Aqui estamos. Quase duas décadas no século 21 e a necessidade de mais poder de computação ainda é um problema. As empresas de tecnologia estão se esforçando para enfrentar esse enorme problema de frente. Os engenheiros de hardware encontraram uma solução alterando a maneira como projetam e fabricam a unidade de processamento central (CPU) de um computador. Eles agora contêm vários núcleos, o que permite a simultaneidade. Por sua vez, os desenvolvedores de software ajustaram a maneira como escrevem programas para se adaptar a essa mudança no hardware.
A comunidade PostgreSQL aproveitou ao máximo essas CPUs de vários núcleos para melhorar o desempenho das consultas. Simplesmente atualizando para as versões 9.6 ou superiores, você pode utilizar um recurso chamado paralelismo de consulta para realizar várias operações. Ele divide as tarefas em partes menores e distribui cada tarefa em vários núcleos de CPU. Cada núcleo pode processar as tarefas ao mesmo tempo. Devido às limitações de hardware, esta é a única maneira de melhorar o desempenho do computador à medida que avançamos no futuro.
Antes de usar o recurso de paralelismo no banco de dados PostgreSQL, é essencial reconhecer como ele torna uma consulta paralela. Você será capaz de depurar e resolver quaisquer problemas que surgirem.
Como funciona o paralelismo de consulta?
Para entender melhor como o paralelismo é executado, é uma boa ideia começar no nível do cliente. Para acessar o PostgreSQL, um cliente deve enviar uma solicitação de conexão ao servidor de banco de dados chamado postmaster. O postmaster concluirá a autenticação e, em seguida, bifurcará para criar um novo processo de servidor para cada conexão. Também é responsável por criar uma área de memória compartilhada que contém um buffer pool. O buffer pool supervisiona a transferência de dados entre a memória compartilhada e o armazenamento. Portanto, no momento em que uma conexão é estabelecida, o buffer pool transfere os dados e permite que o paralelismo de consulta possa ocorrer.
Não é necessário que todas as consultas sejam paralelas. Há casos em que apenas uma pequena quantidade de dados é necessária e pode ser processada rapidamente por apenas um núcleo. Esse recurso é usado apenas quando uma consulta levará muito tempo para ser concluída. O otimizador de banco de dados determina se o paralelismo deve ser executado. Se for necessário, o banco de dados usará uma porção adicional de memória chamada memória compartilhada dinâmica (DSM). Isso permite que o processo líder e os processos de trabalho paralelos dividam a consulta entre vários núcleos e reúnam dados pertinentes.
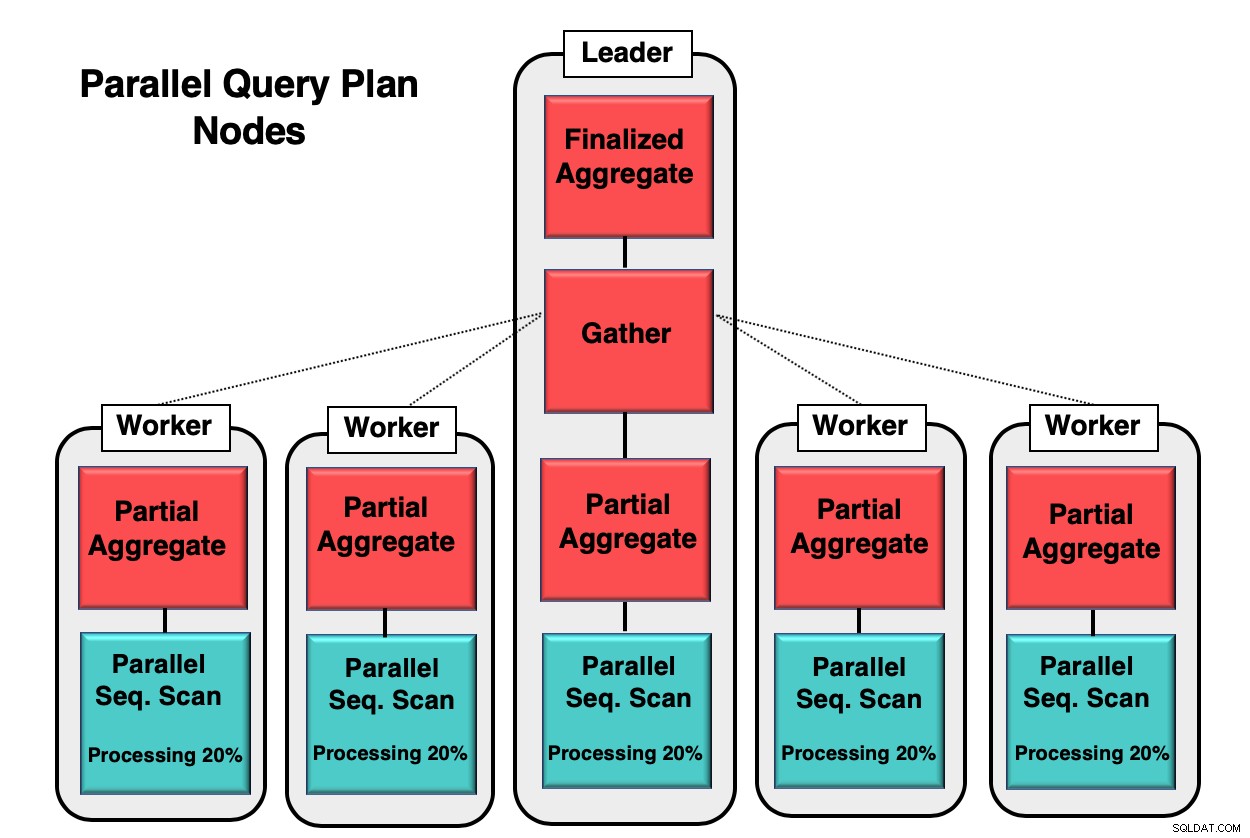
A Figura 1 fornece um exemplo de como o paralelismo ocorre dentro do banco de dados. O processo líder executa a consulta inicial, enquanto os processos de trabalho individuais iniciam uma cópia do mesmo processo. O nó de agregação parcial, ou núcleo de CPU, é responsável por implementar a varredura sequencial paralela da tabela do banco de dados.
Nesse caso, cada nó de varredura sequencial está processando 20% dos dados em blocos de 8kb. Esses mesmos nós podem coordenar suas atividades usando uma técnica chamada de reconhecimento paralelo. Cada nó tem total conhecimento de quais dados já foram processados e quais dados precisam ser verificados na tabela para concluir a consulta. Uma vez que as tuplas são coletadas por completo, elas são enviadas para o nó de coleta para serem compiladas e finalizadas.
Operações paralelas
Vários tipos de consultas podem ser usados para buscar dados de um banco de dados para produzir conjuntos de resultados. Aqui estão as operações específicas que permitem que você aproveite o uso de vários núcleos de forma eficaz.
Verificação Sequencial
Esta operação lê dados em uma tabela do início ao fim para coletar dados. Ele distribui uniformemente a carga de trabalho entre vários núcleos para aumentar a velocidade de processamento de consultas. Ele está ciente de cada atividade dos núcleos, tornando mais fácil determinar se toda a consulta foi concluída. O nó de coleta recebe os dados extraídos com base na consulta.
Agregação
Uma operação padrão, que pega uma grande quantidade de dados e os condensa em um número menor de linhas. Isso acontece durante o processamento paralelo, extraindo apenas de uma tabela ou índices, as informações apropriadas com base na consulta. Realizar uma média de dados específicos é um excelente exemplo de agregação.
União de hash
Uma técnica que é usada para unir os dados entre duas tabelas. É o algoritmo de junção mais rápido, que normalmente é executado com uma tabela pequena e uma grande. Você primeiro cria uma tabela de hash e carrega todos os dados de uma tabela para lá. Em seguida, você pode verificar todos os dados do hash e da segunda tabela, usando a verificação sequencial paralela. Cada tupla extraída da varredura é comparada à tabela de hash para ver se há uma correspondência. Se uma correspondência for identificada, os dados serão agrupados. Com o lançamento do PostgreSQL 11, usar o paralelismo para concluir uma junção de hash leva cerca de um terço do tempo de processamento anterior.
Mesclar associação
Se o otimizador determinar que uma junção de hash excederá a capacidade de memória, ele executará uma junção de mesclagem. O processo envolve a varredura através de duas listas classificadas ao mesmo tempo e une os mesmos elementos. Se os itens não forem iguais, os dados não serão unidos.
União de loop aninhado
Essa operação é usada quando você precisa unir duas tabelas contendo linguagens de programação diferentes, como Quick Basic, Python, etc. Cada tabela é verificada e processada usando vários núcleos. Se os dados corresponderem, eles serão enviados ao nó de coleta para serem unidos. Os índices também são verificados, e é por isso que esse processo contém vários loops para recuperar os dados. Em média, levará apenas um terço do tempo para concluir a junção usando o processo paralelo.
Varredura de índice de árvore B
Essa operação varre uma árvore de dados classificados para localizar informações específicas. Esse processo leva mais tempo do que a varredura sequencial típica porque há muita espera ao procurar registros. No entanto, o trabalho de varredura dos dados apropriados é dividido entre vários processadores.
Verificação de pilha de bitmap
Você pode mesclar vários índices usando esta operação. Você primeiro deseja criar o número equivalente de bitmaps, pois possui índices. Por exemplo, se você tiver três índices, deverá primeiro criar três bitmaps. Cada bitmap buscará e compilará tuplas com base na consulta.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Paralelismo de partição
Existe outra forma de paralelismo que pode ocorrer dentro do banco de dados PostgreSQL. No entanto, não vem da digitalização de tabelas e da divisão das tarefas. Você pode particionar ou dividir os dados por valores específicos. Por exemplo, você pode pegar os compradores de valor e ter um único núcleo processando os dados apenas dentro desse valor. Dessa forma, você sabe exatamente o que cada núcleo está processando em um determinado momento.
Particionamento de hash
Esta operação é usada espalhando as linhas da tabela em subtabelas. Novamente, a divisão geralmente determinada por um valor distinto ou uma lista de valores de uma tabela. Este é um excelente método para usar se você não tiver uma técnica de gerenciamento de armazenamento eficiente em todos os seus dispositivos. Você gostaria de usar o particionamento para distribuir aleatoriamente os dados para evitar gargalos de E/S.
Juntar por partição
Uma técnica usada para dividir tabelas por partições e uni-las combinando partições semelhantes. Por exemplo, você pode ter uma grande tabela de compradores de todos os Estados Unidos. Você pode primeiro dividir a tabela por cidades diferentes e depois juntar algumas cidades com base na região de cada estado. A junção por partição simplifica seus dados e permite a manipulação de tabelas.
Paralelamente inseguro
O PostgreSQL 11 executa automaticamente o paralelismo de consulta se o otimizador determinar que esta é a maneira mais rápida de concluir a consulta. Quanto maior a versão do PostgreSQL que você estiver usando, mais capacidade paralela terá seu banco de dados. Infelizmente, nem todas as consultas devem ser executadas de forma paralela, mesmo que tenha a capacidade. O tipo de consulta que você está realizando pode ter limitações específicas e exigirá que apenas um núcleo conclua todo o processamento. Isso diminuirá o desempenho do seu sistema, mas garantirá que os dados recebidos sejam inteiros.
Para garantir que suas consultas nunca sejam colocadas em risco, os desenvolvedores criaram uma função chamada paralela insegura. Você pode substituir manualmente o otimizador de banco de dados e solicitar que a consulta nunca seja paralela. O processo de paralelismo não será realizado.
O paralelismo dentro do banco de dados PostgreSQL é um recurso que só melhora a cada versão do banco de dados. Embora o futuro da tecnologia seja incerto, parece que o uso desse recurso veio para ficar.
Para mais informações, você pode conferir a seguir...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table