O PostgreSQL é um dos bancos de dados de código aberto mais avançados do mundo, com muitos recursos excelentes. Um deles é o Streaming Replication (Physical Replication) que foi introduzido no PostgreSQL 9.0. Ele é baseado em registros XLOG que são transferidos para o servidor de destino e aplicados lá. No entanto, é baseado em cluster e não podemos fazer um único banco de dados ou replicação de objeto único (replicação seletiva). Ao longo dos anos, dependemos de ferramentas externas como Slony, Bucardo, BDR, etc. para replicação seletiva ou parcial, pois não havia recursos no nível do núcleo até o PostgreSQL 9.6. No entanto, o PostgreSQL 10 surgiu com um recurso chamado Replicação Lógica, através do qual podemos realizar replicação em nível de banco de dados/objeto.
A Replicação Lógica replica as alterações de objetos com base em sua identidade de replicação, que geralmente é uma chave primária. É diferente da replicação física, na qual a replicação é baseada em blocos e replicação byte a byte. A Replicação Lógica não precisa de uma cópia binária exata no lado do servidor de destino, e temos a capacidade de escrever no servidor de destino, ao contrário da Replicação Física. Este recurso se origina do módulo pglogical.
Neste post do blog, vamos discutir:
- Como funciona - Arquitetura
- Recursos
- Casos de uso - quando é útil
- Limitações
- Como alcançá-lo
Como funciona - Arquitetura de replicação lógica
A Replicação Lógica implementa um conceito de publicação e assinatura (Publicação e Assinatura). Abaixo está um diagrama de arquitetura de nível superior sobre como ele funciona.
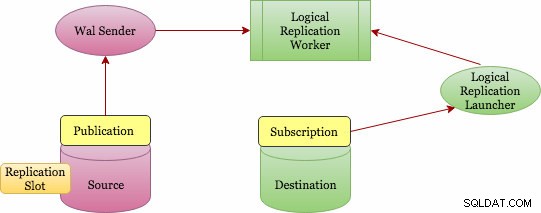
Arquitetura de replicação lógica básica
A publicação pode ser definida no servidor mestre e o nó no qual ela é definida é chamado de "editor". A publicação é um conjunto de alterações de uma única tabela ou grupo de tabelas. Está no nível do banco de dados e cada publicação existe em um banco de dados. Várias tabelas podem ser adicionadas a uma única publicação e uma tabela pode estar em várias publicações. Você deve adicionar objetos explicitamente a uma publicação, exceto se escolher a opção "TODAS AS TABELAS", que precisa de um privilégio de superusuário.
Você pode limitar as alterações de objetos (INSERT, UPDATE e DELETE) a serem replicados. Por padrão, todos os tipos de operação são replicados. Você deve ter uma identidade de replicação configurada para o objeto que deseja adicionar a uma publicação. Isso é para replicar as operações UPDATE e DELETE. A identidade de replicação pode ser uma chave primária ou um índice exclusivo. Se a tabela não tiver uma chave primária ou índice exclusivo, ela poderá ser definida como identidade de réplica "completa", na qual todas as colunas serão consideradas chave (a linha inteira se tornará a chave).
Você pode criar uma publicação usando CREATE PUBLICATION. Alguns comandos práticos são abordados na seção "Como alcançá-lo".
A assinatura pode ser definida no servidor de destino e o nó no qual ela é definida é chamado de "assinante". A conexão com o banco de dados de origem é definida na assinatura. O nó do assinante é o mesmo que qualquer outro banco de dados postgres autônomo, e você também pode usá-lo como uma publicação para outras assinaturas.
A assinatura é adicionada usando CREATE SUBSCRIPTION e pode ser interrompida/reiniciada a qualquer momento usando o comando ALTER SUBSCRIPTION e removida usando DROP SUBSCRIPTION.
Depois que uma assinatura é criada, a replicação lógica copia um instantâneo dos dados no banco de dados do editor. Feito isso, ele aguarda as alterações delta e as envia para o nó de assinatura assim que elas ocorrem.
No entanto, como as mudanças são coletadas? Quem os envia para o alvo? E quem as aplica no alvo? A replicação lógica também se baseia na mesma arquitetura da replicação física. É implementado pelos processos “walsender” e “apply”. Como se baseia na decodificação WAL, quem inicia a decodificação? O processo walsender é responsável por iniciar a decodificação lógica do WAL e carrega o plug-in de decodificação lógica padrão (pgoutput). O plugin transforma as alterações lidas do WAL para o protocolo de replicação lógica e filtra os dados de acordo com a especificação da publicação. Os dados são então transferidos continuamente usando o protocolo de replicação de streaming para o operador de aplicação, que mapeia os dados para tabelas locais e aplica as alterações individuais à medida que são recebidas, na ordem transacional correta.
Ele registra todas essas etapas em arquivos de log durante a configuração. Podemos ver as mensagens na seção "Como conseguir isso" mais adiante no post.
Recursos de replicação lógica
- A replicação lógica replica objetos de dados com base em sua identidade de replicação (geralmente uma
- chave primária ou índice exclusivo).
- O servidor de destino pode ser usado para gravações. Você pode ter diferentes índices e definições de segurança.
- A replicação lógica tem suporte entre versões. Ao contrário da Replicação de Streaming, a Replicação Lógica pode ser configurada entre diferentes versões do PostgreSQL (> 9.4, no entanto)
- A replicação lógica faz filtragem baseada em eventos
- Quando comparada, a replicação lógica tem menos amplificação de gravação do que a replicação de streaming
- As publicações podem ter várias assinaturas
- A replicação lógica fornece flexibilidade de armazenamento por meio da replicação de conjuntos menores (mesmo tabelas particionadas)
- Carga mínima do servidor em comparação com soluções baseadas em gatilho
- Permite streaming paralelo entre editores
- A replicação lógica pode ser usada para migrações e atualizações
- A transformação de dados pode ser feita durante a configuração.
Casos de uso - quando a replicação lógica é útil?
É muito importante saber quando usar a Replicação Lógica. Caso contrário, você não obterá muitos benefícios se seu caso de uso não corresponder. Então, aqui estão alguns casos de uso sobre quando usar a Replicação Lógica:
- Se você deseja consolidar vários bancos de dados em um único banco de dados para fins analíticos.
- Se seu requisito é replicar dados entre diferentes versões principais do PostgreSQL.
- Se você deseja enviar alterações incrementais em um único banco de dados ou em um subconjunto de um banco de dados para outros bancos de dados.
- Se estiver dando acesso a dados replicados para diferentes grupos de usuários.
- Se compartilhar um subconjunto do banco de dados entre vários bancos de dados.
Limitações da replicação lógica
A Replicação Lógica tem algumas limitações nas quais a comunidade está trabalhando continuamente para superar:
- As tabelas devem ter o mesmo nome completo qualificado entre a publicação e a assinatura.
- As tabelas devem ter chave primária ou chave exclusiva
- A replicação mútua (bidirecional) não é compatível
- Não replica esquema/DDL
- Não replica sequências
- Não replica TRUNCATE
- Não replica objetos grandes
- As assinaturas podem ter mais colunas ou uma ordem diferente de colunas, mas os tipos e os nomes das colunas devem corresponder entre Publicação e Assinatura.
- Privilégios de superusuário para adicionar todas as tabelas
- Você não pode transmitir para o mesmo host (a assinatura será bloqueada).
Como obter replicação lógica
Aqui estão as etapas para obter a Replicação Lógica básica. Podemos discutir sobre cenários mais complexos mais tarde.
-
Inicialize duas instâncias diferentes para publicação e assinatura e inicie.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Parâmetros a serem alterados antes de iniciar as instâncias (para instâncias de publicação e assinatura).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server started
Outros parâmetros podem estar no padrão para configuração básica.
-
Altere o arquivo pg_hba.conf para permitir a replicação. Observe que esses valores dependem do seu ambiente, no entanto, este é apenas um exemplo básico (para instâncias de publicação e assinatura).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Crie algumas tabelas de teste para replicar e inserir alguns dados na instância Publication.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Crie a estrutura das tabelas na instância de Assinatura, pois a Replicação Lógica não replica a estrutura.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Crie a publicação na instância Publication (porta 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Crie uma assinatura na instância de assinatura (porta 5556) para a publicação criada na etapa 6.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 ms
Do registro:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finished
Como você pode ver na mensagem AVISO, ele criou um slot de replicação que garante que a limpeza do WAL não seja feita até que o instantâneo inicial ou as alterações delta sejam transferidas para o banco de dados de destino. Em seguida, o remetente WAL começou a decodificar as alterações e a aplicação da replicação lógica funcionou quando o pub e o sub foram iniciados. Em seguida, ele inicia a sincronização da tabela.
-
Verifique os dados na instância de assinatura.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#
Como você vê, os dados foram replicados por meio do instantâneo inicial.
-
Verifique as alterações delta.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
Estas são as etapas para uma configuração básica de replicação lógica.