Este blog inicia uma multi-série documentando minha jornada no benchmarking do PostgreSQL na nuvem.
A primeira parte inclui uma visão geral das ferramentas de benchmarking e dá início à diversão com o Amazon Aurora PostgreSQL.
Selecionando os provedores de serviços em nuvem PostgreSQL
Há algum tempo, me deparei com o procedimento de benchmark da AWS para o Aurora e achei que seria muito legal se eu pudesse fazer esse teste e executá-lo em outros provedores de hospedagem em nuvem. Para crédito da Amazon, dos três provedores de computação utilitária mais conhecidos – AWS, Google e Microsoft – a AWS é o único grande contribuinte para o desenvolvimento do PostgreSQL e o primeiro a oferecer o serviço PostgreSQL gerenciado (em novembro de 2013).
Embora os serviços gerenciados do PostgreSQL também estejam disponíveis em uma infinidade de provedores de hospedagem PostgreSQL, eu queria me concentrar nos três provedores de computação em nuvem mencionados, já que seus ambientes são onde muitas organizações que procuram as vantagens da computação em nuvem optam por executar seus aplicativos, desde que tenham o know-how necessário no gerenciamento do PostgreSQL. Acredito firmemente que, no cenário de TI atual, as organizações que trabalham com cargas de trabalho críticas na nuvem se beneficiariam muito dos serviços de um provedor de serviços PostgreSQL especializado, que pode ajudá-las a navegar no mundo complexo do GUCS e em inúmeras apresentações do SlideShare.
Selecionando a ferramenta de comparação certa
Benchmarking O PostgreSQL aparece com bastante frequência na lista de discussão de desempenho e, conforme enfatizado inúmeras vezes, os testes não têm a intenção de validar uma configuração para um aplicativo da vida real. No entanto, selecionar a ferramenta e os parâmetros de referência corretos são importantes para obter resultados significativos. Eu esperaria que todo provedor de nuvem fornecesse procedimentos para benchmarking de seus serviços, especialmente quando a primeira experiência na nuvem pode não começar com o pé direito. A boa notícia é que dois dos três jogadores neste teste incluíram benchmarks em sua documentação. O guia AWS Benchmark Procedure for Aurora é fácil de encontrar, disponível diretamente na página Amazon Aurora Resources. O Google não fornece um guia específico para PostgreSQL, mas a documentação do Compute Engine contém um guia de teste de carga para SQL Server baseado em HammerDB.
A seguir está um resumo das ferramentas de benchmark com base em suas referências que valem a pena ser analisadas:
- O AWS Benchmark mencionado acima é baseado em pgbench e sysbench.
- O HammerDB, também mencionado anteriormente, é discutido em um post recente na lista pgsql-hackers.
- Testes TPC-C baseados no oltpbench, como mencionado nesta outra discussão sobre pgsql-hackers.
- benchmarksql é mais um teste TPC-C que foi usado para validar as alterações nas divisões de página B-Tree.
- pg_ycsb é o novo garoto da cidade, aprimorando o pgbench e já sendo usado por alguns hackers do PostgreSQL.
- pgbench-tools, como o nome sugere, é baseado no pgbench e, embora não tenha recebido nenhuma atualização desde 2016, é produto de Greg Smith, autor dos livros PostgreSQL High Performance.
- join order benchmark é um benchmark que testará o otimizador de consulta.
- pgreplay, que encontrei ao ler o blog do prompt de comando, é o mais próximo possível de um benchmarking de um cenário da vida real.
Outro ponto a ser observado é que o PostgreSQL ainda não é adequado para o padrão de benchmark TPC-H e, como observado acima, todas as ferramentas (exceto pgreplay) devem ser executadas no modo TPC-C (pgbench é o padrão).
Para os propósitos deste blog, achei que o AWS Benchmark Procedure for Aurora é um bom começo simplesmente porque define um padrão para provedores de nuvem e é baseado em ferramentas amplamente utilizadas.
Além disso, usei a versão mais recente do PostgreSQL disponível na época. Ao selecionar um provedor de nuvem, é importante considerar a frequência das atualizações, especialmente quando recursos importantes introduzidos por novas versões podem afetar o desempenho (que é o caso das versões 10 e 11 versus 9). A partir desta escrita temos:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS para PostgreSQL 10.6
- Google Cloud SQL para PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
...e o vencedor aqui é a AWS, oferecendo a versão mais recente (embora não seja a mais recente, que até o momento é 11.2).
Configurando o ambiente de comparação
Decidi limitar meus testes a cargas de trabalho médias por alguns motivos:primeiro, os recursos de nuvem disponíveis não são idênticos entre os provedores. No guia, as especificações da AWS para a instância do banco de dados são 64 vCPU / 488 GiB RAM / 25 Gigabit Network, enquanto a RAM máxima do Google para qualquer tamanho de instância (a escolha deve ser definida como “custom” na Google Calculator) é 208 GiB, e o Business Critical Gen5 da Microsoft com 32 vCPU vem com apenas 163 GiB). Segundo, a inicialização do pgbench traz o tamanho do banco de dados para 160GiB que, no caso de uma instância com 488 GiB de RAM, provavelmente será armazenado na memória.
Além disso, deixei a configuração do PostgreSQL intocada. A razão para manter os padrões do provedor de nuvem é que, fora da caixa, quando pressionado por um benchmark padrão, espera-se que um serviço gerenciado tenha um desempenho razoavelmente bom. Lembre-se de que a comunidade PostgreSQL executa testes pgbench como parte do processo de gerenciamento de versões. Além disso, o guia da AWS não menciona nenhuma alteração na configuração padrão do PostgreSQL.
Conforme explicado no guia, a AWS aplicou dois patches ao pgbench. Como o patch para o número de clientes não se aplicava perfeitamente na versão 10.6 do PostgreSQL e eu não queria investir tempo para corrigi-lo, o número de clientes foi limitado ao máximo de 1.000.
O guia especifica um requisito para que a instância do cliente tenha a rede avançada habilitada — para esse tipo de instância que é o padrão:
[example@sqldat.com ~]$ ip a1:lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 host de escopo lo valid_lft sempre preferido_lft sempre inet6 ::1/128 host de escopo valid_lft sempre preferido_lft sempre2:eth0: mtu 9001 qdisc mq state UP group default qlen 1000 link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0 valid_lft para sempre preferido_lft para sempre inet6 fe80::8cd:eeff:fe40:2be6/64 escopo link valid_lft sempre preferido_lft para sempre[example@sqldat.com ~]$ ethtool -i eth0driver:enaversion:2.0.2gfirmware-version:bus-info:0000:00:03.0supports-statistics:yessupports-test:nosupports-eeprom-access:nosupports-register-dump:nosupports-priv-flags:no>>> aws (master *%) ~ $ aws ec2 describe-instances --instance- ids i-0ee51642334c1ec57 --que ry "Reservations[].Instances[].EnaSupport"[ true] Execução do comparativo de mercado no Amazon Aurora PostgreSQL
Durante a corrida real, decidi fazer mais um desvio do guia:em vez de executar o teste por 1 hora, defina o limite de tempo para 10 minutos, o que geralmente é aceito como um bom valor.
Execução nº 1
Especificidades
- Este teste usa as especificações da AWS para tamanhos de instância de cliente e banco de dados.
- Máquina cliente:instância do EC2 otimizada para memória sob demanda:
- vCPU:32 (16 núcleos x 2 threads/núcleo)
- RAM:244 GiB
- Armazenamento:Otimizado para EBS
- Rede:10 Gigabits
- Cluster de banco de dados:db.r4.16xlarge
- vCPU:64
- ECU (capacidade da CPU):195 x [1,0-1,2 GHz] 2007 Opteron / Xeon
- RAM:488 GiB
- Armazenamento:EBS otimizado (capacidade dedicada para E/S)
- Rede:largura de banda máxima de 14.000 Mbps em uma rede de 25 Gps
- Máquina cliente:instância do EC2 otimizada para memória sob demanda:
- A configuração do banco de dados incluiu uma réplica.
- O armazenamento do banco de dados não foi criptografado.
Realizando os testes e resultados
- Siga as instruções no guia para instalar o pgbench e o sysbench.
- Edite ~/.bashrc para definir as variáveis de ambiente para a conexão do banco de dados e os caminhos necessários para as bibliotecas PostgreSQL:
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.comexport PGUSER=postgresexport PGPASSWORD=postgresexport PGDATABASE=postgresexport PATH=$PATH:/usr/local/pgsql/binexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Inicialize o banco de dados:
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000NOTICE:table "pgbench_history" não existe, skippingNOTICE:table "pgbench_tellers" não existe, skippingNOTICE:a tabela "pgbench_accounts" não existe, skippingNOTICE:a tabela "pgbench_branches" não existe, ignorandocriando tabelas...100000 de 1000000000 tuplas (0%) concluída (decorrido 0,05 s, restante 457,23 s)200000 de 1000000000 tuplas (0%) feitas (decorridos 0,13 s, restantes 631,70 s) 300000 de 1000000000 tuplas (0%) feitas (decorridos 0,21 s, restantes 688,29 s)... (0,41 s restantes) 999600000 de 1000000000 tuplas (99%) feito (decorrido 811,50 s, restante 0,32 s) 999700000 de 1000000000 tuplas (99%) feito (decorrido 811,58 s, restante 0,24 s) 999800900 de 1000000000 feito (decorrido 811,58 s, restante 0,24 s) 999800900 decorridos 811,65 s, restantes 0,16 s) 999900000 de 1000000000 tuplas (99%) feitas (decorridos 811,73 s, restantes 0,08 s) 1000000000 de 1000000000 tuplas ( 100%) concluído (passado 811,80 s, restante 0,00 s)vácuo...definir chaves primárias...concluído. - Verifique o tamanho do banco de dados:
postgres=> \l+ postgres Lista de bancos de dados Nome | Proprietário | Codificação | Agrupar | Ctipo | Privilégios de acesso | Tamanho | Espaço de tabela | Descrição----------+----------+----------+-------------+-- -------+-------------------+--------+--------- ---+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | banco de dados de conexão administrativa padrão (1 linha) - Use a seguinte consulta para verificar se o intervalo de tempo entre os pontos de verificação está definido para que os pontos de verificação sejam forçados durante a execução de 10 minutos:
Resultado:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpointsFROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutos_entre_checkpoints-------------------+----------------------------- 50 | 0.977392292333333(1 linha) - Execute a carga de trabalho de leitura/gravação:
Saída[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048iniciando vácuo...end.progress:60,0 s, 35670,3 tps, lat 27,243 ms stddev 10,915progress:120,0 s, 36569,5 tps, lat 27,352 ms stddev 11,859progress:180,0 s, 35845,2 tps, lat tps MS stddev 12.785Progress:240,0 s, 36613.7 TPS, Lat 27.310 ms stddev 11.804Progress:300.0 S, 37323.4 TPS, Lat 26.793 MS StdDev 11.36PROUSS:360.0 S, 36828.8.8 Lat 27.268 ms stddev 12.083Progress:480,0 s, 37176,1 tps, lat 26.899 ms stddev 10.981Progress:540.0 s, 37210.8 tps, lat 26.875 ms stdDev 11.341.Progress:600.0. TPC-B (mais ou menos)>fator de escala:10000modo de consulta:preparadonúmero de clientes:1000número de threads:1000duração:600 snúmero de transações realmente processadas:22040445média de latência =27,149 mslatency stddev =11,617 mstps =36710,8285424 (incluindo o estabelecimento de conexões)tps =36811. (excluindo o estabelecimento de conexões) - Prepare o teste do sysbench:
Saída:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1. rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ -- oltp-table-size=450000 \ prepararsysbench 0.5:benchmark de avaliação de sistema multi-threadCreating table 'sbtest1'...Inserindo 450.000 registros em 'sbtest1'Creating secondary index on 'sbtest1'...Creating table 'sbtest2'.... ..Criando tabela 'sbtest250'...Inserindo 450.000 registros em 'sbtest250'Criando índices secundários em 'sbtest250'... - Execute o teste do sysbench:
Saída:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1. rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ -- oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp- sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ executarsysbench 0.5:benchmark de avaliação de sistema multi-threadExecutando o teste com as seguintes opções:Número de threads:1000Relatar resultados intermediários a cada 60 segundos(s) Semente do gerador de números aleatórios é 0 e será ignoradoForçar desligamento em 630 segundosInicializando threads de trabalho...Threads iniciados![ 60s] threads:1000, tps:20443,09, leituras:0,00, gravações:81834,16, tempo de resposta:68,24ms (95%), erros:0,62, reconecta:0,00[ 120s] threads:1000 , tps:20580,68, leituras:0,00, gravações:82324,33, tempo de resposta:70,75 ms (95%), erros:0,73, reconecta:0,00[ 180s] threads:1000, tps:20531,85, leituras:0,00, gravações:82127,21, resposta tempo:70,63ms (95%), erros:0,73, reconecta:0,00[ 240s] threads:1000, tps:20212,67, leituras:0,00, gravações:80861,67, tempo de resposta:71,99ms (95%), erros:0,43, reconecta :0,00[ 300s] threads:1000, tps:19383,90, leituras:0,00, gravações:77537,87, tempo de resposta:75,64ms (95%), erros:0,75, reconecta:0,00[ 360s] threads:1000, tps:19797,2 0, leituras:0,00, gravações:79190,78, tempo de resposta:75,27 ms (95%), erros:0,68, reconecta:0,00[ 420s] threads:1000, tps:20304,43, leituras:0,00, gravações:81212,87, tempo de resposta:73,82 ms (95%), erros:0,70, reconecta:0,00[ 480s] threads:1000, tps:20933,80, leituras:0,00, gravações:83737,16, tempo de resposta:74,71ms (95%), erros:0,68, reconecta:0,00[ 540s] threads:1000, tps:20663,05, leituras:0,00, gravações:82626,42, tempo de resposta:73,56 ms (95%), erros:0,75, reconecta:0,00[ 600s] threads:1000, tps:20746,02, leituras:0,00, gravações:83015.81, tempo de resposta:73,58ms (95%), erros:0,78, reconecta:0,00OLTP estatísticas de teste:consultas realizadas:leitura:0 gravação:48868458 outros:24434022 total:73302480 transações:12216804 (20359,59 por segundo) leitura /write solicitações:48868458 (81440,43 por segundo) outras operações:24434022 (40719,87 por segundo) erros ignorados:414 (0,69 por segundo) reconecta:0 (0,00 por segundo) Estatísticas gerais:tempo total:600,0516s número total de eventos:12216804 tempo total gasto pela execução do evento:599964,4735s resposta tempo:min:6,27ms média:49,11ms máx.:350,24ms aprox. Percentil 95:72,90 ms Imparcialidade dos threads:eventos (média/stddev):12216,8040/31,27 tempo de execução (média/stddev):599,9645/0,01
Métricas coletadas
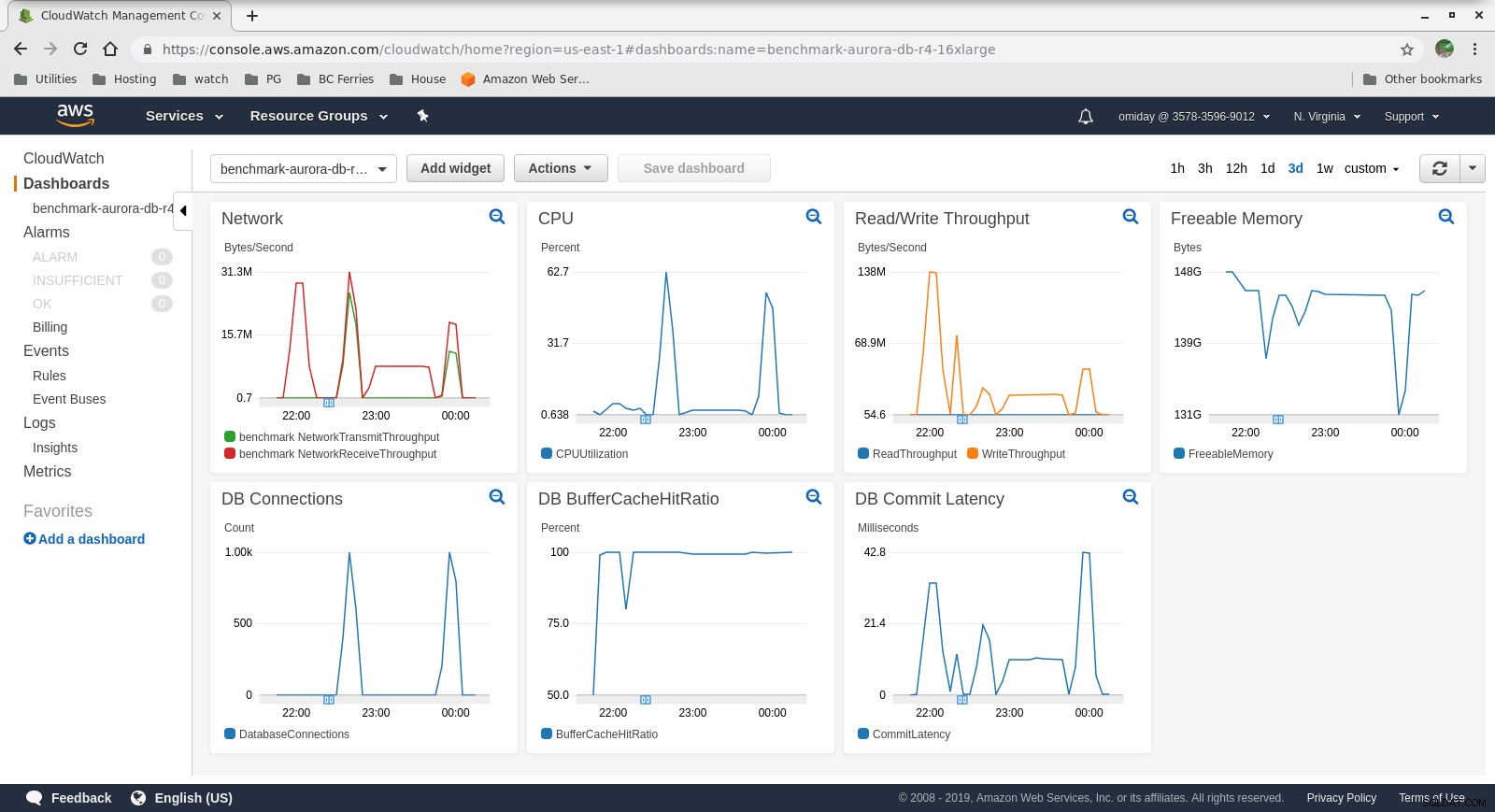 Métricas do Cloudwatch
Métricas do Cloudwatch 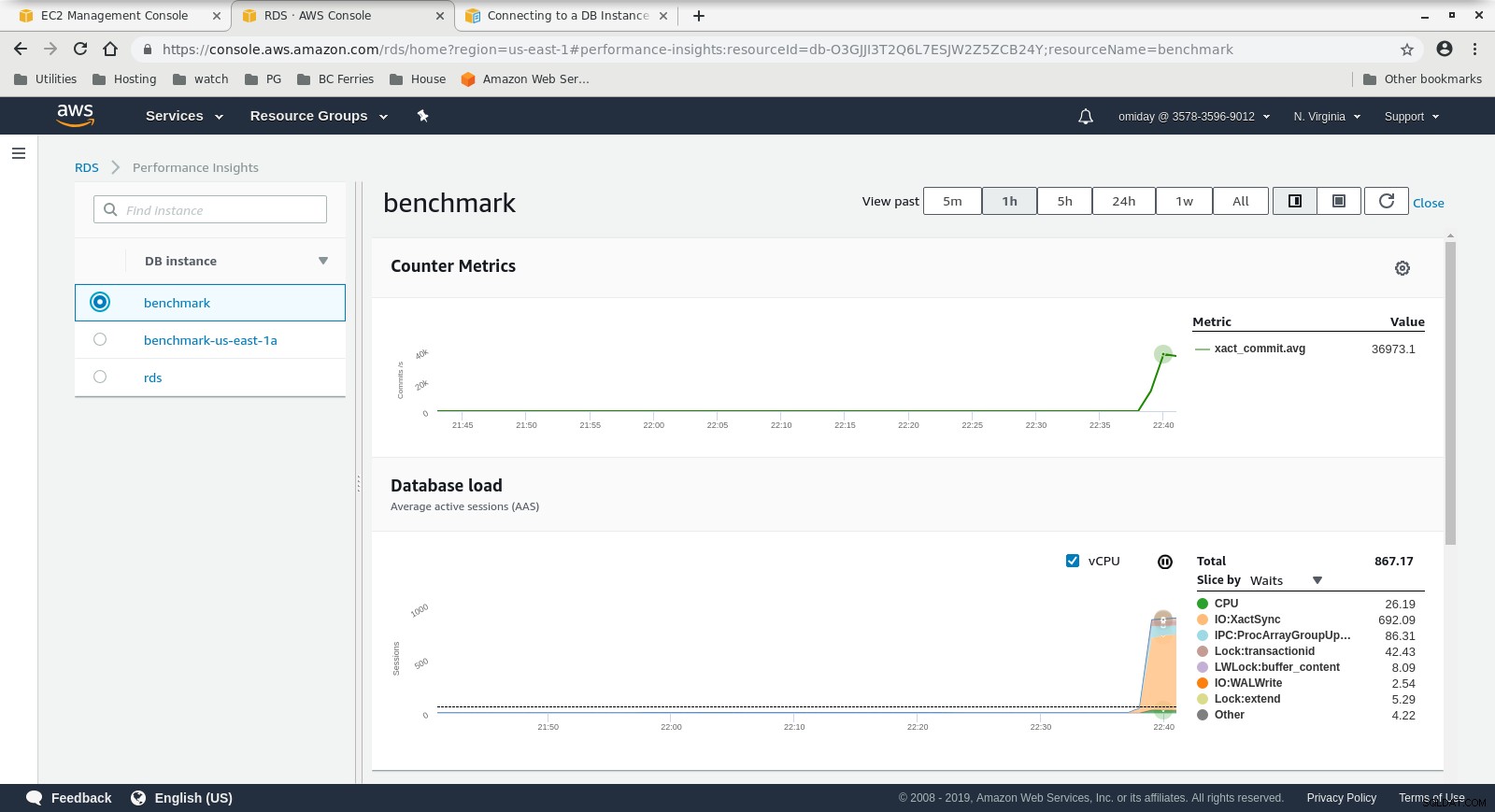 Métricas de insights de desempenhoBaixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba mais sobre o que você precisa saber para implantar, monitorar, gerencie e dimensione o PostgreSQLBaixe o whitepaper
Métricas de insights de desempenhoBaixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba mais sobre o que você precisa saber para implantar, monitorar, gerencie e dimensione o PostgreSQLBaixe o whitepaper Execução nº 2
Especificidades
- Este teste usa as especificações da AWS para o cliente e um tamanho de instância menor para o banco de dados:
- Máquina cliente:instância do EC2 otimizada para memória sob demanda:
- vCPU:32 (16 núcleos x 2 threads/núcleo)
- RAM:244 GiB
- Armazenamento:Otimizado para EBS
- Rede:10 Gigabits
- Cluster de banco de dados:db.r4.2xlarge:
- vCPU:8
- RAM:61 GiB
- Armazenamento:Otimizado para EBS
- Rede:largura de banda máxima de 1.750 Mbps em uma conexão de até 10 Gbps
- Máquina cliente:instância do EC2 otimizada para memória sob demanda:
- O banco de dados não incluiu uma réplica.
- O armazenamento do banco de dados não foi criptografado.
Realizando os testes e resultados
As etapas são idênticas à execução nº 1, então estou mostrando apenas a saída:
-
Carga de trabalho de leitura/gravação do pgbench:
(pre>...745700000 de 1000000000 tuplas (74%) concluídas (decorridos 794,93 s, restantes 271,09 s) 745800000 de 1000000000 tuplas (74%) concluídas (decorridas 795,00 s, restantes 270,97 s) 745900000 de 100000000 74%) feito (decorridos 795,09 s, restantes 270,86 s) 746000000 de 1000000000 tuplas (74%) feito (decorridos 795,17 s, restantes 270,74 s) 746100000 de 1000000000 tuplas (74%) feito (decorridos 795,240,0000 s) de 1.000.000.000 tuplas (74%) feitas (decorridos 795,33 s, restantes 270,51 s) s, 0,11 s restantes) 1000000000 de 1000000000 tuplas (100%) feito (decorrido 1067,28 s, restante 0,00 s)vácuo...definir chaves primárias...tempo total:4386,44 s (inserir 1067,33 s, confirmar 0,46 s, vácuo 2088,25 s, índice 1230,41 s)concluído.iniciando vácuo...end.progress:60,0 s, 3361,3 tps, lat 286,143 ms stddev 80,417progress:120,0 s, 3466,8 tps, lat 288,386 ms stddev 76,373progress:180,0 s, 3683,1 tps, lat 271,840 ms stddev 75.712Progress:240,0 s, 3444.3 TPS, Lat 289.909 ms stddev 69.564Progress:300.0 s, 3475.8 tps, Lat 287.736 ms StdDev 73.712 Ms:360.0 S, 3449.5. 284.432 ms stddev 74.276progress:480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264progress:540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206progress:600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649transaction type: -
teste do sysbench:
sysbench 0.5:benchmark de avaliação de sistema multi-threadExecutando o teste com as seguintes opções:Número de threads:1000Relatar resultados intermediários a cada 60 segundos(s) Semente do gerador de número aleatório é 0 e será ignoradoForçar desligamento em 630 segundosInicializando threads de trabalho ...Threads iniciados![ 60s] threads:1000, tps:4809,05, leituras:0,00, gravações:19301,02, tempo de resposta:288,03ms (95%), erros:0,05, reconecta:0,00[ 120s] threads:1000, tps :5264,15, leituras:0,00, gravações:21005,40, tempo de resposta:255,23 ms (95%), erros:0,08, reconecta:0,00[ 180s] threads:1000, tps:5178,27, leituras:0,00, gravações:20713,07, tempo de resposta:260,40 ms (95%), erros:0,03, reconecta:0,00[ 240 s] threads:1000, tps:5145,95, leituras:0,00, gravações:20610,08, tempo de resposta:255,76 ms (95%), erros:0,05, reconecta:0,00 [300s] threads:1000, tps:5127,92, leituras:0,00, gravações:20507,98, tempo de resposta:264,24ms (95%), erros:0,05, reconecta:0,00[360s] threads:1000, tps:5063,83, lê:0,00, gravações:20278,10, tempo de resposta:268,55ms (95%), erros:0,05, reconecta:0,00[420s] threads:1000, tps:5057,51, leituras:0,00, gravações:20237,28, tempo de resposta:269,19ms (95% ), erros:0,10, reconecta:0,00[ 480s] threads:1000, tps:5036,32, lê:0,00, grava:20139,29, tempo de resposta:279,62ms (95%), erros:0,10, reconecta:0,00[ 540s] threads:1000, tps:5115,25, leituras:0,00, gravações:20459,05, tempo de resposta:264,64 ms (95%), erros:0,08, reconexão:0,00[ 600s] threads:1000, tps:5124,89, leituras:0,00, gravações:20510,07, tempo de resposta:265,43ms (95%), erros:0,10, reconecta:0,00OLTP estatísticas de teste:consultas realizadas:leitura:0 gravação:12225686 outros:6112822 total:18338508 transações:3056390 (5093,75 por segundo) solicitações de leitura/gravação:12225686 (20375,20 por seg.) outras operações:6112822 (10187,57 por segundo) erros ignorados:42 (0,07 por segundo) reconecta:0 (0,00 por segundo) Estatísticas gerais:tempo total:600,0277s número total de eventos:3056390 tempo total gasto pela execução do evento:600005,2104s resposta tempo:min:9,57ms média:196,31ms máx.:608,70ms aprox. 95 percentil:268,71ms Justiça de threads:eventos (média/stddev):3056,3900/67,44 tempo de execução (média/stddev):600,0052/0,01
Métricas coletadas
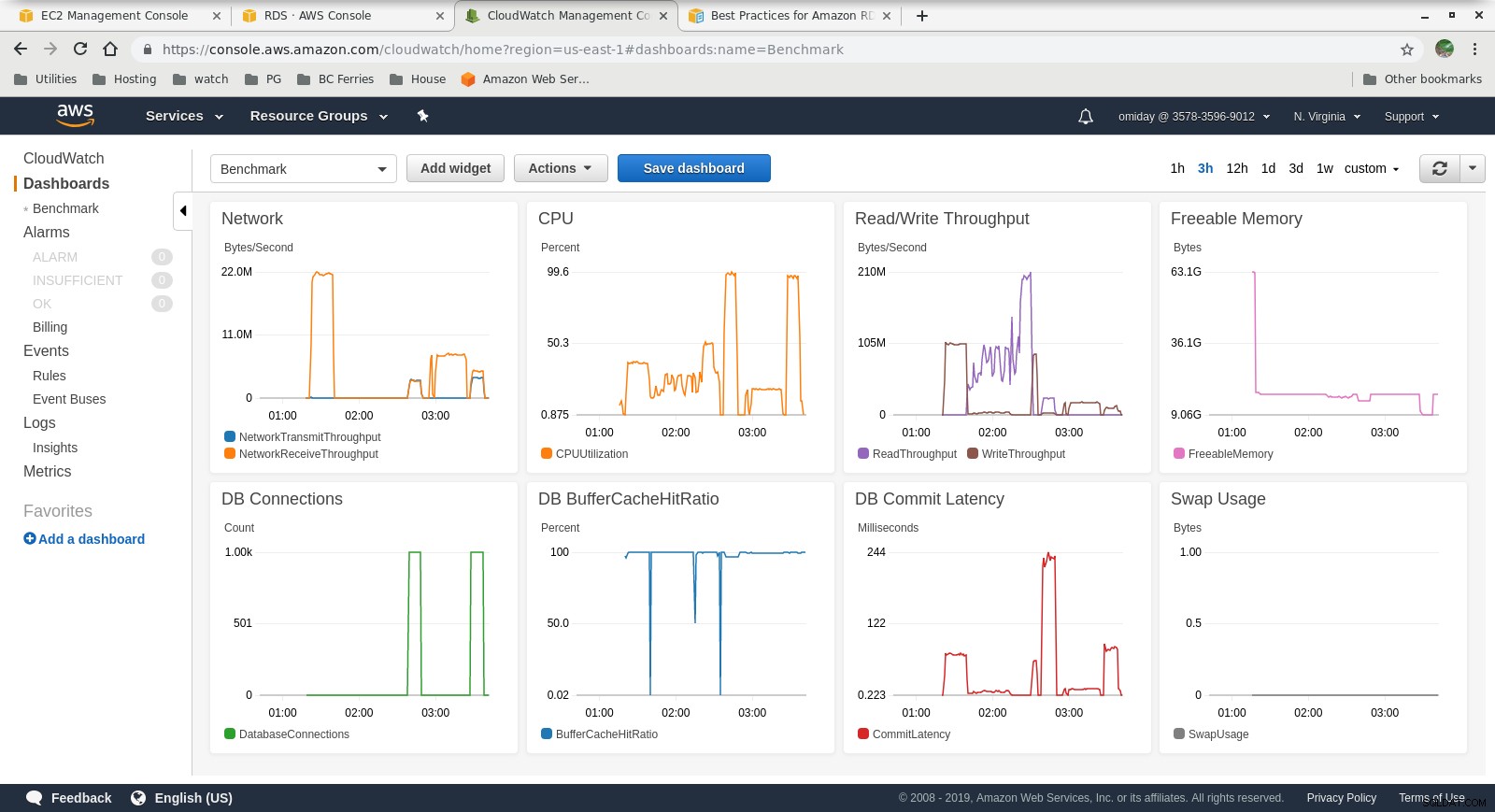 Métricas do Cloudwatch
Métricas do Cloudwatch 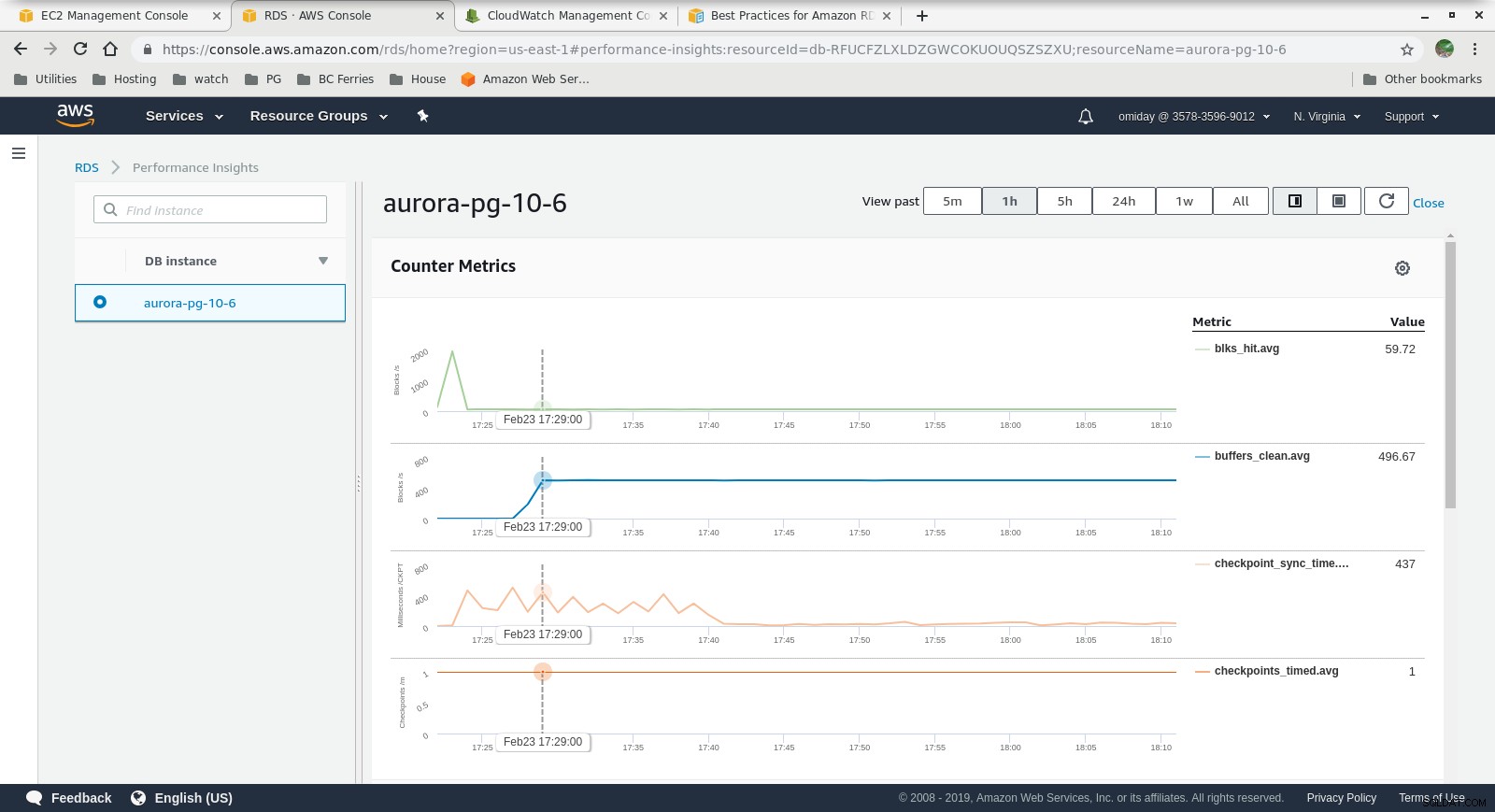 Performance Insights - Counter Metrics
Performance Insights - Counter Metrics 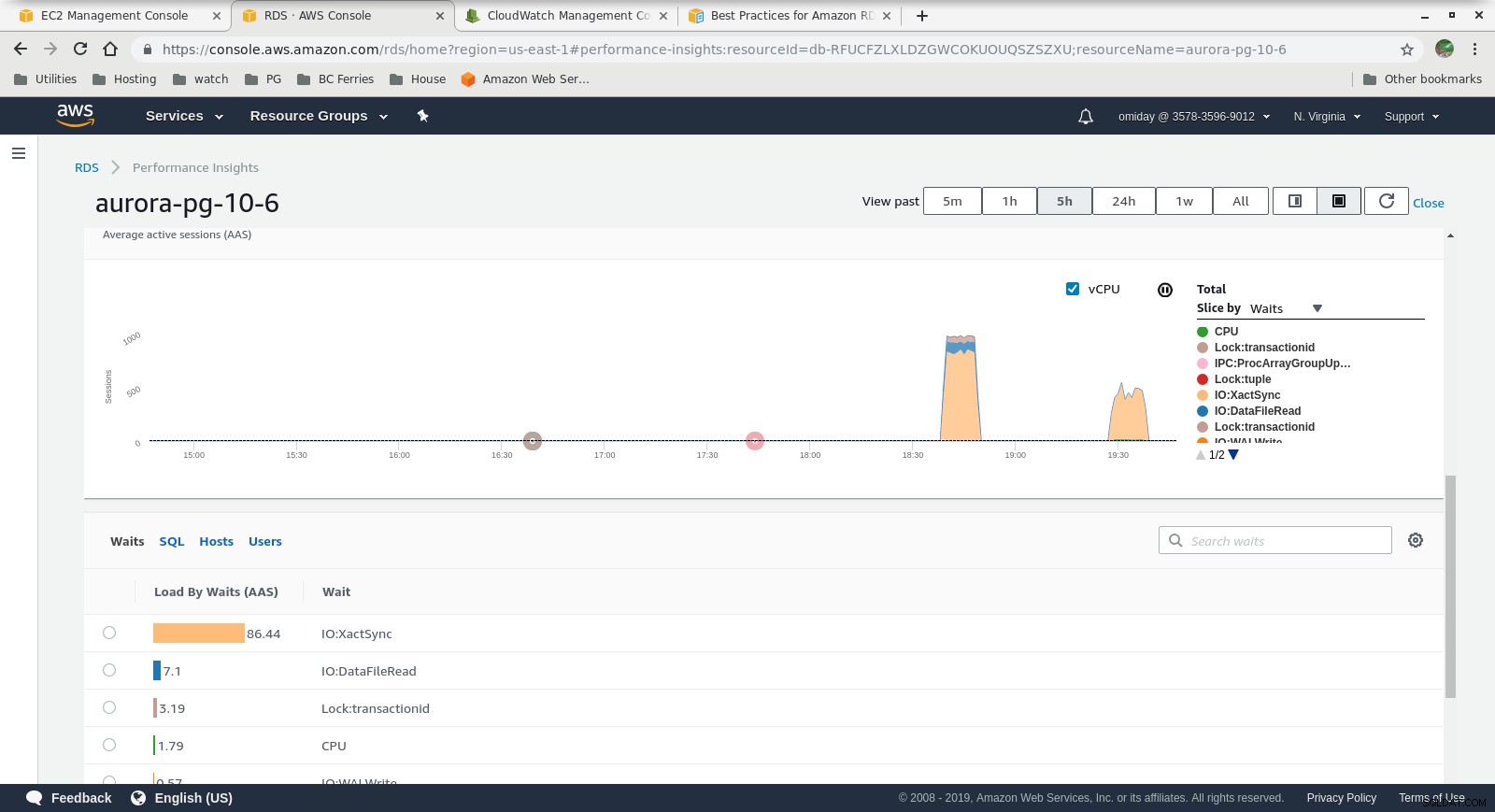 Performance Insights - Carregamento de banco de dados por esperas
Performance Insights - Carregamento de banco de dados por esperas Considerações finais
- Os usuários estão limitados a usar tamanhos de instância predefinidos. Como desvantagem, se o benchmark mostrar que a instância pode se beneficiar de memória adicional, não é possível “apenas adicionar mais RAM”. Adicionar mais memória significa aumentar o tamanho da instância que vem com um custo mais alto (o custo dobra para cada tamanho de instância).
- O mecanismo de armazenamento do Amazon Aurora é muito diferente do RDS e é desenvolvido com base no hardware SAN. As métricas de taxa de transferência de E/S por instância mostram que o teste não se aproximou ainda mais do máximo para os volumes EBS de SSD IOPS provisionados de 1.750 MiB/s.
- Outros ajustes podem ser realizados analisando os eventos do AWS PostgreSQL incluídos nos gráficos do Performance Insights.
Próximo da série
Fique atento à próxima parte:Amazon RDS for PostgreSQL 10.6.