O monitoramento é uma das tarefas fundamentais em qualquer sistema. Ele pode nos ajudar a detectar problemas e agir, ou simplesmente conhecer o estado atual de nossos sistemas. O uso de exibições visuais pode nos tornar mais eficazes, pois podemos detectar problemas de desempenho com mais facilidade.
Neste blog, veremos como usar o SCUMM para monitorar nossos bancos de dados PostgreSQL e quais métricas podemos usar para essa tarefa. Também analisaremos os painéis disponíveis, para que você possa descobrir facilmente o que realmente está acontecendo com suas instâncias do PostgreSQL.
O que é SCUMM?
Primeiro de tudo, vamos ver o que é SCUMM (Severalnines ClusterControl Unified Monitoring and Management ).
É uma nova solução baseada em agente com agentes instalados nos nós do banco de dados.
Os Agentes SCUMM são exportadores do Prometheus que exportam métricas de serviços como PostgreSQL como métricas do Prometheus.
Um servidor Prometheus é usado para raspar e armazenar dados de séries temporais dos Agentes SCUMM.
O Prometheus é um kit de ferramentas de monitoramento e alerta de sistema de código aberto originalmente construído no SoundCloud. Agora é um projeto de código aberto autônomo e mantido de forma independente.
O Prometheus foi projetado para confiabilidade, para ser o sistema que você acessa durante uma interrupção para permitir o diagnóstico rápido de problemas.
Como usar o SCUMM?
Ao utilizar o ClusterControl, ao selecionar um cluster, podemos ter uma visão geral de nossos bancos de dados, bem como algumas métricas básicas que podem ser utilizadas para identificar um problema. No painel abaixo, podemos ver uma configuração mestre-escravo com um mestre e 2 escravos, com HAProxy e Keepalived.
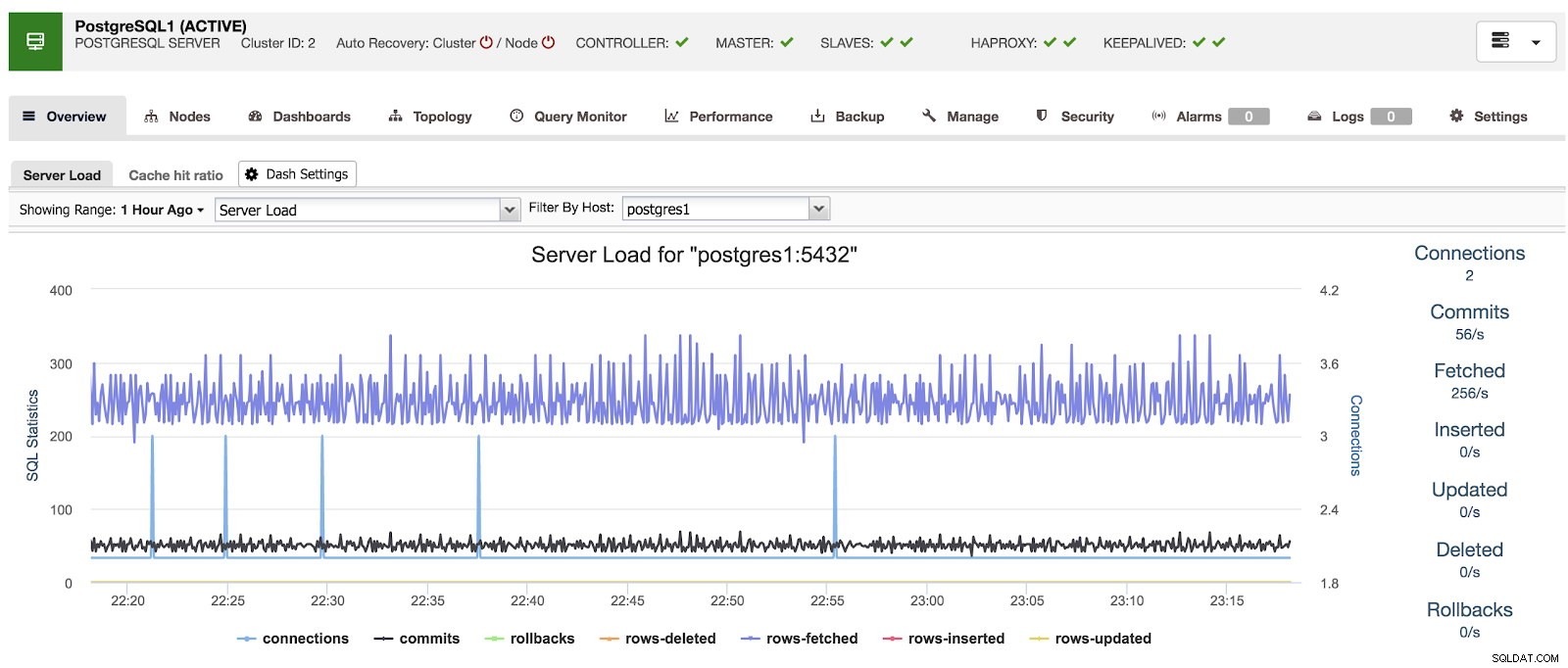 Visão geral do ClusterControl
Visão geral do ClusterControl Se formos para a opção “Painéis”, podemos ver uma mensagem como a seguinte.
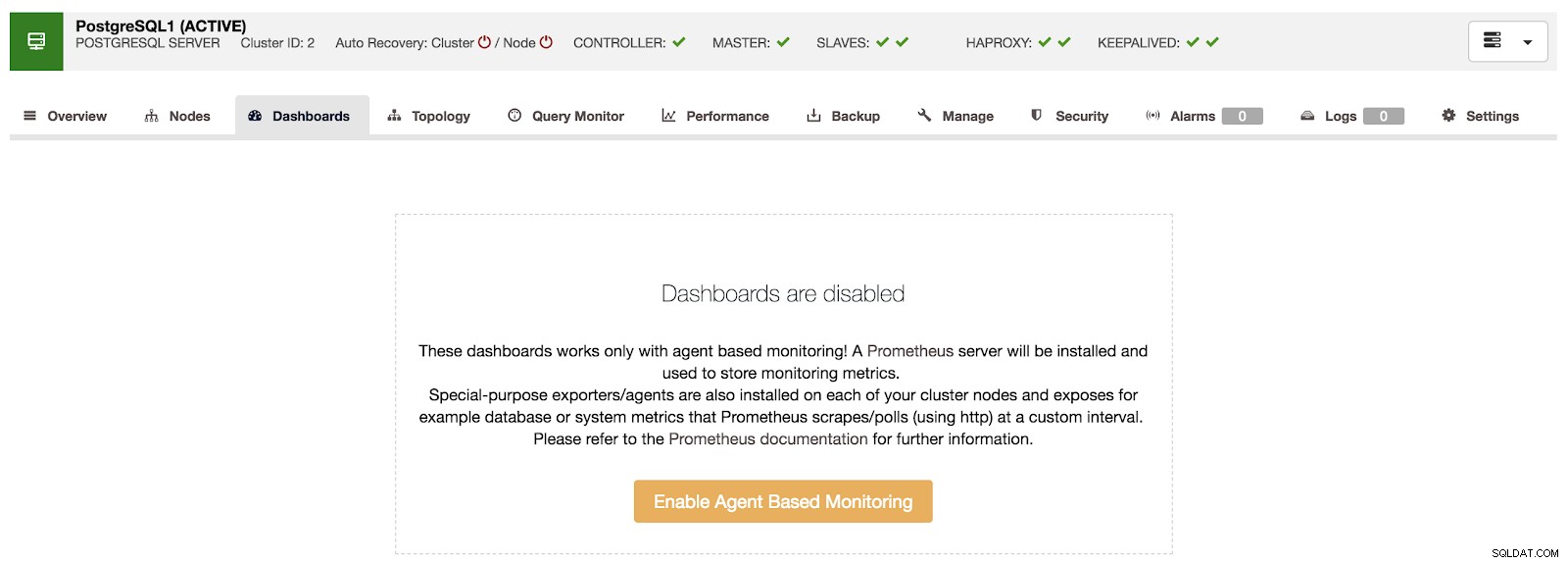 Painéis de controle de cluster desativados
Painéis de controle de cluster desativados Para usar esse recurso, devemos habilitar o agente mencionado acima. Para isso, basta pressionar o botão "Ativar monitoramento baseado em agente" nesta seção.
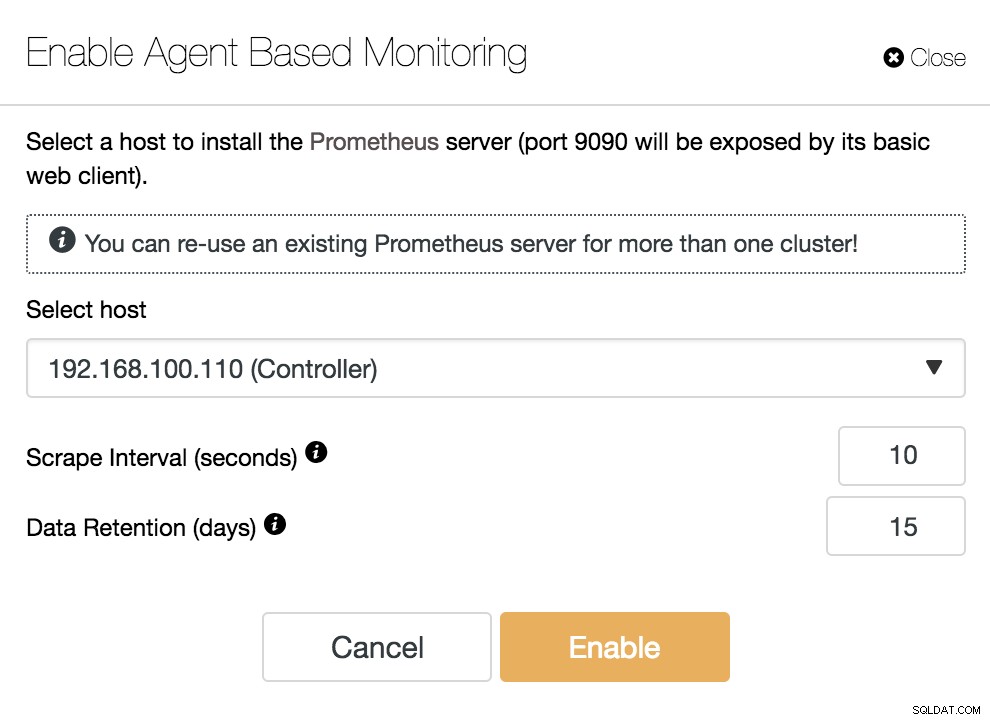 ClusterControl Habilitar monitoramento baseado em agente
ClusterControl Habilitar monitoramento baseado em agente Para habilitar nosso agente, devemos especificar o host onde instalaremos nosso servidor Prometheus, que, como podemos ver no exemplo, pode ser nosso servidor ClusterControl.
Devemos especificar também:
- Intervalo de raspagem (segundos):defina com que frequência os nós são raspados para métricas. O padrão é 10 segundos.
- Retenção de dados (dias):defina por quanto tempo as métricas são mantidas antes de serem removidas. O padrão é 15 dias.
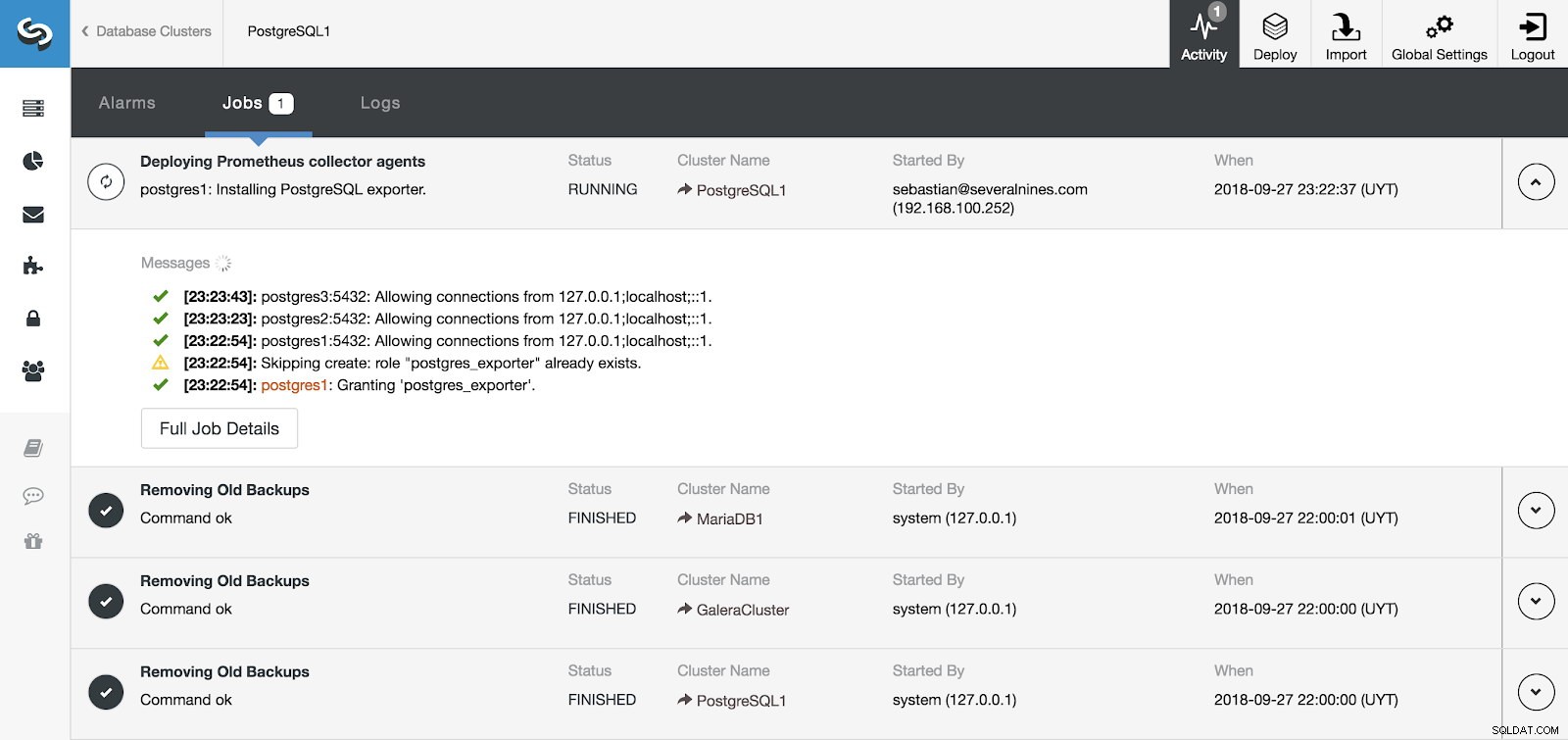 Seção de atividade de controle de cluster
Seção de atividade de controle de cluster Podemos monitorar a instalação de nosso servidor e agentes a partir da seção Activity no ClusterControl e, uma vez finalizada, podemos ver nosso cluster com os agentes habilitados na tela principal do ClusterControl.
 Agentes de ClusterControl habilitados
Agentes de ClusterControl habilitados Painéis
Com nossos agentes habilitados, se formos para a seção Dashboards, veremos algo assim:
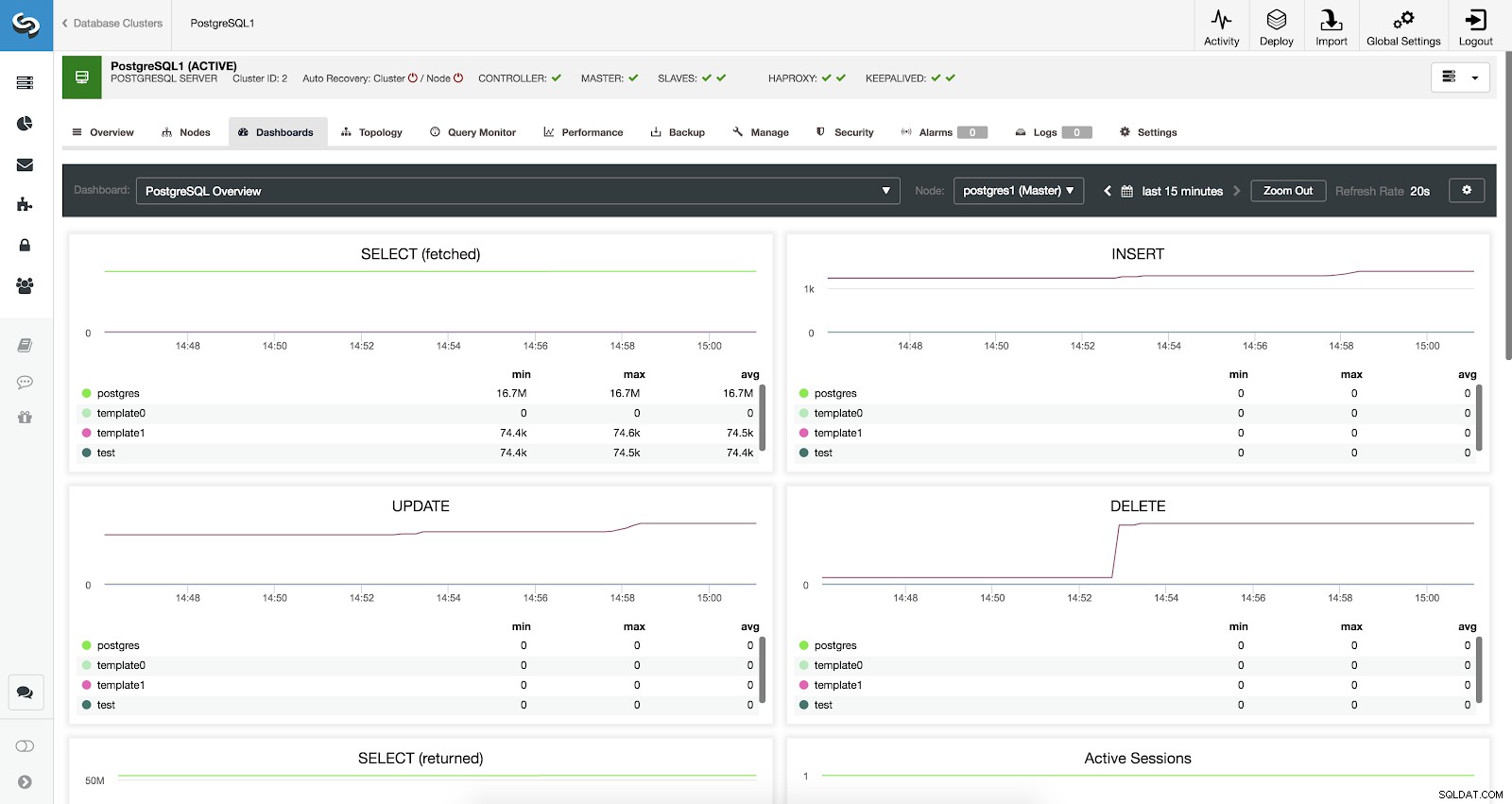 Painéis de controle de cluster habilitados
Painéis de controle de cluster habilitados Temos três tipos diferentes de painéis disponíveis, Visão geral do sistema, Gráficos entre servidores e Visão geral do PostgreSQL. O último é o que vemos por padrão ao entrar nesta seção.
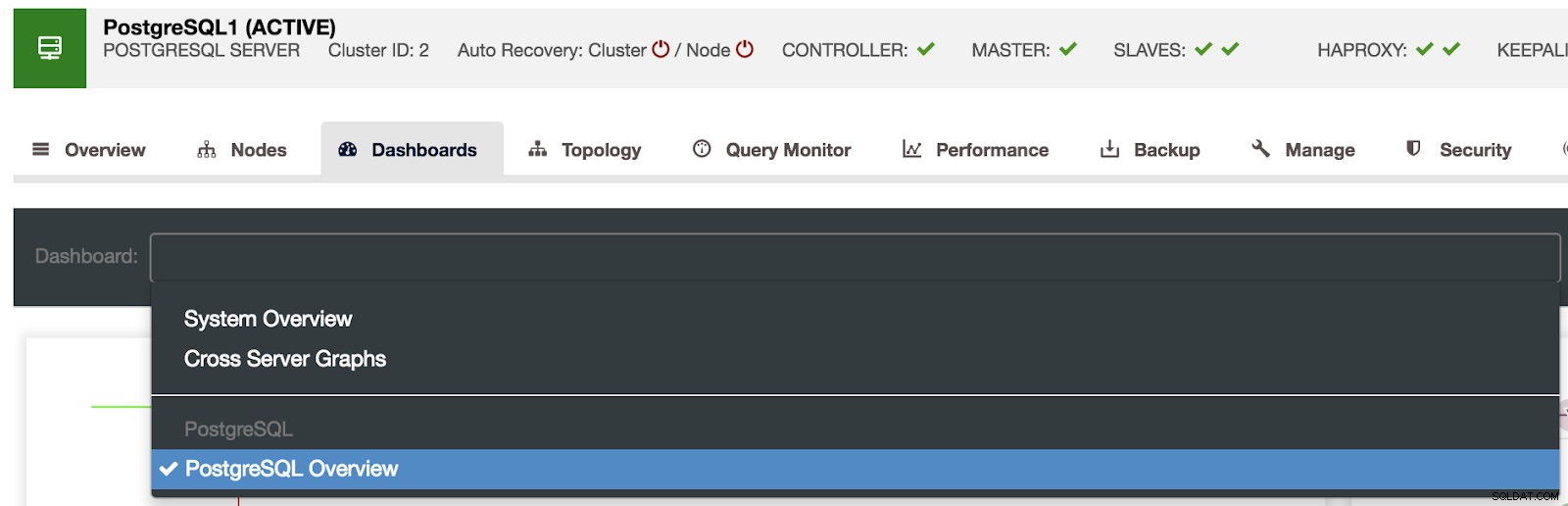 Seleção de painéis de controle de cluster
Seleção de painéis de controle de cluster Aqui também podemos especificar qual nó monitorar, o intervalo de tempo e a taxa de atualização.
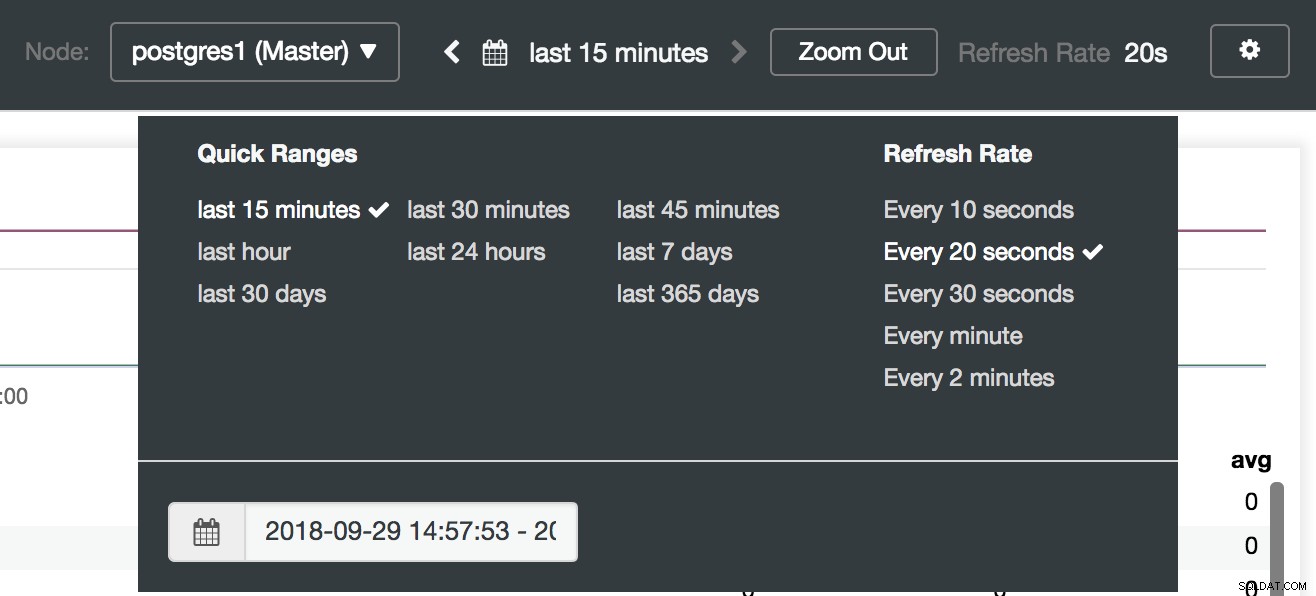 Opções do painel de controle de cluster
Opções do painel de controle de cluster Na seção de configuração, podemos habilitar ou desabilitar nossos agentes (Exportadores), verificar o status dos agentes e verificar a versão do nosso servidor Prometheus.
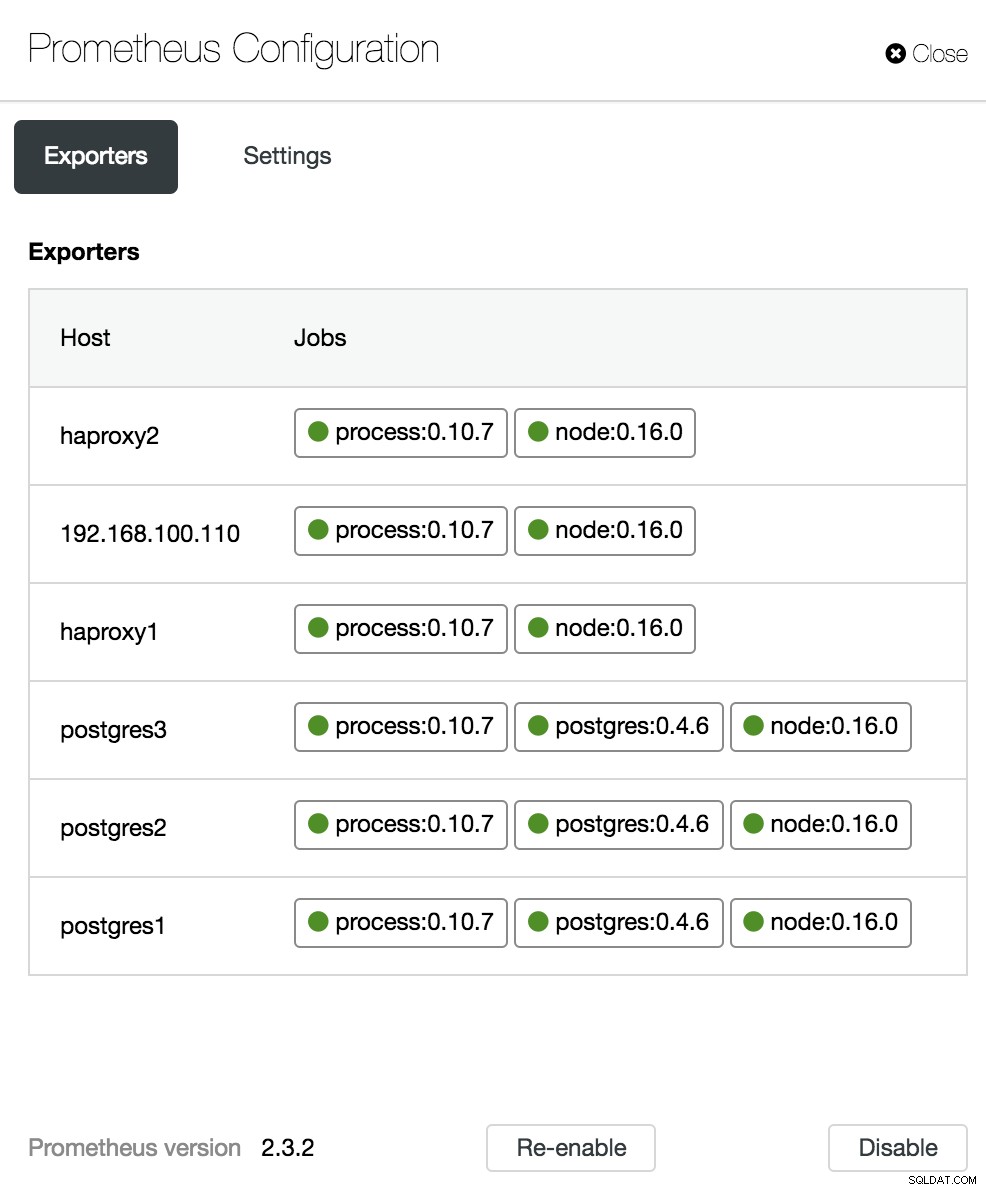 Configuração do painel de controle de cluster
Configuração do painel de controle de cluster Métricas de visão geral do PostgreSQL
Vamos ver agora quais métricas temos disponíveis para cada um dos nossos bancos de dados PostgreSQL (todos para o nó selecionado).
- SELECT (buscada):Quantidade de linhas selecionadas (buscadas) para cada banco de dados. As linhas buscadas referem-se a linhas ativas buscadas na tabela.
- SELECT (retornado):Quantidade de linhas selecionadas (retornadas) para cada banco de dados. As linhas retornadas referem-se a todas as linhas lidas da tabela, que inclui linhas mortas e linhas ainda não confirmadas (em contraste com as linhas buscadas que contam apenas as tuplas ativas).
- INSERIR:quantidade de linhas inseridas para cada banco de dados.
- ATUALIZAÇÃO:quantidade de linhas atualizadas para cada banco de dados.
- DELETE:quantidade de linhas excluídas para cada banco de dados.
- Sessões ativas:quantidade de sessões ativas (mín., máx. e média) para cada banco de dados.
- Sessões ociosas:quantidade de sessões ociosas (mín., máx. e média) para cada banco de dados.
- Tabelas de bloqueios:quantidade de bloqueios (mín., máx. e média) separados por tipo para cada banco de dados.
- Utilização de E/S de disco:utilização de E/S de disco do servidor.
- Uso do disco:porcentagem de uso do disco do servidor (mín., máximo e médio).
- Latência do disco:latência do disco do servidor.
Métricas de visão geral do ClusterControl PostgreSQL Métricas de visão geral do sistema
Para monitorar nosso sistema, temos disponíveis para cada servidor as seguintes métricas (todas para o nó selecionado):
- Tempo de atividade do sistema:tempo desde que o servidor está ativo.
- CPUs:quantidade de CPUs.
- RAM:quantidade de memória RAM.
- Memória disponível:porcentagem de memória RAM disponível.
- Média de carga:carga mínima, máxima e média do servidor.
- Memória:memória do servidor disponível, total e usada.
- Uso da CPU:informações de uso mínimo, máximo e médio da CPU do servidor.
- Distribuição de memória:distribuição de memória (buffer, cache, livre e usada) no nó selecionado.
- Métricas de saturação:mín., máx. e média de carga de E/S e carga de CPU no nó selecionado.
- Detalhes avançados da memória:detalhes de uso da memória, como páginas, buffer e muito mais, no nó selecionado.
- Forks:quantidade de processos de forks. Fork é uma operação pela qual um processo cria uma cópia de si mesmo. Geralmente é uma chamada de sistema, implementada no kernel.
- Processos:quantidade de processos em execução ou aguardando no sistema operacional.
- Mudanças de contexto:uma mudança de contexto é a ação de armazenar o estado de um processo ou de um encadeamento.
- Interrupções:Quantidade de interrupções. Uma interrupção é um evento que altera o fluxo normal de execução de um programa e pode ser gerado por dispositivos de hardware ou mesmo pela própria CPU.
- Tráfego de rede:tráfego de rede de entrada e saída em KBytes por segundo no nó selecionado.
- Utilização da rede por hora:tráfego enviado e recebido no último dia.
- Trocar:troque o uso (gratuito e usado) no nó selecionado.
- Atividade de troca:lê e grava dados na troca.
- Atividade de E/S:page in e page out no IO.
- Descritores de arquivo:descritores de arquivo alocados e limitados.
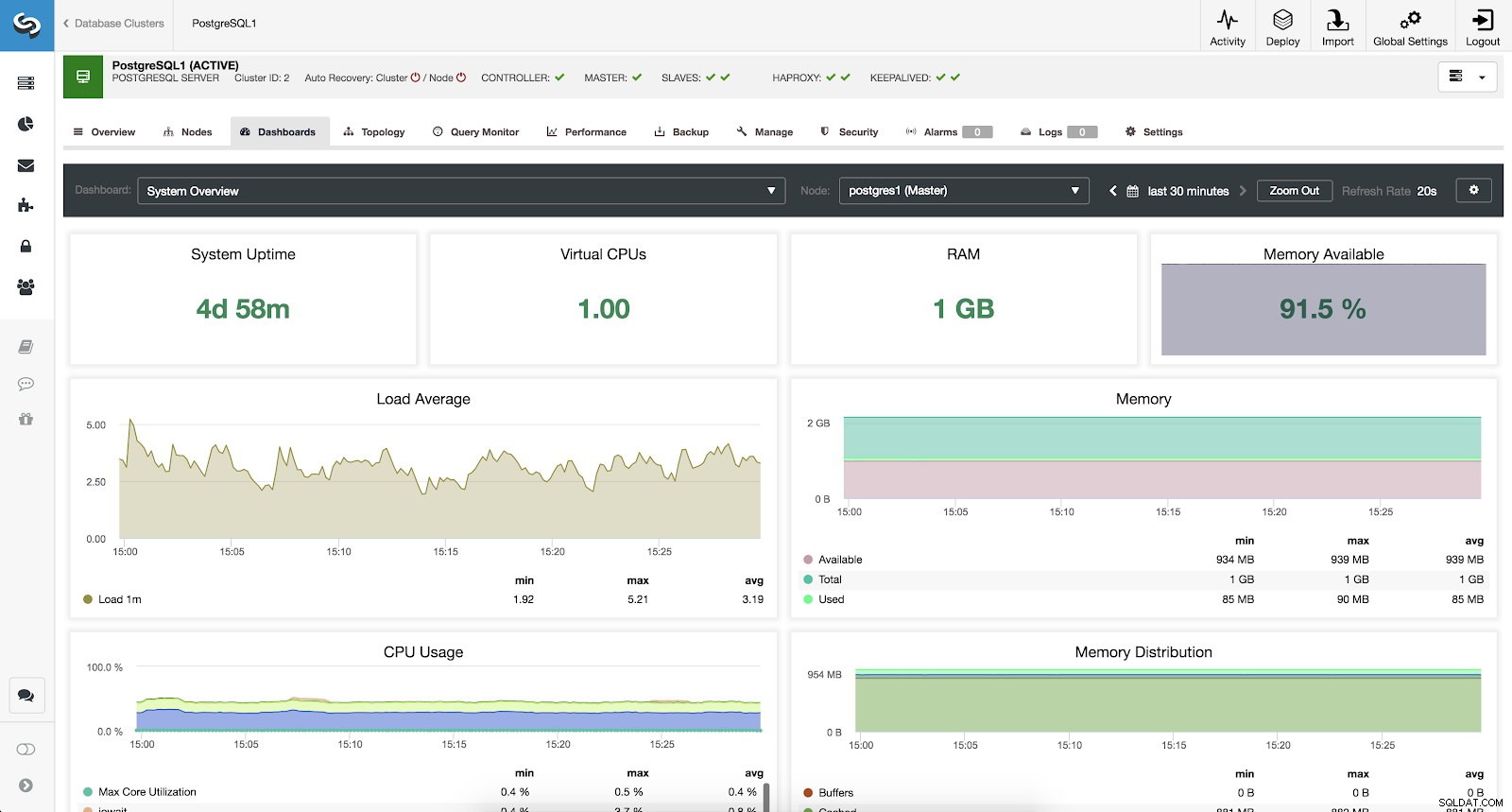 Métricas de visão geral do sistema ClusterControl
Métricas de visão geral do sistema ClusterControl Métricas de gráficos entre servidores
Se quisermos ver o estado geral de todos os nossos servidores, podemos usar este painel com as seguintes métricas:
- Média de carga:média de carga dos servidores para cada servidor.
- Uso de memória:porcentagem de uso de memória para cada servidor.
- Tráfego de rede:kBytes mínimo, máximo e médio de tráfego de rede por segundo.
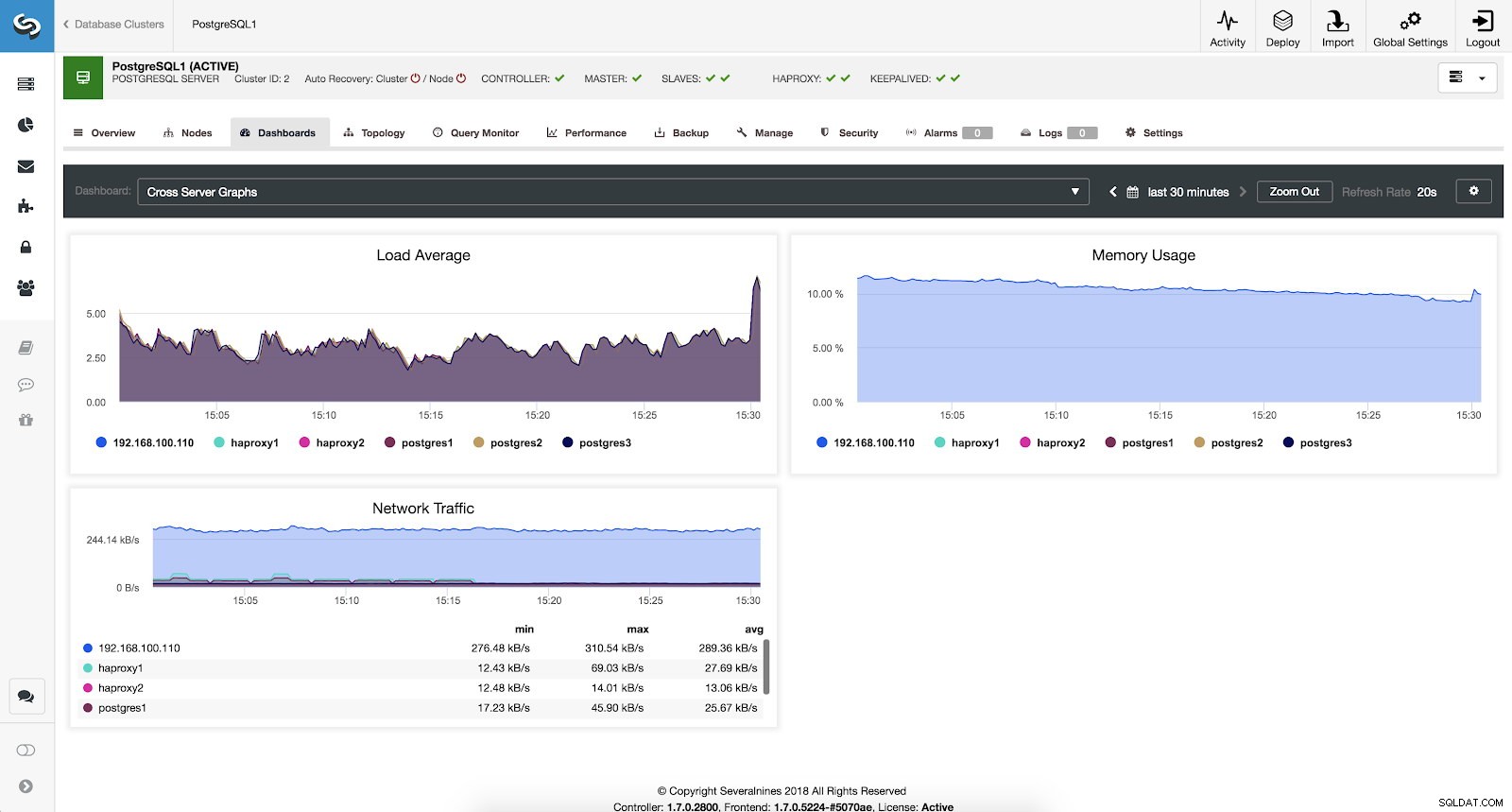 Métricas de gráficos de servidor cruzado do ClusterControl
Métricas de gráficos de servidor cruzado do ClusterControl Conclusão
Existem várias maneiras de monitorar o PostgreSQL. O ClusterControl fornece monitoramento sem agente e agora baseado em agente por meio do Prometheus. Ele fornece dados de monitoramento de maior resolução, bem como diferentes painéis para entender o desempenho do banco de dados. O ClusterControl também pode ser integrado a ferramentas externas como Slack ou PagerDuty para alertas.