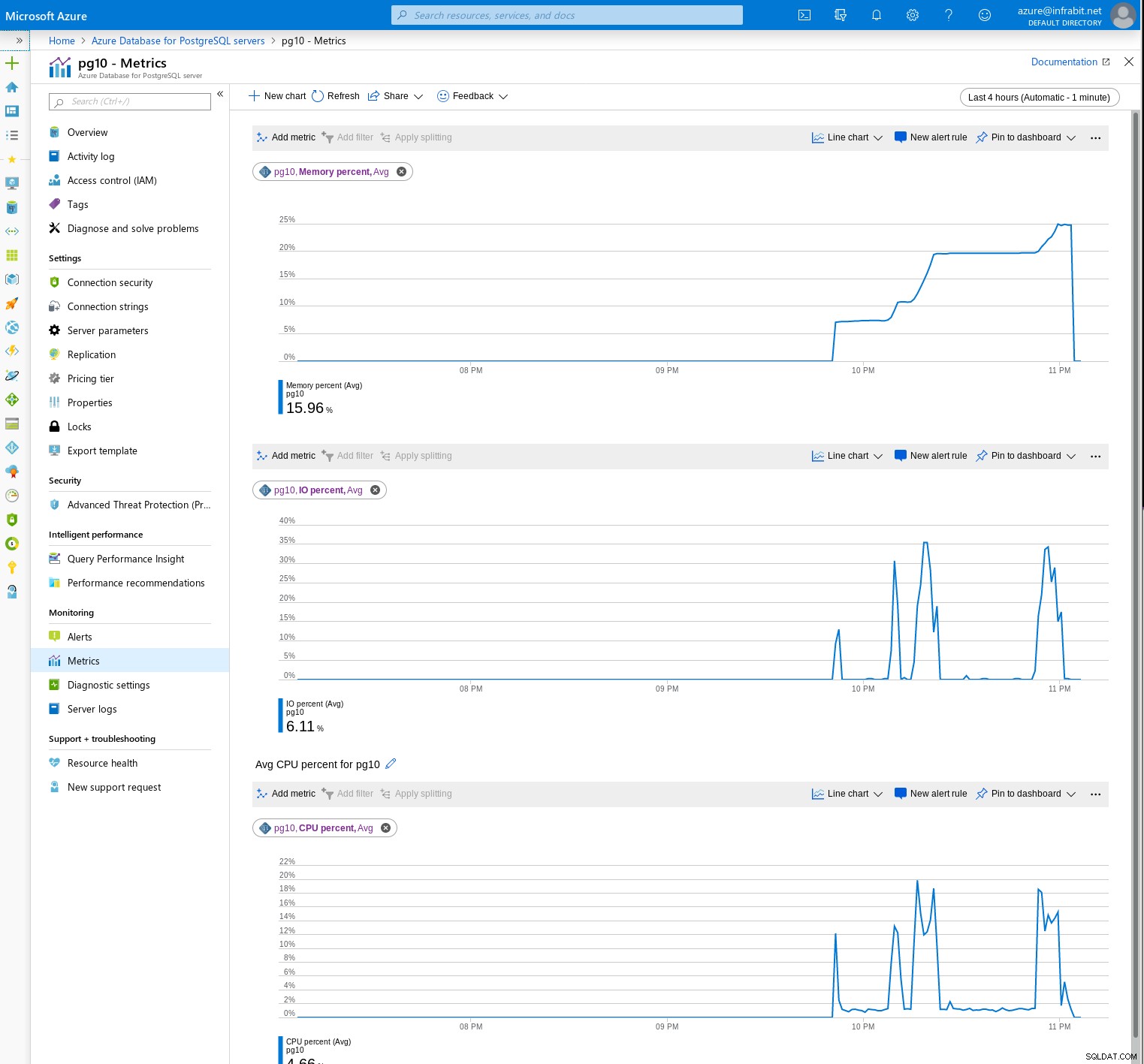
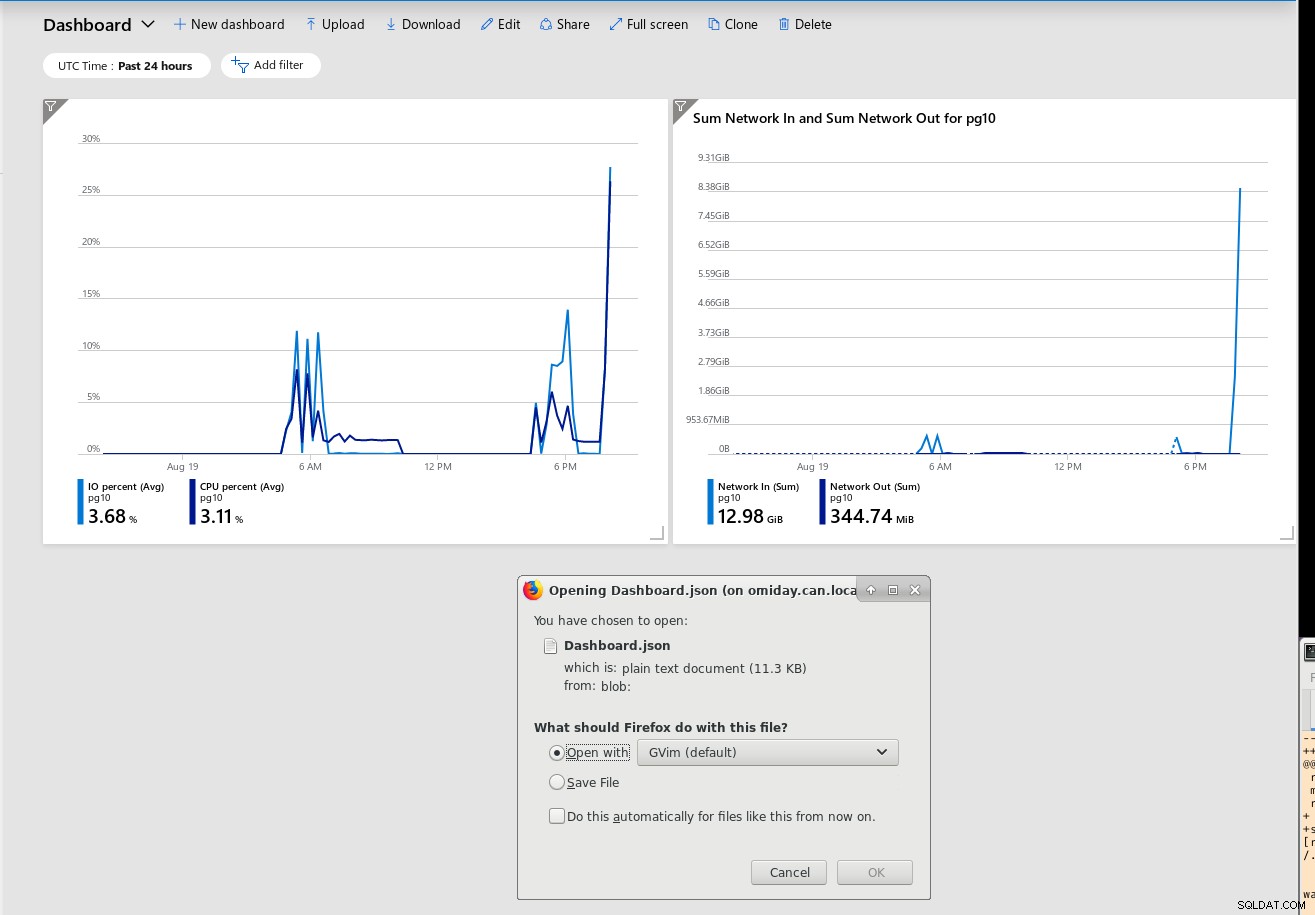
Aqueles familiarizados com Graphviz ou Blockdiag provavelmente apreciarão a opção de exportar o painel inteiro para um arquivo JSON:
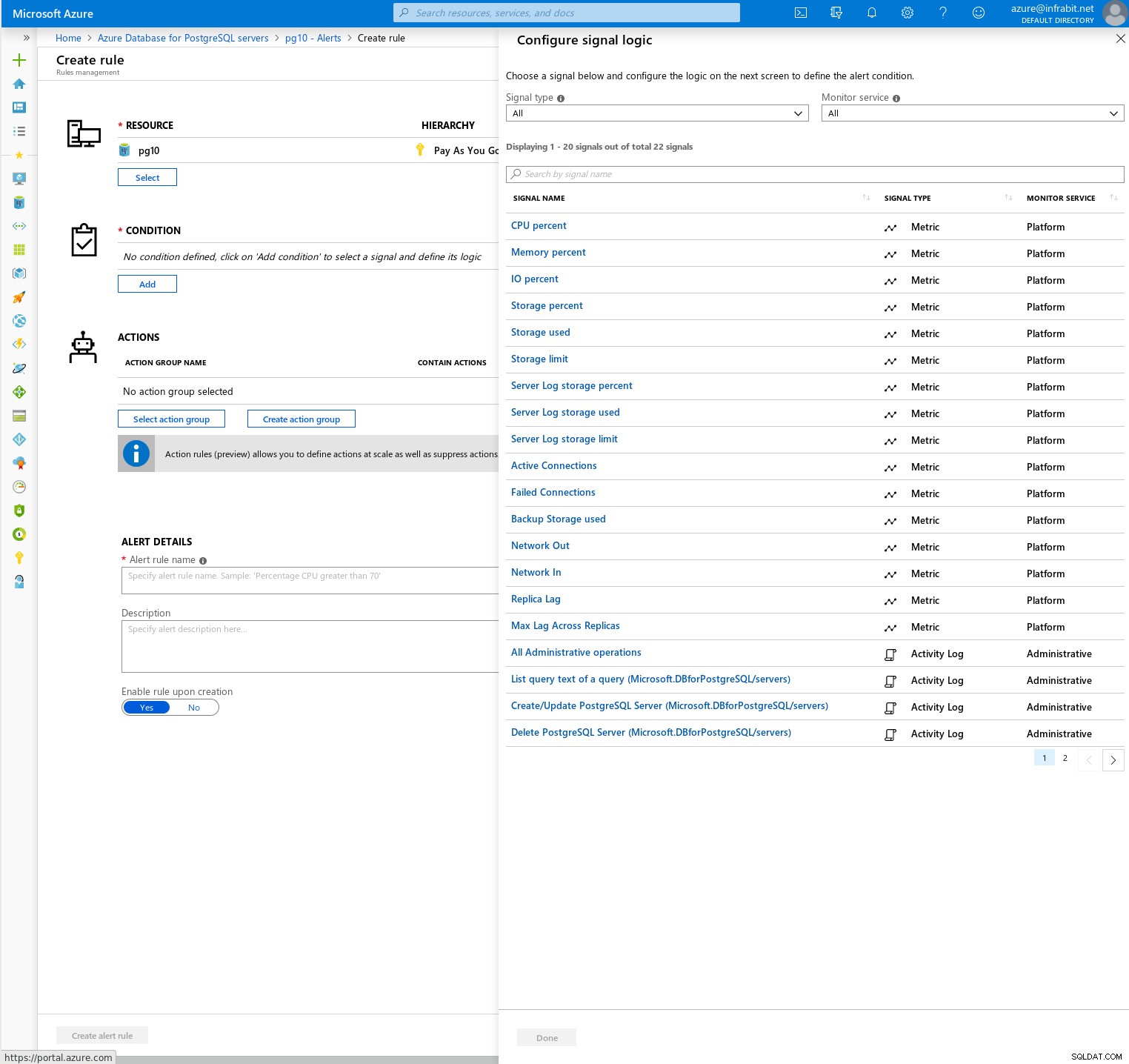
Além disso, as métricas podem — e devem — ser vinculadas a alertas:
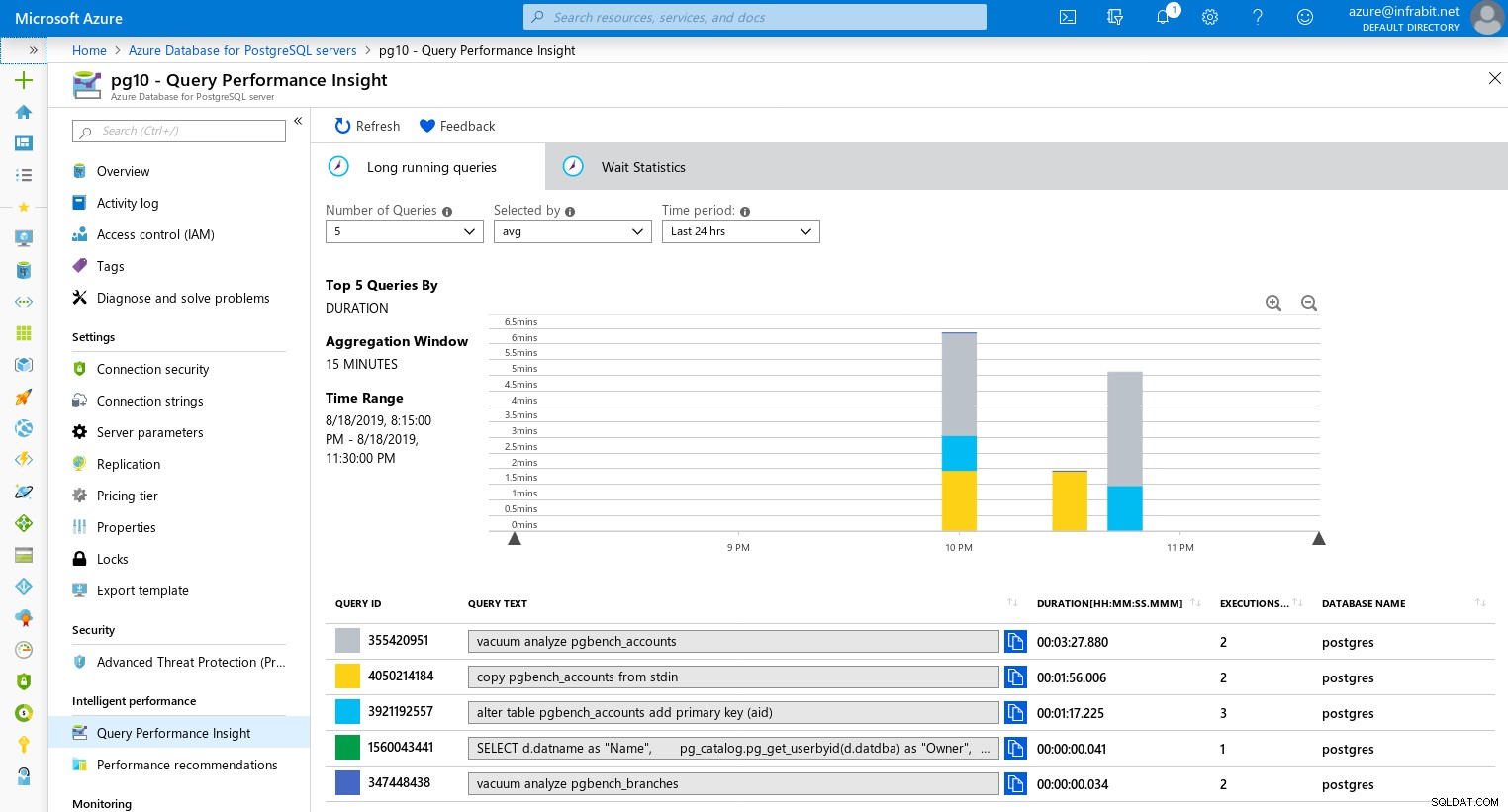
As estatísticas de consulta podem ser rastreadas por meio do Query Store e visualizadas com o Query Performance Entendimento. Para isso, alguns parâmetros específicos do Azure precisarão ser habilitados:
example@sqldat.com:5432 postgres> select * from pg_settings where name ~ 'pgms_wait_sampling.query_capture_mode|pg_qs.query_capture_mode';
-[ RECORD 1 ]---+------------------------------------------------------------------------------------------------------------------
name | pg_qs.query_capture_mode
setting | top
unit |
category | Customized Options
short_desc | Selects which statements are tracked by pg_qs. Need to reload the config to make change take effect.
extra_desc |
context | superuser
vartype | enum
source | configuration file
min_val |
max_val |
enumvals | {none,top,all}
boot_val | none
reset_val | top
sourcefile |
sourceline |
pending_restart | f
-[ RECORD 2 ]---+------------------------------------------------------------------------------------------------------------------
name | pgms_wait_sampling.query_capture_mode
setting | all
unit |
category | Customized Options
short_desc | Selects types of wait events are tracked by this extension. Need to reload the config to make change take effect.
extra_desc |
context | superuser
vartype | enum
source | configuration file
min_val |
max_val |
enumvals | {none,all}
boot_val | none
reset_val | all
sourcefile |
sourceline |
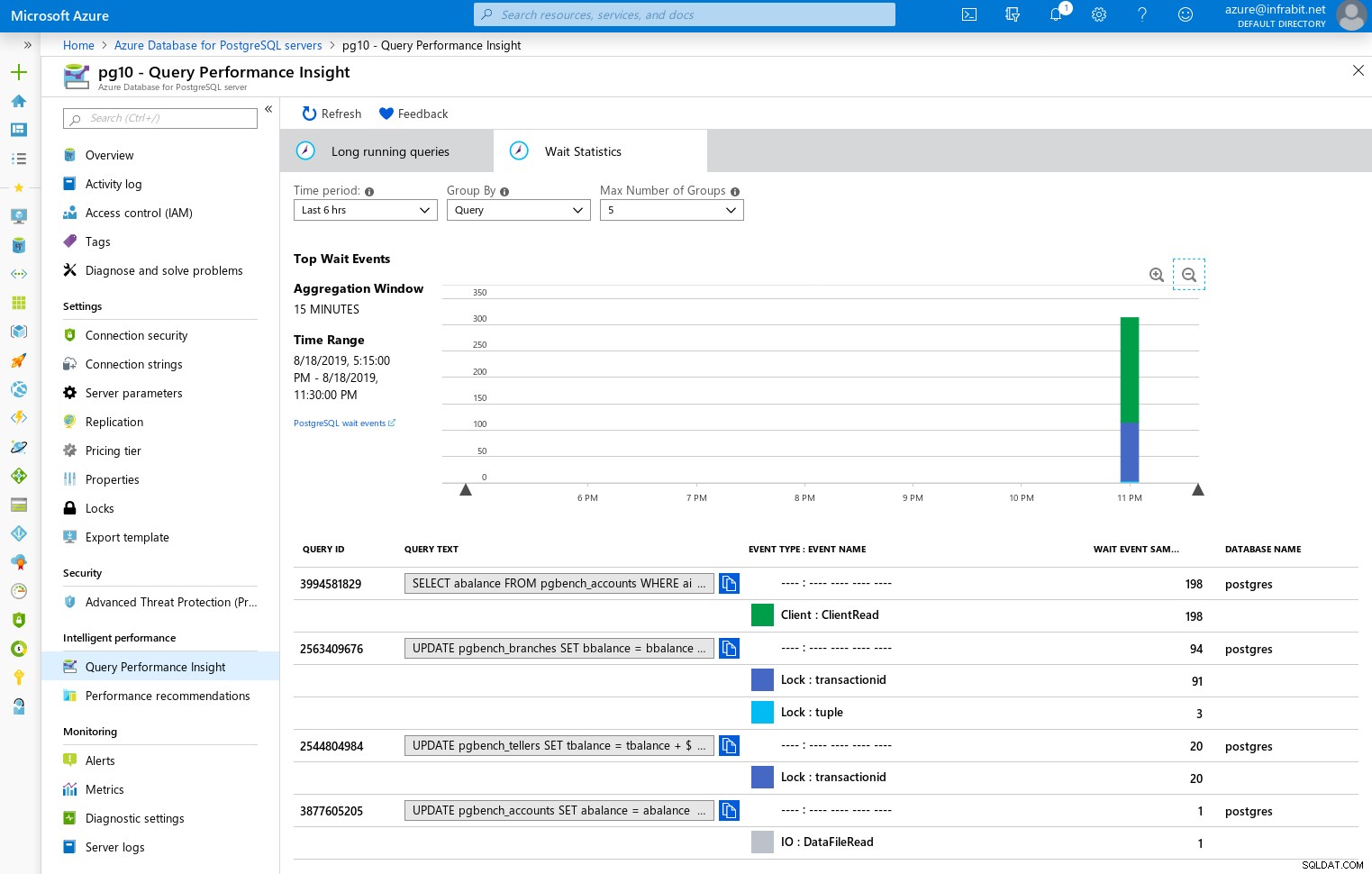
pending_restart | fPara visualizar as consultas e esperas lentas, passamos para o widget Query Performance:
Consultas de longa duração
Estatísticas de espera
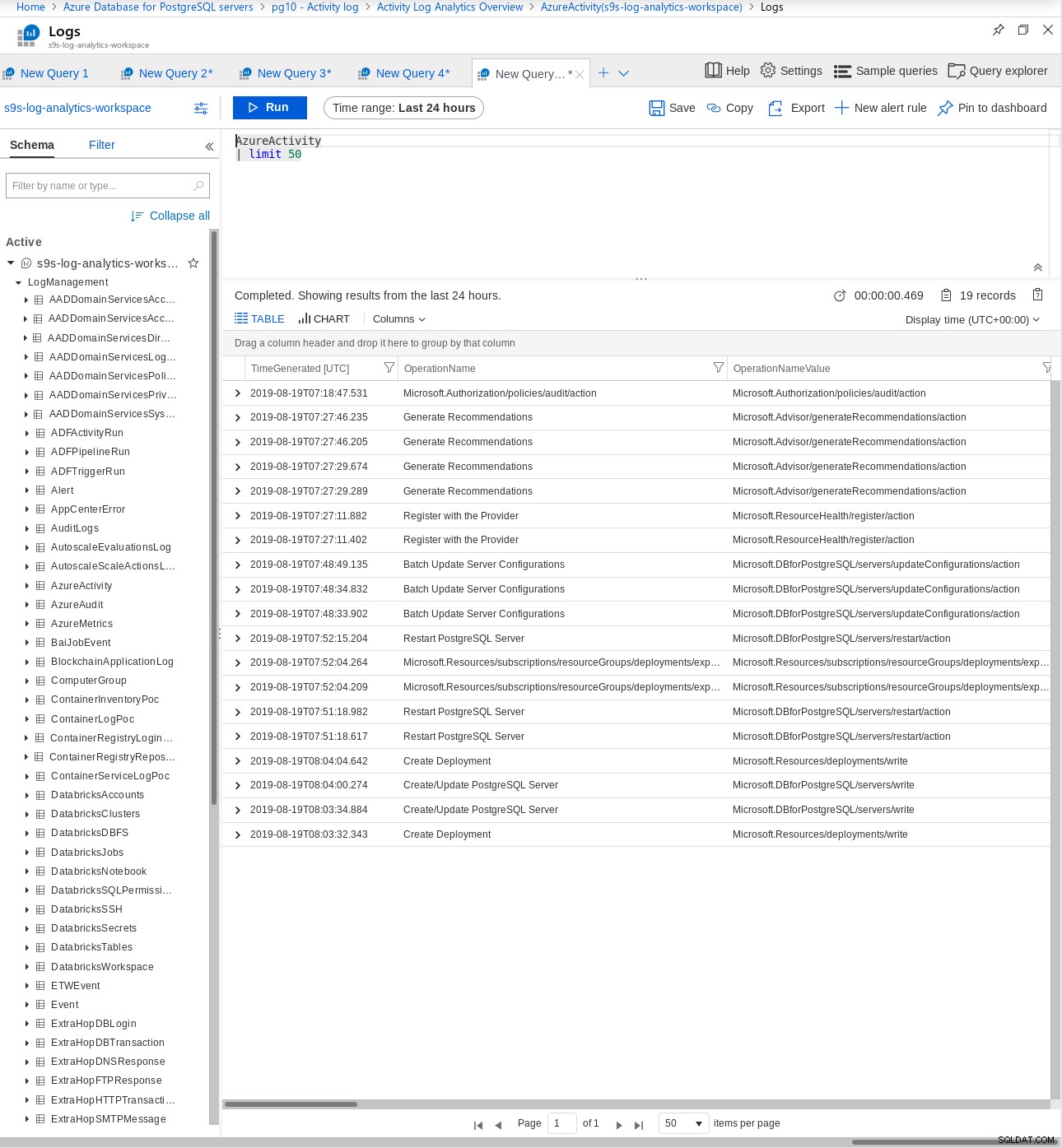
Log do PostgreSQL no Azure
Os registros padrão do PostgreSQL podem ser baixados ou exportados para o Log Analytics para uma análise mais avançada:
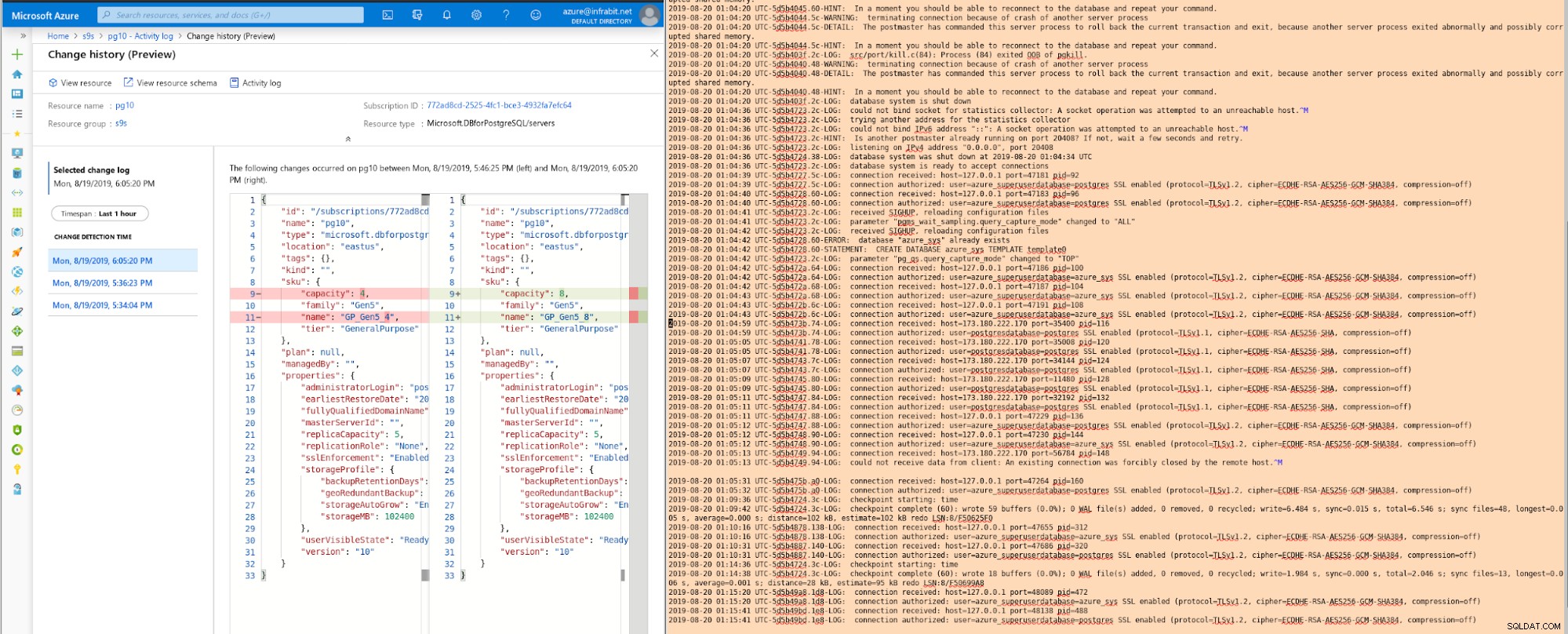
Desempenho e dimensionamento do PostgreSQL com o Azure
Embora o número de vCores possa ser facilmente aumentado ou diminuído, esta ação acionará uma reinicialização do servidor:
Para atingir zero tempo de inatividade, os aplicativos devem ser capazes de lidar com erros transitórios .
Para consultas de ajuste, o Azure fornece ao DBA recomendações de desempenho, além das extensões pg_statements e pg_buffercache pré-carregadas:
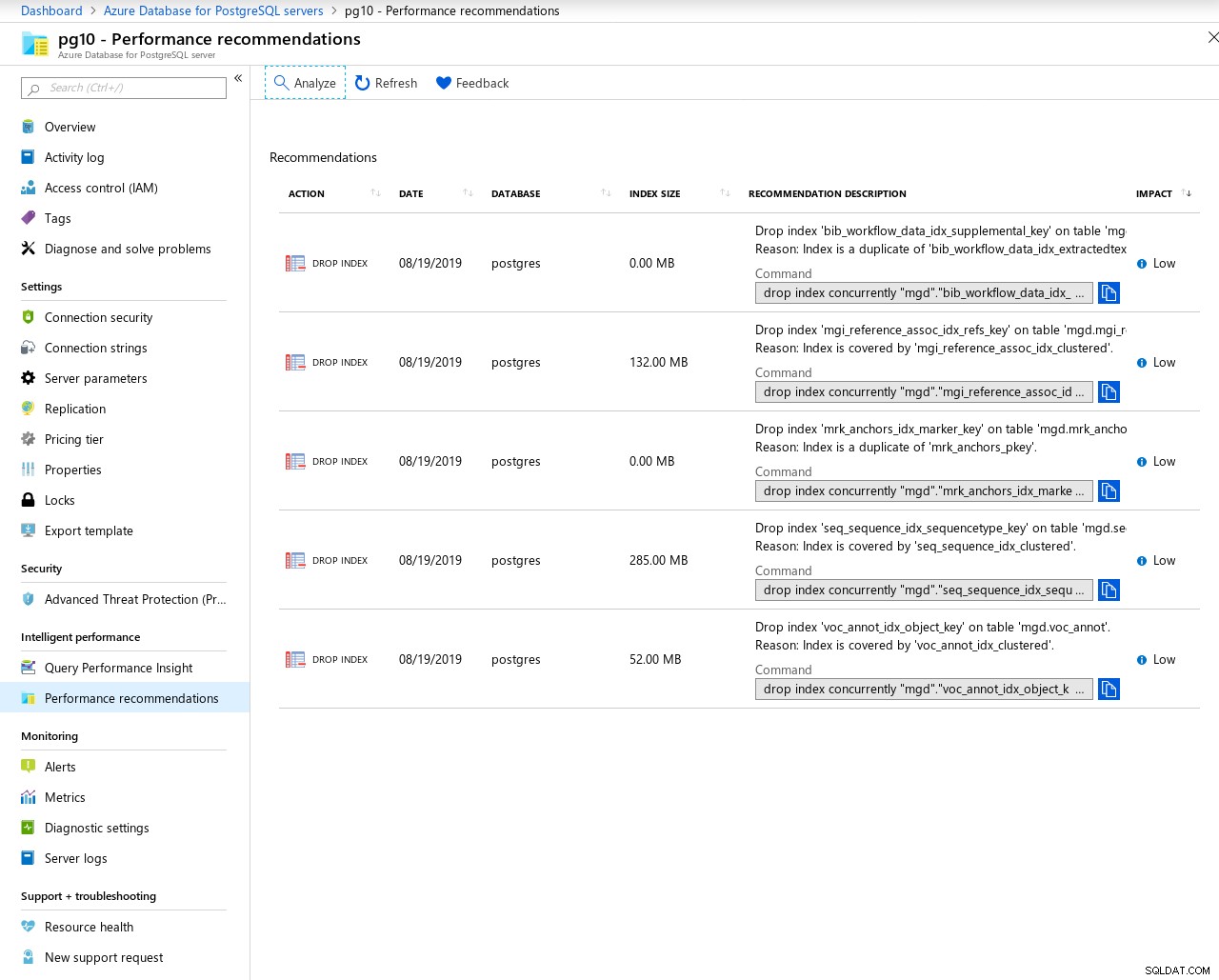
Alta disponibilidade e replicação no Azure
A alta disponibilidade do servidor de banco de dados é alcançada por meio de uma replicação de hardware baseada em nó. Isso garante que, no caso de falha de hardware, um novo nó possa ser criado em dezenas de segundos.
O Azure fornece um gateway redundante como um ponto de extremidade de conexão de rede para todos os servidores de banco de dados em uma região.
Segurança do PostgreSQL no Azure
Por padrão, as regras de firewall negam acesso à instância do PostgreSQL. Como um servidor de banco de dados do Azure é equivalente a um cluster de banco de dados, as regras de acesso serão aplicadas a todos os bancos de dados hospedados no servidor.
Além dos endereços IP, as regras de firewall podem fazer referência à rede virtual, um recurso disponível apenas para as camadas de Uso Geral e Otimizado para Memória.
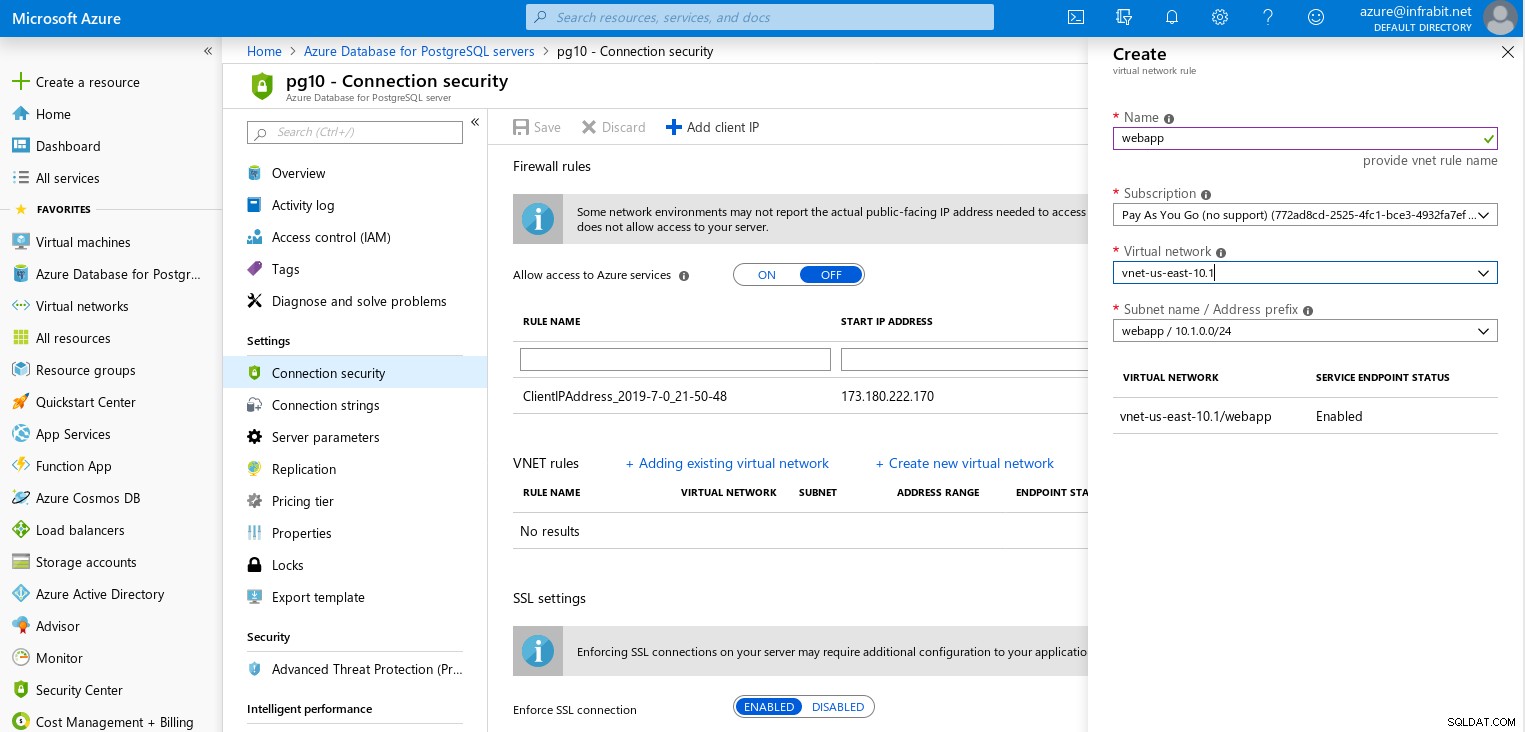
Uma coisa que achei peculiar na interface web do firewall — não consegui navegar fora da página enquanto as alterações estavam sendo salvas:
Os dados em repouso são criptografados usando uma chave gerenciada pelo servidor e os usuários da nuvem não podem desative a criptografia. Os dados em trânsito também são criptografados — o SSL obrigatório só pode ser alterado após a criação do servidor de banco de dados. Assim como os dados em repouso, os backups são criptografados e a criptografia não pode ser desabilitada.
A Proteção Avançada contra Ameaças fornece alertas e recomendações sobre várias solicitações de acesso ao banco de dados que são consideradas um risco de segurança. O recurso está atualmente em visualização. Para demonstrar, simulei um ataque de força bruta de senha:
~ $ while : ; do psql -U $(pwgen -s 20 1)@pg10 ; sleep 0.1 ; done
psql: FATAL: password authentication failed for user "AApT6z4xUzpynJwiNAYf"
psql: FATAL: password authentication failed for user "gaNeW8VSIflkdnNZSpNV"
psql: FATAL: password authentication failed for user "SWZnY7wGTxdLTLcbqnUW"
psql: FATAL: password authentication failed for user "BVH2SC12m9js9vZHcuBd"
psql: FATAL: password authentication failed for user "um9kqUxPIxeQrzWQXr2v"
psql: FATAL: password authentication failed for user "8BGXyg3KHF3Eq3yHpik1"
psql: FATAL: password authentication failed for user "5LsVrtBjcewd77Q4kaj1"
....Verifique os logs do PostgreSQL:
2019-08-19 07:13:50 UTC-5d5a4c2e.138-FATAL: password authentication failed
for user "AApT6z4xUzpynJwiNAYf"
2019-08-19 07:13:50 UTC-5d5a4c2e.138-DETAIL: Role "AApT6z4xUzpynJwiNAYf" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:51 UTC-5d5a4c2f.13c-LOG: connection received: host=173.180.222.170 port=27248 pid=316
2019-08-19 07:13:51 UTC-5d5a4c2f.13c-FATAL: password authentication failed for user "gaNeW8VSIflkdnNZSpNV"
2019-08-19 07:13:51 UTC-5d5a4c2f.13c-DETAIL: Role "gaNeW8VSIflkdnNZSpNV" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:52 UTC-5d5a4c30.140-LOG: connection received: host=173.180.222.170 port=58256 pid=320
2019-08-19 07:13:52 UTC-5d5a4c30.140-FATAL: password authentication failed for user "SWZnY7wGTxdLTLcbqnUW"
2019-08-19 07:13:52 UTC-5d5a4c30.140-DETAIL: Role "SWZnY7wGTxdLTLcbqnUW" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:53 UTC-5d5a4c31.148-LOG: connection received: host=173.180.222.170 port=32984 pid=328
2019-08-19 07:13:53 UTC-5d5a4c31.148-FATAL: password authentication failed for user "BVH2SC12m9js9vZHcuBd"
2019-08-19 07:13:53 UTC-5d5a4c31.148-DETAIL: Role "BVH2SC12m9js9vZHcuBd" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:53 UTC-5d5a4c31.14c-LOG: connection received: host=173.180.222.170 port=43384 pid=332
2019-08-19 07:13:54 UTC-5d5a4c31.14c-FATAL: password authentication failed for user "um9kqUxPIxeQrzWQXr2v"
2019-08-19 07:13:54 UTC-5d5a4c31.14c-DETAIL: Role "um9kqUxPIxeQrzWQXr2v" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:54 UTC-5d5a4c32.150-LOG: connection received: host=173.180.222.170 port=27672 pid=336
2019-08-19 07:13:54 UTC-5d5a4c32.150-FATAL: password authentication failed for user "8BGXyg3KHF3Eq3yHpik1"
2019-08-19 07:13:54 UTC-5d5a4c32.150-DETAIL: Role "8BGXyg3KHF3Eq3yHpik1" does not exist.
Connection matched pg_hba.conf line 3: "host all all 173.180.222.170/32 password"
2019-08-19 07:13:55 UTC-5d5a4c33.154-LOG: connection received: host=173.180.222.170 port=12712 pid=340
2019-08-19 07:13:55 UTC-5d5a4c33.154-FATAL: password authentication failed for user "5LsVrtBjcewd77Q4kaj1"
2019-08-19 07:13:55 UTC-5d5a4c33.154-DETAIL: Role "5LsVrtBjcewd77Q4kaj1" does not exist.O alerta por e-mail chegou cerca de 30 minutos depois:
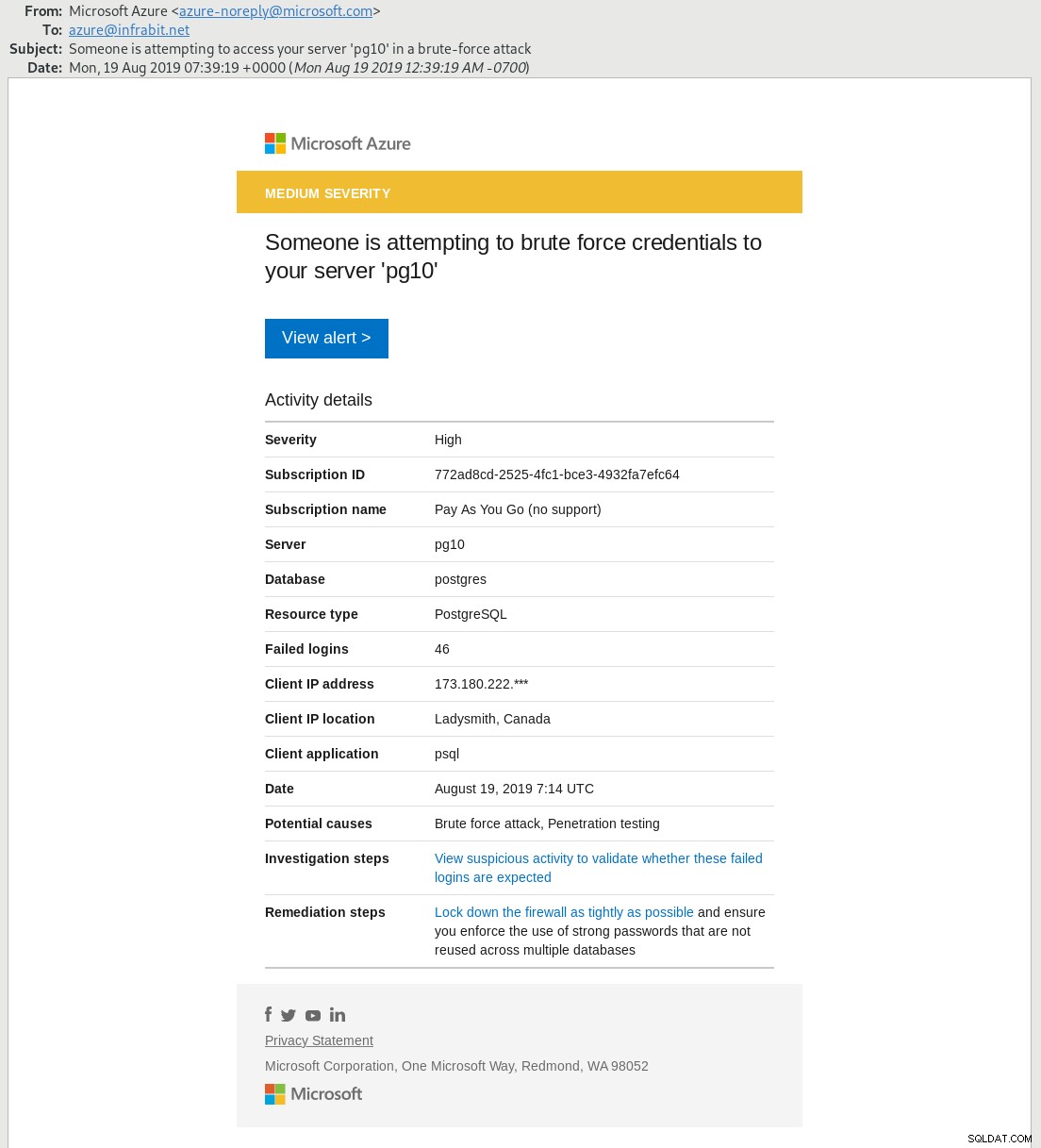
Para permitir acesso refinado ao servidor de banco de dados, o Azure fornece RBAC, que é um recurso de controle de acesso nativo da nuvem, apenas mais uma ferramenta no arsenal do PostgreSQL Cloud DBA. Isso é o mais próximo que podemos chegar das onipresentes regras de acesso pg_hba.
Backup e recuperação do PostgreSQL no Azure
Independentemente dos níveis de preço, os backups são retidos entre 7 e 35 dias. O tipo de preço também influencia a capacidade de restaurar dados.
A recuperação pontual está disponível por meio do Portal do Azure ou da CLI e, de acordo com a documentação, granular em até cinco minutos. A funcionalidade do portal é bastante limitada - o widget selecionador de data mostra cegamente os últimos 7 dias como datas possíveis para selecionar, embora eu tenha criado o servidor hoje. Além disso, não há verificação realizada no tempo de destino da recuperação — eu esperava que a inserção de um valor fora do intervalo de recuperação acionasse um erro impedindo que o assistente continuasse:
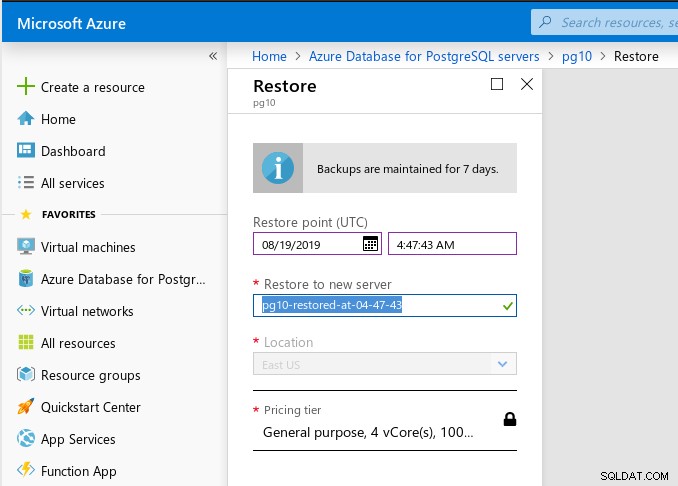
Ao iniciar o processo de restauração, ocorre um erro, supostamente causado pelo out do valor do intervalo, aparecerá cerca de um minuto depois:
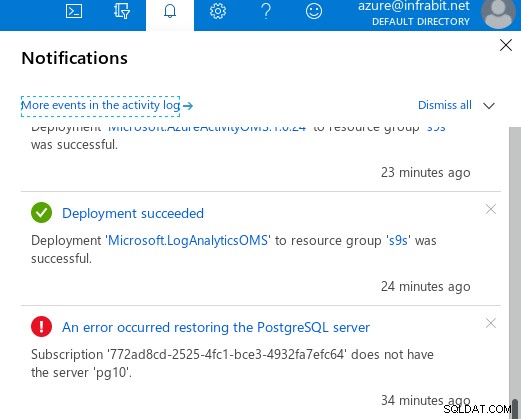
…mas, infelizmente, a mensagem de erro não foi muito útil:
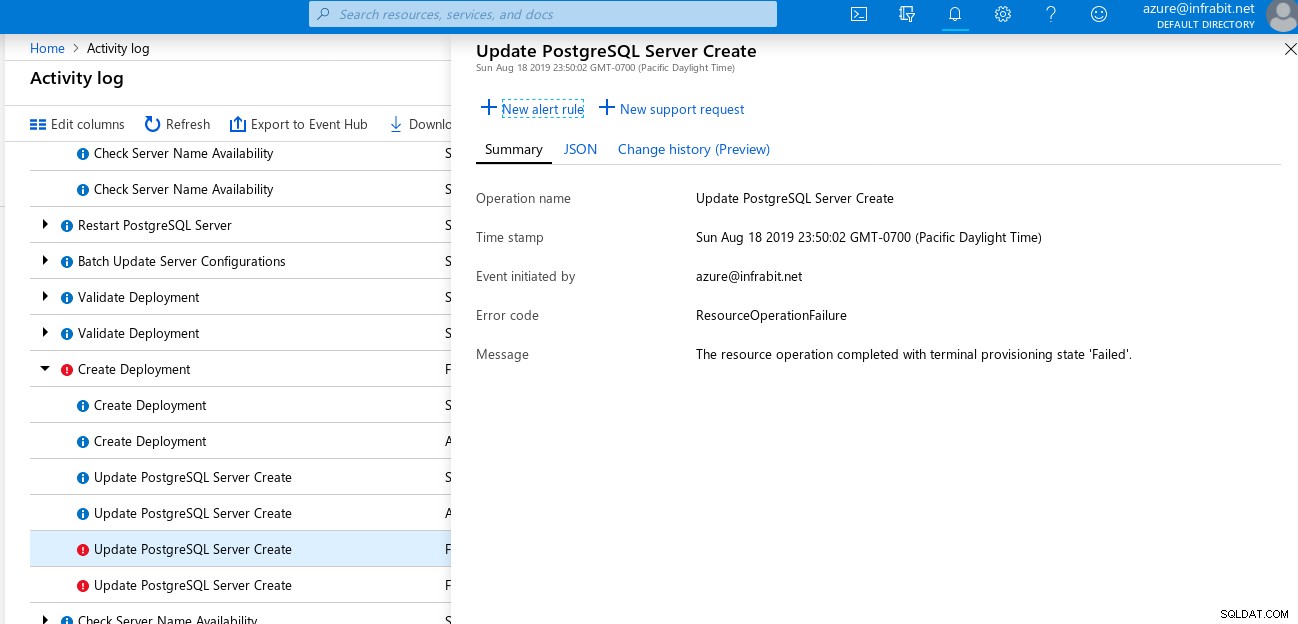
Por fim, o armazenamento de backup é gratuito por períodos de retenção de até 7 dias. Isso pode ser extremamente útil para ambientes de desenvolvimento.
Dicas e dicas
Limites
Acostume-se com os limites de servidor único.
Conectividade
Sempre use a string de conexão para que a conexão seja roteada para o servidor de banco de dados correto.
Replicação
Para cenários de recuperação de desastres, localize réplicas de leitura em uma das regiões emparelhadas.
Funções
Assim como acontece com AWS e GCloud, não há acesso de superusuário.
GUCs
Os parâmetros que exigem uma reinicialização do servidor ou acesso de superusuário não podem ser configurados.
Escala
Durante o dimensionamento automático, os aplicativos devem tentar novamente até que o novo nó seja ativado.
A quantidade de memória e o IOPS não podem ser especificados — a memória é alocada em unidades de GB por vCore, até um máximo de 320 GB (32 vCores x 10 GB), e o IOPS depende do tamanho do armazenamento provisionado para máximo de 6.000 IOPS. Neste momento, o Azure oferece uma grande opção de visualização de armazenamento com um máximo de 20.000 IOPS.
Os servidores criados na camada Básica não podem ser atualizados para Uso Geral ou Otimizado para Memória.
Armazenamento
Certifique-se de que o recurso de crescimento automático esteja habilitado — se a quantidade de dados exceder o espaço de armazenamento provisionado, o banco de dados entrará no modo somente leitura.
O armazenamento só pode ser ampliado. Assim como em todos os outros provedores de nuvem, a alocação de armazenamento não pode ser diminuída e não encontrei nenhuma explicação. Dado o equipamento de última geração, os grandes players de nuvem podem pagar, não deve haver motivo para não fornecer recursos semelhantes à realocação de dados online do LVM. O armazenamento é muito barato hoje em dia, não há realmente nenhuma razão para pensar em reduzir a escala até a próxima atualização de versão principal.
Firewall
Em alguns casos, as atualizações das regras de firewall podem levar até cinco minutos para serem propagadas.
Um servidor está localizado na mesma sub-rede que os servidores de aplicativos não poderão ser acessados até que as regras de firewall apropriadas estejam em vigor.
As regras de rede virtual não permitem acesso entre regiões e, como resultado, dblink e postgres_fdw não podem ser usados para se conectar a bancos de dados fora da nuvem do Azure.
A abordagem VNet/Sub-rede não pode ser aplicada a aplicativos Web, pois suas conexões se originam de endereços IP públicos.
As grandes redes virtuais ficarão indisponíveis enquanto os pontos de extremidade de serviço estiverem habilitados.
Criptografia
Para aplicativos que exigem validação de certificado de servidor, o arquivo está disponível para download na Digicert. A Microsoft facilitou e você não deve se preocupar com a renovação até 2025:
~ $ openssl x509 -in BaltimoreCyberTrustRoot.crt.pem -noout -dates
notBefore=May 12 18:46:00 2000 GMT
notAfter=May 12 23:59:00 2025 GMTSistema de detecção de intrusão
A versão prévia da Proteção Avançada contra Ameaças não está disponível para as instâncias da camada Básica.
Backup e restauração
Para aplicativos que não podem suportar um tempo de inatividade da região, considere configurar o servidor com armazenamento de backup com redundância geográfica. Esta opção só pode ser habilitada no momento da criação do servidor de banco de dados.
O requisito para reconfigurar as regras de firewall na nuvem após uma operação PITR é particularmente importante.
A exclusão de um servidor de banco de dados remove todos os backups.
Após a restauração, algumas tarefas pós-restauração terão que ser executadas.
Tabelas não registradas são recomendadas para inserções em massa para aumentar o desempenho, no entanto, elas não são replicadas.
Monitoramento
As métricas são registradas a cada minuto e armazenadas por 30 dias.
Registro
O Repositório de Consultas é uma opção global, o que significa que se aplica a todos os bancos de dados. As transações e consultas somente leitura com mais de 6.000 bytes são problemáticas. Por padrão, as consultas capturadas são retidas por 7 dias.
Desempenho
As recomendações do Query Performance Insight estão atualmente limitadas à criação e eliminação do índice.
Desative pg_stat_staements quando não for necessário.
Substitua uuid_generate_v4 por gen_random_uuid(). Isso está de acordo com a recomendação na documentação oficial do PostgreSQL, veja Construindo uuid-ossp.
Alta disponibilidade e replicação
Há um limite de cinco réplicas de leitura. Os aplicativos de gravação intensiva devem evitar o uso de réplicas de leitura, pois o mecanismo de replicação é assíncrono, o que introduz alguns atrasos que os aplicativos devem ser capazes de tolerar. As réplicas de leitura podem estar localizadas em uma região diferente.
O suporte REPLICA só pode ser habilitado após a criação do servidor. O recurso requer uma reinicialização do servidor:
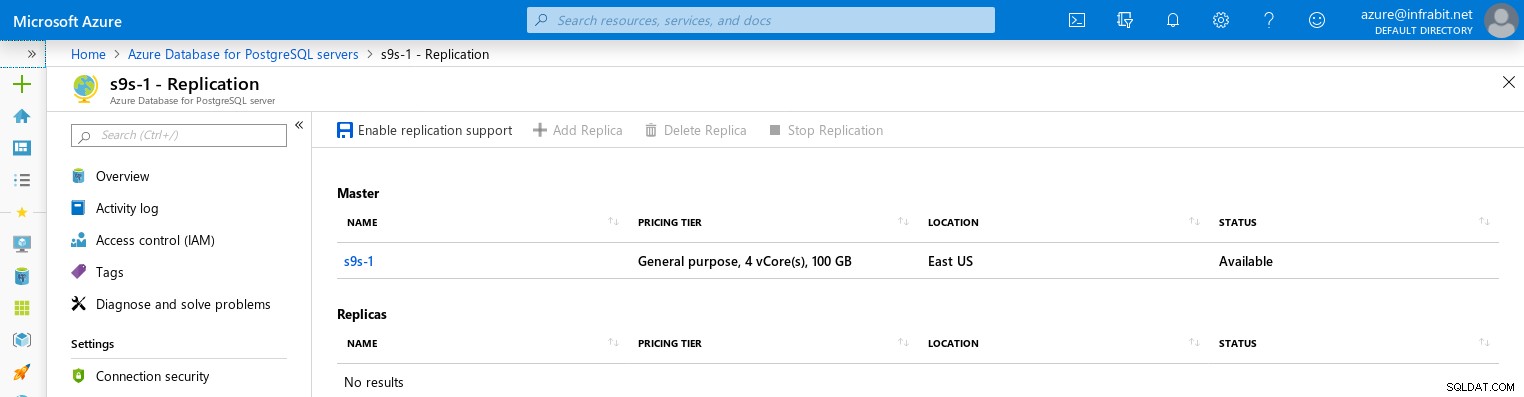
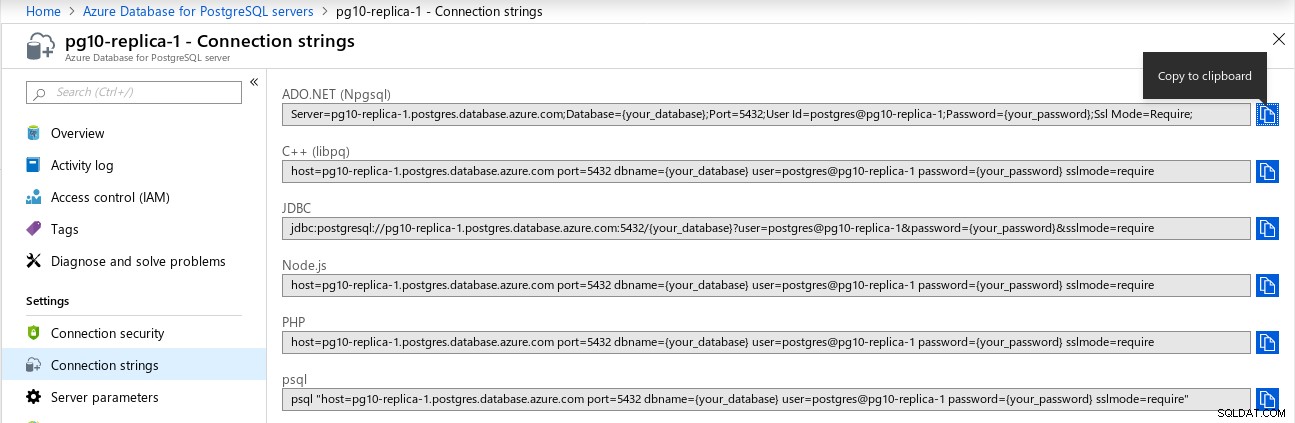
As réplicas de leitura não herdam as regras de firewall do nó mestre:
O failover para ler a réplica não é automático. O mecanismo de failover é baseado em nó.
Há uma longa lista de Considerações que precisam ser revisadas antes de configurar as réplicas de leitura.
A criação de réplicas leva muito tempo, mesmo quando testei com um conjunto de dados relativamente pequeno:
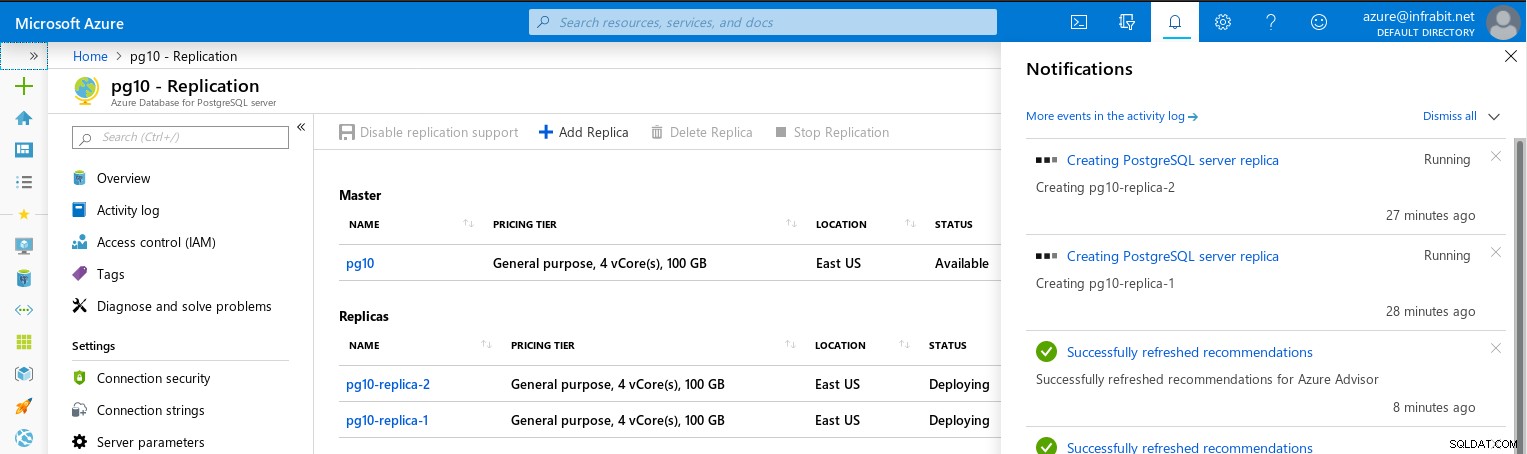 Vacuum
Vacuum
Vacuo
Revise os principais parâmetros, pois o Banco de Dados do Azure para PostgreSQL é fornecido com valores padrão de vácuo upstream:
example@sqldat.com:5432 postgres> select name,setting from pg_settings where name ~ '^autovacuum.*';
name | setting
-------------------------------------+-----------
autovacuum | on
autovacuum_analyze_scale_factor | 0.05
autovacuum_analyze_threshold | 50
autovacuum_freeze_max_age | 200000000
autovacuum_max_workers | 3
autovacuum_multixact_freeze_max_age | 400000000
autovacuum_naptime | 15
autovacuum_vacuum_cost_delay | 20
autovacuum_vacuum_cost_limit | -1
autovacuum_vacuum_scale_factor | 0.05
autovacuum_vacuum_threshold | 50
autovacuum_work_mem | -1
(12 rows)Atualizações
As atualizações principais automáticas não são suportadas. Conforme mencionado anteriormente, esta é uma oportunidade de economia de custos, reduzindo o armazenamento de crescimento automático.
Aprimoramentos do PostgreSQL Azure
Série temporal
TimescaleDB está disponível como uma extensão (não faz parte dos módulos do PostgreSQL), porém, está a apenas alguns cliques de distância. A única desvantagem é a versão mais antiga 1.1.1, enquanto a versão upstream está atualmente em 1.4.1 (2019-08-01).
example@sqldat.com:5432 postgres> CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
WARNING:
WELCOME TO
_____ _ _ ____________
|_ _(_) | | | _ \ ___ \
| | _ _ __ ___ ___ ___ ___ __ _| | ___| | | | |_/ /
| | | | _ ` _ \ / _ \/ __|/ __/ _` | |/ _ \ | | | ___ \
| | | | | | | | | __/\__ \ (_| (_| | | __/ |/ /| |_/ /
|_| |_|_| |_| |_|\___||___/\___\__,_|_|\___|___/ \____/
Running version 1.1.1
For more information on TimescaleDB, please visit the following links:
1. Getting started: https://docs.timescale.com/getting-started
2. API reference documentation: https://docs.timescale.com/api
3. How TimescaleDB is designed: https://docs.timescale.com/introduction/architecture
CREATE EXTENSION
example@sqldat.com:5432 postgres> \dx timescaledb
List of installed extensions
Name | Version | Schema | Description
-------------+---------+--------+-------------------------------------------------------------------
timescaledb | 1.1.1 | public | Enables scalable inserts and complex queries for time-series data
(1 row)Registro
Além das opções de log do PostgreSQL, o Banco de Dados do Azure para PostgreSQL pode ser configurado para registrar eventos de diagnóstico adicionais.
Firewall
O Portal do Azure inclui um recurso útil para permitir conexões dos endereços IP conectados ao portal:
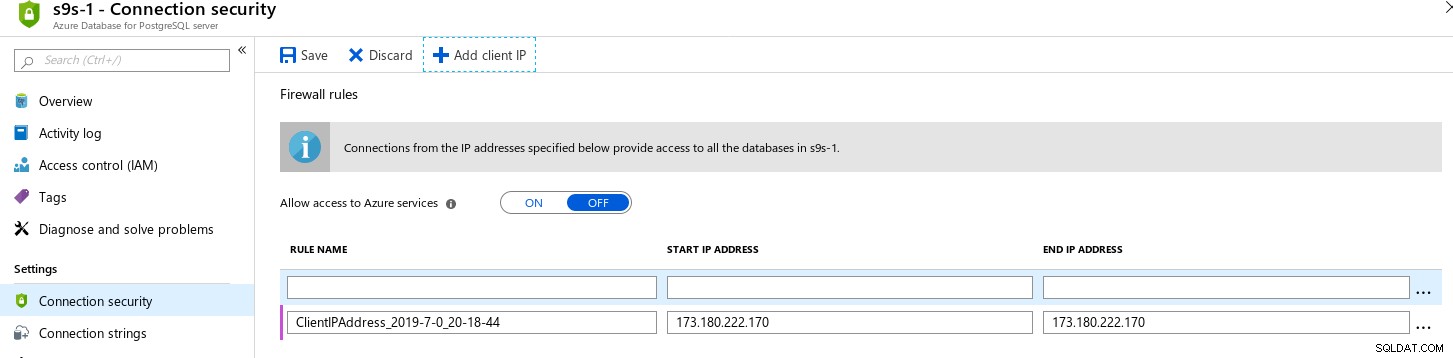
Observei o recurso, pois facilita para desenvolvedores e administradores de sistema se permitem, e se destaca como um recurso não oferecido nem pela AWS nem pelo GCloud.
Conclusão
O Azure Database for PostgreSQL Single Server oferece serviços de nível empresarial, no entanto, muitos desses serviços ainda estão no modo de visualização:Query Store, Performance Insight, Performance Recommendation, Advanced Threat Protection, Large Storage, Cross-region Leia réplicas.
Embora o conhecimento do sistema operacional não seja mais necessário para administrar o PostgreSQL na nuvem do Azure, espera-se que o DBA adquira habilidades que não se limitam ao próprio banco de dados — rede do Azure (VNet), segurança de conexão (firewall ), visualizador de log e análise junto com KQL, CLI do Azure para scripts úteis e a lista continua.
Por fim, para aqueles que planejam migrar suas cargas de trabalho PostgreSQL para o Azure, há vários recursos disponíveis juntamente com uma lista selecionada de Parceiros do Azure, incluindo Credativ, um dos principais patrocinadores e colaboradores do PostgreSQL.