Monitorar o PostgreSQL pode, às vezes, ser como tentar ganhar gado em uma tempestade. Os aplicativos se conectam e emitem consultas tão rapidamente que é difícil ver o que está acontecendo ou até mesmo obter uma boa visão geral do desempenho do sistema além do típico desenvolvedor reclamando do tipo 'as coisas estão lentas, socorro!'.
Em artigos anteriores, discutimos como chegar à fonte quando o PostgreSQL está agindo lentamente, mas quando a fonte é especificamente consultas, o monitoramento de nível básico pode não ser suficiente para avaliar o que está acontecendo em um ambiente ativo ao vivo.
Digite pg_top, um programa específico do PostgreSQL para monitorar a atividade em tempo real em um banco de dados, bem como visualizar informações básicas para o próprio host do banco de dados. Muito parecido com o comando linux ‘top’, executá-lo traz o usuário para uma exibição interativa ao vivo da atividade do banco de dados no host, atualizando automaticamente em intervalos.
Instalação
A instalação do pg_top pode ser feita das formas geralmente esperadas:gerenciadores de pacotes e instalação do código-fonte. A versão mais recente deste artigo é 3.7.0.
Gerenciadores de pacotes
Com base na distribuição do linux em questão, procure por pgtop ou pg_top no gerenciador de pacotes, provavelmente está disponível em algum aspecto para a versão instalada do PostgreSQL no sistema.
Distribuições baseadas em Red Hat:
# sudo yum install pg_topDistribuições baseadas no Gentoo:
# sudo apt-get install pgtopFonte
Se desejado, o pg_top pode ser instalado via fonte do repositório PostgreSQL git. Isso fornecerá qualquer versão desejada, até mesmo compilações mais recentes que ainda não estão nas versões oficiais.
Recursos
Uma vez instalado, o pg_top funciona como uma visualização em tempo real muito precisa do banco de dados que está monitorando e usando a linha de comando para executar o ‘pg_top’ iniciará a ferramenta interativa de monitoramento PostgreSQL.
A própria ferramenta pode ajudar a esclarecer todos os processos atualmente conectados ao banco de dados.
Executando pg_top
O lançamento do pg_top é o mesmo que o próprio comando 'top' no estilo unix/linux, junto com as informações de conexão com o banco de dados.
Para executar o pg_top em um host de banco de dados local:
pg_top -h localhost -p 5432 -d severalnines -U postgresPara executar o pg_top em um host remoto, o sinalizador -r ou --remote-mode é necessário e a extensão pg_proctab instalada no próprio host:
pg_top -r -h 192.168.1.20 -p 5432 -d severalnines -U postgresO que está na tela
Ao iniciar o pg_top, vemos uma tela com bastante informação.
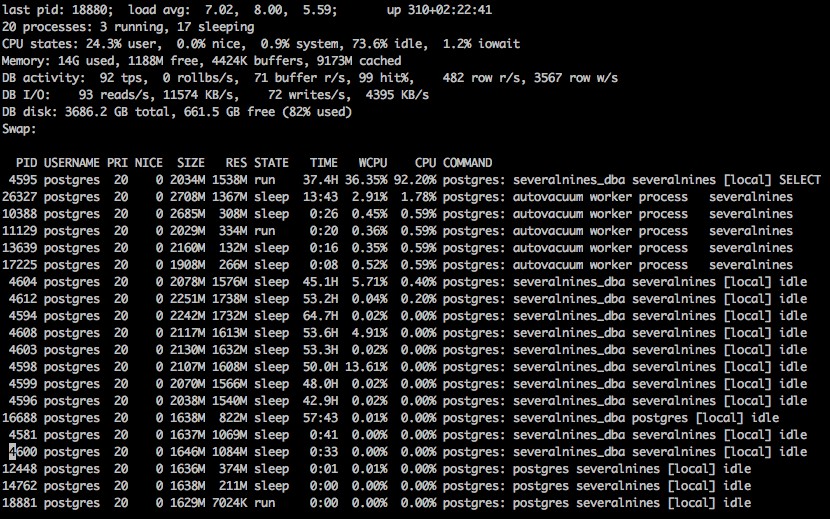 Saída padrão do pg_top no linux
Saída padrão do pg_top no linux Load Average:
Como o comando top padrão, esta carga média para intervalos de 1, 5 e 15 minutos.
Uptime:
A quantidade total de tempo que o sistema esteve online desde a última reinicialização.
Processos:
O número total de processos de banco de dados conectados, com um número de quantos estão em execução e quantos estão dormindo.
CPU Stats:
As estatísticas da CPU, mostrando a porcentagem de carga para usuário, sistema e ocioso, informações interessantes, bem como porcentagens de espera.
Memória:
A quantidade total de memória usada, livre, em buffers e em cache.
Atividade do banco de dados:
As estatísticas da atividade do banco de dados, como transações por segundo, número de reversões por segundo, buffers lidos por segundo, buffers atingidos por segundo, número de linhas lidas por segundo e linhas gravadas por segundo.
Atividade de DB I/O:
A atividade de Input Output no sistema, mostrando quantas leituras e gravações por segundo, bem como a quantidade lida e gravada por segundo.
DB Disk Stats:
O tamanho total do disco do banco de dados, bem como quanto espaço livre.
Swap:
As informações sobre o espaço de troca usado, se houver.
Processos:
Uma lista de processos conectados ao banco de dados, incluindo qualquer tipo de autovacuum de processos internos. A lista inclui o pid, a prioridade, a quantidade boa, a memória residente usada, o estado da conexão, o número de segundos de CPU usados, a porcentagem de CPU e o comando atual que o processo está executando.
Recursos interativos úteis
Há um punhado de recursos interativos no pg_top que podem ser acessados enquanto ele está em execução. Uma lista completa pode ser encontrada digitando um ?, que abrirá uma tela de ajuda com todas as diferentes opções disponíveis.
Informações do planejador
E - Plano de Execução
Inserir E fornecerá um prompt para um ID de processo para o qual mostrar um plano de explicação. Isso é equivalente a executar “EXPLAIN
A - EXPLAIN ANALYZE (UPDATE/DELETE safe)
Inserir A fornecerá um prompt para um ID de processo para o qual mostrar um plano EXPLAIN ANALYZE. Isso é equivalente a executar “EXPLAIN ANALYZE
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Informações do processo
Q - Mostrar consulta atual de um processo
Inserir Q fornecerá um prompt para um ID de processo para o qual mostrar a consulta completa.
I - Mostra as estatísticas de E/S por processo (somente Linux)
Inserindo I alterna a lista de processos para um display de E/S, mostrando cada processo de leituras, gravações, etc no disco.
L - Mostra bloqueios retidos por um processo
Inserir L fornecerá um prompt para um ID de processo para o qual mostrar bloqueios retidos. Isso incluirá o banco de dados, a tabela, o tipo de bloqueio e se o bloqueio foi concedido ou não. Útil para explorar processos de longa execução ou em espera.
Informações de relacionamento
R - Mostra as estatísticas da tabela do usuário.
Inserir R mostra as estatísticas da tabela, incluindo varreduras sequenciais, varreduras de índice, INSERTs, UPDATEs e DELETEs, todos relevantes para a atividade recente.
X - Mostrar estatísticas de índice do usuário
Inserir X mostra estatísticas de índice, incluindo varreduras de índice, leituras de índice e buscas de índice, todas relevantes para a atividade recente.
Classificação
A classificação da exibição pode ser feita através de qualquer um dos seguintes caracteres.
M - Classificar por uso de memória
N - Classificar por pid
P - Classificar por uso de CPU
T - Classificar por Tempo
A seguir estão as entradas especificadas após pressionar o, permitindo a classificação das páginas de índice, tabela e estatísticas de e/s também.
o - Especifique a ordem de classificação (cpu, tamanho, res, tempo, comando)
estatísticas do índice (idx_scan, idx_tup_fetch, idx_tup_read)
estatísticas da tabela (seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins, n_tup_upd, n_tup_del)
i/o stats (pid, rchar, wchar, syscr i/o stats (pid, rchar, wchar , escreve, cwrites, comando)
Conexão/Manipulação de Consulta
k - matar processos especificados
Digitar k fornecerá um prompt para um processo ou uma lista de processos de banco de dados a serem eliminados.
r - renice um processo (apenas banco de dados local, apenas root)
Digitar r fornecerá um prompt para um valor legal, seguido por uma lista de processos para definir esse novo valor legal. Isso altera a prioridade de processos importantes no sistema.
Exemplo:“renice 1 7004”
Diferentes usos do pg_top
Uso reativo de pg_top
O uso geral para pg_top é o modo interativo, permitindo-nos ver quais consultas estão sendo executadas em um sistema que está enfrentando problemas de lentidão, executar planos de explicação sobre essas consultas, cancelar consultas importantes para concluí-las mais rapidamente ou eliminar quaisquer consultas que causem grandes lentidão . Geralmente, ele permite que o administrador do banco de dados faça muitas das mesmas coisas que podem ser feitas manualmente no sistema, mas de forma mais rápida e em uma única opção.
Uso proativo do pg_top
Embora não seja muito comum, o pg_top pode ser executado em 'modo de lote', que exibirá as principais informações discutidas no padrão e sairá. Isso pode ser roteirizado para ser executado em determinados intervalos e, em seguida, enviado para qualquer processo personalizado desejado, analisado e alertas gerados com base no que o administrador pode querer ser alertado. Por exemplo, se a carga do sistema ficar muito alta, se houver um valor de transações por segundo maior do que o esperado, qualquer coisa que um programa criativo possa descobrir.
Geralmente, existem outras ferramentas para coletar e relatar essas informações, mas ter mais opções é sempre bom e, com mais ferramentas disponíveis, as melhores opções podem ser encontradas.
Uso histórico de pg_top
Muito parecido com o uso anterior, uso proativo, podemos criar scripts pg_top em um modo de lote para registrar instantâneos de como o banco de dados se parece ao longo do tempo. Isso pode ser tão simples quanto gravá-lo em um arquivo de texto com um carimbo de data/hora ou analisá-lo e armazenar a data em um banco de dados relacional para gerar relatórios. Isso permitiria que mais informações fossem encontradas após um grande incidente, como uma falha de banco de dados às 4 da manhã. Quanto mais dados disponíveis, mais problemas podem ser encontrados.
Mais informações
A documentação para o projeto é bastante limitada, e a maioria das informações está disponível na página de manual do linux, encontrada executando 'man pg_top'. A comunidade PostgreSQL pode ajudar com dúvidas ou problemas através das listas de discussão do PostgreSQL ou da sala de bate-papo oficial do IRC encontrada no freenode, nome do canal #postgresql.