O vácuo é um dos recursos mais importantes para recuperar tuplas excluídas em tabelas e índices. Sem vácuo, tabelas e índices continuariam a crescer em tamanho sem limites. Esta postagem de blog descreve a opção PARALLEL para o comando VACUUM, que foi recentemente introduzida no PostgreSQL13.
Fases de processamento a vácuo
Antes de discutir a nova opção em profundidade, vamos rever os detalhes de como funciona o vácuo.
Vácuo (sem opção FULL) consiste em cinco fases. Por exemplo, para uma tabela com dois índices, funciona da seguinte forma:
- Fase de varredura de pilha
- Verifique a tabela de cima para baixo e colete tuplas de lixo na memória.
- Fase de vácuo de índice
- Aspire os dois índices um por um.
- Fase de vácuo de pilha
- Aspire o heap (tabela).
- Fase de limpeza do índice
- Limpe os dois índices um por um.
- Fase de truncamento de heap
- Trunque as páginas vazias no final da tabela.
Na fase de verificação de heap, o vácuo pode usar o Mapa de visibilidade para pular o processamento de páginas que são conhecidas como sem lixo, enquanto na fase de vácuo do índice e na fase de limpeza do índice, dependendo dos métodos de acesso ao índice, uma verificação de índice inteira É necessário.
Por exemplo, índices btree, o tipo de índice mais popular, requerem uma varredura de índice inteira para remover tuplas de lixo e fazer a limpeza do índice. Como o vácuo é sempre realizado por um único processo, os índices são processados um a um. O maior tempo de execução do vácuo, especialmente em uma mesa grande, muitas vezes incomoda os usuários.
Opção PARALELA
Para resolver esse problema, propus um patch para paralelizar o vácuo em 2016. Após um longo processo de revisão e muitas reformas, a opção PARALLEL foi introduzida no PostgreSQL 13. Com esta opção, o vácuo pode realizar a fase de vácuo do índice e a fase de limpeza do índice com trabalhadores paralelos. Os trabalhadores de vácuo paralelos são iniciados antes de entrar na fase de vácuo do índice ou na fase de limpeza do índice e saem no final da fase. Um trabalhador Individual é atribuído a um índice. O vácuo paralelo é sempre desabilitado no autovacuum.
A opção PARALLEL sem uma opção de argumento inteiro calculará automaticamente o grau paralelo com base no número de índices na tabela.
VACUUM (PARALLEL) tbl;
Como o processo líder sempre processa um índice, o número máximo de trabalhadores paralelos será (o número de índices na tabela – 1), que é limitado a max_parallel_maintenance_workers. O índice de destino deve ser maior ou igual a min_parallel_index_scan_size.
A opção PARALLEL nos permite especificar o grau paralelo passando um valor inteiro diferente de zero. O exemplo a seguir usa três trabalhadores, para um total de quatro processos em paralelo.
VACUUM (PARALLEL 3) tbl;
A opção PARALELA está ativada por padrão; para desabilitar o vácuo paralelo, defina max_parallel_maintenance_workers como 0 ou especifique
PARALLEL 0 . VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Observando a saída VACUUM VERBOSE, podemos ver que um trabalhador está processando o índice.
As informações impressas como "por trabalhador paralelo" são relatadas pelo trabalhador.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Métodos de acesso de índice vs grau de paralelismo
O vácuo nem sempre executa necessariamente a fase de vácuo do índice e a fase de limpeza do índice em paralelo. Se o tamanho do índice for pequeno ou se for conhecido que o processo pode ser concluído rapidamente, o custo de iniciar e gerenciar trabalhadores paralelos para paralelização causará sobrecarga. Dependendo dos métodos de acesso ao índice e seu tamanho, é melhor não realizar essas fases por um processo de trabalho de vácuo paralelo.
Por exemplo, ao limpar um índice btree grande o suficiente, a fase de vácuo de índice do índice pode ser executada por um operador de vácuo paralelo porque sempre requer uma varredura de índice inteira, enquanto a fase de limpeza de índice é realizada por um operador de vácuo paralelo se o índice vácuo não é executado (por exemplo, não há lixo na mesa). Isso ocorre porque o que os índices btree exigem na fase de limpeza do índice é coletar as estatísticas do índice, que também são coletadas durante a fase de vácuo do índice. Por outro lado, os índices de hash sempre não exigem uma varredura no índice na fase de limpeza do índice.
Para oferecer suporte a diferentes tipos de estratégias de vácuo de índice, os desenvolvedores de métodos de acesso de índice podem especificar esses comportamentos definindo sinalizadores para as
amparallelvacuumoptions campo da IndexAmRoutine estrutura. As bandeiras disponíveis são as seguintes:- VACUUM_OPTION_NO_PARALLEL (padrão)
- o vácuo paralelo é desativado em ambas as fases.
- VACUUM_OPTION_PARALLEL_BULKDEL
- a fase de vácuo do índice pode ser executada em paralelo.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- a fase de limpeza do índice pode ser executada em paralelo se a fase de limpeza do índice ainda não tiver sido executada.
- VACUUM_OPTION_PARALLEL_CLEANUP
- a fase de limpeza do índice pode ser executada em paralelo, mesmo que a fase de vácuo do índice já tenha processado o índice.
A tabela abaixo mostra como o índice AMs interno do PostgreSQL suporta vácuo paralelo.
| nbtree | hash | gin | essência | spgist | brin | florescer | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Veja ‘src/include/command/vacuum.h‘ para mais detalhes.
Verificação de desempenho
Avaliei o desempenho do vácuo paralelo no meu laptop (Core i7 2,6 GHz, 16 GB de RAM, SSD de 512 GB). O tamanho da tabela é de 6 GB e possui oito índices de 3 GB. A relação total é de 30GB, o que não cabe na memória RAM da máquina. Para cada avaliação, sujei vários por cento da mesa uniformemente após a aspiração e, em seguida, realizei a aspiração enquanto alterava o grau paralelo. O gráfico abaixo mostra o tempo de execução do vácuo.
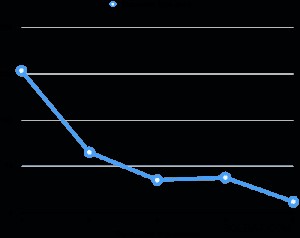
Em todas as avaliações o tempo de execução do vácuo do índice foi responsável por mais de 95% do tempo total de execução. Portanto, a paralelização da fase de vácuo do índice ajudou a reduzir muito o tempo de execução do vácuo.
Obrigado
Agradecimentos especiais a Amit Kapila pela revisão dedicada, aconselhamento e submissão deste recurso ao PostgreSQL 13. Agradeço a todos os desenvolvedores que estiveram envolvidos neste recurso para revisão, teste e discussão.