O SQL Server introduziu objetos OLTP na memória no SQL Server 2014. Havia muitas limitações na versão inicial; alguns foram abordados no SQL Server 2016, e espera-se que mais sejam abordados na próxima versão à medida que o recurso continua a evoluir. Até agora, a adoção do OLTP na memória não parece muito difundida, mas à medida que o recurso amadurece, espero que mais clientes comecem a perguntar sobre a implementação. Como acontece com qualquer alteração importante de esquema ou código, recomendo testes completos para determinar se o OLTP na memória fornecerá os benefícios esperados. Com isso em mente, eu estava interessado em ver como o desempenho mudou para instruções INSERT, UPDATE e DELETE muito simples com OLTP na memória. Eu estava esperançoso de que se eu pudesse demonstrar travamento ou travamento como um problema com tabelas baseadas em disco, então as tabelas na memória forneceriam uma solução, pois elas são livres de travamento e travamento.
Eu desenvolvi o seguinte teste casos:
- Uma tabela baseada em disco com procedimentos armazenados tradicionais para DML.
- Uma tabela In-Memory com procedimentos armazenados tradicionais para DML.
- Uma tabela na memória com procedimentos compilados nativamente para DML.
Eu estava interessado em comparar o desempenho de procedimentos armazenados tradicionais e procedimentos compilados nativamente, porque uma restrição de um procedimento compilado nativamente é que todas as tabelas referenciadas devem estar na memória. Embora modificações solitárias de uma única linha possam ser comuns em alguns sistemas, muitas vezes vejo modificações ocorrendo em um procedimento armazenado maior com várias instruções (SELECT e DML) acessando uma ou mais tabelas. A documentação do OLTP na memória recomenda fortemente o uso de procedimentos compilados nativamente para obter o máximo benefício em termos de desempenho. Eu queria entender o quanto isso melhorou o desempenho.
A configuração
Criei um banco de dados com um grupo de arquivos com otimização de memória e, em seguida, criei três tabelas diferentes no banco de dados (uma baseada em disco, duas na memória):
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
O DDL era quase o mesmo para todos os objetos, contabilizando no disco versus na memória, quando apropriado. DiskTable DDL vs. DDL na memória:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Também criei nove procedimentos armazenados – um para cada combinação de tabela/modificação.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Atualização
- InMemRegularSP _Delete
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Cada procedimento armazenado aceitou uma entrada inteira para fazer um loop para esse número de modificações. Os procedimentos armazenados seguiram o mesmo formato, as variações foram apenas a tabela acessada e se o objeto foi compilado nativamente ou não. O código completo para criar o banco de dados e os objetos pode ser encontrado aqui, com exemplos de instruções INSERT e UPDATE abaixo:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Observação:as tabelas IDs_* foram preenchidas novamente após a conclusão de cada conjunto de INSERTs e eram específicas para os três cenários diferentes.
Metodologia de teste
O teste foi feito usando scripts .cmd que usavam sqlcmd para chamar um script que executava o procedimento armazenado, por exemplo:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"
exit
Usei essa abordagem para criar uma ou mais conexões com o banco de dados que seriam executadas simultaneamente. Além de entender as mudanças básicas no desempenho, eu também queria examinar o efeito de diferentes cargas de trabalho. Esses scripts foram iniciados de uma máquina separada para eliminar a sobrecarga de instanciar conexões. Cada procedimento armazenado foi executado 1.000 vezes por uma conexão e testei 1 conexão, 10 conexões e 100 conexões (1.000, 10.000 e 100.000 modificações, respectivamente). Capturei métricas de desempenho usando o Query Store e também capturei estatísticas de espera. Com o Query Store, pude capturar a duração média e a CPU para cada procedimento armazenado. Os dados de estatísticas de espera foram capturados para cada conexão usando dm_exec_session_wait_stats e, em seguida, agregados para todo o teste.
Executei cada teste quatro vezes e, em seguida, calculei as médias gerais dos dados usados neste post. Os scripts usados para teste de carga de trabalho podem ser baixados aqui.
Resultados
Como se poderia prever, o desempenho com objetos In-Memory foi melhor do que com objetos baseados em disco. No entanto, uma tabela na memória com um procedimento armazenado regular às vezes tinha desempenho comparável ou apenas um pouco melhor em comparação com uma tabela baseada em disco com um procedimento armazenado regular. Lembre-se:eu estava interessado em entender se eu realmente precisava de um procedimento armazenado compilado para obter um grande benefício com uma tabela na memória. Para este cenário, eu fiz. Em todos os casos, a tabela na memória com o procedimento compilado nativamente teve um desempenho significativamente melhor. Os dois gráficos abaixo mostram os mesmos dados, mas com escalas diferentes para o eixo x, para demonstrar que o desempenho de procedimentos armazenados regulares que modificam dados degradados com mais conexões simultâneas.
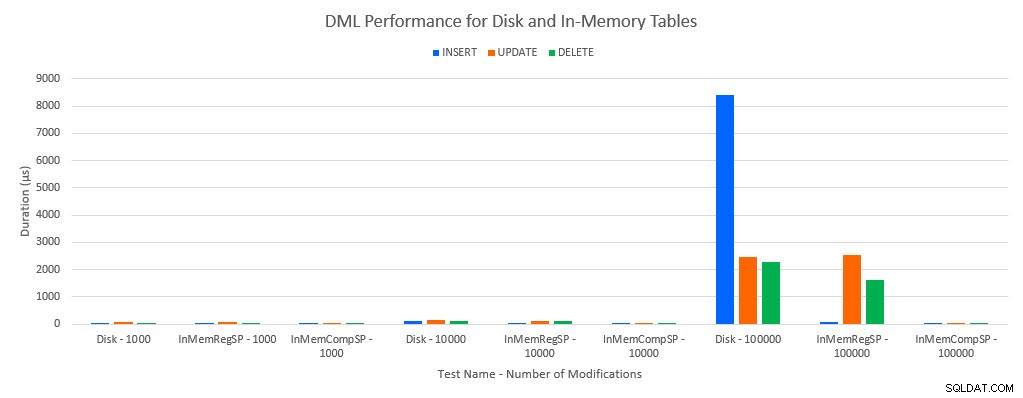
Desempenho de DML por teste e carga de trabalho
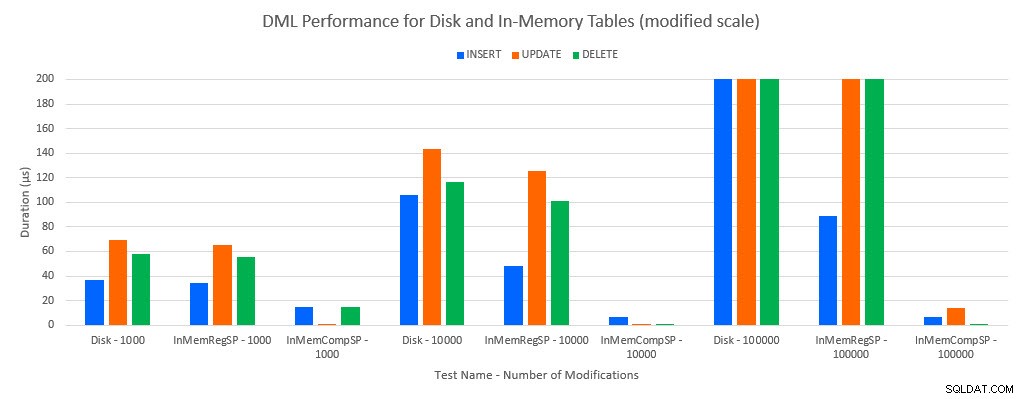
Desempenho de DML por teste e carga de trabalho [escala modificada]
A exceção é INSERTs na tabela In-Memory com o procedimento armazenado regular. Com 100 conexões, a duração média é superior a 8 ms para uma tabela baseada em disco, mas inferior a 100 microssegundos para a tabela In-Memory. O motivo provável é a ausência de bloqueio e travamento com a tabela In-Memory, e isso é compatível com dados de estatísticas de espera:
| Teste | INSERIR | ATUALIZAÇÃO | EXCLUIR |
|---|---|---|---|
| Tabela de disco – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Tabela de disco – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10.000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Tabela de disco – 100.000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100.000 | WRITELOG | WRITELOG | WRITELOG |
Estatísticas de espera por teste
Os dados de estatísticas de espera são listados aqui com base no Tempo de espera total do recurso (que geralmente também é traduzido para o tempo médio de recurso mais alto, mas houve exceções). O tipo de espera WRITELOG é o fator limitante neste sistema na maioria das vezes. No entanto, o PAGELATCH_EX aguarda 100 conexões simultâneas executando instruções INSERT sugere que, com carga adicional, o comportamento de travamento e travamento que existe com tabelas baseadas em disco pode ser um fator limitante. Nos cenários UPDATE e DELETE com 10 e 100 conexões para os testes de tabela baseada em disco, o Tempo Médio de Espera de Recurso foi mais alto para bloqueios (LCK_M_X).
Conclusão
O OLTP na memória pode fornecer absolutamente um aumento de desempenho para a carga de trabalho certa. Os exemplos testados aqui, no entanto, são extremamente simples e não devem ser considerados apenas como motivo para migrar para uma solução In-Memory. Existem várias limitações que ainda existem que devem ser consideradas, e testes completos devem ser feitos antes que uma migração ocorra (principalmente porque a migração para uma tabela In-Memory é um processo offline). Mas para o cenário certo, esse novo recurso pode fornecer um aumento de desempenho. Contanto que você entenda que algumas limitações subjacentes ainda existirão, como a velocidade do log de transações para tabelas duráveis, embora provavelmente de maneira reduzida – independentemente de a tabela existir no disco ou na memória.